Download to read offline





![WHAT IS MACHINE LEARNING
The science (and art) of programming computers so that they can learn from data
[Machine Learning is the] field of study that gives computers the ability to learn without being
explicitly programmed.
—Arthur Samuel, 1959
A computer program is said to learn from experience E with respect to some task T and some
performance measure P, if its performance on T, as measured by P, improves with experience E.
-Tom Mitchell, 1997](https://image.slidesharecdn.com/chapter8whatismachinelearning2-241028215345-bfbbddd3/85/Chapter8_What_Is_Machine_Learning-Testing-Cases-5-320.jpg)

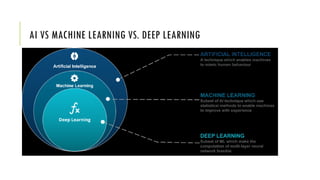
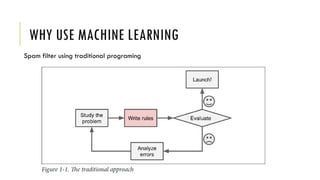
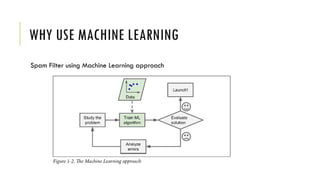
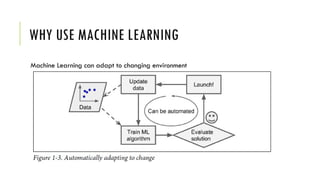
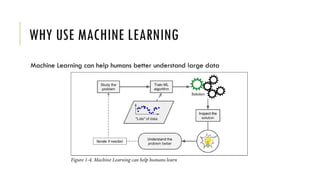



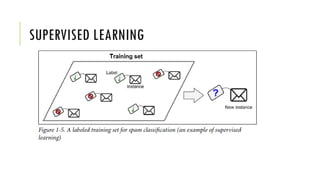

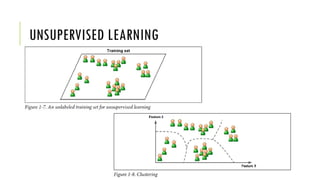
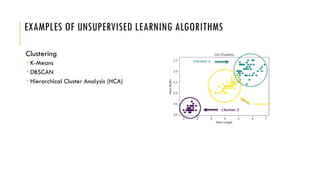





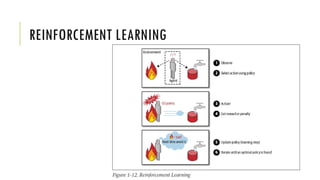


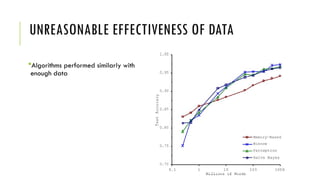
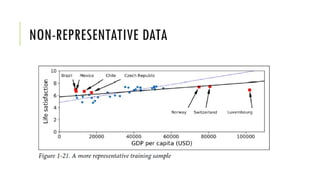


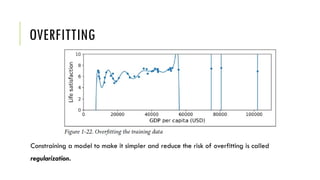




The document outlines the fundamentals and applications of machine learning, including its definitions, types, and challenges. It emphasizes machine learning's adaptability to changing environments and its ability to handle complex problems, along with various applications such as image classification and detecting credit card fraud. It also discusses the importance of data quality and methods for testing and validating machine learning models.










![1_Introduction to Machine Learning [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/1introductiontomachinelearningautosaved-250910004933-3913b711-thumbnail.jpg?width=640&height=640&fit=bounds)





















































