Downloaded 14 times






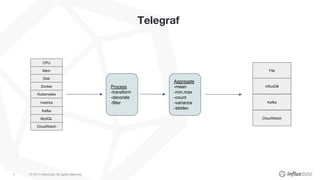





















The document provides a comprehensive guide on optimizing the TICK stack, focusing on aspects such as hardware utilization, schema design, and query performance. Key points emphasize effective resource management, the importance of shard configuration, and best practices for writing data to InfluxDB using line protocol. Recommendations are made for tuning parameters to enhance both write and query performance while minimizing cardinality issues.


































![Paul Dix [InfluxData] The Journey of InfluxDB | InfluxDays 2022](https://cdn.slidesharecdn.com/ss_thumbnails/2022-11-02influxdays-journeyofinfluxdb-221020214252-ff7c76c5-thumbnail.jpg?width=640&height=640&fit=bounds)





![Sam Dillard [InfluxData] | Performance Optimization in InfluxDB | InfluxDays...](https://cdn.slidesharecdn.com/ss_thumbnails/influxdaysoptimizinginfluxdbperformancegreentheme-200622220133-thumbnail.jpg?width=640&height=640&fit=bounds)



![Tim Hall [InfluxData] | InfluxDB Roadmap | InfluxDays Virtual Experience Lond...](https://cdn.slidesharecdn.com/ss_thumbnails/influxdb-roadmap-tim-hall-200623173849-thumbnail.jpg?width=640&height=640&fit=bounds)








![Ward Bowman [PTC] | ThingWorx Long-Term Data Storage with InfluxDB | InfluxDa...](https://cdn.slidesharecdn.com/ss_thumbnails/influxdays-221027185325-5d2f430b-thumbnail.jpg?width=640&height=640&fit=bounds)










![Steinkamp, Clifford [InfluxData] | Welcome to InfluxDays 2022 - Day 2 | Influ...](https://cdn.slidesharecdn.com/ss_thumbnails/influxdays2022welcometoday2-221020215815-c8463942-thumbnail.jpg?width=640&height=640&fit=bounds)
![Steinkamp, Clifford [InfluxData] | Closing Thoughts | InfluxDays 2022](https://cdn.slidesharecdn.com/ss_thumbnails/influxdays2022closingthoughtsday2-221020220104-abde55ea-thumbnail.jpg?width=640&height=640&fit=bounds)
![Steinkamp, Clifford [InfluxData] | Closing Thoughts Day 1 | InfluxDays 2022](https://cdn.slidesharecdn.com/ss_thumbnails/influxdays2022closingthoughtsday1-221020215301-f8040e1f-thumbnail.jpg?width=640&height=640&fit=bounds)
![Scott Anderson [InfluxData] | New & Upcoming Flux Features | InfluxDays 2022](https://cdn.slidesharecdn.com/ss_thumbnails/influxdays2022-fluxupdates-scott-221021210238-9d323cba-thumbnail.jpg?width=640&height=640&fit=bounds)











