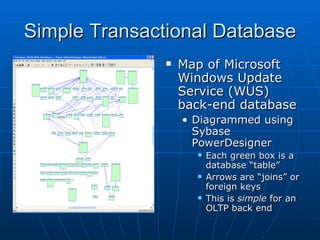
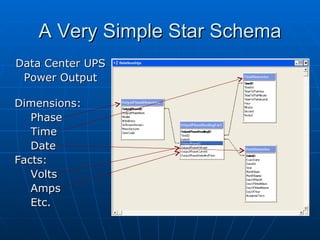
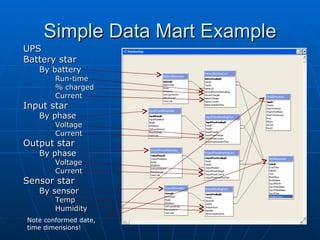
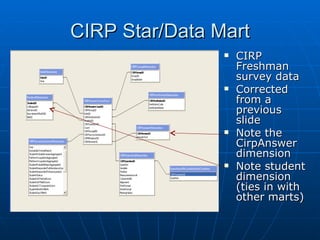
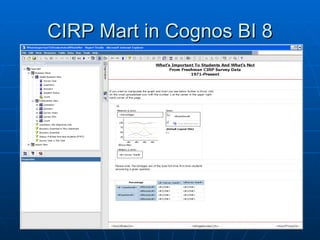
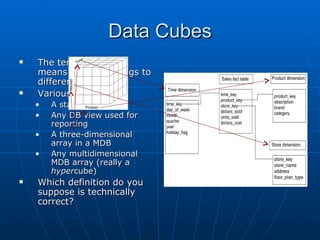
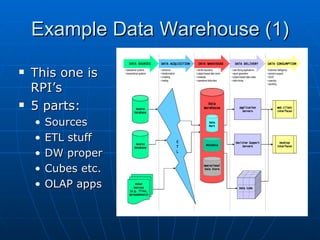
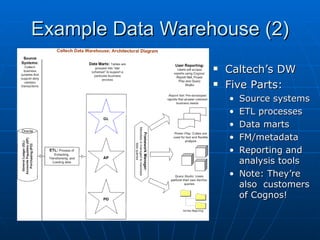
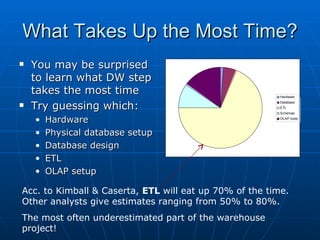
Richard discusses what a data warehouse is and why schools are setting them up. He explains that a data warehouse makes it easier for schools to optimize classroom usage, refine admissions systems, forecast demand, and more by bringing together data from different sources. It provides better information to make better admissions, retention, and fundraising decisions. He then discusses key data warehouse concepts like OLTP, OLAP, ETL, star schemas, and metadata to help the audience understand warehouse implementations.