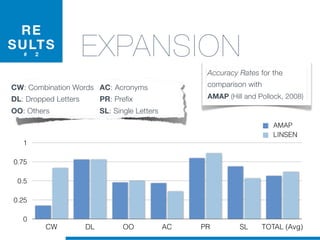
Downloaded 58 times




























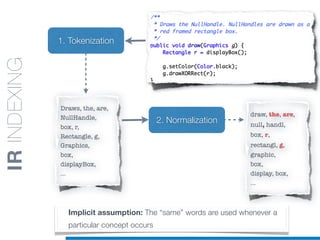



















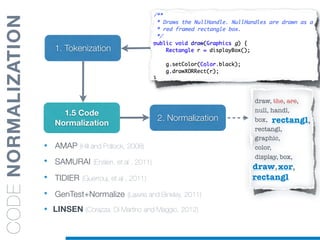
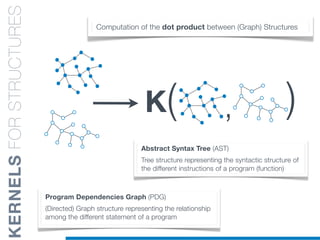
![1. Tokenization
2. Normalization
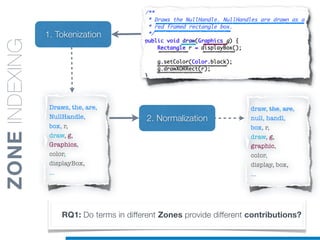
1.5 Identifier
Splitting
• Splitting algorithms based on naming conventions
• camelCase Splitter: r’(?<=!^)([A-Z][a-z]+)’
• NullHandle ==> Null | Handle
• displayBox ==> display | Box
draw, the, are,
box, r,
rectangl, g,
graphic,
color,
....
STATEOFTHEARTTOOLS
display, box
null, handl](https://image.slidesharecdn.com/ml4sedefense-130627044912-phpapp02/85/Improving-Software-Maintenance-using-Unsupervised-Machine-Learning-techniques-64-320.jpg)
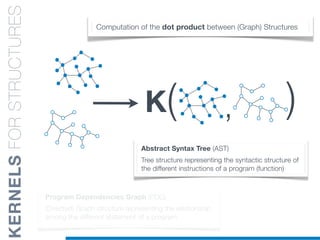
![1. Tokenization
2. Normalization
1.5 Identifier
Splitting
• Splitting algorithms based on naming conventions
• camelCase Splitter: r’(?<=!^)([A-Z][a-z]+)’
• NullHandle ==> Null | Handle
• displayBox ==> display | Box
draw, the, are,
box, r,
rectangl, g,
graphic,
color,
....
STATEOFTHEARTTOOLS
display, box
null, handl](https://image.slidesharecdn.com/ml4sedefense-130627044912-phpapp02/85/Improving-Software-Maintenance-using-Unsupervised-Machine-Learning-techniques-65-320.jpg)
![1. Tokenization
2. Normalization
1.5 Identifier
Splitting
• Splitting algorithms based on naming conventions
• camelCase Splitter: r’(?<=!^)([A-Z][a-z]+)’
• NullHandle ==> Null | Handle
draw, the, are,
box, r,
rectangl, g,
graphic,
color,
....
STATEOFTHEARTTOOLS
display, box
null, handl](https://image.slidesharecdn.com/ml4sedefense-130627044912-phpapp02/85/Improving-Software-Maintenance-using-Unsupervised-Machine-Learning-techniques-66-320.jpg)
![1. Tokenization
2. Normalization
1.5 Identifier
Splitting
• Splitting algorithms based on naming conventions
• camelCase Splitter: r’(?<=!^)([A-Z][a-z]+)’
• NullHandle ==> Null | Handle
• displayBox ==> display | Box
draw, the, are,
box, r,
rectangl, g,
graphic,
color,
....
STATEOFTHEARTTOOLS
null, handl
display, box](https://image.slidesharecdn.com/ml4sedefense-130627044912-phpapp02/85/Improving-Software-Maintenance-using-Unsupervised-Machine-Learning-techniques-67-320.jpg)
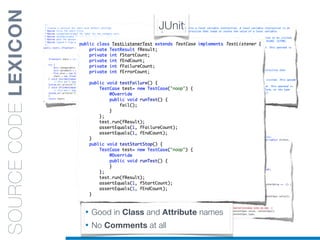
![• camelCase Splitter: r’(?<=!^)([A-Z][a-z]+)’
IDENTIFIERSSPLITTING](https://image.slidesharecdn.com/ml4sedefense-130627044912-phpapp02/85/Improving-Software-Maintenance-using-Unsupervised-Machine-Learning-techniques-68-320.jpg)
![• camelCase Splitter: r’(?<=!^)([A-Z][a-z]+)’
• drawXORRect ==> drawXOR | Rect
IDENTIFIERSSPLITTING](https://image.slidesharecdn.com/ml4sedefense-130627044912-phpapp02/85/Improving-Software-Maintenance-using-Unsupervised-Machine-Learning-techniques-69-320.jpg)
![• camelCase Splitter: r’(?<=!^)([A-Z][a-z]+)’
• drawXORRect ==> drawXOR | Rect
• drawxorrect ==> NO SPLIT
Splitting algorithms based on naming conventions
are not robust enough
IDENTIFIERSSPLITTING](https://image.slidesharecdn.com/ml4sedefense-130627044912-phpapp02/85/Improving-Software-Maintenance-using-Unsupervised-Machine-Learning-techniques-70-320.jpg)





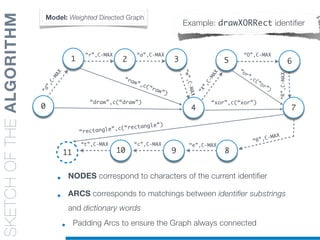
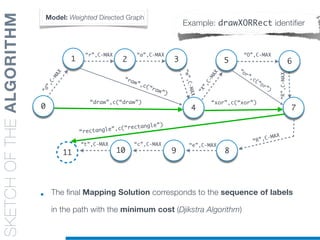
![SKETCHOFTHEALGORITHM
• Every Arc is Labelled with the corresponding dictionary word
• Weights represent the “cost” of each matching
• Cost function [c(“word”)] favors longest words and domain-
related information
Model: Weighted Directed Graph
Example: drawXORRect identifier
0
11
1
9
4
“r”,C-MAX
“d”,C-MAX
5
7
8
2
“R”,C-MAX
6
“a”,C-MAX
3
“w”,C-MAX
“X”,C-MAX
“O”,C-MAX
“e”,C-MAX
10
“c”,C-MAX“t”,C-MAX
“raw”,c(“raw”)
“draw”,c(“draw”)
“or”,c(“or”)
“xor”,c(“xor”)
“rectangle”,c(“rectangle”)
“R”,C-MAX](https://image.slidesharecdn.com/ml4sedefense-130627044912-phpapp02/85/Improving-Software-Maintenance-using-Unsupervised-Machine-Learning-techniques-81-320.jpg)












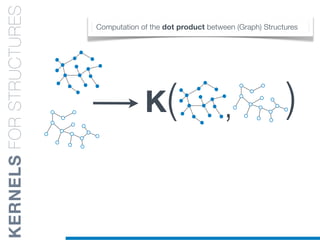

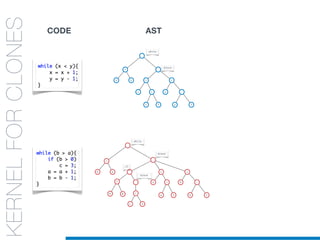
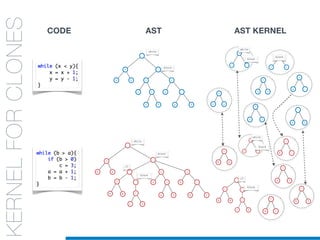
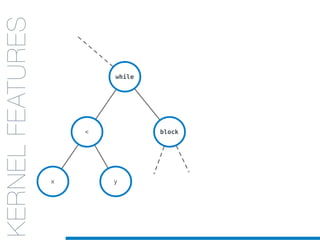
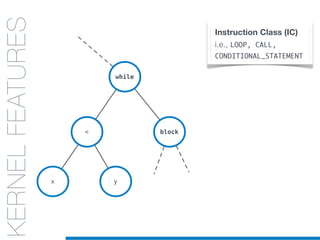
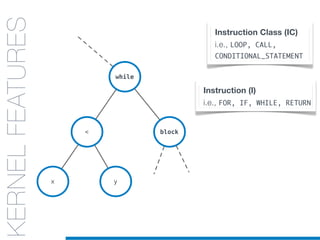
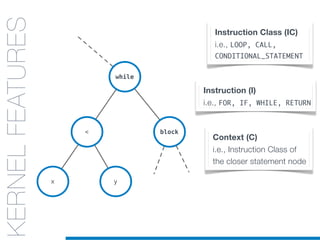
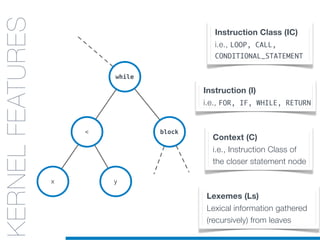
![while
block<
x y
KERNELS
FOR CODE
STRUCTURES:
AST
KERNELFEATURES
IC = Conditional-Expr
I = Less-operator
C = Loop
Ls= [x,y]
IC = Loop
I = while-loop
C = Function-Body
Ls= [x, y]
Instruction Class (IC)
i.e., LOOP, CALL,
CONDITIONAL_STATEMENT
Instruction (I)
i.e., FOR, IF, WHILE, RETURN
Context (C)
i.e., Instruction Class of
the closer statement node
Lexemes (Ls)
Lexical information gathered
(recursively) from leaves
IC = Block
I = while-body
C = Loop
Ls= [ x ]](https://image.slidesharecdn.com/ml4sedefense-130627044912-phpapp02/85/Improving-Software-Maintenance-using-Unsupervised-Machine-Learning-techniques-110-320.jpg)









Il dottorato di Valerio Maggio si concentra sull'apprendimento automatico non supervisionato per la manutenzione del software, proponendo soluzioni per l'analisi automatica del codice sorgente e il supporto alle attività di manutenzione. La tesi affronta questioni cruciali come la rimodularizzazione del software, la normalizzazione del codice sorgente e la rilevazione dei clone, evidenziando l'utilizzo di tecniche machine learning e recupero informatico. La ricerca mira a migliorare l'efficienza e l'efficacia della manutenzione del software, che rappresenta una delle fasi più costose e complesse nel ciclo di vita del software.
























































































