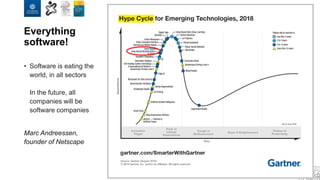
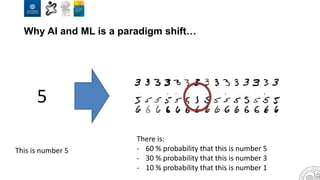
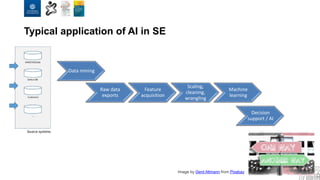
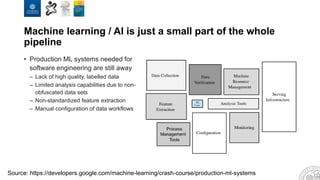
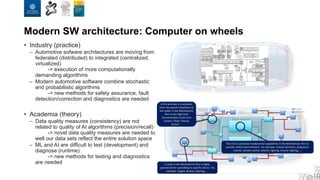
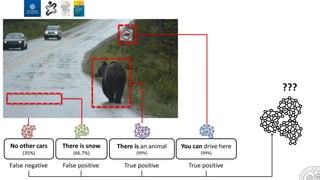
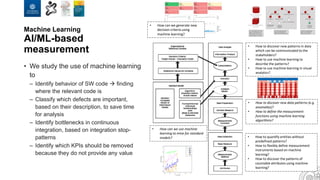
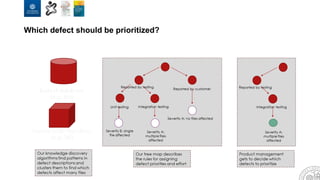
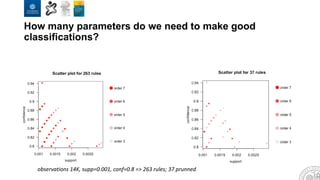
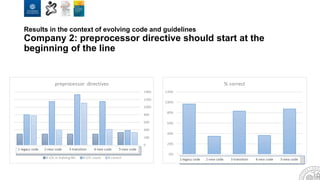
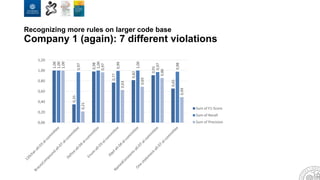
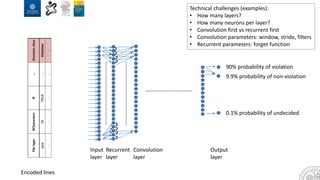
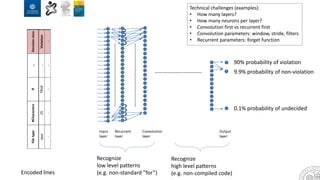
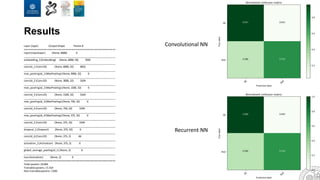
The document discusses the integration of artificial intelligence and machine learning in software engineering, emphasizing the transition to data-driven development and the challenges posed by high-quality data requirements. It highlights the need for new architectural designs and testing methods in automotive software, as well as the potential for machine learning to enhance software quality assessments and defect prioritization. The author, a professor at the University of Gothenburg, draws on industry collaboration and research to illustrate the evolving landscape of software engineering amid digital transformation.






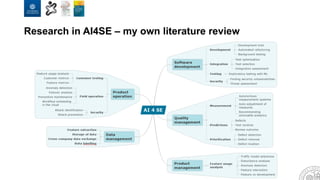
![Data source ML Methods Difficulty level ROI/Impact Examples of visualization
Defect prediction - JIRA
- ClearQuest
- BugZilla
- Regression
[Excel, R, Weka, Python]
- Classification
[R, Weka, Python]
Low High/decision support
CCFlex ML metrics - Git
- SVN
- ClearCase
- Decision trees
[CCFlex, R, Weka, Python]
Medium Medium/data collection
Test optimization - Test tools
- Portals
- Test DBs
- Classification
[R, Weka, Python]
- Cluster analysis
[R, Weka, Python]
- Reinforced learning
[R, Weka, Python]
High High/development practices
Customer data analysis - Field data DB - Classification
[R, Weka, Python]
- Cluster analysis
[R, Weka, Python]
- Decision trees
[R, Weka, Python]
High High/decision support
KPI trend analysis - Metrics DB - Classification
[R, Weka, Python]
- Regression
[R, Weka, Python]
Medium Medium/dissemination
Requirements quality
assessment
- Requirements DB
- ReqPro
- DOORS
- Classification
[R, Weka, Python]
- Clustering
[R, Weka, Python]
Low Medium/development practices
Dashboard support - Metrics DB - Classification
[R, Weka, Python]
- Time series
[R, Weka, Python]
Low Medium/decision support
Defect classification - JIRA
- ClearQuest
- Bugzilla
- Decision trees
[R, Weka, Python]
- Clustering
[R, Weka, Python]
Medium Medium/development practices
Speed / CI - Gerrit
- Jenkins
- Deep learning
[R, Weka, Python]
- Decision trees
[R, Weka, Python]
High Medium/development practices](https://image.slidesharecdn.com/2019ai4sekeynotev02-190902092943/85/AI-for-Software-Engineering-10-320.jpg)












































































![[DSC Europe 25] Milos Belcevic - Product Professional's Journey to Full-Stack...](https://cdn.slidesharecdn.com/ss_thumbnails/1zovd6fgsycdg4wvgvls-milos-belcevic-product-professionals-journey-to-full-stack-product-developer-260123083019-d993120d-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Predrag Maletic - Scaling AI in Banking – Our Strategic Journ...](https://cdn.slidesharecdn.com/ss_thumbnails/qu2onv0aruwlvqtygmxx-predrag-maletic-scaling-ai-in-banking-260123083019-6cf1da1d-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Raul Cruz Bonilla - Harnessing GEN AI in Fashion, Luxury and ...](https://cdn.slidesharecdn.com/ss_thumbnails/me7nvup5thwqzwzblbvw-raul-cruz-harnessing-ai-en-luxury-260123083019-32ac5a43-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Josip Saban - Career building for data professionals.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/zroflcttkm1vmli0txea-josip-saban-career-building-for-data-professionals-260123083019-587cdb8c-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DSC Europe 25] Ekaterina Bubenko - Behind the Curtain: How Data Roles Collab...](https://cdn.slidesharecdn.com/ss_thumbnails/anmv6x8dstqbbzchoklr-ekaterina-bubenko-behind-the-curtain-how-data-roles-collaborate-in-the-ai-era-a-260123083019-4b252ec7-thumbnail.jpg?width=640&height=640&fit=bounds)
