Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Hibino Hisashi
14,304 views
【第26回Elasticsearch勉強会】Logstashとともに振り返る、やっちまった事例ごった煮
第26回Elasticsearch勉強会資料
Technology
◦
Read more
11
Save
Share
Embed
Embed presentation
Download
Downloaded 57 times
1
/ 40
2
/ 40
3
/ 40
4
/ 40
5
/ 40
6
/ 40
7
/ 40
8
/ 40
9
/ 40
10
/ 40
11
/ 40
12
/ 40
13
/ 40
14
/ 40
15
/ 40
Most read
16
/ 40
17
/ 40
18
/ 40
19
/ 40
20
/ 40
21
/ 40
22
/ 40
23
/ 40
24
/ 40
25
/ 40
26
/ 40
27
/ 40
28
/ 40
29
/ 40
30
/ 40
Most read
31
/ 40
32
/ 40
33
/ 40
34
/ 40
35
/ 40
36
/ 40
37
/ 40
38
/ 40
Most read
39
/ 40
40
/ 40
More Related Content
PDF
YugabyteDBを使ってみよう(NewSQL/分散SQLデータベースよろず勉強会 #1 発表資料)
by
NTT DATA Technology & Innovation
PPTX
PostgreSQLのロール管理とその注意点(Open Source Conference 2022 Online/Osaka 発表資料)
by
NTT DATA Technology & Innovation
PDF
Dockerからcontainerdへの移行
by
Kohei Tokunaga
PDF
アーキテクチャから理解するPostgreSQLのレプリケーション
by
Masahiko Sawada
PDF
Javaのログ出力: 道具と考え方
by
Taku Miyakawa
PPTX
コンテナネットワーキング(CNI)最前線
by
Motonori Shindo
PDF
Grafana LokiではじめるKubernetesロギングハンズオン(NTT Tech Conference #4 ハンズオン資料)
by
NTT DATA Technology & Innovation
PPTX
はじめてのElasticsearchクラスタ
by
Satoyuki Tsukano
YugabyteDBを使ってみよう(NewSQL/分散SQLデータベースよろず勉強会 #1 発表資料)
by
NTT DATA Technology & Innovation
PostgreSQLのロール管理とその注意点(Open Source Conference 2022 Online/Osaka 発表資料)
by
NTT DATA Technology & Innovation
Dockerからcontainerdへの移行
by
Kohei Tokunaga
アーキテクチャから理解するPostgreSQLのレプリケーション
by
Masahiko Sawada
Javaのログ出力: 道具と考え方
by
Taku Miyakawa
コンテナネットワーキング(CNI)最前線
by
Motonori Shindo
Grafana LokiではじめるKubernetesロギングハンズオン(NTT Tech Conference #4 ハンズオン資料)
by
NTT DATA Technology & Innovation
はじめてのElasticsearchクラスタ
by
Satoyuki Tsukano
What's hot
PDF
PostgreSQLの運用・監視にまつわるエトセトラ
by
NTT DATA OSS Professional Services
PDF
PGOを用いたPostgreSQL on Kubernetes入門(PostgreSQL Conference Japan 2022 発表資料)
by
NTT DATA Technology & Innovation
PDF
PostgreSQL 15の新機能を徹底解説
by
Masahiko Sawada
PDF
PostgreSQLをKubernetes上で活用するためのOperator紹介!(Cloud Native Database Meetup #3 発表資料)
by
NTT DATA Technology & Innovation
PPTX
Dockerからcontainerdへの移行
by
Akihiro Suda
PPTX
Kubernetesでの性能解析 ~なんとなく遅いからの脱却~(Kubernetes Meetup Tokyo #33 発表資料)
by
NTT DATA Technology & Innovation
PDF
ソーシャルゲーム案件におけるDB分割のPHP実装
by
infinite_loop
PDF
Apache Airflow 概要(Airflowの基礎を学ぶハンズオンワークショップ 発表資料)
by
NTT DATA Technology & Innovation
PPTX
オンライン物理バックアップの排他モードと非排他モードについて ~PostgreSQLバージョン15対応版~(第34回PostgreSQLアンカンファレンス...
by
NTT DATA Technology & Innovation
PDF
速習!論理レプリケーション ~基礎から最新動向まで~(PostgreSQL Conference Japan 2022 発表資料)
by
NTT DATA Technology & Innovation
PDF
Linux女子部 systemd徹底入門
by
Etsuji Nakai
PDF
InnoDBのすゝめ(仮)
by
Takanori Sejima
PDF
レプリケーション遅延の監視について(第40回PostgreSQLアンカンファレンス@オンライン 発表資料)
by
NTT DATA Technology & Innovation
PDF
インターネットの仕組みとISPの構造
by
Taiji Tsuchiya
PDF
PostgreSQL13でのレプリケーション関連の改善について(第14回PostgreSQLアンカンファレンス@オンライン)
by
NTT DATA Technology & Innovation
PPTX
Apache Spark on Kubernetes入門(Open Source Conference 2021 Online Hiroshima 発表資料)
by
NTT DATA Technology & Innovation
PDF
Hadoop/Spark で Amazon S3 を徹底的に使いこなすワザ (Hadoop / Spark Conference Japan 2019)
by
Noritaka Sekiyama
PDF
NetflixにおけるPresto/Spark活用事例
by
Amazon Web Services Japan
PDF
Spring Boot × Vue.jsでSPAを作る
by
Go Miyasaka
PPTX
iostat await svctm の 見かた、考え方
by
歩 柴田
PostgreSQLの運用・監視にまつわるエトセトラ
by
NTT DATA OSS Professional Services
PGOを用いたPostgreSQL on Kubernetes入門(PostgreSQL Conference Japan 2022 発表資料)
by
NTT DATA Technology & Innovation
PostgreSQL 15の新機能を徹底解説
by
Masahiko Sawada
PostgreSQLをKubernetes上で活用するためのOperator紹介!(Cloud Native Database Meetup #3 発表資料)
by
NTT DATA Technology & Innovation
Dockerからcontainerdへの移行
by
Akihiro Suda
Kubernetesでの性能解析 ~なんとなく遅いからの脱却~(Kubernetes Meetup Tokyo #33 発表資料)
by
NTT DATA Technology & Innovation
ソーシャルゲーム案件におけるDB分割のPHP実装
by
infinite_loop
Apache Airflow 概要(Airflowの基礎を学ぶハンズオンワークショップ 発表資料)
by
NTT DATA Technology & Innovation
オンライン物理バックアップの排他モードと非排他モードについて ~PostgreSQLバージョン15対応版~(第34回PostgreSQLアンカンファレンス...
by
NTT DATA Technology & Innovation
速習!論理レプリケーション ~基礎から最新動向まで~(PostgreSQL Conference Japan 2022 発表資料)
by
NTT DATA Technology & Innovation
Linux女子部 systemd徹底入門
by
Etsuji Nakai
InnoDBのすゝめ(仮)
by
Takanori Sejima
レプリケーション遅延の監視について(第40回PostgreSQLアンカンファレンス@オンライン 発表資料)
by
NTT DATA Technology & Innovation
インターネットの仕組みとISPの構造
by
Taiji Tsuchiya
PostgreSQL13でのレプリケーション関連の改善について(第14回PostgreSQLアンカンファレンス@オンライン)
by
NTT DATA Technology & Innovation
Apache Spark on Kubernetes入門(Open Source Conference 2021 Online Hiroshima 発表資料)
by
NTT DATA Technology & Innovation
Hadoop/Spark で Amazon S3 を徹底的に使いこなすワザ (Hadoop / Spark Conference Japan 2019)
by
Noritaka Sekiyama
NetflixにおけるPresto/Spark活用事例
by
Amazon Web Services Japan
Spring Boot × Vue.jsでSPAを作る
by
Go Miyasaka
iostat await svctm の 見かた、考え方
by
歩 柴田
Similar to 【第26回Elasticsearch勉強会】Logstashとともに振り返る、やっちまった事例ごった煮
PDF
実運用して分かったRabbit MQの良いところ・気をつけること #jjug
by
Yahoo!デベロッパーネットワーク
PDF
【第21回Elasticsearch勉強会】aws環境に合わせてelastic stackをログ分析基盤として構築した話
by
Hibino Hisashi
PDF
Logstashを愛して5年、370ページを超えるガチ本を書いてしまった男の話.
by
Hibino Hisashi
PDF
AWS Security JAWS 経済的にハニーポットのログ分析をするためのベストプラクティス?
by
Masamitsu Maehara
PPTX
Slurmのジョブスケジューリングと実装
by
Ryuichi Sakamoto
PDF
ElasticSearch勉強会 第6回
by
Naoyuki Yamada
PPTX
ぼくの考えた最強のpipeline構成
by
Naoto Nishizono
PPTX
ELK ではじめる自宅ネットワーク監視
by
npsg
PDF
Varnishのログの眺め方
by
Iwana Chan
PDF
Okinawa Open Days 2014 OpenStackハンズオンセミナー / OpenStackの機能概要
by
Etsuji Nakai
PPTX
『フルスタックエンジニアを目指す』ためのOpenStack勉強術 - OpenStack最新情報セミナー 2014年2月
by
VirtualTech Japan Inc.
PPT
vFabricを触ろう
by
土岐 孝平
PDF
【YahooJapanMeetup#31LT】ElasticStack on AWS DeepDive
by
Hibino Hisashi
PPT
Osc10do linux nextstep
by
smokey monkey
PPTX
作られては消えていく泡のように儚いクラスタの運用話
by
Tsuyoshi Torii
PDF
Serf2Excel - Serf を実運用に活かす話 + Consul もあるよ
by
Masahito Zembutsu
PPTX
『フルスタックエンジニアを目指す』ためのOpenStack勉強術 - OpenStack最新情報セミナー 2014年2月
by
Nobuyuki Tamaoki
PDF
20130927 adstir emr
by
AdStir
PDF
Google APP Engine vs リアルタイムウェブ
by
Hagiwara takayuki
PDF
fluent-plugin-resque_stat
by
Makoto Haruyama
実運用して分かったRabbit MQの良いところ・気をつけること #jjug
by
Yahoo!デベロッパーネットワーク
【第21回Elasticsearch勉強会】aws環境に合わせてelastic stackをログ分析基盤として構築した話
by
Hibino Hisashi
Logstashを愛して5年、370ページを超えるガチ本を書いてしまった男の話.
by
Hibino Hisashi
AWS Security JAWS 経済的にハニーポットのログ分析をするためのベストプラクティス?
by
Masamitsu Maehara
Slurmのジョブスケジューリングと実装
by
Ryuichi Sakamoto
ElasticSearch勉強会 第6回
by
Naoyuki Yamada
ぼくの考えた最強のpipeline構成
by
Naoto Nishizono
ELK ではじめる自宅ネットワーク監視
by
npsg
Varnishのログの眺め方
by
Iwana Chan
Okinawa Open Days 2014 OpenStackハンズオンセミナー / OpenStackの機能概要
by
Etsuji Nakai
『フルスタックエンジニアを目指す』ためのOpenStack勉強術 - OpenStack最新情報セミナー 2014年2月
by
VirtualTech Japan Inc.
vFabricを触ろう
by
土岐 孝平
【YahooJapanMeetup#31LT】ElasticStack on AWS DeepDive
by
Hibino Hisashi
Osc10do linux nextstep
by
smokey monkey
作られては消えていく泡のように儚いクラスタの運用話
by
Tsuyoshi Torii
Serf2Excel - Serf を実運用に活かす話 + Consul もあるよ
by
Masahito Zembutsu
『フルスタックエンジニアを目指す』ためのOpenStack勉強術 - OpenStack最新情報セミナー 2014年2月
by
Nobuyuki Tamaoki
20130927 adstir emr
by
AdStir
Google APP Engine vs リアルタイムウェブ
by
Hagiwara takayuki
fluent-plugin-resque_stat
by
Makoto Haruyama
More from Hibino Hisashi
PDF
【JEUG】 オープンSIEMの世界へ
by
Hibino Hisashi
PDF
AWS re:Inforce2019 re:Cap LT
by
Hibino Hisashi
PDF
【ログ分析勉強会】セッションアクティビティログは使えるのか
by
Hibino Hisashi
PDF
【第20回セキュリティ共有勉強会】Amazon FSx for Windows File Serverをセキュリティ観点で試してみたお話
by
Hibino Hisashi
PDF
【SecurityJAWS】Kibana Canvasで魅せる!AWS環境における脅威分析ユースケース
by
Hibino Hisashi
PDF
Elastic Cloudを活用!!ゼロトラストセキュリティの「はじめの一歩」
by
Hibino Hisashi
PDF
オープンソースソフトウェアで実現するエンタープライズにおけるセキュリティ脅威分析の勘所
by
Hibino Hisashi
PDF
【第17回セキュリティ共有勉強会】WAF導入で見えた脆弱性管理のあれこれ
by
Hibino Hisashi
PDF
【DeepSecurityUserNight】我が家の箱入り娘を世間に晒すのは危険なのでDeepSecurityに見守ってもらった話
by
Hibino Hisashi
PDF
【Log Analytics Tech Meetup】オープンソースで実現するログ分析技術入門
by
Hibino Hisashi
PDF
Amazon Elasticsearch Service & Open Distro for Elasticsearch Meetup
by
Hibino Hisashi
PDF
【セキュランLT】国内金融機関に激震!!仮想通貨、要求されたらあなたはどうしますか?
by
Hibino Hisashi
PDF
【JANOG41.5】Telemetryワーキンググループの発足と参加のお願い
by
Hibino Hisashi
PDF
Security threat analysis points for enterprise with oss
by
Hibino Hisashi
PDF
【JAWS-UGコンテナ#14】ETL処理をServerlessにしてみた件
by
Hibino Hisashi
PDF
【Log Analytics Tech Meetup】Beatsファミリーの紹介
by
Hibino Hisashi
PDF
【第31回Elasticsearch勉強会】Security for Elasticsearch
by
Hibino Hisashi
【JEUG】 オープンSIEMの世界へ
by
Hibino Hisashi
AWS re:Inforce2019 re:Cap LT
by
Hibino Hisashi
【ログ分析勉強会】セッションアクティビティログは使えるのか
by
Hibino Hisashi
【第20回セキュリティ共有勉強会】Amazon FSx for Windows File Serverをセキュリティ観点で試してみたお話
by
Hibino Hisashi
【SecurityJAWS】Kibana Canvasで魅せる!AWS環境における脅威分析ユースケース
by
Hibino Hisashi
Elastic Cloudを活用!!ゼロトラストセキュリティの「はじめの一歩」
by
Hibino Hisashi
オープンソースソフトウェアで実現するエンタープライズにおけるセキュリティ脅威分析の勘所
by
Hibino Hisashi
【第17回セキュリティ共有勉強会】WAF導入で見えた脆弱性管理のあれこれ
by
Hibino Hisashi
【DeepSecurityUserNight】我が家の箱入り娘を世間に晒すのは危険なのでDeepSecurityに見守ってもらった話
by
Hibino Hisashi
【Log Analytics Tech Meetup】オープンソースで実現するログ分析技術入門
by
Hibino Hisashi
Amazon Elasticsearch Service & Open Distro for Elasticsearch Meetup
by
Hibino Hisashi
【セキュランLT】国内金融機関に激震!!仮想通貨、要求されたらあなたはどうしますか?
by
Hibino Hisashi
【JANOG41.5】Telemetryワーキンググループの発足と参加のお願い
by
Hibino Hisashi
Security threat analysis points for enterprise with oss
by
Hibino Hisashi
【JAWS-UGコンテナ#14】ETL処理をServerlessにしてみた件
by
Hibino Hisashi
【Log Analytics Tech Meetup】Beatsファミリーの紹介
by
Hibino Hisashi
【第31回Elasticsearch勉強会】Security for Elasticsearch
by
Hibino Hisashi
【第26回Elasticsearch勉強会】Logstashとともに振り返る、やっちまった事例ごった煮
1.
Logstashとともに振り返る やっちまった事例ごった煮 2018/11/21(Wed) 第26回 Elasticsearch勉強会 フューチャーアーキテクト株式会社 日比野恒
2.
自己紹介 名前:日比野 恒 (ひびの
ひさし) 所属:フューチャーアーキテクト株式会社 セキュリティアーキテクト (CISSP、CISA、情報処理安全確保支援士) オープンな技術 オープンな環境× 【オープンSIEM構想】 「オープンな技術」や「オープンな環境」でSIEMを作りたい!! 「個人の知見やスキルは、社会の利益のために使われるべき」というマインド
3.
本日のテーマ ✓ 実際に運用しないと得られない気づきを伝えたい! ✓ オープンに公開されていないようなネタを伝えたい! ※本資料は終了後公開しますので、メモ不要ですw
4.
そして主役は...
5.
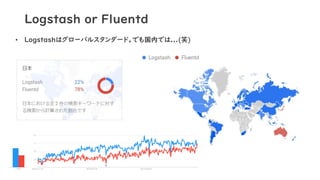
Logstash or Fluentd •
Logstashはグローバルスタンダード。でも国内では...(笑)
6.
お世話になっているinputたち • ログ分析において、だいぶお世話になっているものがオレンジ色、稀にお世話になるものが黄緑色。 azure_event_hubs beats cloudwatch couchdb_changes dead_letter_queue elasticsearch exec file ganglia gelf generator github google_pubsub graphite heartbeat http http_poller imap irc jdbc jms jmx kafka kinesis log4j lumberjack meetup pipe puppet_facter rabbitmq redis relp rss s3 salesforce snmptrap sqlite sqs stdin stomp syslog tcp twitter udp unix varnishlog websocket wmi xmpp
7.
お世話になっているfilterたち • ログ分析において、だいぶお世話になっているものがオレンジ色、稀にお世話になるものが黄緑色。 aggregate alter cidr cipher clone csv date de_dot dissect dns drop elapsed elasticsearch environment extractnumbers fingerprint geoip grok i18n jdbc_static jdbc_streaming json json_encode kv metricize metrics mutate prune range ruby sleep split syslog_pri throttle tld translate truncate urldecode useragent uuid xml
8.
お世話になっているoutputたち • ログ分析において、だいぶお世話になっているものがオレンジ色、稀にお世話になるものが黄緑色。 boundary circonus cloudwatch csv datadog datadog_metrics elasticsearch email exec file ganglia gelf google_bigquery google_pubsub graphite graphtastic http influxdb irc juggernaut kafka librato loggly lumberjack metriccatcher mongodb nagios nagios_nsca opentsdb pagerduty pipe rabbitmq redis redmine riak riemann s3 sns solr_http sqs statsd stdout stomp syslog tcp timber udp webhdfs websocket xmpp zabbix
9.
お世話になっているcodecたち • ログ分析において、だいぶお世話になっているものがオレンジ色、稀にお世話になるものが黄緑色。 avro cef cloudfront collectd dots edn edn_lines es_bulk fluent graphite gzip_lines json json_lines line msgpack multiline netflow nmap plain protobuf rubydebug
10.
さて、そろそろ本題...
11.
Logstashにおける性能と拡張性
12.
このような通信分析環境を構築してみた • Netflow CollectorをElastic
Stackで構築し、約20,000/秒のフローの取り込みを行う。 ※構築時は最終的にどのくらいのフロー数が流れてくるか読めていなかった...(泣) NetFlow Exporter Netflow Collector Netflow (UDP) ここの話 input { udp { port => "2055" workers => “4" queue_size => "2048“ codec => netflow { versions => [5,9,10] } } }
13.
Logstashのシステム構成 • オンプレ環境のNutanix上に仮想マシンとしてLogstash専用ノード×1台準備。 Nutanix AHV
(Host OS) CentOS7 64bit (Guest OS) Server Node Java 8 Logstash 6.2.4 X-Pack Basic 6.2.4 項目 設定値 vCPU 4コア vRAM 16GB vDisk 100GB vNIC 1個 (1000BASE-T)
14.
【参考】Netflowとは • シスコ社が開発したトラフィックの詳細情報を収集するための技術で、主に通信分析に活用する。
15.
【参考】Netflowのドキュメント内容 • Netflow(v9)で取り込んだフローのドキュメント(KeyとValue)は以下の通り。
16.
【参考】codec netflow • 1個のパケット(=FlowSequence)に含まれる複数のフローをフロー単位に分割してくれる。 input (udp) Codec (netflow) Filter Output (elastic search) UDPパケット フロー 【パケットキャプチャデータ】 例)1個のパケットの中には19個のフローが含まれていた。 【参考URL】Netflow
codec plugin https://www.elastic.co/guide/en/logstash/current/plugins-codecs-netflow.html
17.
発生した性能問題 【ポイント】 150Mbps出ているはずが、100分の1しか収集出来ていなかった。 • 収集したフロー情報からKibanaでグラフ作成するもCactiの性能データと大きく乖離があった。
18.
障害切り分け • Logstashの各処理で想定外の動きをしていないかを中心に疑い切り分けを実施するも... 【疑った観点1】 Logstashのfilterで parse errorが起きているの では? 【疑った観点2】 codec
netflowで正しく フローが分割出来ていない のでは? 【疑った観点3】 そもそもNetflowパケットが 正しく受信出来ていないので は? 【結果1】 Netflowをパケットキャプ チャして、パケットの中身と比 較するもデータサイズに差分 なし... 【結果2】 同じくパケットキャプチャした パケットのシーケンス単位で フローを比較するも差分な し... 【結果3】 Exporter側とCollecter側 の通信量を比較するも大きく 差分なし... どこでDropしているのか?
19.
パケットのDropが起きていることが判明 • netstat –suコマンドのpacket
receive errorsのカウンタが上がり続けていた。 【ポイント】 7/2のフロー取得対象機器追加後 収集フロー数が激減していた。 # netstat -su IcmpMsg: InType3: 4 InType8: 1016 OutType0: 1016 OutType3: 8594 Udp: 229538 packets received 340486 packets to unknown port received. 79619 packet receive errors 107 packets sent 79619 receive buffer errors 0 send buffer errors UdpLite: IpExt: InNoRoutes: 2 InBcastPkts: 44 InOctets: 1372994252 OutOctets: 6150335046 InBcastOctets: 5909 InNoECTPkts: 2374707
20.
Dropしていたパケットを集計 • netstat –suコマンドを毎秒cronで回して、カウンタ値を集計してみたら大分泣けてきた...
21.
pipelineアーキテクチャ図 • Logstashのpluginが各処理の中でどのようにメモリ領域を利用しているのかを書いてみた。 CentOS7 Memory JVM Heaps Netflow Exporter UDP Receive
buffer Memory Queue input udp queue Logstash input (udp) Codec (netflow) Filter Output (elastic search) Packet Packet flow Elasticsearch #1 document Netflow Exporter ・ ・ ・ Elasticsearch #2 Elasticsearch #3 document document Workers × Batch SizeWorkers Packet Packet flow flow flow
22.
改善対処1: 受信バッファの拡張 • OSのカーネルパラメータ(/etc/sysctl.d)をチューニングすることで受信バッファを拡張。 ※input
udpのreceive_buffer_bytesは利用せずにOS側で設定を実施 ※net.core.rmem_maxを2GBに出来ず、とりあえずで1GBまで拡張 No 設定項目 説明 デフォルト値 設定変更後 1 net.core.somaxconn 待機中の最大TCPコネクション数(個) 128 2,048 2 net.core.netdev_max_backlog パケット受信時にキューに接続できる最大パケット数(個) 1,000 2,048 3 net.core.rmem_max 受信ソケットバッファの最大サイズ(バイト) 212,992 1,073,741,824 4 net.core.rmem_default 受信ソケットバッファのデフォルトサイズ(バイト) 212,992 1,073,741,824 5 net.ipv4.udp_rmem_min UDP受信バッファの最小サイズ(バイト) 4,096 1,073,741,824 6 net.ipv4.udp_mem UDPの全ソケットのキューで利用可能なページ数(個) ※min、pressure、maxの順 769,677 1,026,238 1,539,354 1,610,612,736 3,221,225,472 6,442,450,944
23.
改善対処2: CPUリソースの拡張 • 受信バッファの拡張ではDropは収まらず、worker数等を拡張するためにCPUコア数を追加。 vCPU:4 vRAM:16GB vCPU:16 vRAM:32GB vCPU:32 vRAM:64GB No
設定ファイル 設定項目 第1形態 第2形態 第3形態 1 jvm.options -Xms 1g 15g 30g 2 jvm.options -Xmx 1g 15g 30g 3 logstash.conf queue_size 2048 8192 16384 4 logstash.conf workers 4 16 32 5 logstash.yml pipeline.workers 4 16 32 6 logstash.yml pipeline.batch.size 125 1000 2000 【第1形態】 【第2形態】 【第3形態】
24.
【参考】CPU割り当て最大値 • 最近はあまり気にしたことがなかったので、念のため仕様も確認したがいらぬ心配だった(笑) 【参考URL】CentOSの製品仕様 https://wiki.centos.org/About/Product
25.
【参考】input udpの性能に影響する設定値 • OSに割り当てているCPUコア数に合わせてworkersを設定してinput処理性能を稼ぐ。 •
受信バッファやキューサイズはあくまでバースト性のある通信が流れてきた時の保険でしかない。 No 設定項目 説明 デフォルト値 1 buffer_size ネットワーク上を流れる1個のUDPパケットの最大読み取りサイズ(バイト) 65,536 2 queue_size メモリに保持できる未処理のUDPパケット数(パケット) ※メモリ上のキューから溢れるとパケットがドロップする 2,000 3 receive_buffer_bytes OSがUDPパケットを受信した時のソケット受信バッファのサイズ(バイト) ※デフォルトはOSの受信バッファサイズが適用される(net.core.rmem_max) - 4 workers パケットを処理するスレッド数(個) ※CPUコア数と合わせておく 2 【参考URL】Udp input plugin https://www.elastic.co/guide/en/logstash/current/plugins-inputs-udp.html
26.
【参考】pipelineの性能に影響する設定値 • Pipeline処理はworker数×Batchサイズで決まるが、大きくなるとJVMヒープ領域を食う。 • GCが頻繁に発生することでCPU性能が低下する場合は、JVMヒープ領域を拡張する必要がある。 【参考URL】logstash.yml https://www.elastic.co/guide/en/logstash/current/logstash-settings-file.html No
設定項目 説明 デフォルト値 1 pipeline.workers filter処理とoutput処理を並行して実行するスレッド数(個) ※OSに割り当てられたCPUコア数よりも多めに割り当てておくのが良い CPUコア数 2 pipeline.batch.size 各workerスレッドがinput処理から収集する最大イベント数(イベント) 125 3 pipeline.batch.delay input処理からfilter処理に引き渡すバッチ処理で待機する時間(ミリ秒) 50 4 queue.type filter処理前のイベントをキューイングするバッファ領域を指定 ※memoryはメモリ上、persistedはディスク上に保持 memory
27.
第2形態時点におけるLogstashの性能結果 【設定】 ・pipeline.workers:16 ・batch size:1,000 ・JVM Heap
(max):15g 【性能】 ・受信フロー数:4,500/s ・CPU使用率:92-94% ・System Load:25-30
28.
コア拡張(16→32)したLogstashの性能結果 【設定】 ・pipeline.workers:32 ・batch size:1,000 ・JVM Heap
(max):15g 【性能】 ・受信フロー数:8,000/s ・CPU使用率:85-90% ・System Load:35-40
29.
BatchSizeを拡張したLogstashの性能結果 【設定】 ・pipeline.workers:32 ・batch size:2,000 ・JVM Heap
(max):15g 【性能】 ・受信フロー数:9,000/s ・CPU使用率:85-90% ・System Load:40-45
30.
【参考】Monitoring画面の説明 codec処理後のfilter処理前の 秒間イベント数(=ドキュメント数) output pluginsが出力した 秒間イベント数(=ドキュメント数) filter処理による処理遅延時間 (=ミリ秒) 全てのLogstashコア、input、filter outputで利用しているJVM Heap使用率 OSが認識しているLogstashプロセスで 使用しているCPU使用率 OSが認識しているLogstashプロセスで 使用しているLoad
Average
31.
改善対処3: pipelineの分割 • リソース追加でも収まらず、multipipeline機能を用いて、netflowとsflowを分割。 ※ここまでNetflowの説明しかしていませんが、実はsflowの収集も実施しています...(笑) -
pipeline.id: netflow path.config: "/etc/logstash/conf.d/netflow/*.conf" pipeline.workers: 32 - pipeline.id: sflow path.config: "/etc/logstash/conf.d/sflow/*.conf" pipeline.workers: 32 【pipeline.yml】 【ポイント】 pipeline.workersをpipeline単位に分割することで より並列分散処理することが出来ると期待するも取り込むフロー数に大きな変化は無し 【参考URL】Multiple Pipelines https://www.elastic.co/guide/en/logstash/current/multiple-pipelines.html
32.
ちなみに、filter処理を全て外してみると... • Event Latencyはほぼ0msとなり、Received
Rateが約倍増の15,000/sまで上昇した。
33.
今度はダメ元でQueueing方式を変更してみると... • Persistent Queueに変更したことでディスクへの書き込みIO待ちのような結果となった。 【参考URL】Persistent
Queues https://www.elastic.co/guide/en/logstash/current/persistent-queues.html 【結果】 ・CPU使用率は65-80を大きくバタついた ・SystemLoadは25-45を大きくバタついた →フロー取り込み量は改善せずにDrop多発
34.
ダメ押しで、outputの設定変更を試してみるが... • output elasticsearchの出力先を絞ることでLogstashのCPU負荷を上げられるか試した。 Elasticsearch#1 Elasticsearch#2 Elasticsearch#3 output
{ elasticsearch { # hosts => [“192.168.0.1:9200”,”192.168.0.2:9200”,”192.168.0.3:9200” ] hosts => “192.168.0.1:9200” } } 192.168.0.1 192.168.0.2 192.168.0.3 【参考URL】Elasticsearch output plugin https://www.elastic.co/guide/en/logstash/current/plugins-outputs-elasticsearch.html#plugins-outputs-elasticsearch-hosts 【結果】 CPU使用率やSystemLoadは変化せず...
35.
改善対処4: Logstashノードの追加 • 色々試したが1台のLogstashで捌くことに限界を感じ、3ノード追加のスケールアウト構成とした。 ※Netflow
Exporter側で送信先のIPアドレスを変更することでバランス良く振り分ける 【1号機】 ・vcPU:32 ・vRAM:64GB 【2号機】 ・vcPU:32 ・vRAM:64GB 【3号機】 ・vcPU:32 ・vRAM:64GB 【4号機】 ・vcPU:32 ・vRAM:64GB ノード追加 NetFlow Exporter
36.
最終的な構成 • 以下の全コンポーネントをNutanix上に構築することで何とかフローを取り切る。 ※Exporterの機種によって、Logstashで受信出来るフロー量にも違いがあることが分かった 【1号機】 ・vCPU:32 ・vRAM:64GB 【2号機】 ・vCPU:32 ・vRAM:64GB 【3号機】 ・vCPU:32 ・vRAM:64GB 【4号機】 ・vCPU:32 ・vRAM:64GB NetFlow Exporter Elasticsearch#1 Elasticsearch#2 Elasticsearch#3 Elasticsearch
Cluster 【1号機】 ・vCPU:6 ・vRAM:64GB ・vDisk:2TB 【2号機】 ・vCPU:6 ・vRAM:64GB ・vDisk:2TB 【3号機】 ・vCPU:6 ・vRAM:64GB ・vDisk:2TB 合計:4,000fps 合計:9,000fps 合計:4,000fps 合計:3,500fps 総合計:20,500fps CPU使用率:75% SystemLoad:20 CPU使用率:85% SystemLoad:30 CPU使用率:85% SystemLoad:35 CPU使用率:35% SystemLoad:10
37.
Elasticsearchの蓄積データ量 • 1週間分の蓄積データ量(Replica込み)と平日のIndexサイズ(日次)は以下の通り。 No Index名
Document Count Data(GB) 対象期間 1 logstash-2018.08.06 1.1b(11億) 635.2 8/6(月)9:00-8/7(火)8:59 2 logstash-2018.08.07 1.1b(11億) 600.1 8/7(火)9:00-8/8(水)8:59 3 logstash-2018.08.08 1.1b(11億) 616.1 8/8(水)9:00-8/9(木)8:59 4 logstash-2018.08.09 1.1b(11億) 629.1 8/9(木)9:00-8/10(金)8:59 5 logstash-2018.08.10 1.0b(10億) 556.5 8/10(金)9:00-8/11(土)8:59
38.
まとめ ✓ やってみないとどこにボトルネックが来るか見えないツラミ ⇒大量フローがないと性能検証が出来ないので、本番環境でないと見えてこない ⇒Netflowを吐く機種によってもLogstashに与える性能負荷が違った ⇒Logstashのどの処理でスタックしているのか切り分けが難しかった ✓ SystemLoad30を超えるとDrop始める傾向があった ⇒workersは上限値がないので、CPUコアの割り当てすれば性能出るはず... ⇒workers32くらいまでは性能向上したが、48では性能に変化がなかった ⇒filter処理によるCPU負荷が全体のパフォーマンスを大きく左右する ✓
トラブルシュートしながらのチューニングだったので... ⇒正直がこれが正解だったのか... ⇒Exporter毎にLogstashノードを分けておけば良かったと反省
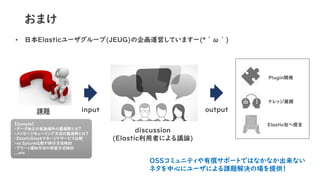
39.
おまけ • 日本Elasticユーザグループ(JEUG)の企画運営していますー(*´ω`) input課題 【Sample】 ・データ加工の実施場所の最適解とは? ・メッセージキューイング方式の最適解とは? ・ElasticStackマネージドサービス比較 ・vs Splunk比較や移行方法検討 ・アラート通知方法の実装方式検討 ...etc output discussion (Elastic利用者による議論) Plugin開発 ナレッジ展開 Elastic社へ提言 OSSコミュニティや有償サポートではなかなか出来ない ネタを中心にユーザによる課題解決の場を提供!
Download











![このような通信分析環境を構築してみた
• Netflow CollectorをElastic Stackで構築し、約20,000/秒のフローの取り込みを行う。
※構築時は最終的にどのくらいのフロー数が流れてくるか読めていなかった...(泣)
NetFlow Exporter
Netflow Collector
Netflow
(UDP)
ここの話
input {
udp {
port => "2055"
workers => “4"
queue_size => "2048“
codec => netflow {
versions => [5,9,10]
}
}
}](https://image.slidesharecdn.com/elasticsearchmeetuplogstash-181121115048/85/26-Elasticsearch-Logstash-12-320.jpg)





















![ダメ押しで、outputの設定変更を試してみるが...
• output elasticsearchの出力先を絞ることでLogstashのCPU負荷を上げられるか試した。
Elasticsearch#1
Elasticsearch#2
Elasticsearch#3
output {
elasticsearch {
# hosts => [“192.168.0.1:9200”,”192.168.0.2:9200”,”192.168.0.3:9200” ]
hosts => “192.168.0.1:9200”
}
}
192.168.0.1
192.168.0.2
192.168.0.3
【参考URL】Elasticsearch output plugin
https://www.elastic.co/guide/en/logstash/current/plugins-outputs-elasticsearch.html#plugins-outputs-elasticsearch-hosts
【結果】
CPU使用率やSystemLoadは変化せず...](https://image.slidesharecdn.com/elasticsearchmeetuplogstash-181121115048/85/26-Elasticsearch-Logstash-34-320.jpg)