Download to read offline



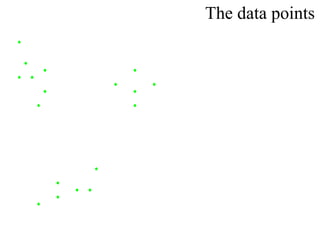

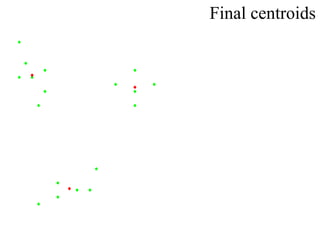

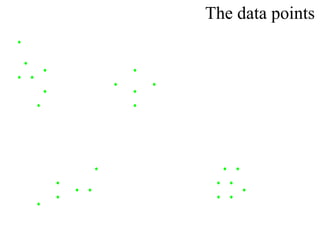
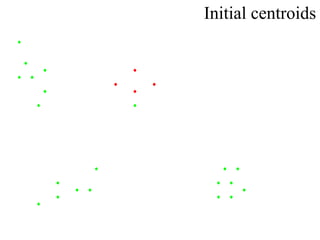
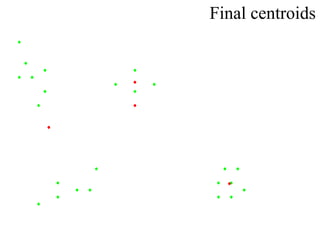




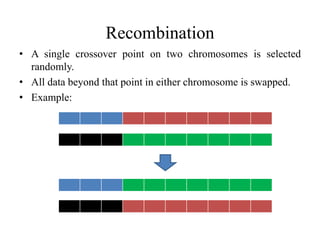





This document proposes using a genetic algorithm to improve the accuracy of k-means clustering by selecting better initial centroids. It describes generating an initial population of random centroids, evaluating their fitness using a k-means objective function, and evolving the population over generations using selection, crossover and mutation to converge on high-fitness initial centroids. Testing showed this genetic k-means approach produced more accurate and globally optimized clustering results than random initial centroids.



























































![Assignment for Factory Method Design Pattern in C# [ANSWERS]](https://cdn.slidesharecdn.com/ss_thumbnails/assingment1answers-200420114633-thumbnail.jpg?width=640&height=640&fit=bounds)





















