







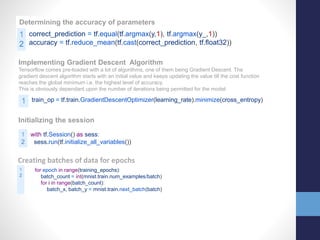
![1
2
x = tf.placeholder(tf.float32, shape=[None, 784])
y_ = tf.placeholder(tf.float32, shape=[None, 10])
Creating Placeholders
The method tf.placeholder allows us to create variables that act as nodes holding the data. Here,
x is a 2-dimensionall array holding the MNIST images, with none implying the batch size (which
can be of any size) and 784 being a single 28×28 image. y_ is the target output class that
consists of a 2-dimensional array
Creating Variables
1
2
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
Initializing the model
Python1 y = tf.nn.softmax(tf.matmul(x,W) + b)
1 cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y),
reduction_indices=[1]))
Defining Cost Function
This is the cost function of the model – a cost function is a difference between the predicted
value and the actual value that we are trying to minimize to improve the accuracy of the model.](https://image.slidesharecdn.com/internshipprojectpresentationfinalupload-180803164802/85/Internship-project-presentation_final_upload-8-320.jpg)
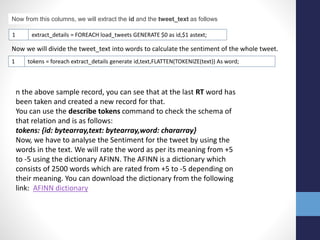
![Executing the model
1 sess.run([train_op], feed_dict={x: batch_x, y_: batch_y})
Print accuracy of the model
1
2
3
4
if epoch % 2 == 0:
print "Epoch: ", epoch
prit "Accuracy: ", accuracy.eval(feed_dict={x: mnist.test.images, y_:
mnist.test.labels})
print "Model Execution Complete"
Final Note
Creating a deep learning model can be easy and intuitive on Tensorflow. But to
really implement some cool things, you need to have a good grasp on machine
learning principles used in data science.](https://image.slidesharecdn.com/internshipprojectpresentationfinalupload-180803164802/85/Internship-project-presentation_final_upload-10-320.jpg)




![3. WORK DONE PREVIOUSLY:
• Over more than half a century, much empirical research was done on testing the
market efficiency, which can be traced to 1930’s by Alfred Cowles, Many studies have
found that stock prices are at least partially predictable. The method to test the
existence of statistical arbitrage was finally described in the paper “Statistical
arbitrage and tests of market efficiency” [4] by, S.Horgan,
• R.Jarrow, and M. Warachka published in 2002.And an improvement on the paper “An
Improved test for Statistical arbitrage”[5] was published in 2011 by the same team
which forms the basis for this project.
4. MOTIVATION:
• Arbitrage has the effect of causing prices in different markets to converge. [3] “The
speed at which the convergence process occurs usually gives us a measure of the
market efficiency”.
• Hence a thorough analysis of statistical arbitrage opportunities using the advanced
learning techniques is essential in mapping the efficiency of current day Indian
market.](https://image.slidesharecdn.com/internshipprojectpresentationfinalupload-180803164802/85/Internship-project-presentation_final_upload-19-320.jpg)
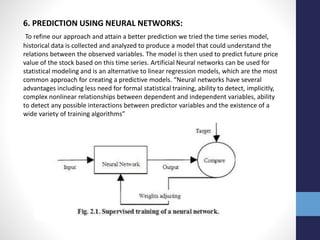
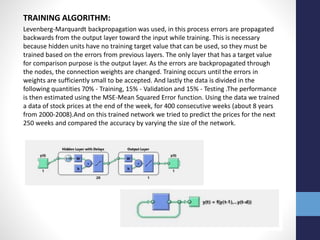
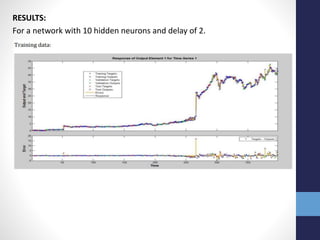
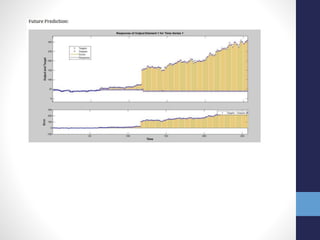
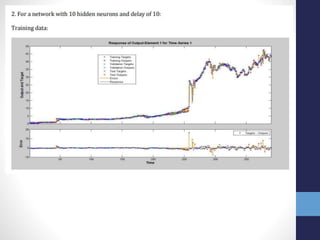
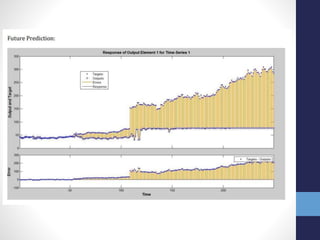




The document outlines projects completed by an intern in machine learning, including handwritten digit recognition using TensorFlow, sentiment analysis on demonetization tweets, and statistical arbitrage detection in Indian stock markets. It discusses the implementation details of each project, such as using TensorFlow for neural networks, data processing with Apache Pig for sentiment analysis, and predictive modeling with neural networks for stock prices. The conclusion emphasizes the challenges in predicting chaotic stock prices and the benefits of simpler models for better generalization.



































































