Download as PDF, PPTX

![SOFTWARE MAINTENANCE
“A software system must be continuously
adapted during its overall life cycle or it
progressively becomes less satisfactory”
(cit. Lehman’s Law of Software Evolution)
• Software Maintenance is one of the most
expensive and time consuming phase of the
whole life cycle
• Anticipating the Maintenance operations
reduces the cost
• 85%-90% of the total cost are related to the
effort necessary to comprehend the system
and its source code [Erlikh, 2000]](https://image.slidesharecdn.com/jimse2012final-130627043958-phpapp02/75/Machine-Learning-for-Software-Maintainability-2-2048.jpg)
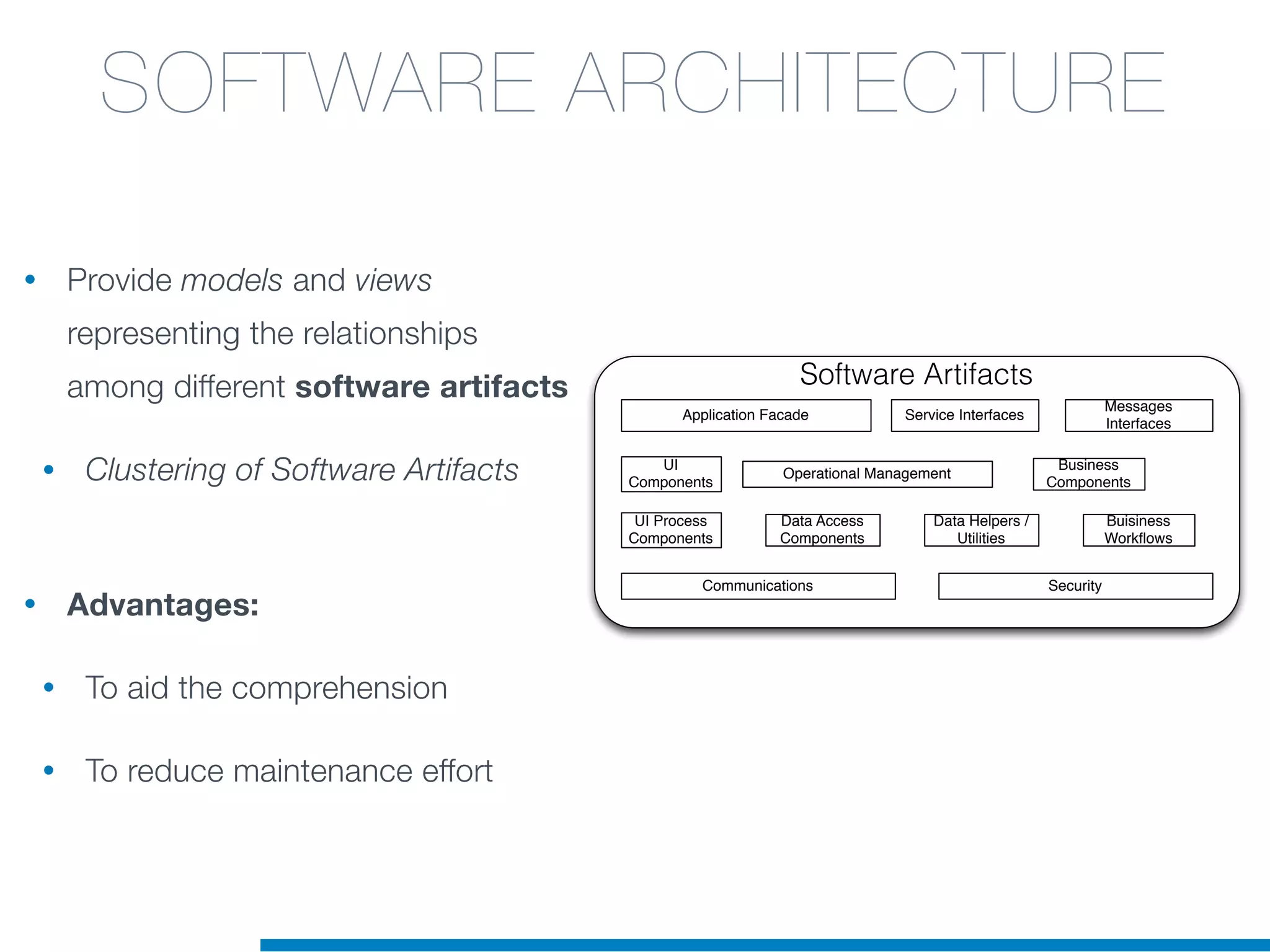
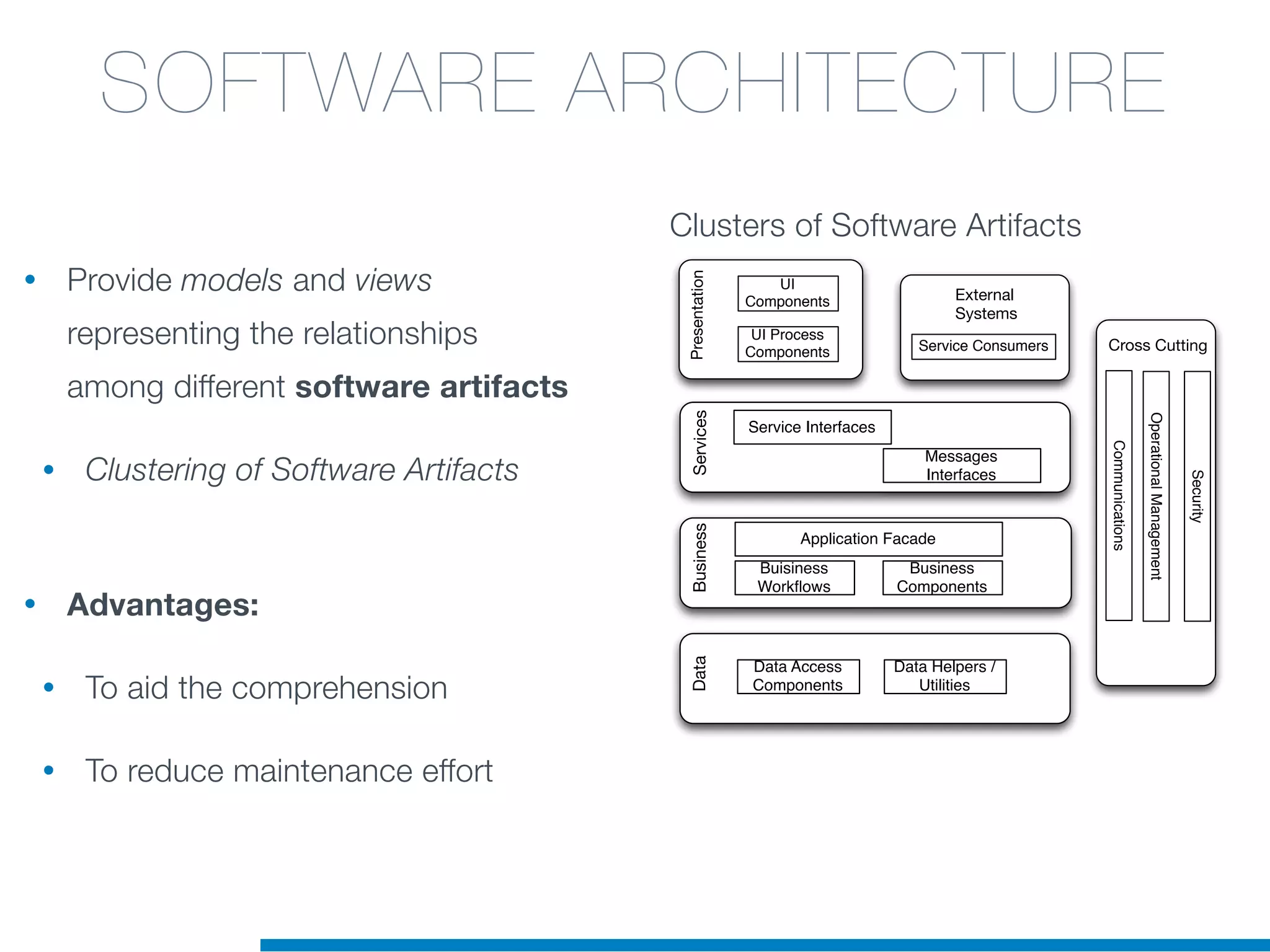
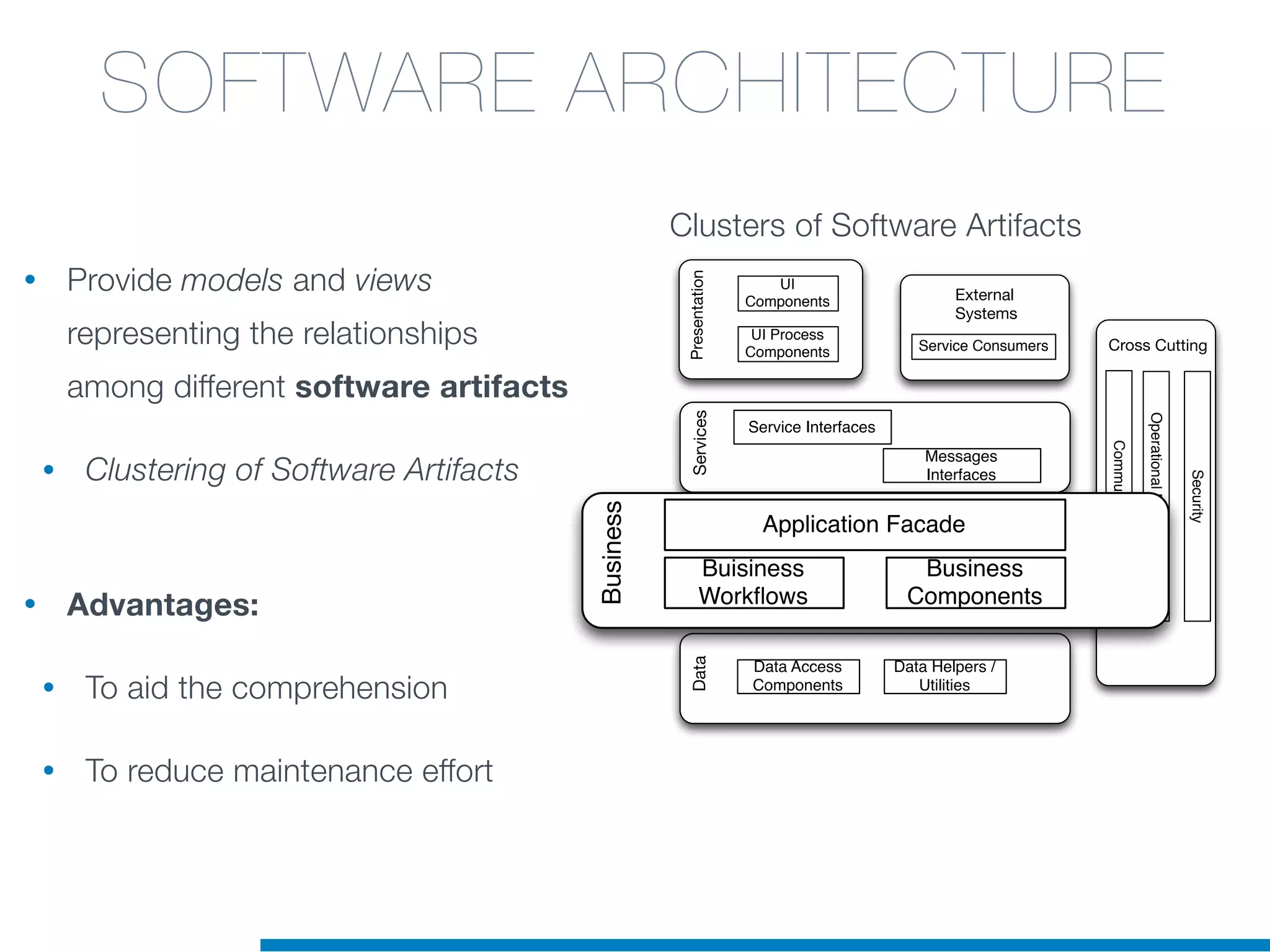
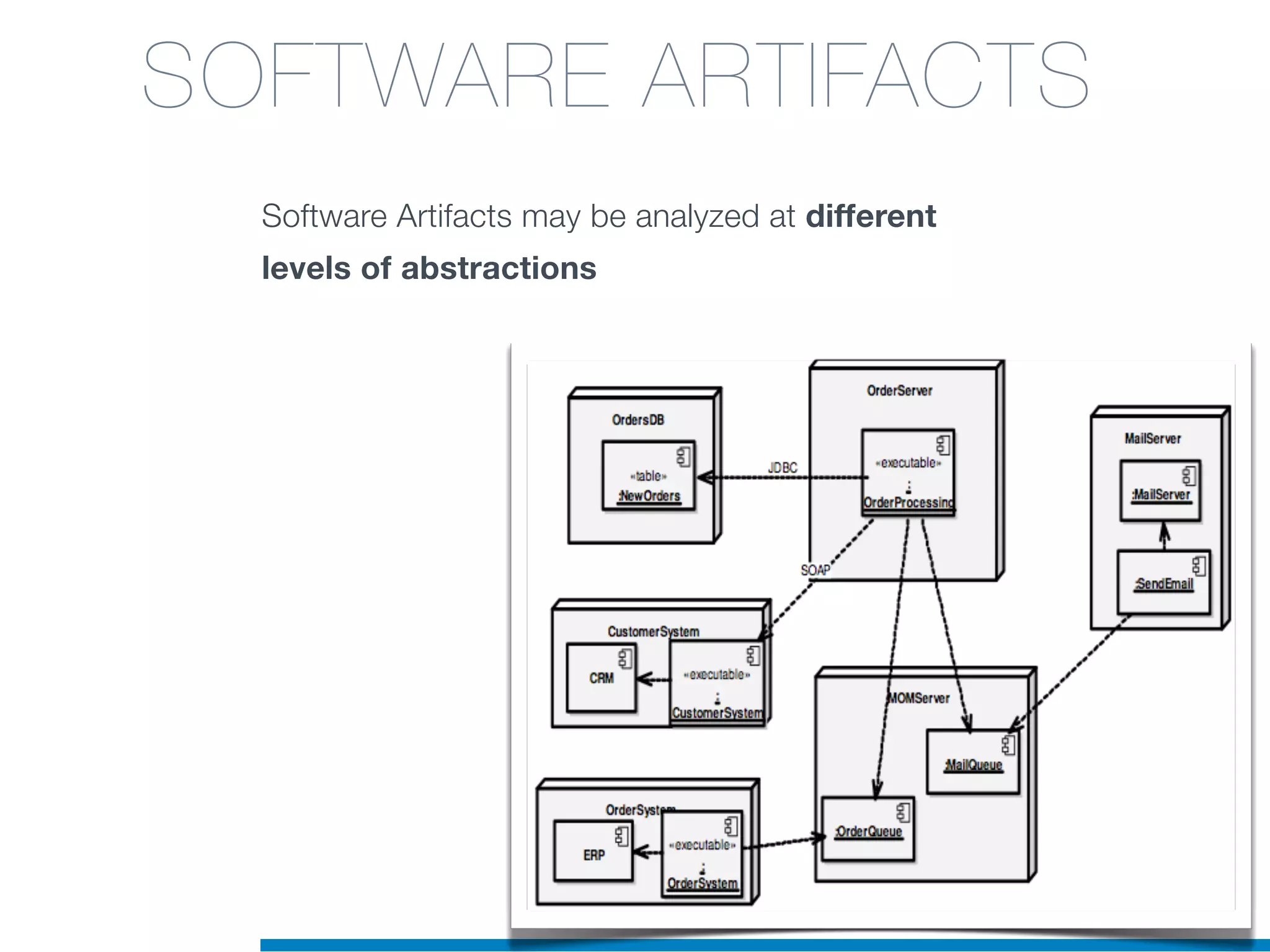



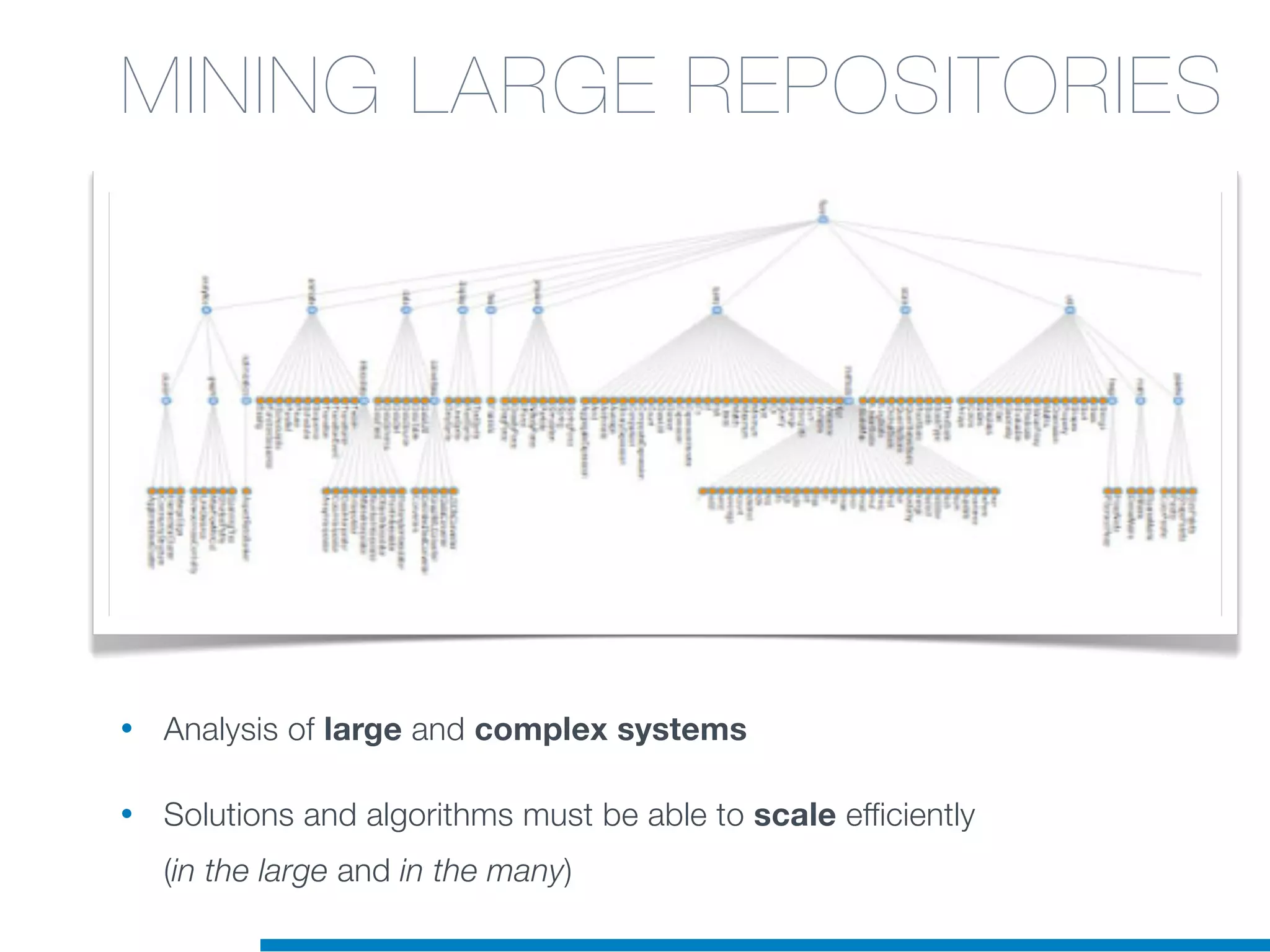



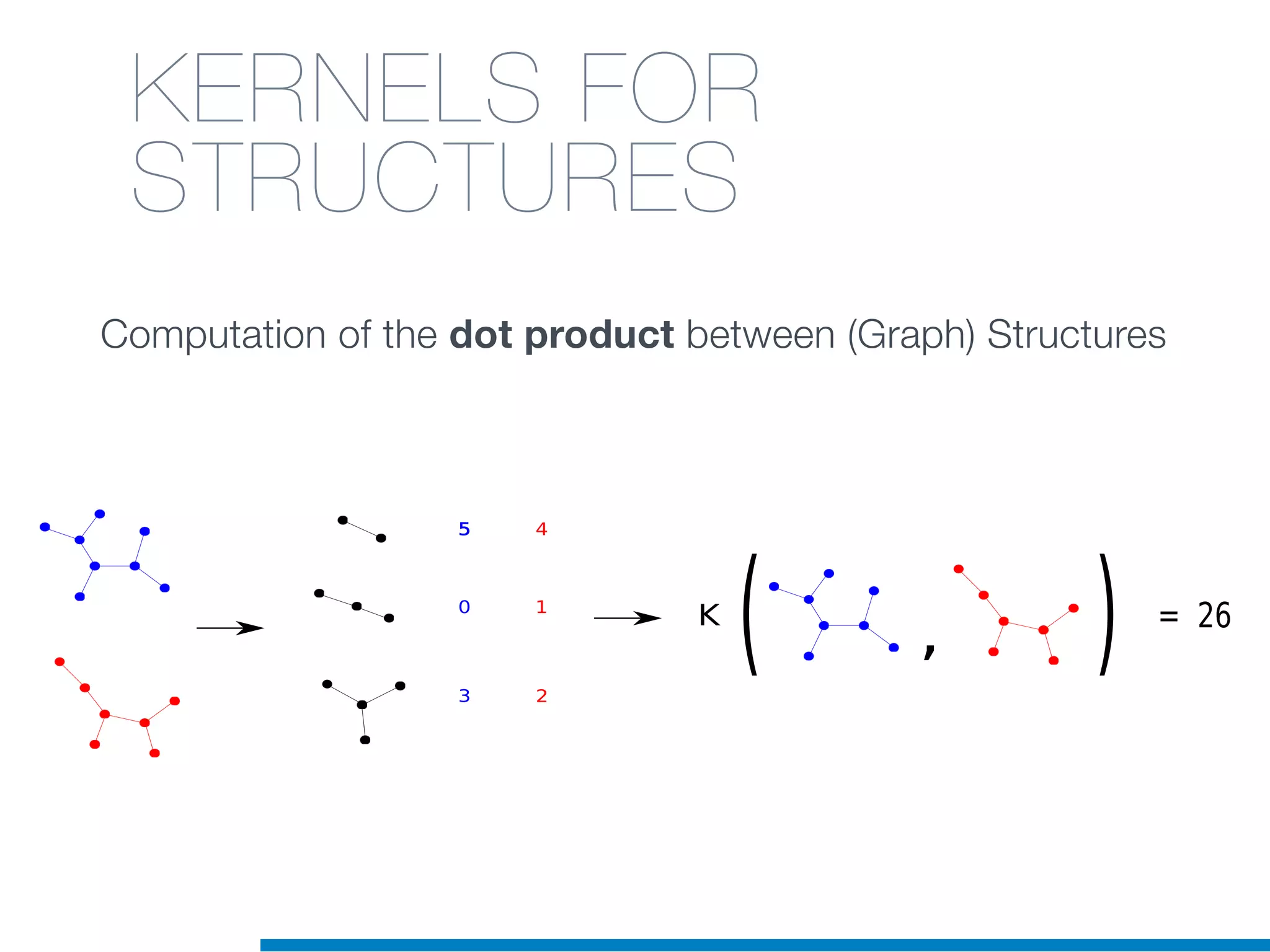
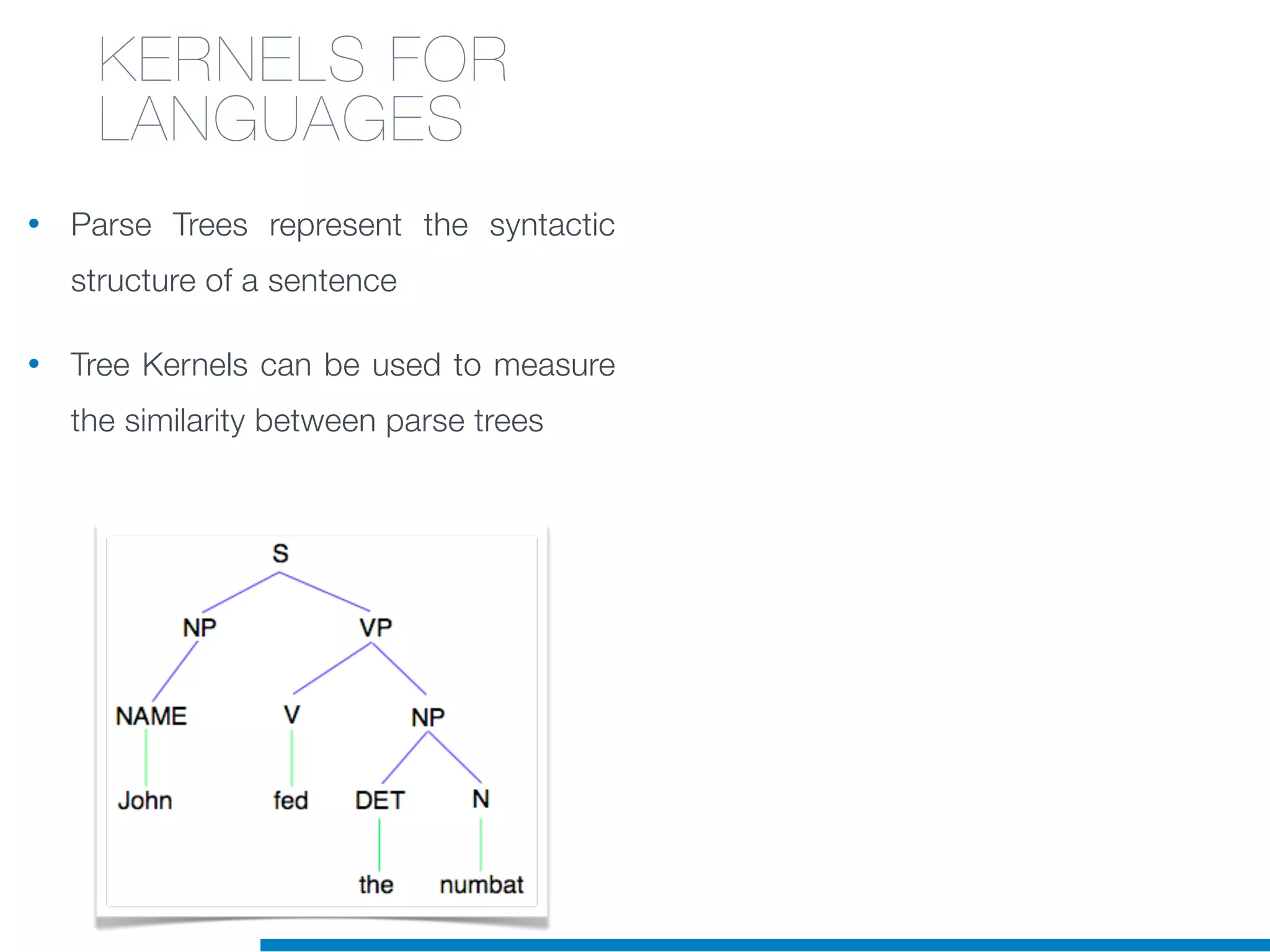
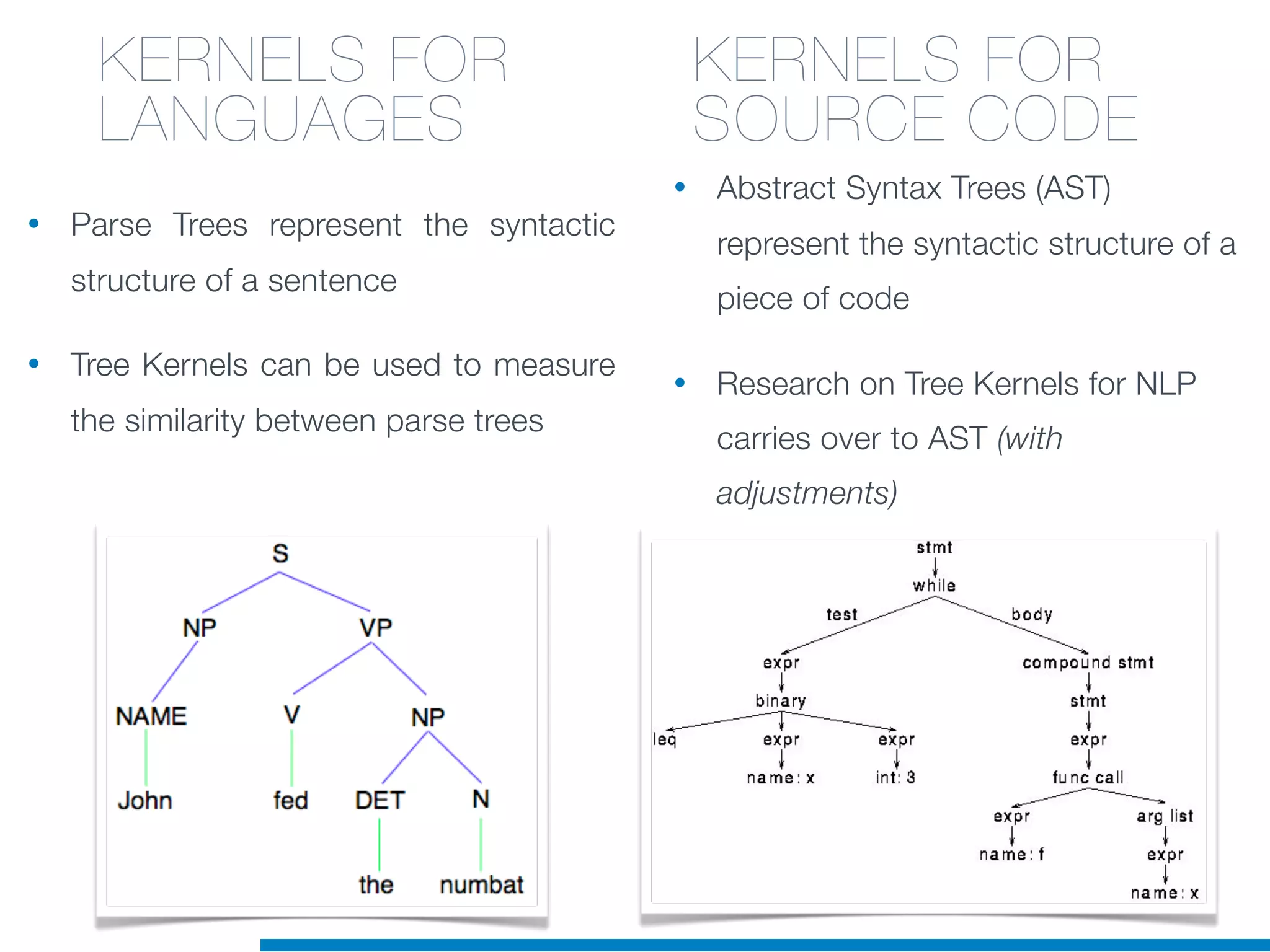
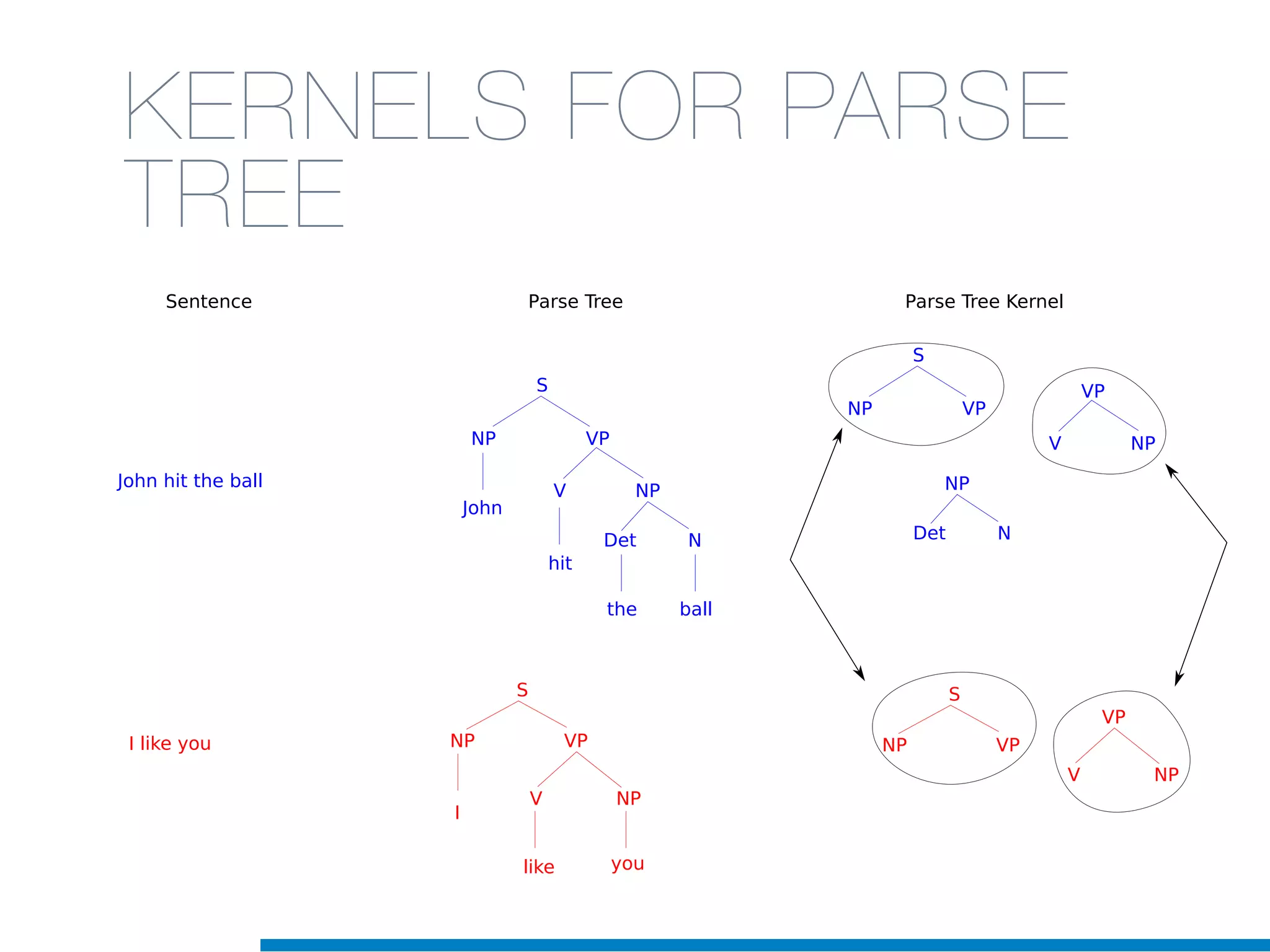
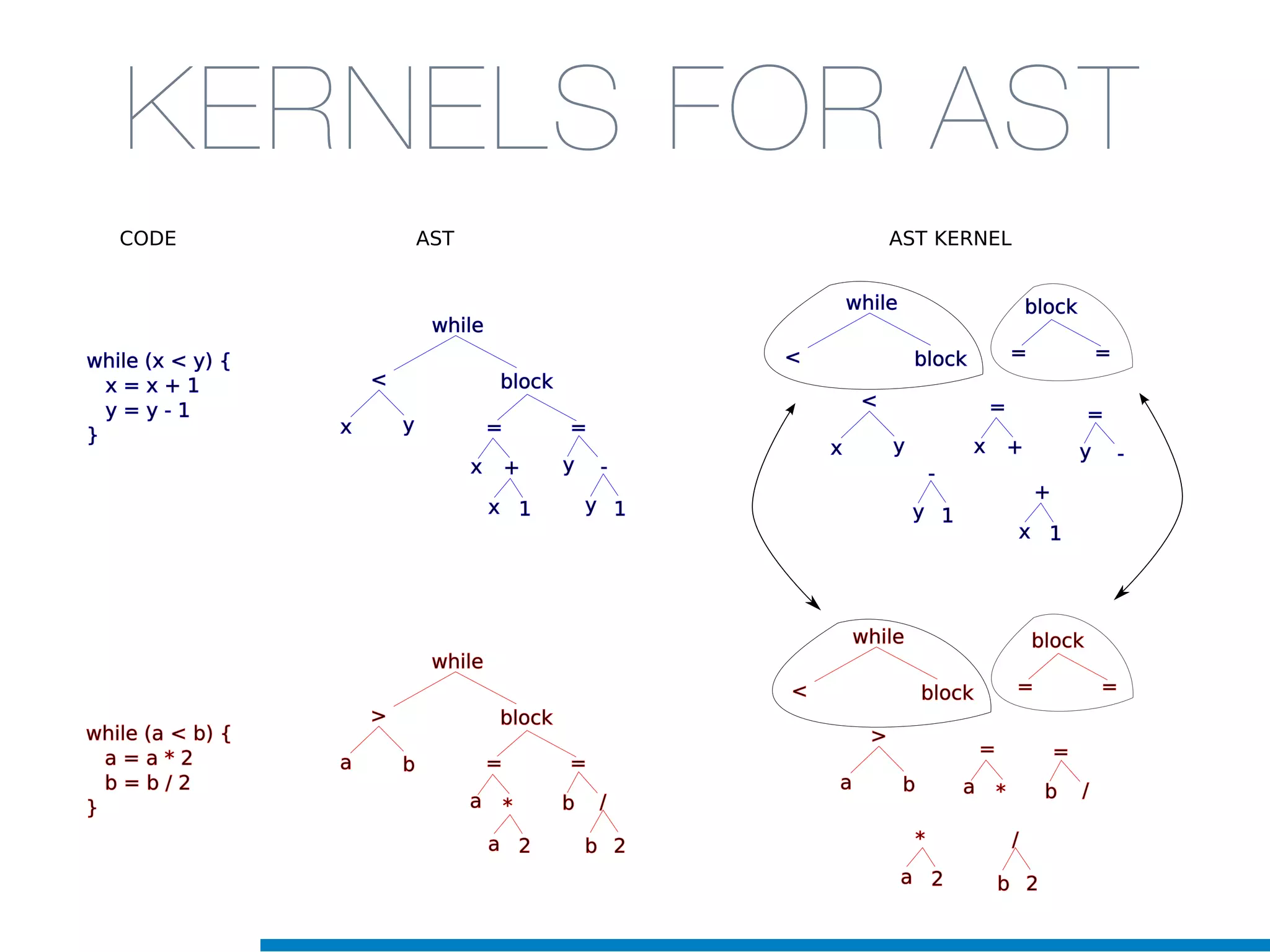


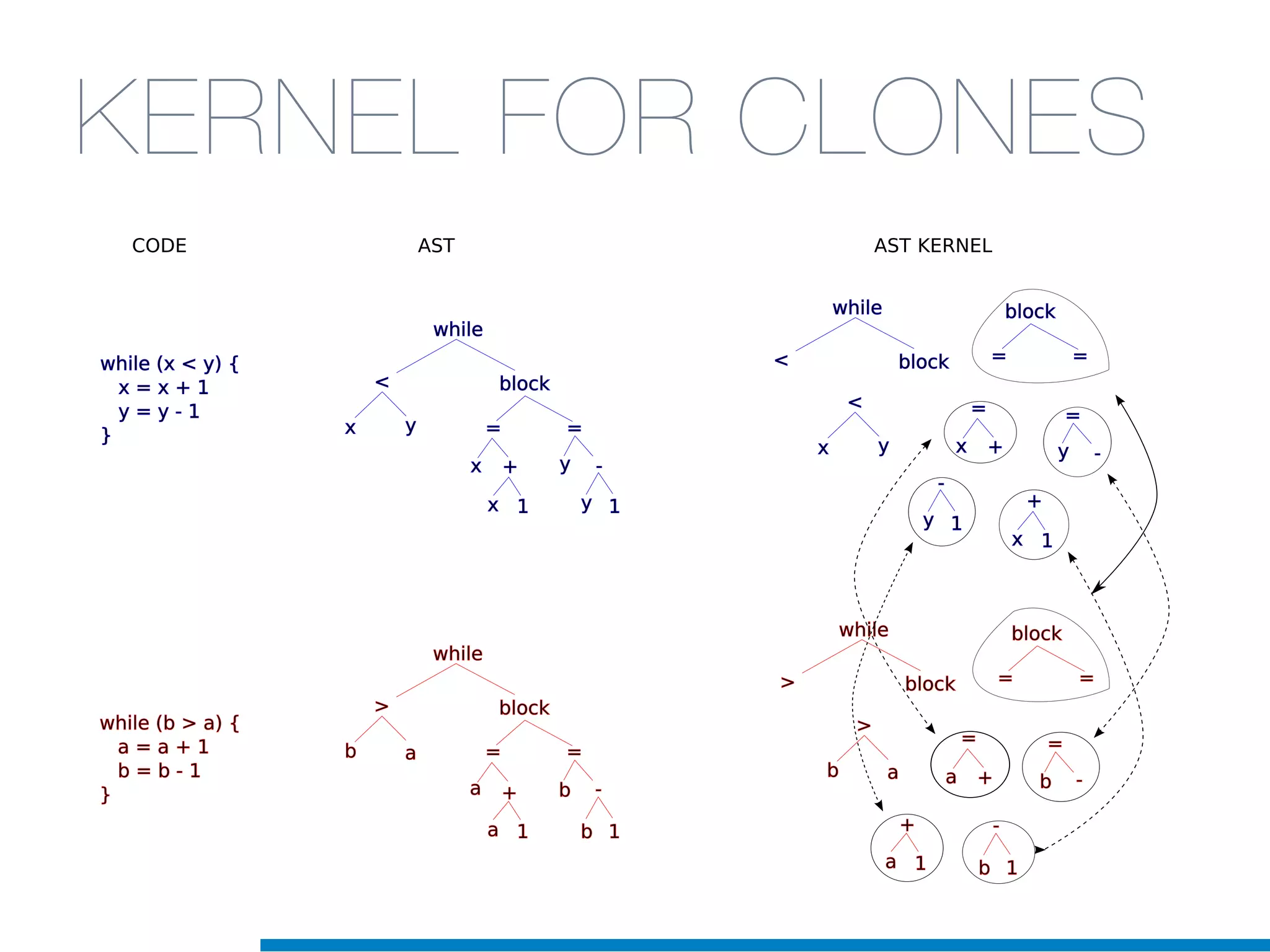






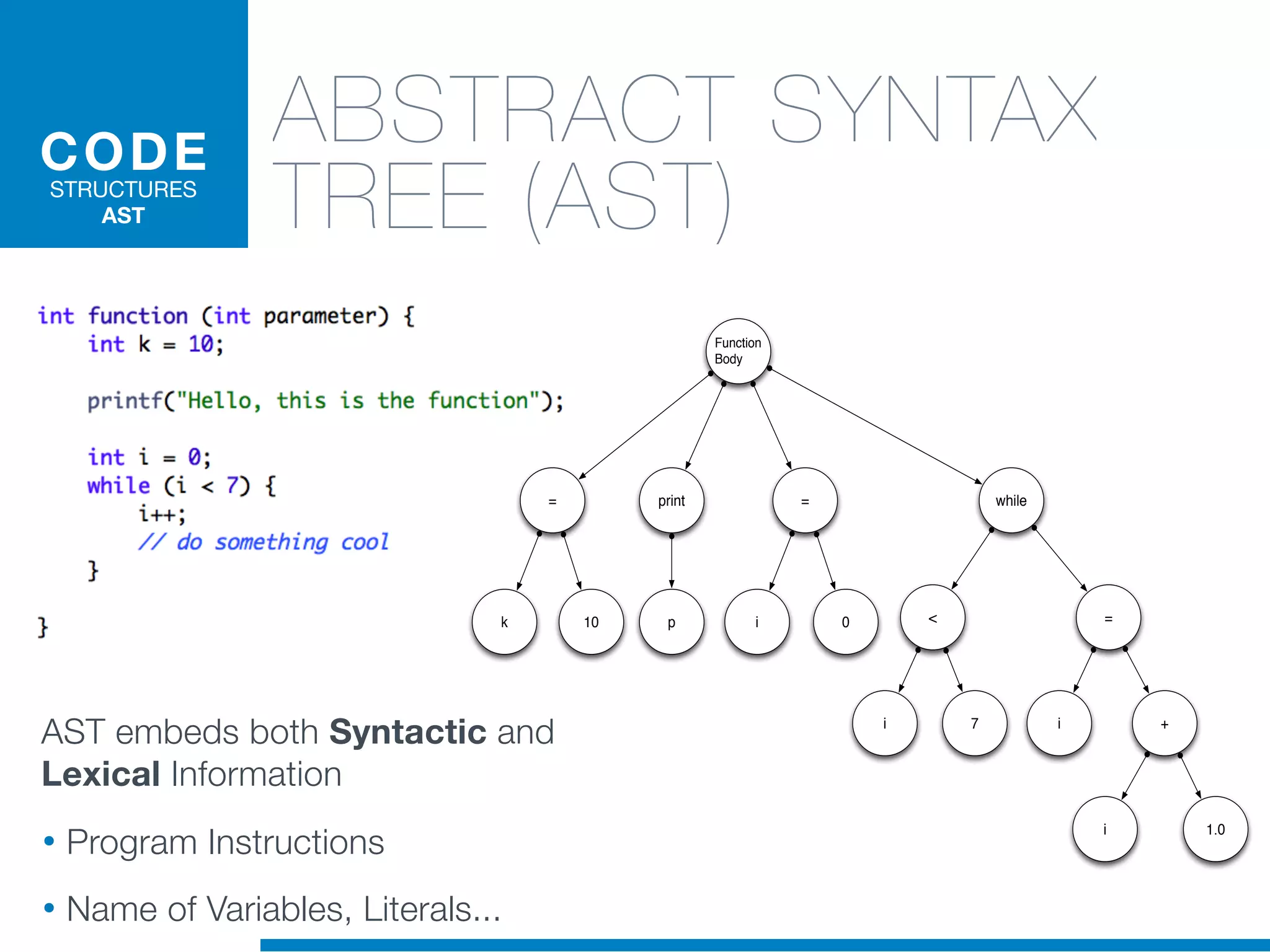
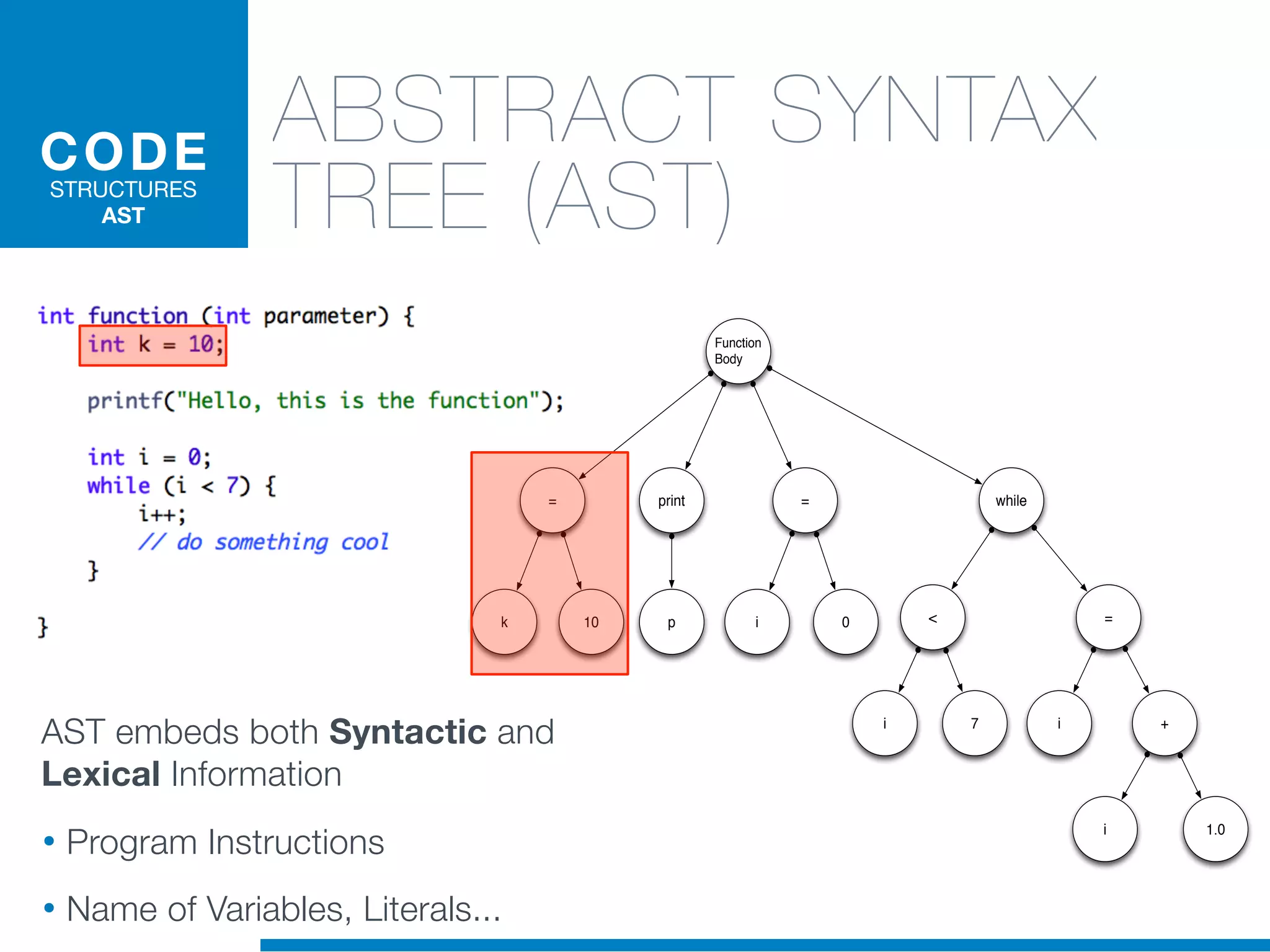
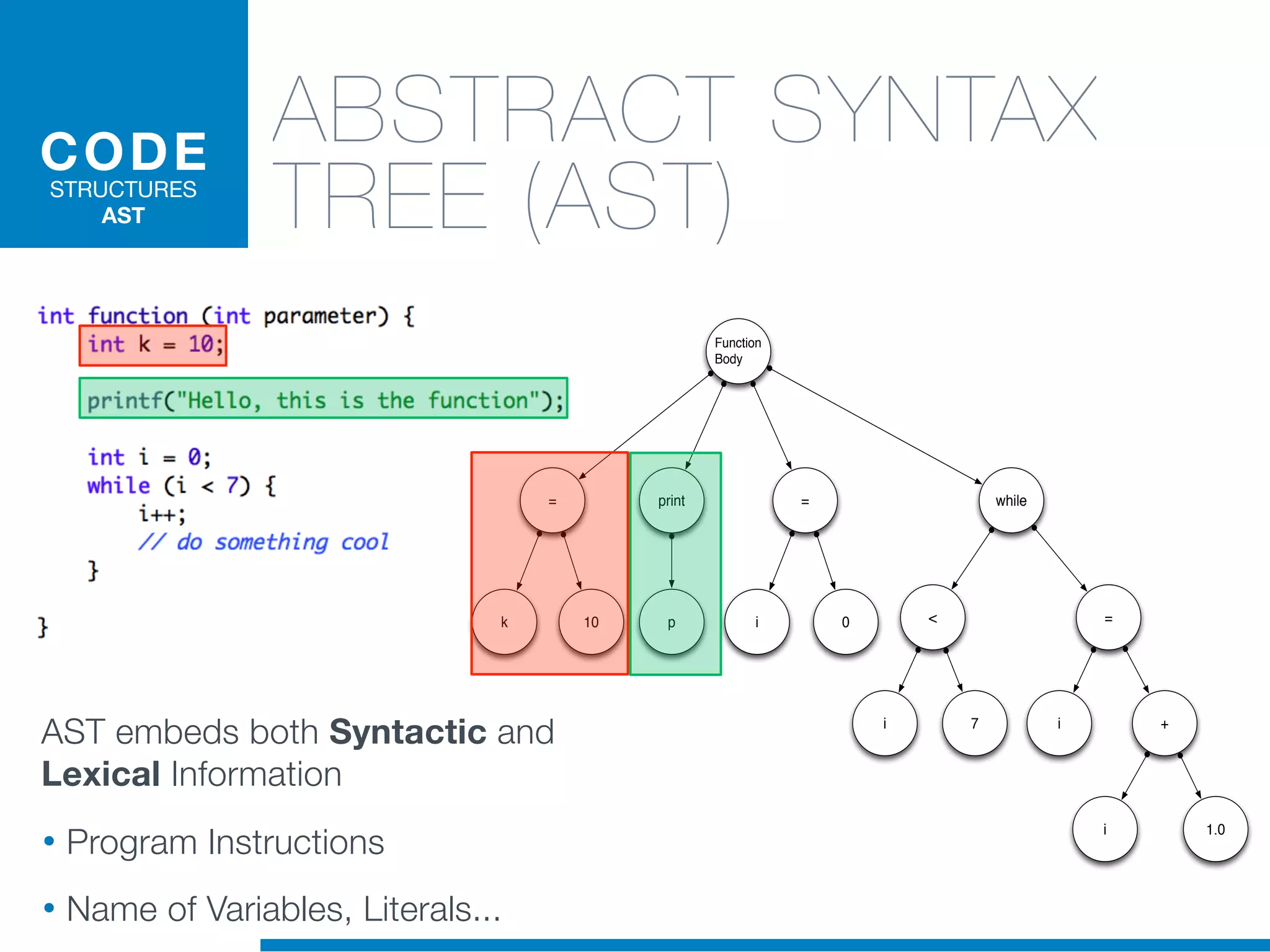
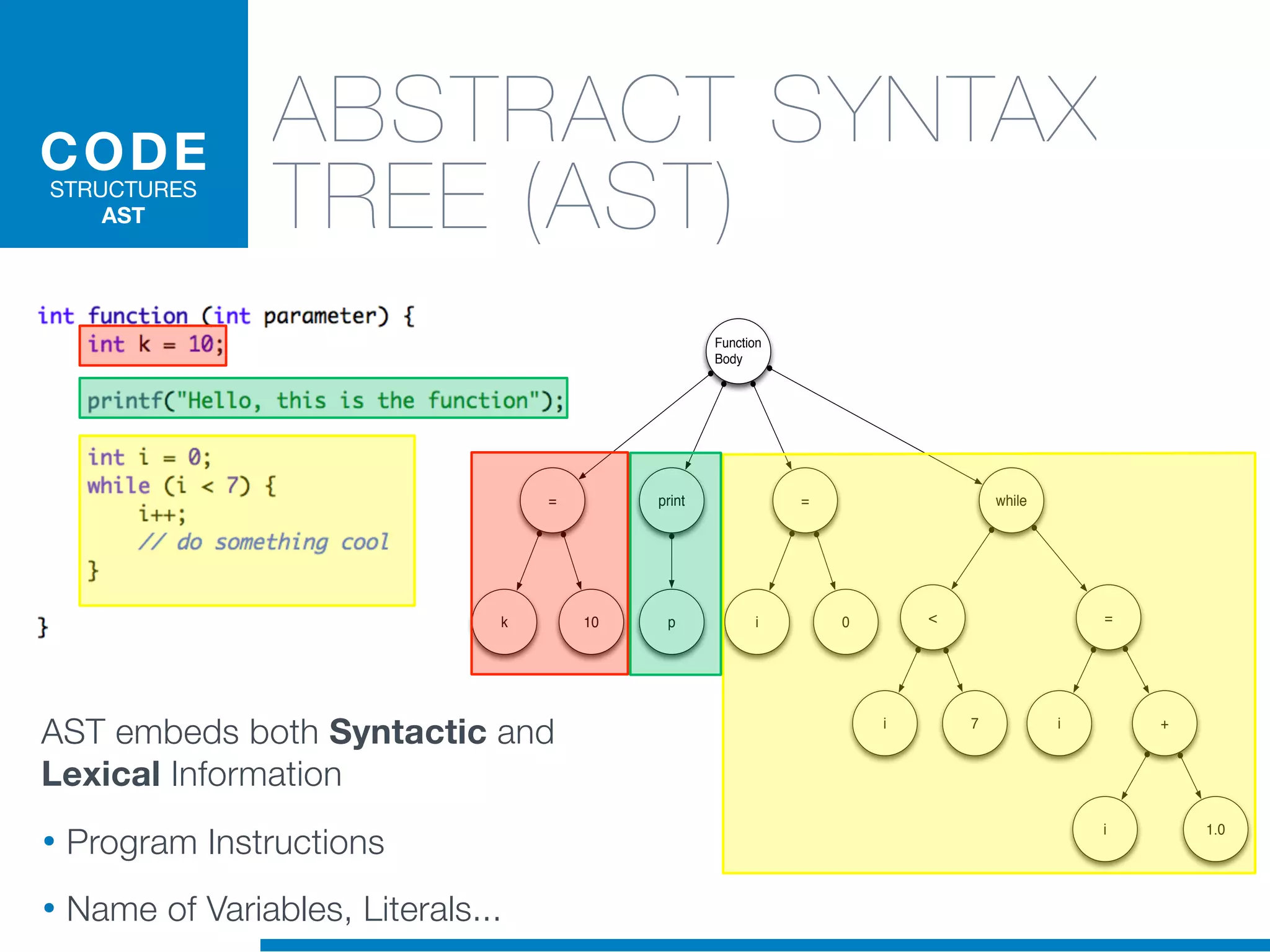
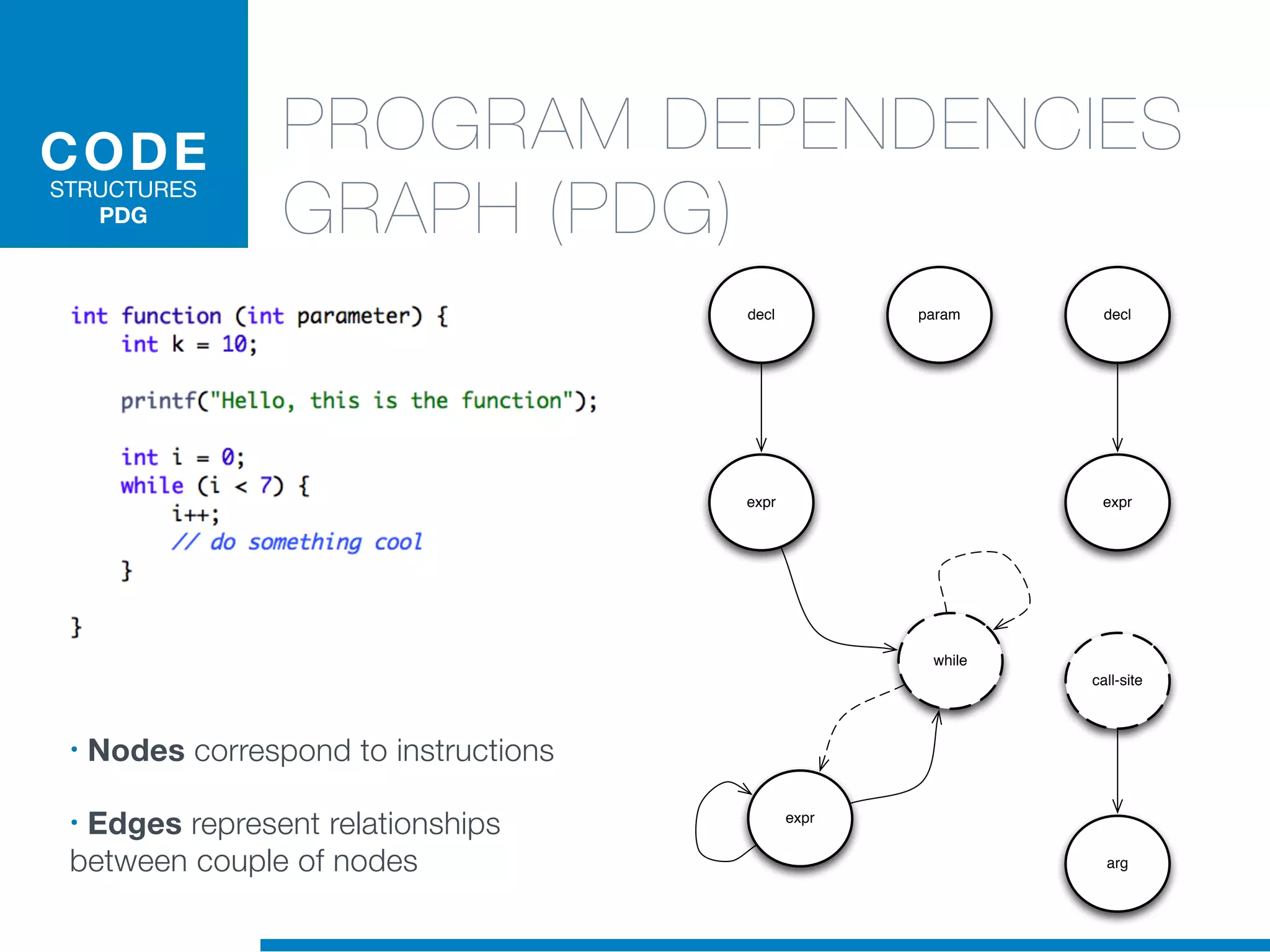
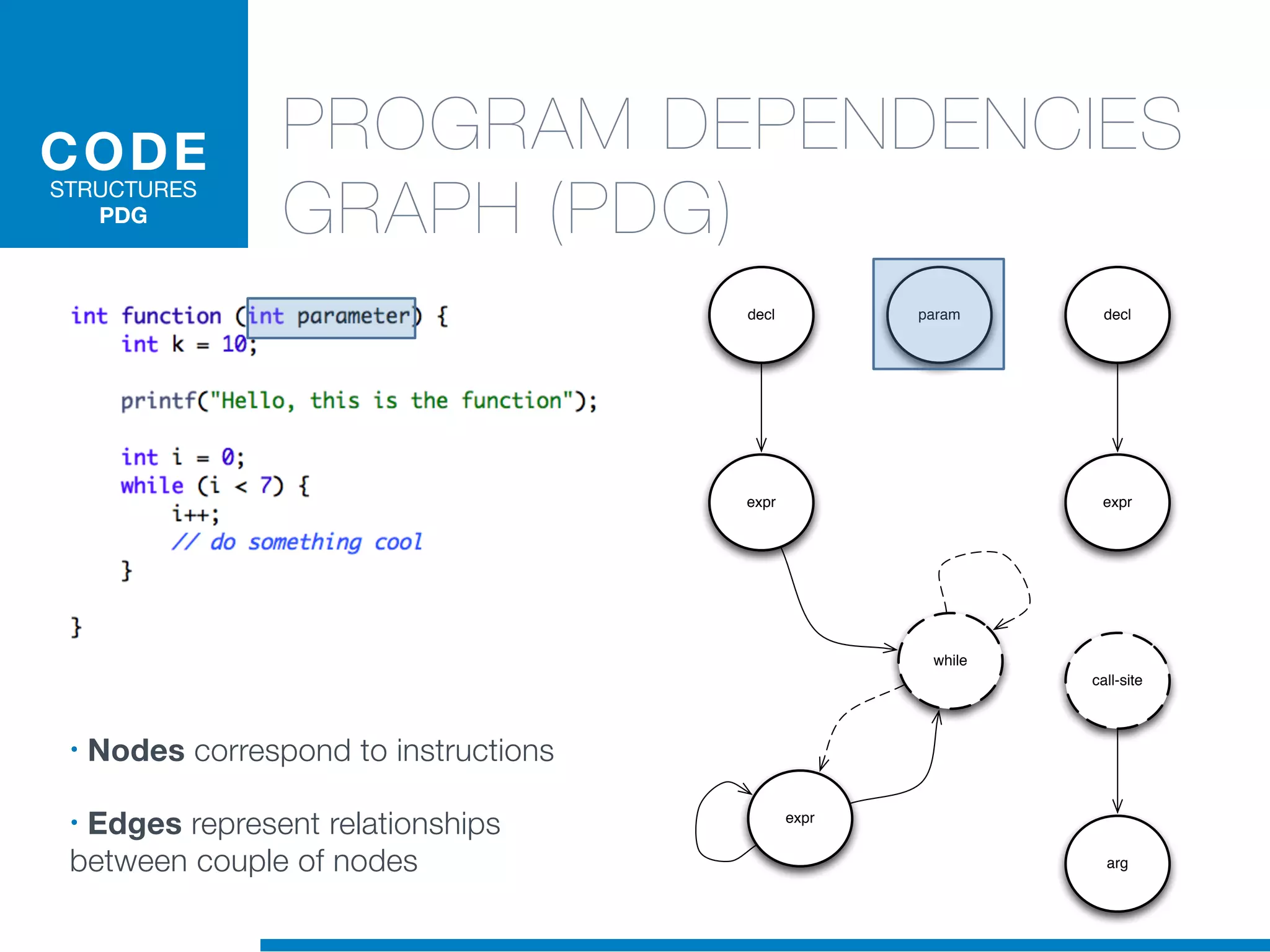
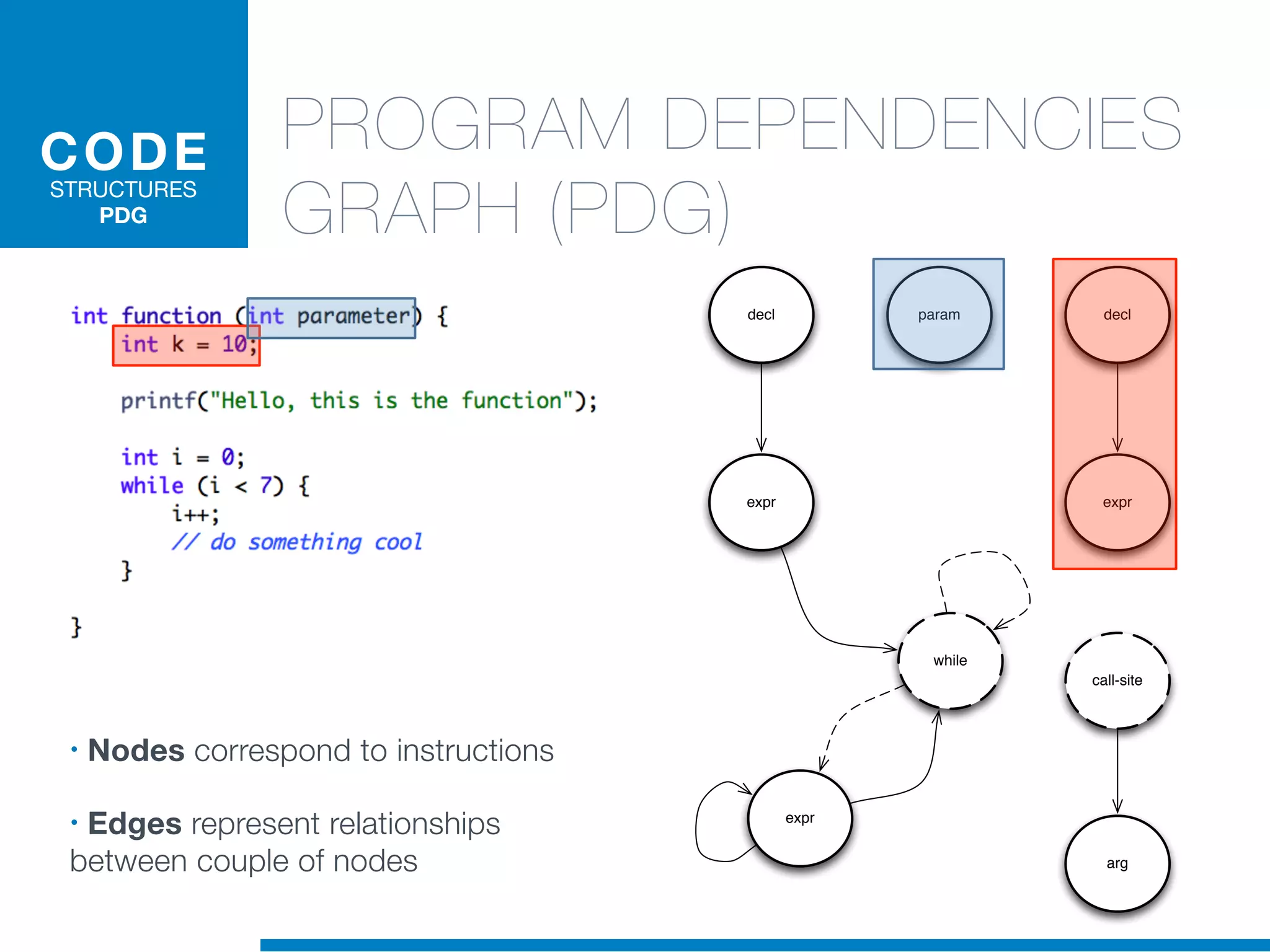
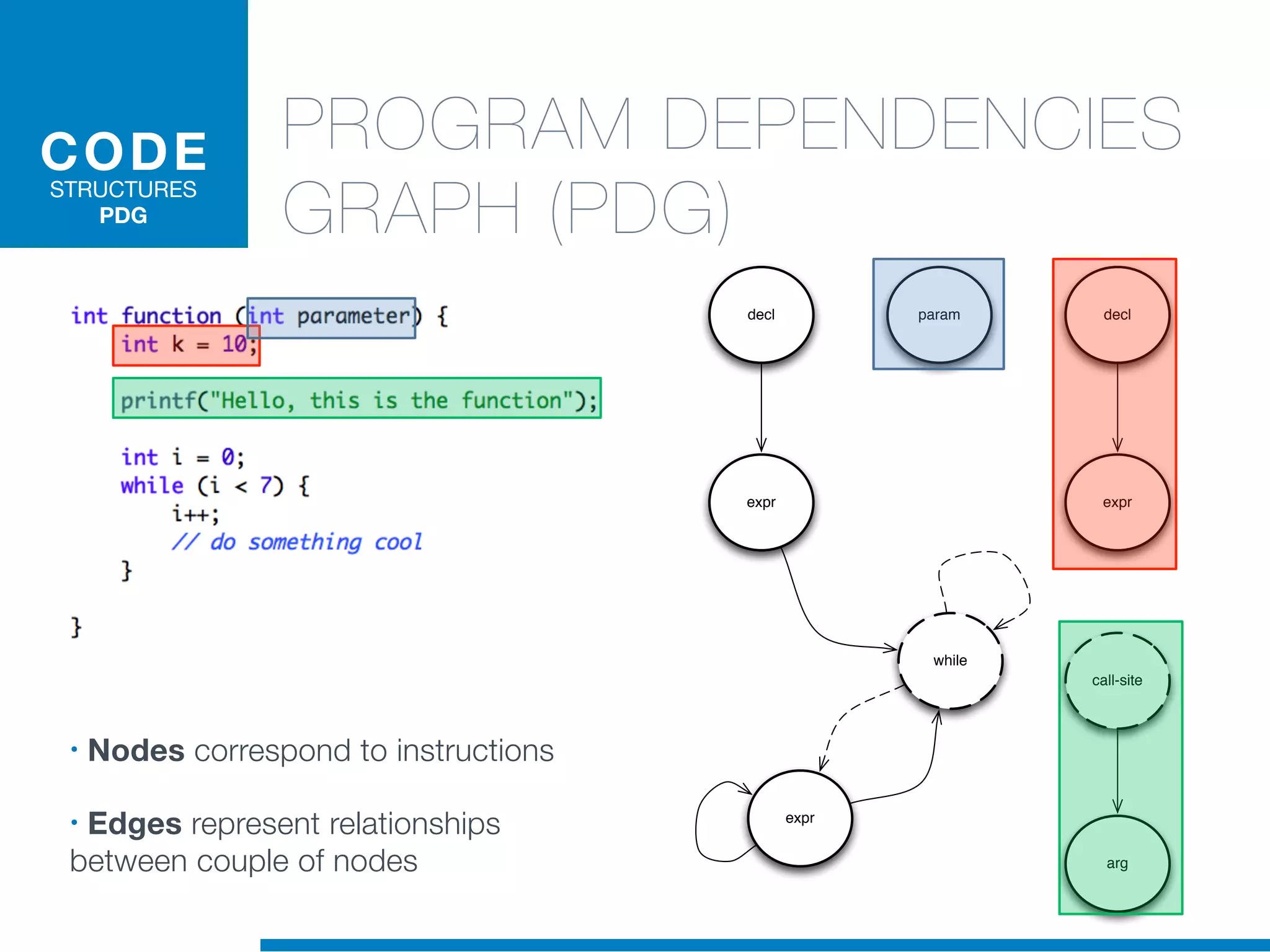
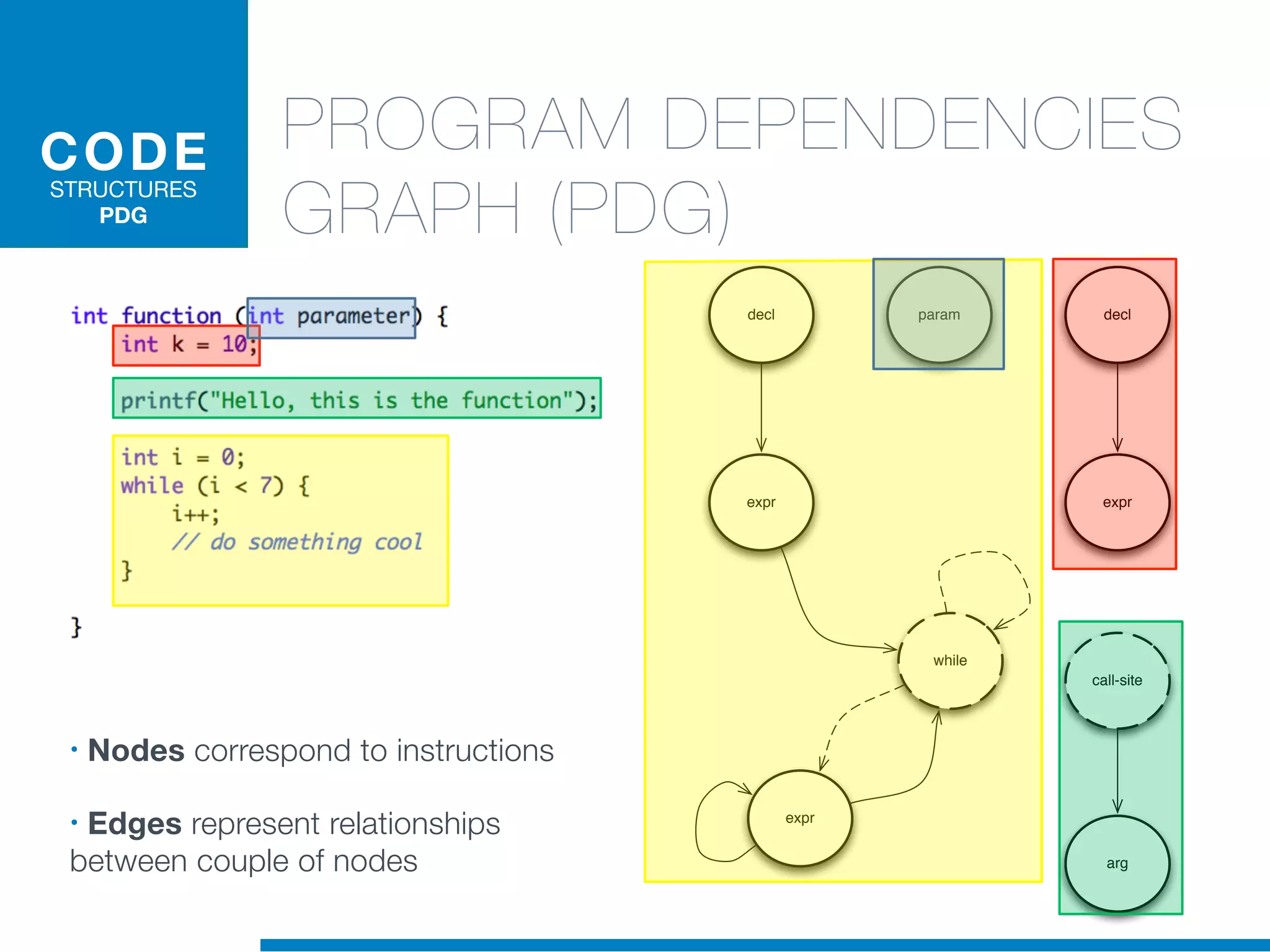
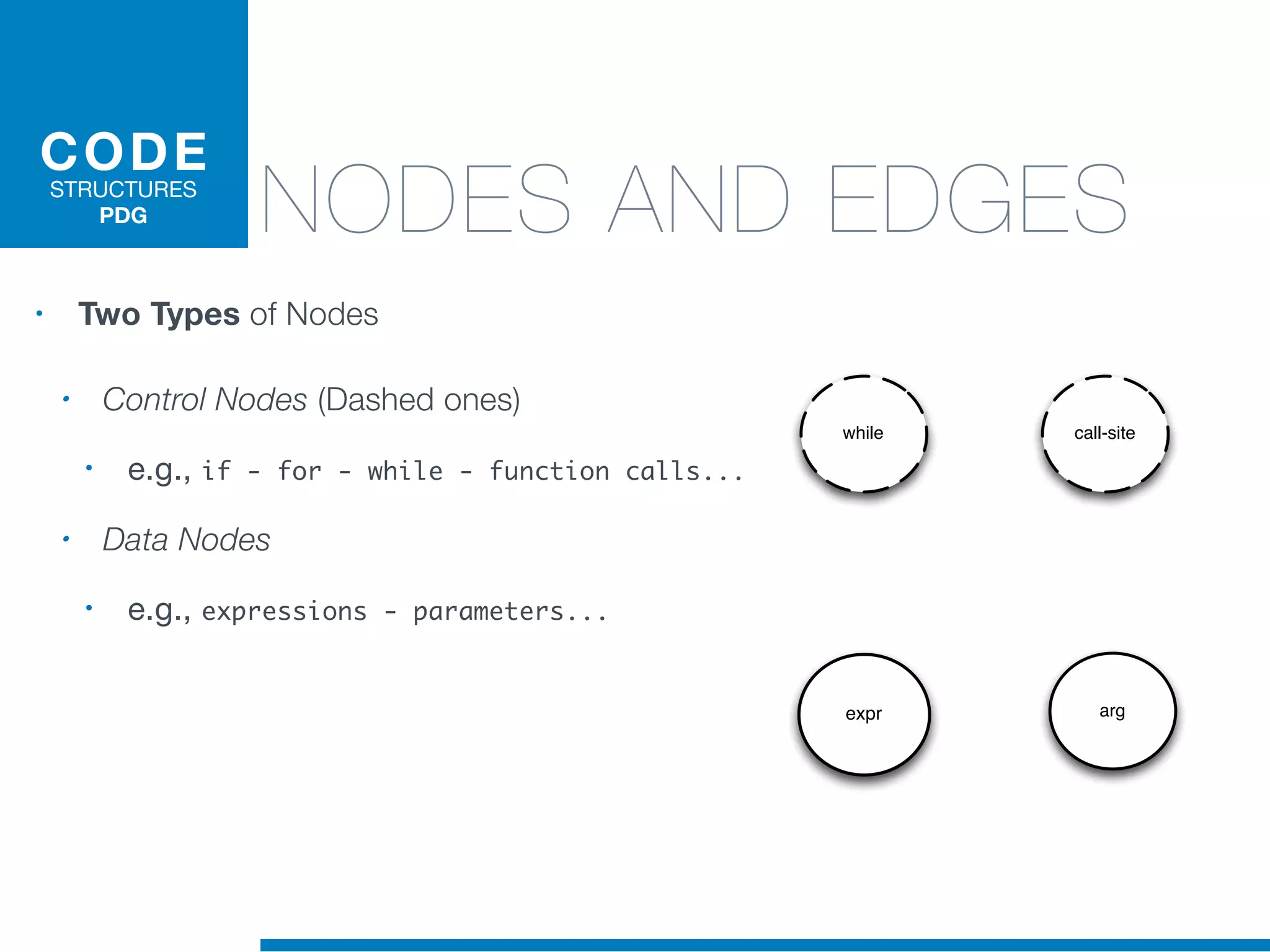
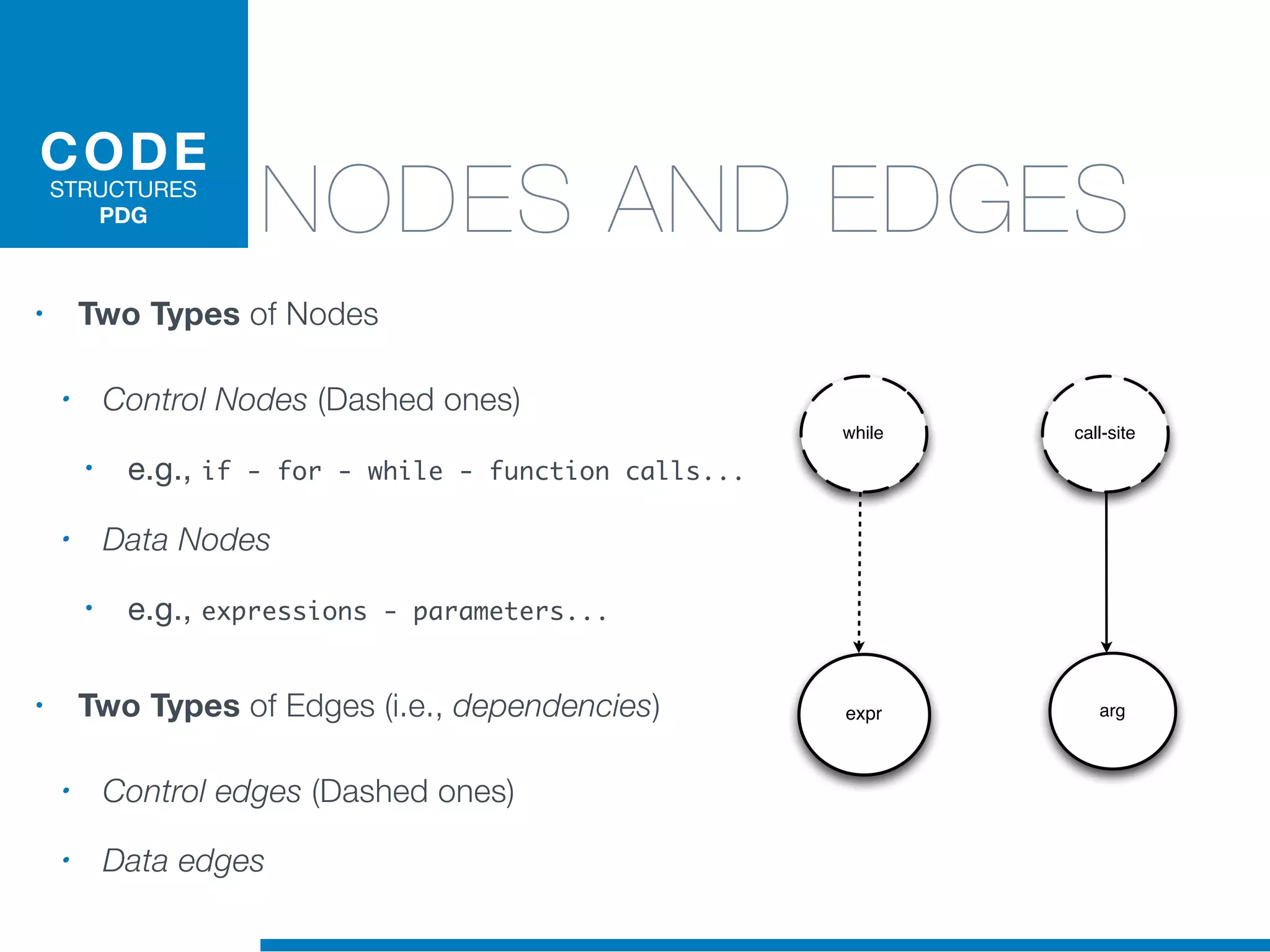

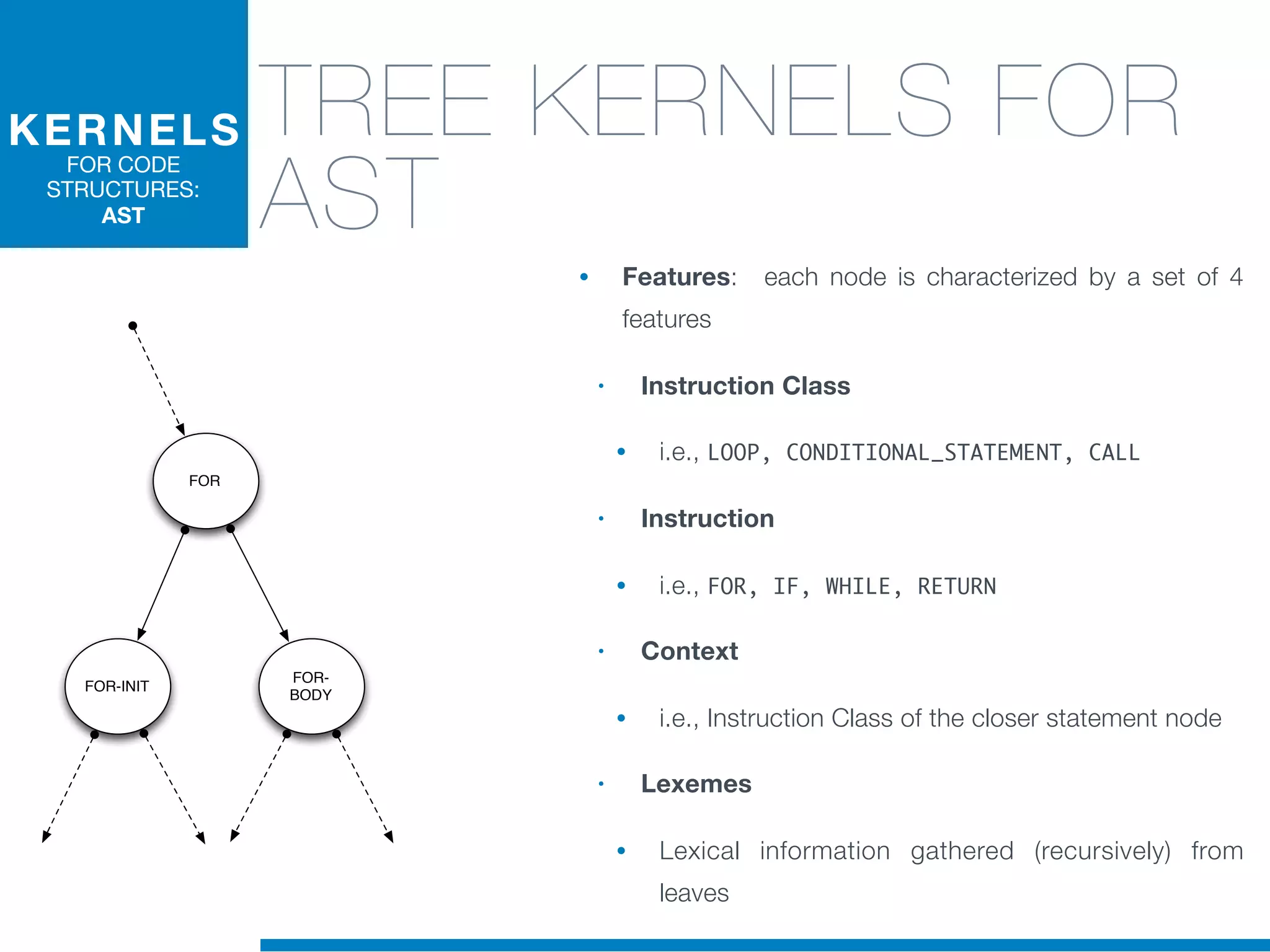
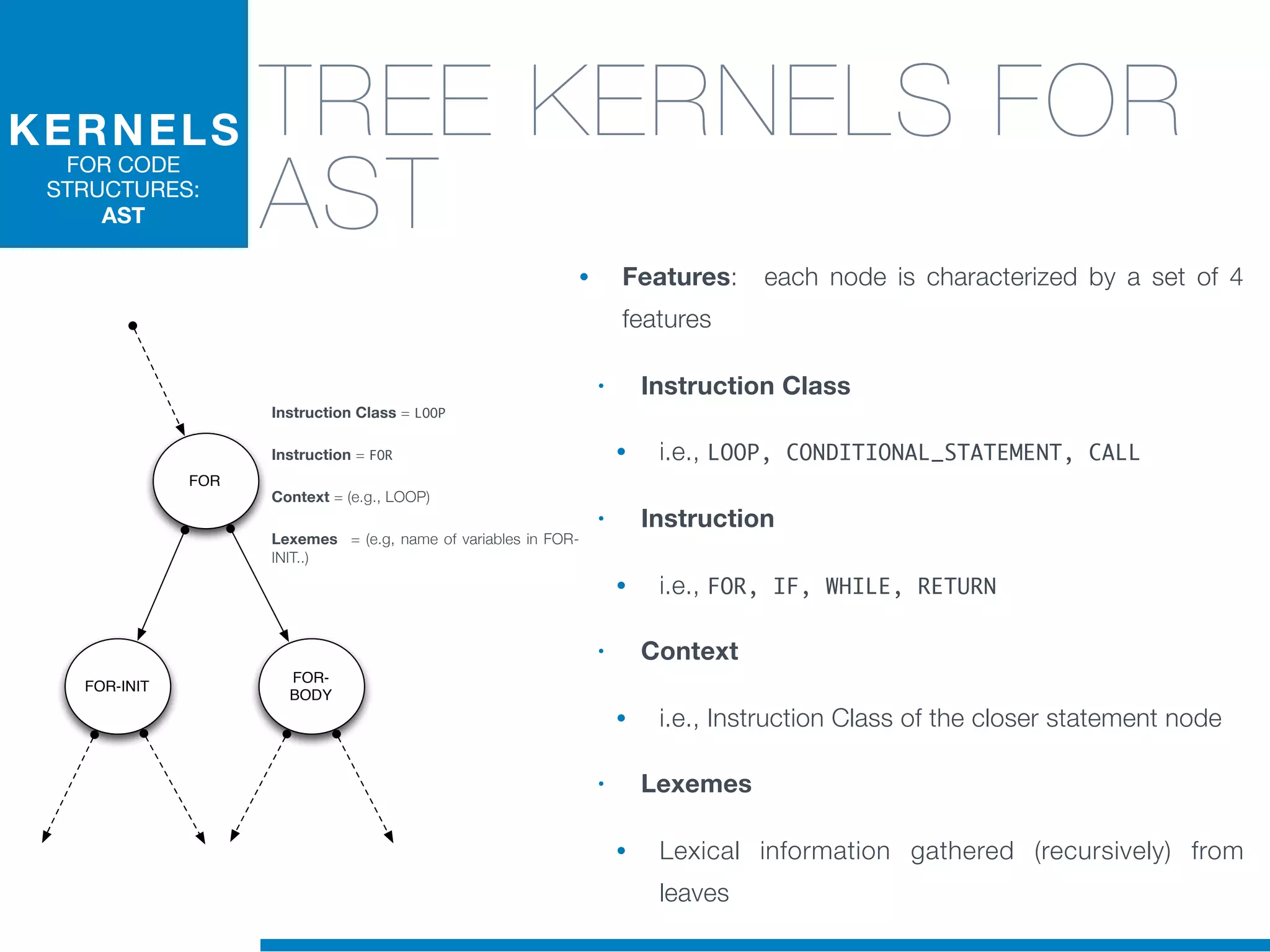
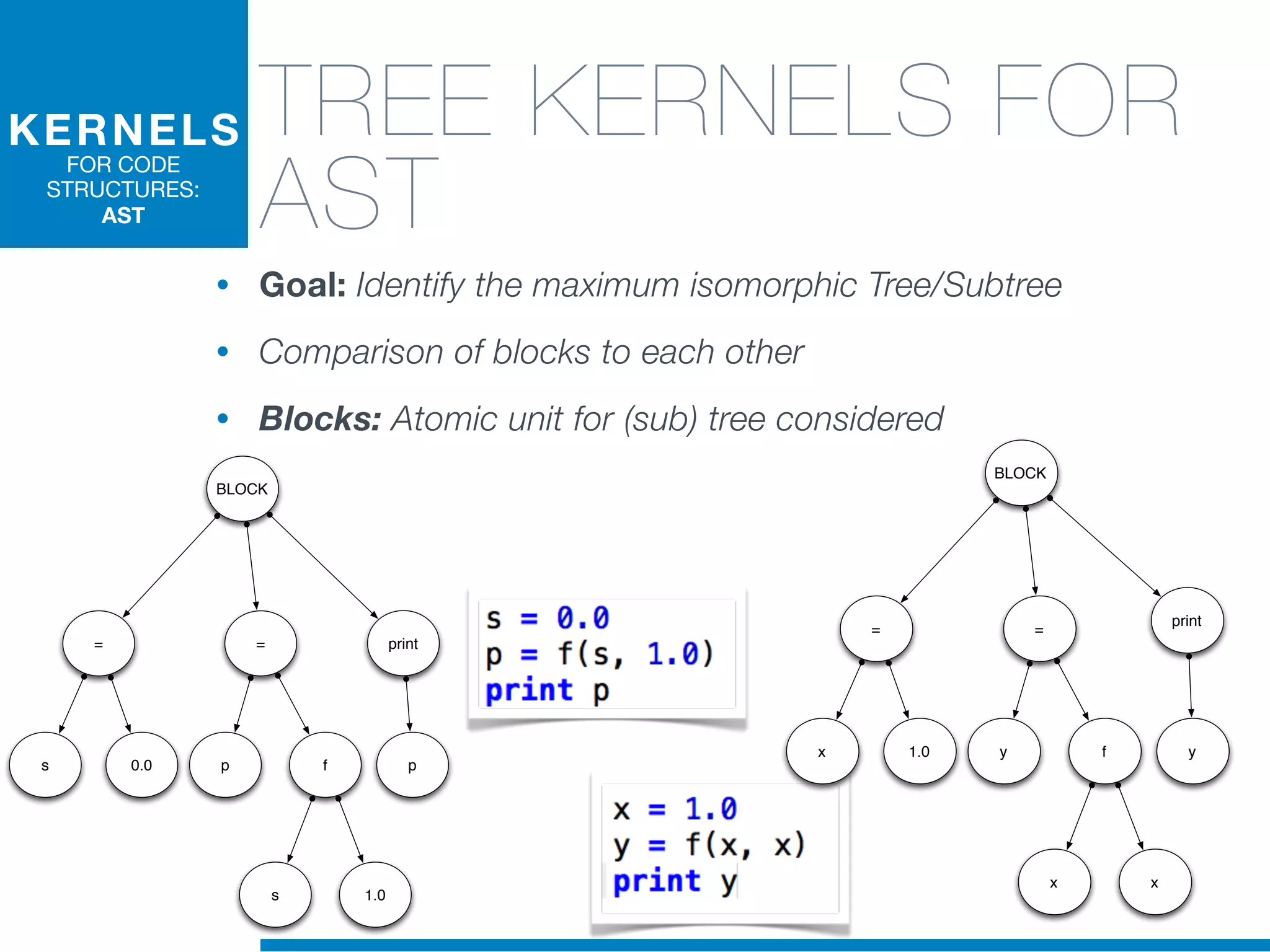
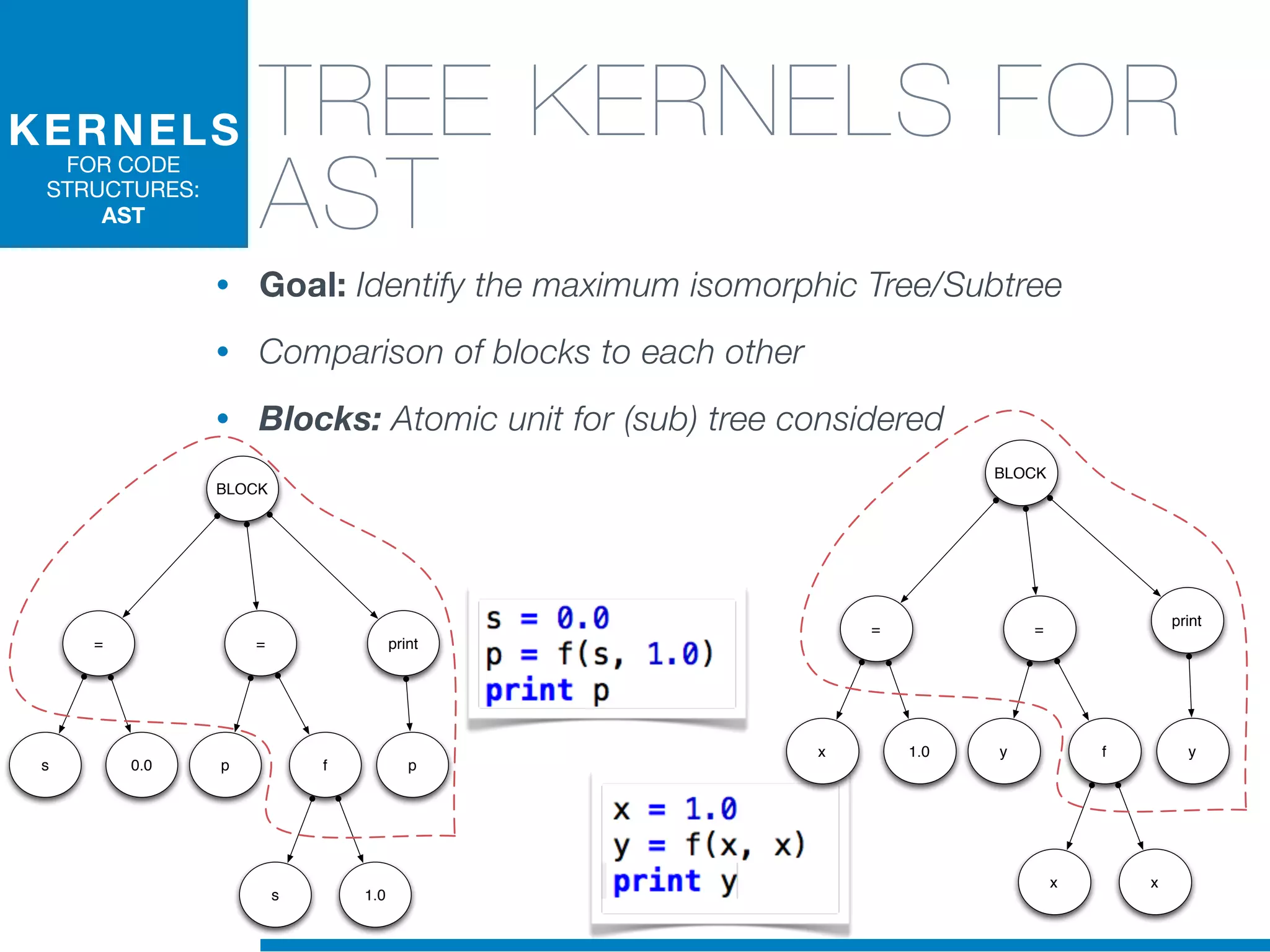


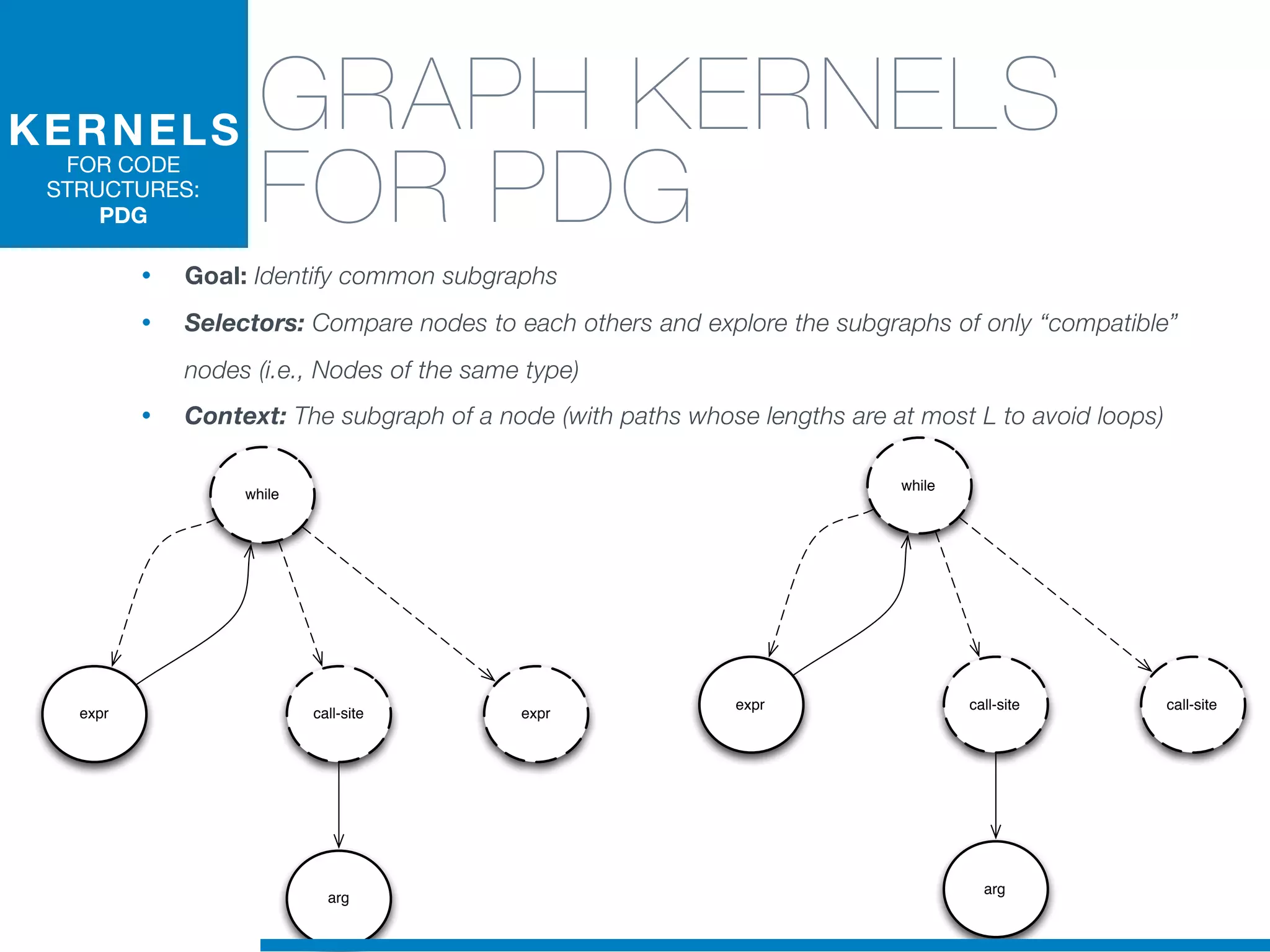
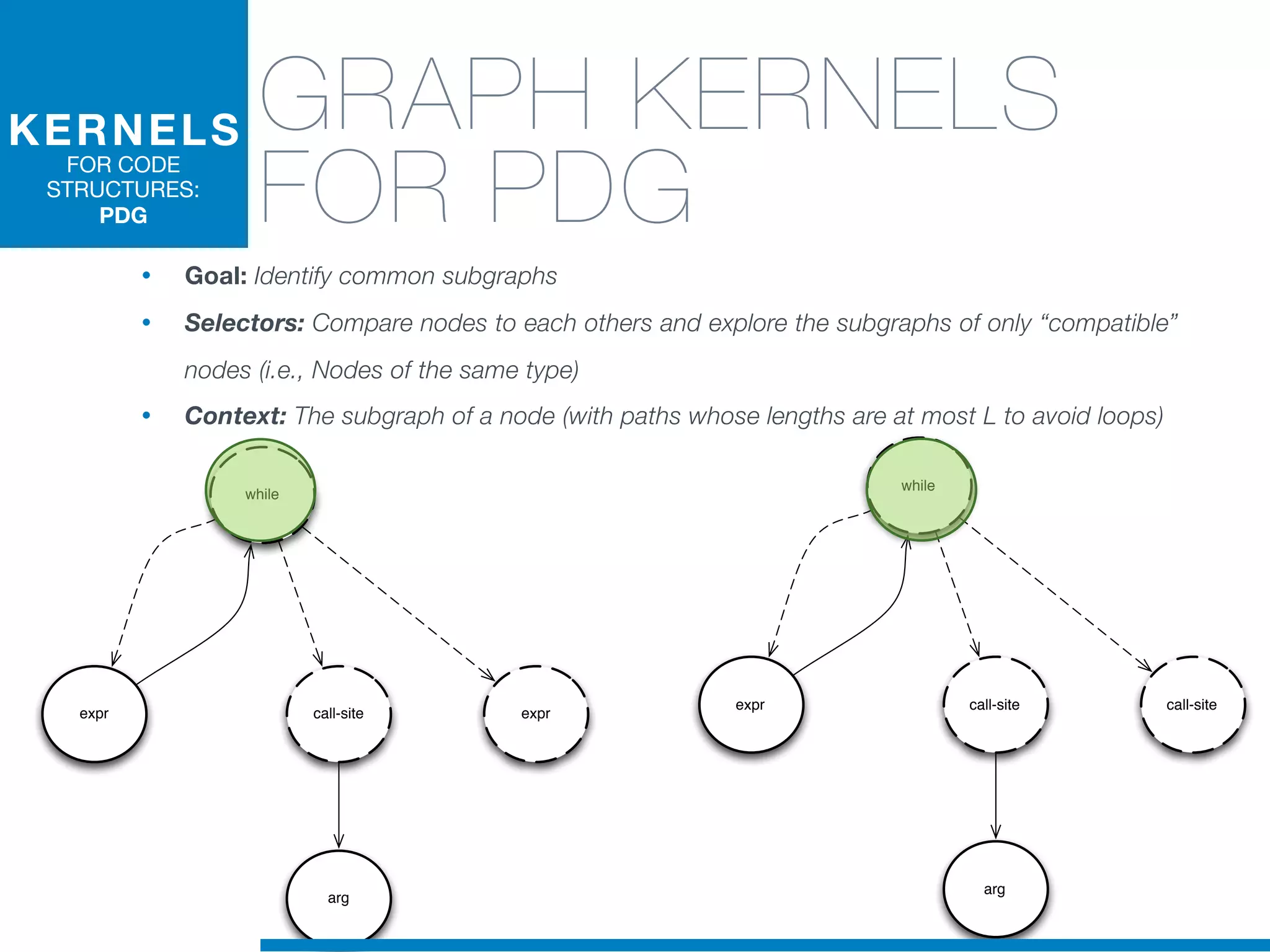
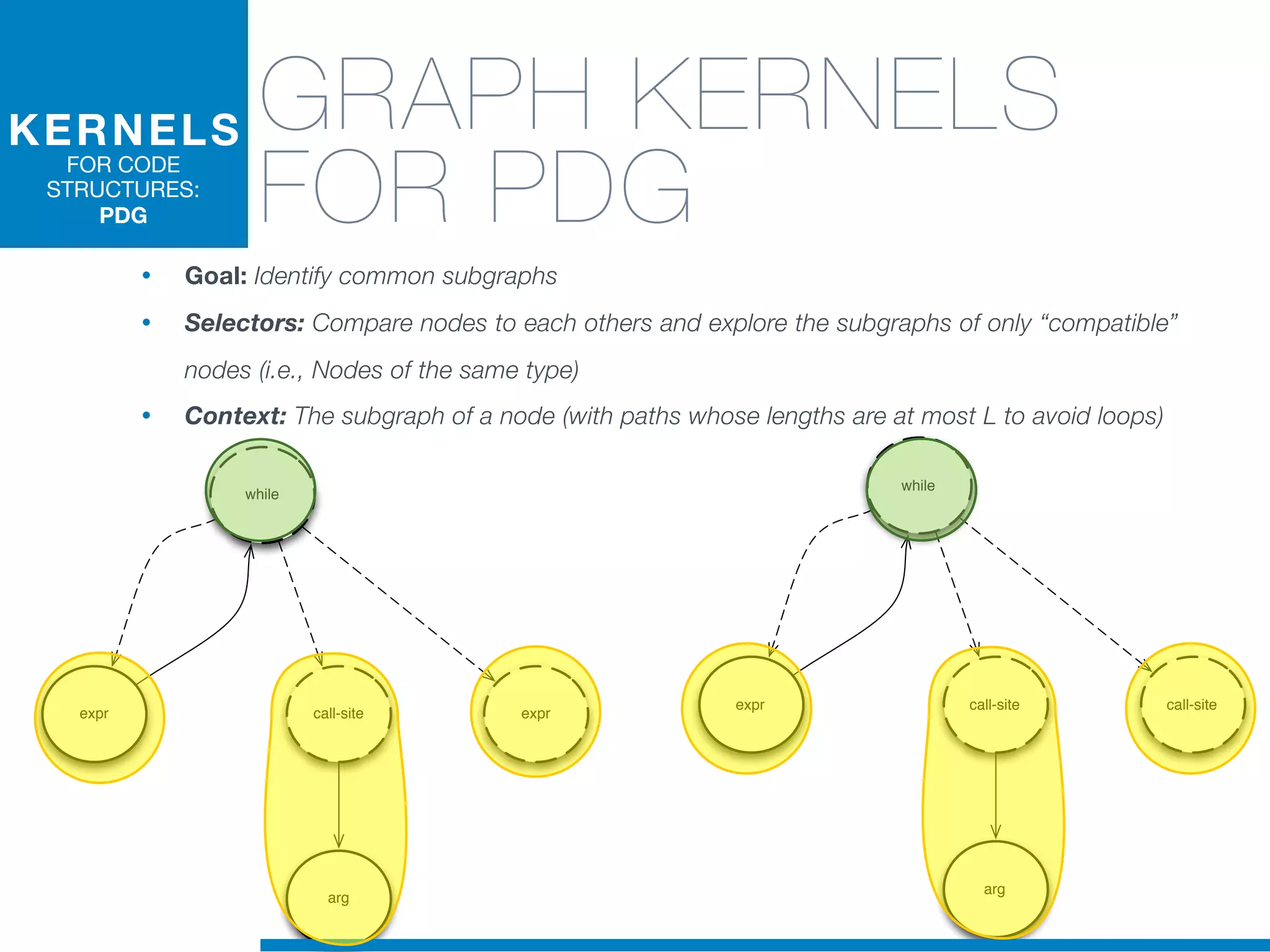








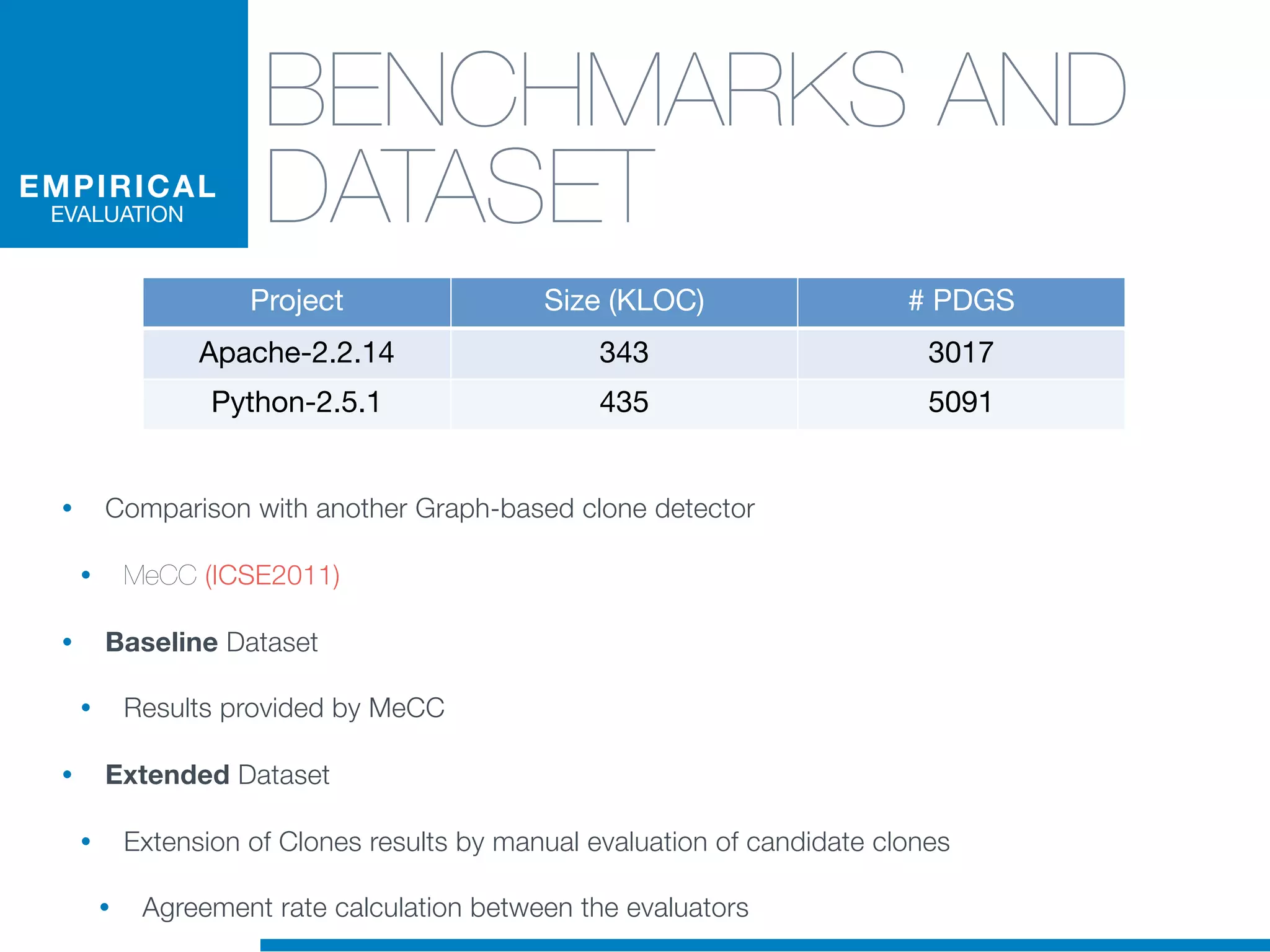

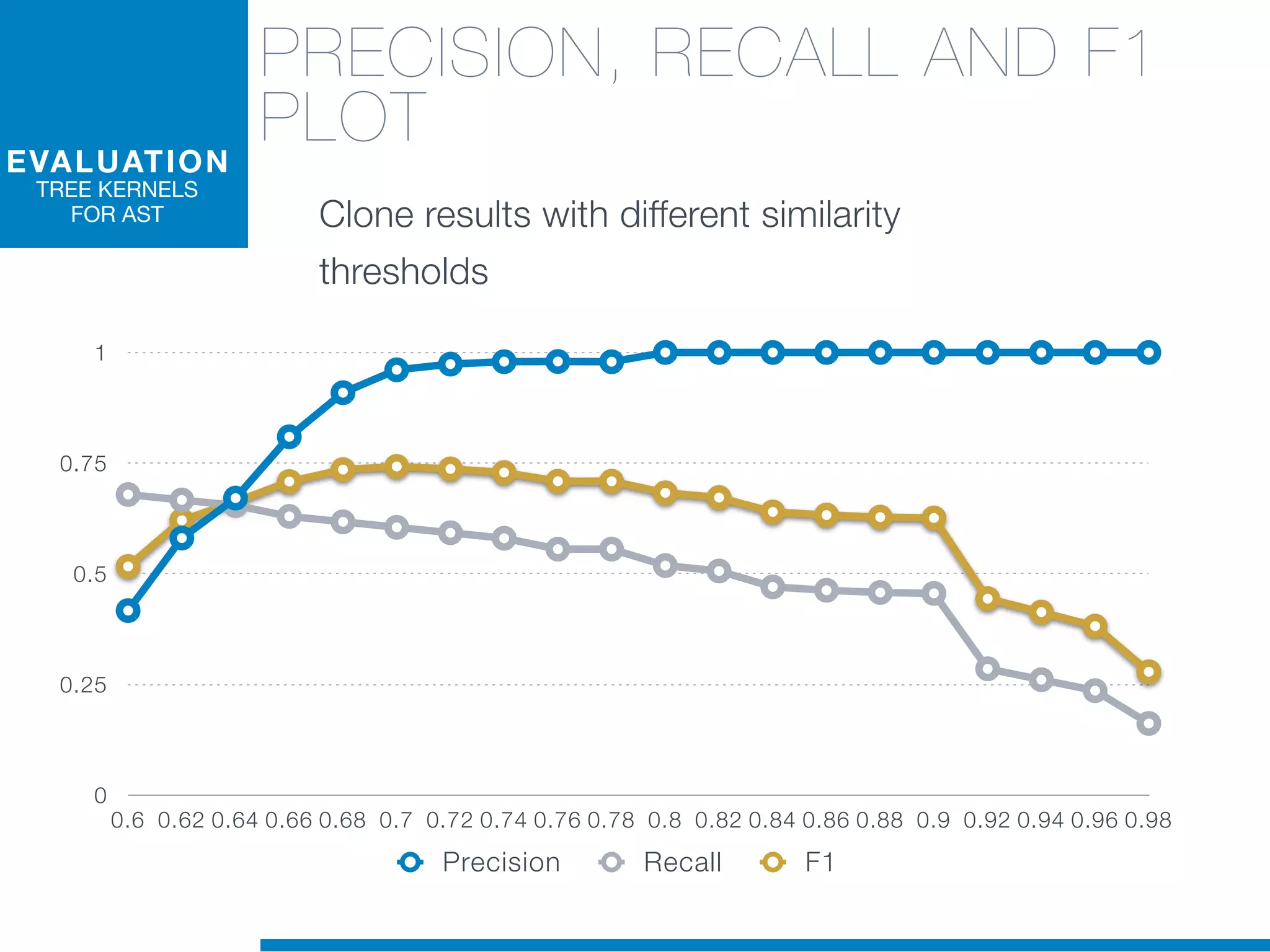
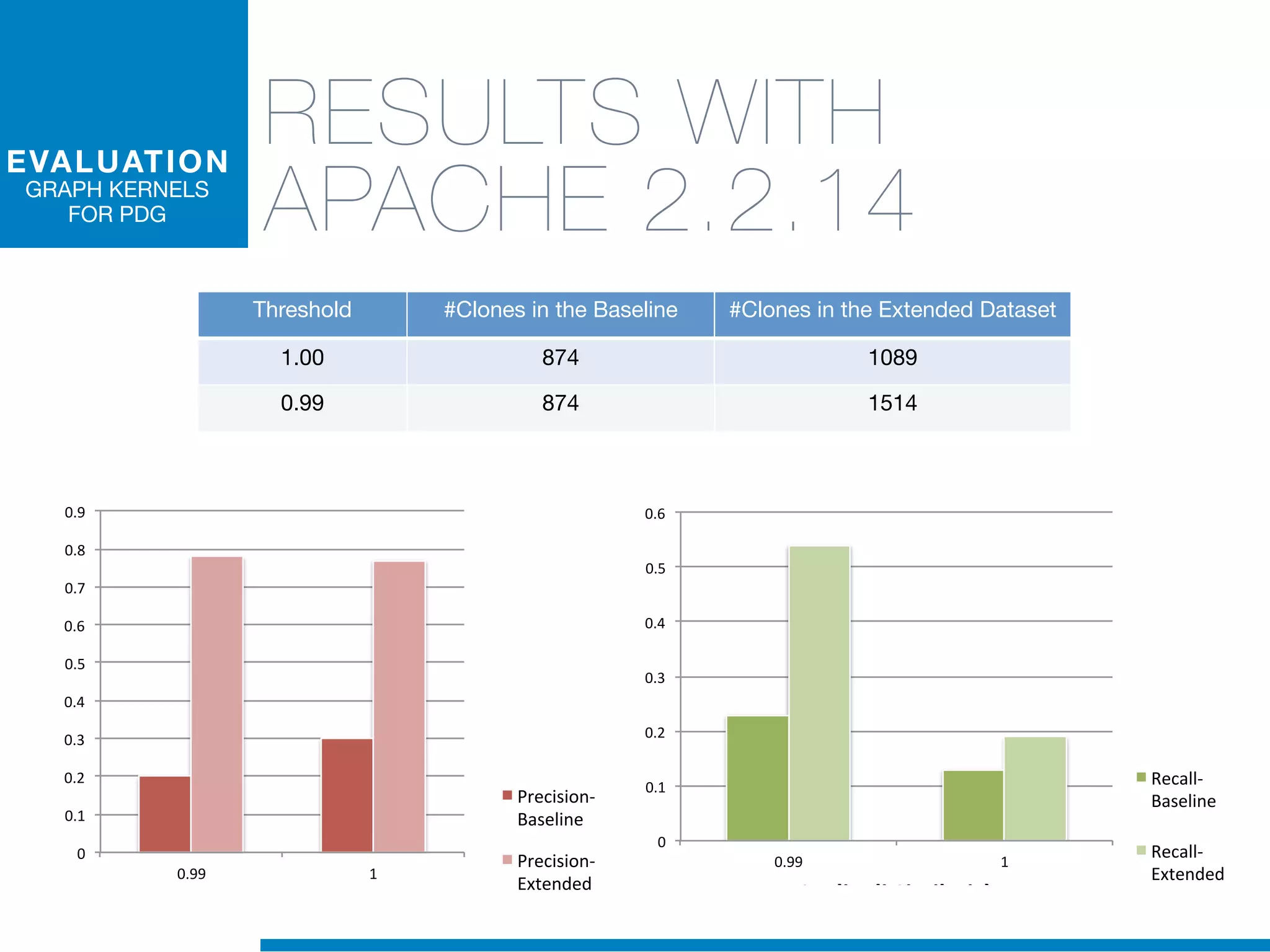
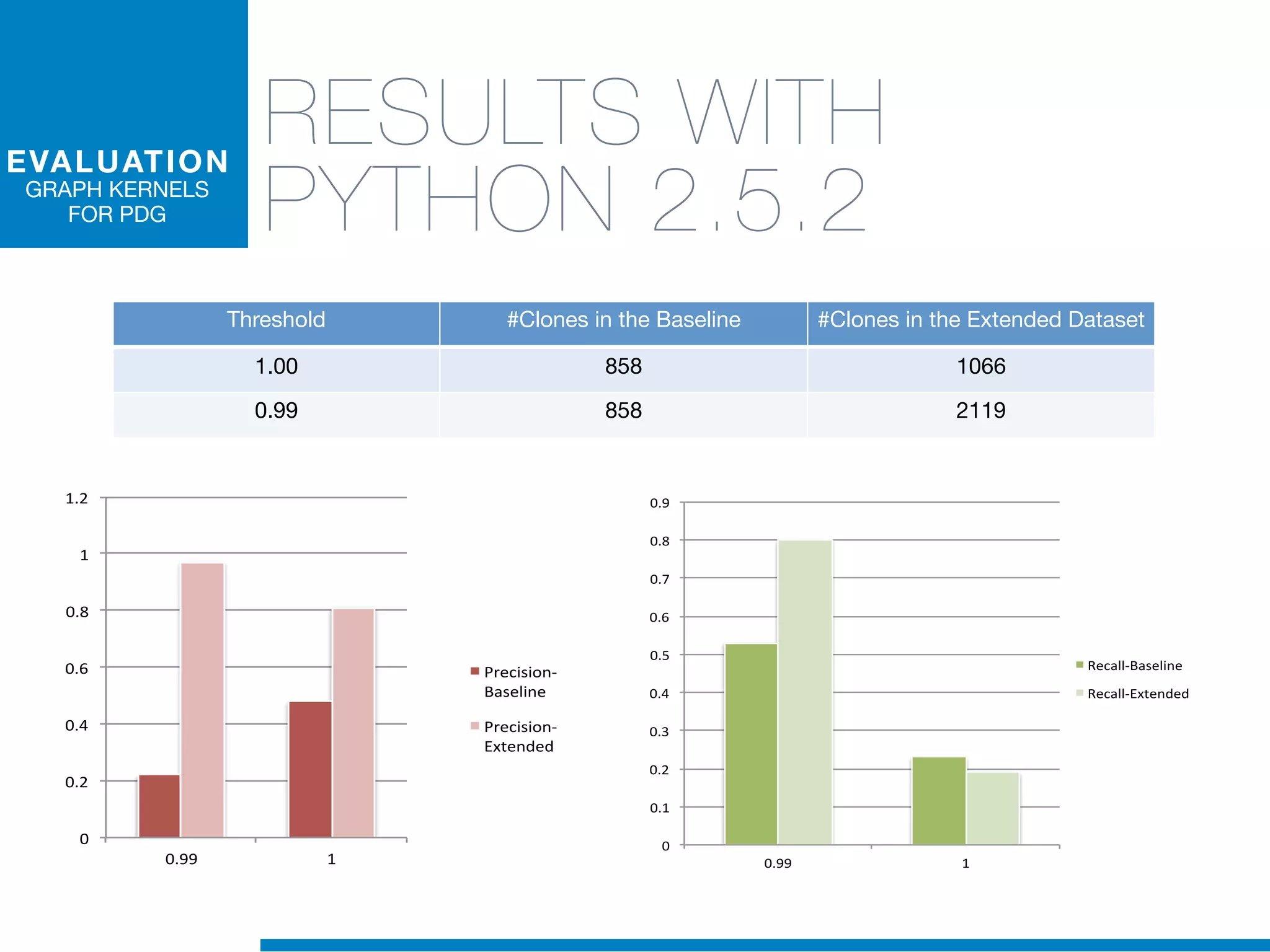



The document discusses the application of machine learning techniques in software maintenance, emphasizing the importance of understanding software artifacts and reducing maintenance costs. It outlines various machine learning approaches for analyzing source code and detecting code clones, particularly through the use of kernel methods that facilitate the classification and clustering of software components. The case study on code clones highlights the use of abstract syntax trees and program dependency graphs to identify duplicated code fragments, thus improving software maintainability.






























































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)















