Download to read offline



![abstract typedef <integer, integer> rational;
condition rational[1] != 0;
/*Operator Definition (abstract functions specifying possible operations)*/
abstract rational createRational(a,b)
int a, b;
precondition b != 0;
postcondition createRational[0] == a;
createRational[1] == b;
abstract rational add(a,b)
rational a, b;
postcondition add[0] == a[0] * b[1] + b[0] * a[1];
add[1] == a[1] * b[1];
abstract rational subtract(a,b)
rational a, b;
postcondition subtract[0] == a[0] * b[1] - b[0] * a[1];
subtract[1] == a[1] * b[1];
abstract rational multiply(a,b)
rational a, b;
postcondition multiply[0] == a[0] * b[0];
multiply[1] == a[1] * b[1];
1.7 Algorithm
Algorithm is defined as a set of rules defined in necessary
flow so as to complete a specific task. It provides a core logic
necessary to solve a problem.
The significant traits of a good algorithm are as follows :
1. An algorithm should be terminated in finite number of
steps and each step should consume finite amount of
time.](https://image.slidesharecdn.com/ykxf4zwkspwxivbmlypm-signature-83da7908ba1a913c2446ce72ba0e2b0e2a9f94786fdc568a90cebcf1ab32f85c-poli-180906130835/85/Introduction-to-Data-Structure-and-Algorithm-4-320.jpg)


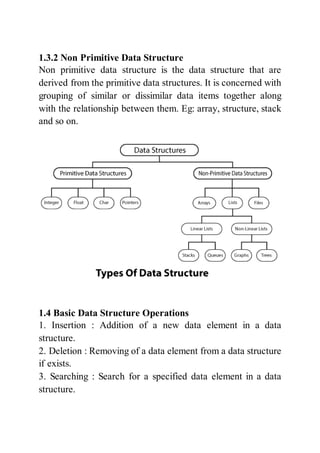
The document discusses fundamental concepts of data structures, including data types and their properties, operations on data structures, and the distinction between primitive and non-primitive data structures. It also highlights the importance of data structures in organizing and accessing data efficiently, as well as introduces abstract data types (ADT) and the characteristics of algorithms. Furthermore, it classifies algorithms based on paradigms such as brute force, divide and conquer, greedy, and dynamic approaches.


















































































