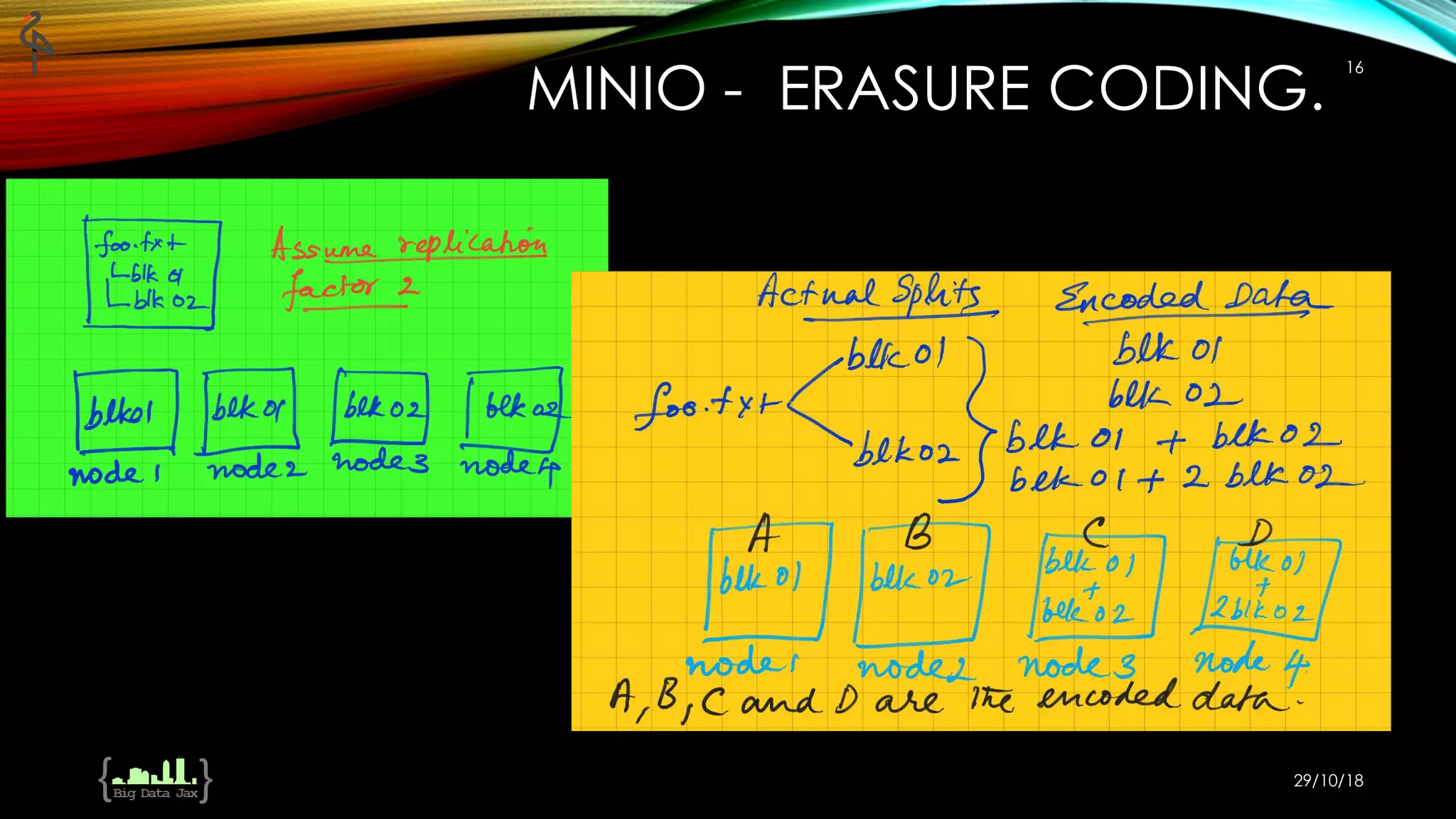
The document discusses the integration of MinIO, Spark, and a unified data architecture to build modern data lakes, focusing on challenges with traditional data processing methods like MapReduce and the inefficiencies of block-based storage systems. It emphasizes the advantages of object storage, such as erasure coding for data protection and scalability, efficiency improvements, and cost-effectiveness compared to HDFS. The document presents a comprehensive overview of the benefits and features of using MinIO, alongside practical use cases with other data processing tools.