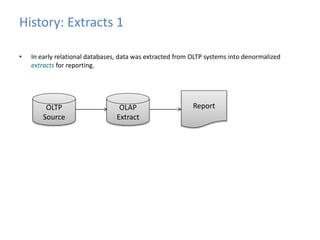
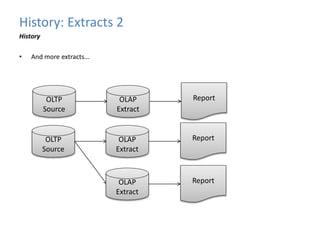
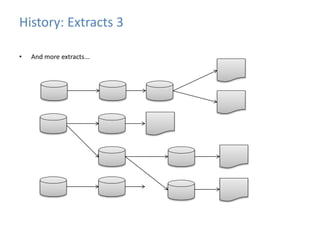
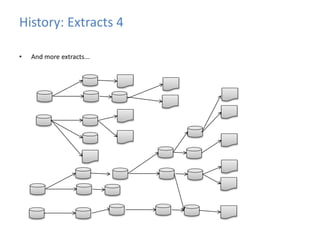
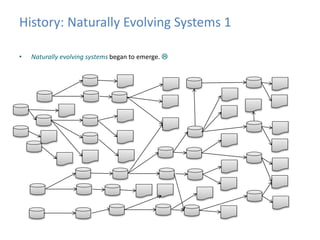
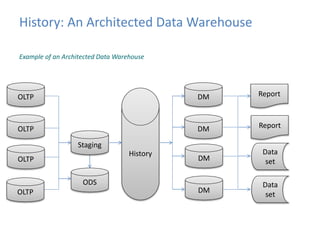
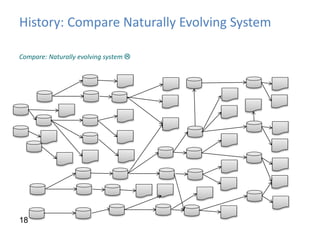
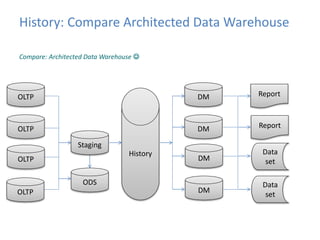
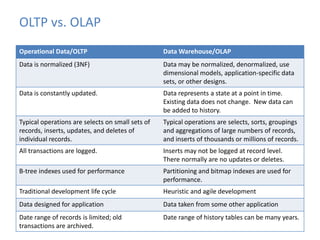
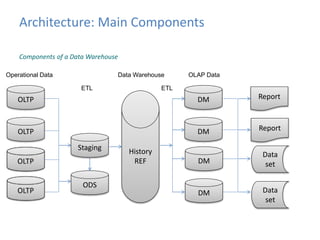
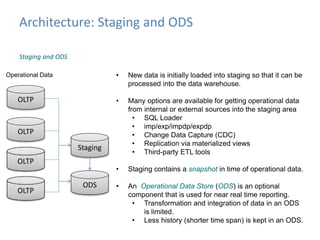
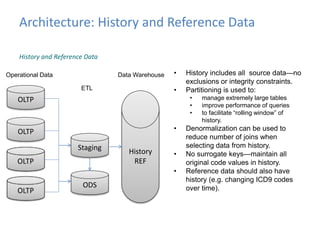
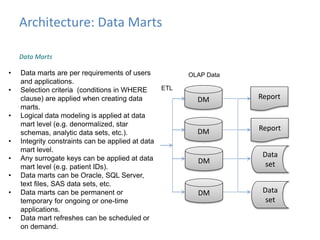
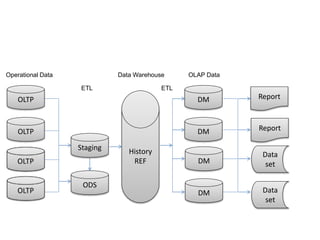
This document provides an introduction to data warehousing, covering its history from early use of punched cards and magnetic tape to modern architectures. It describes how data warehousing has evolved from simple extracts of operational data stored on disks to fully architected systems using techniques like extract-transform-load (ETL) to integrate data from multiple sources into a centralized data warehouse for analysis and reporting. It also compares the different paradigms of online transaction processing (OLTP) versus online analytical processing (OLAP) and discusses emerging technologies impacting data warehousing like massively parallel processing and in-memory databases.