Downloaded 60 times








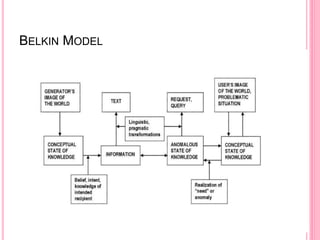












This document summarizes Nicholas Belkin's theory of anomalous state of knowledge (ASK), which proposes that information needs arise from gaps or anomalies in a person's knowledge. It compares the traditional information retrieval model to Belkin's ASK model, which recognizes that users may not be able to precisely specify their information need when they have an incomplete understanding. The document also outlines some applications of anomaly detection and discusses implications of Belkin's theory, such as the need to represent information needs differently than the best-match approach used by most search systems.























































































