Downloaded 37 times







![ANALYSIS EXAMPLES
“Boost is the Secrete of our Energy”
Whitespace Analyzer
[Boost][is][the][Secrete][of][our][Energy]
Simple Analyzer
[boost][is][the][secrete][of][our][energy]
Stop Analyzer
[boost][secrete][energy]
Standard Analyzer
[boost][secrete][energy]](https://image.slidesharecdn.com/introductiontoapachelucene-150515075838-lva1-app6891/85/Introduction-to-apache-lucene-9-320.jpg)



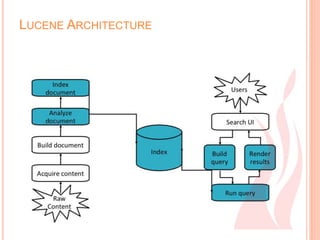
Apache Lucene is an open source Java-based search engine library. It allows adding full-text search capabilities to applications. Lucene indexes and searches documents, and is independent of file format. It analyzes text through tokenization and converts it into indexes. Common analyzers include Whitespace, Simple, Stop, and Standard analyzers.






















































































