Downloaded 52 times

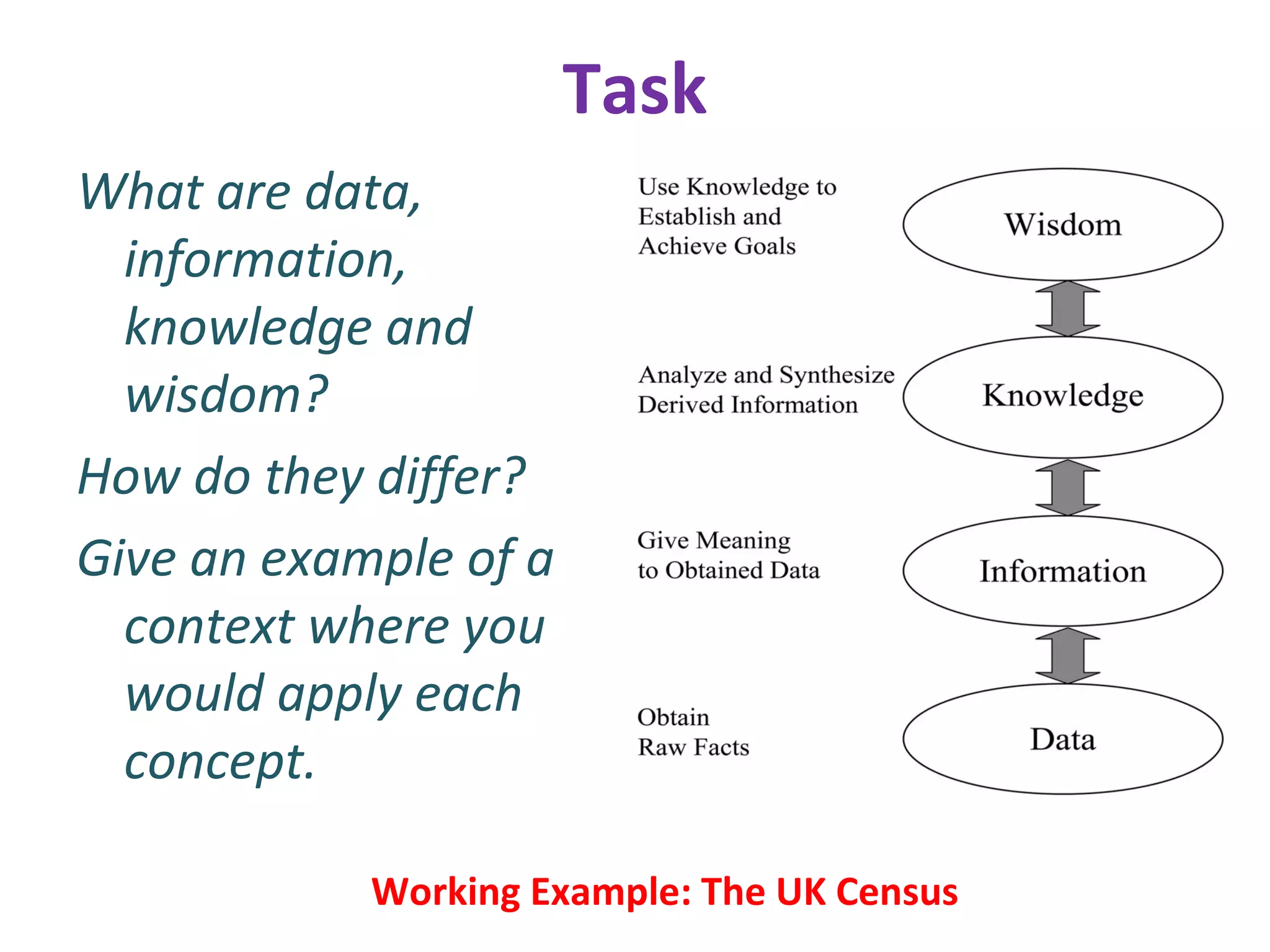
















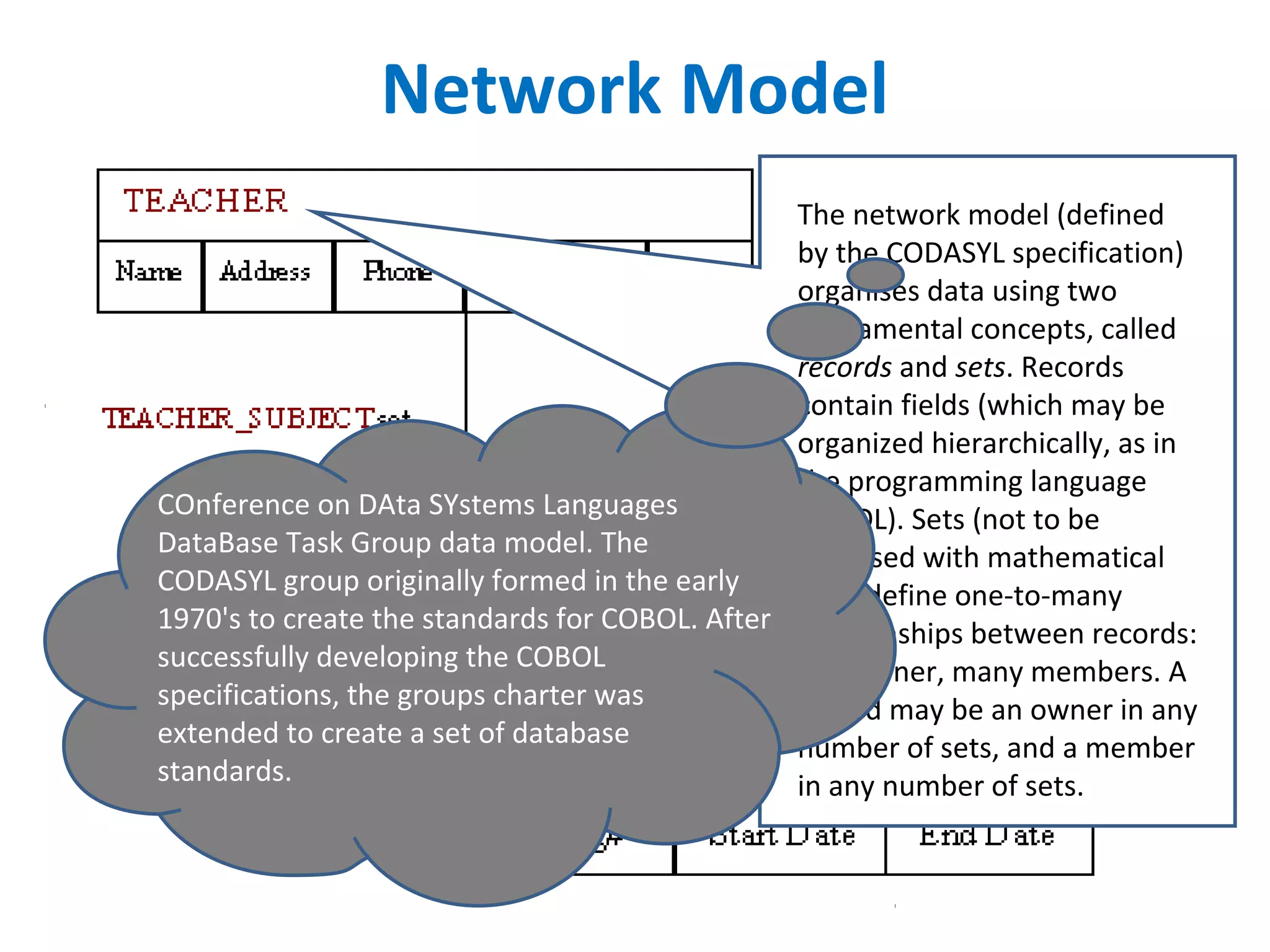












The document discusses the history of database management and database models through 6 generations from 1900 to present. It describes the evolution from early manual record keeping systems to current big data technologies. Key database models discussed include hierarchical, network, relational, object-oriented, and dimensional models. The document also covers topics like data warehousing and data mining.










































































































