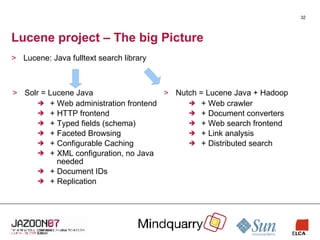
Apache Lucene is a free and open-source search library that provides indexing and searching capabilities. It includes Lucene Java, a core Java library, Solr, a search server with web administration, and Nutch, an open-source web crawler and search engine. Lucene Java provides indexing and searching capabilities, Solr adds web-based administration and HTTP access, and Nutch crawls websites and indexes content.










![Lucene Query Syntax Query examples: jazoon jazoon AND java <=> +jazoon +java jazoon OR java jazoon NOT php <=> jazoon -php conference AND (java OR j2ee) “ Java conference“ title:jazoon j?zoon jaz* schmidt~ schmidt, schmit, schmitt price:[000 TO 050] + more](https://image.slidesharecdn.com/apache-lucene-searching-the-web-and-everything-else-jazoon0711/85/Apache-Lucene-Searching-the-Web-and-Everything-Else-Jazoon07-10-320.jpg)





















![Daniel Naber [email_address] www.danielnaber.de Mindquarry GmbH www.mindquarry.com Presentation license: http://creativecommons.org/licenses/by/3.0/](https://image.slidesharecdn.com/apache-lucene-searching-the-web-and-everything-else-jazoon0711/85/Apache-Lucene-Searching-the-Web-and-Everything-Else-Jazoon07-35-320.jpg)


































![A customized web search engine [autosaved]](https://cdn.slidesharecdn.com/ss_thumbnails/acustomizedwebsearchengineautosaved-130724201343-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)































