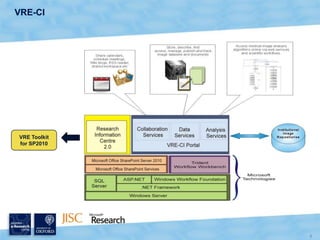
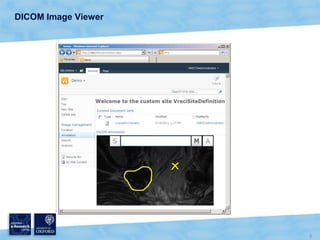
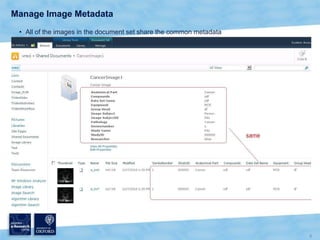
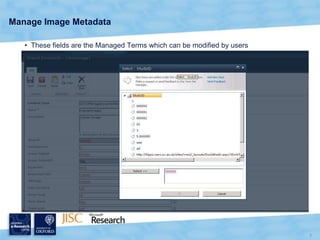
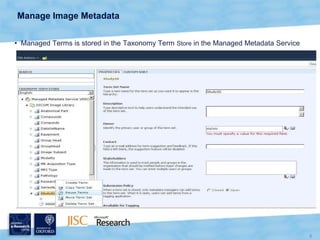
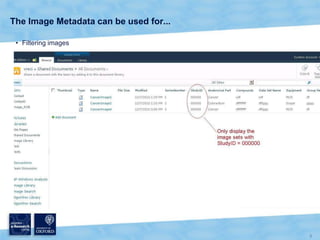
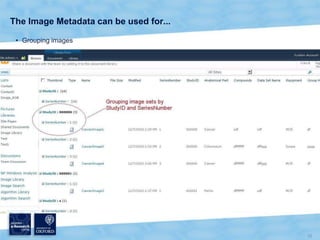
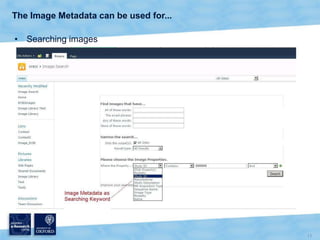
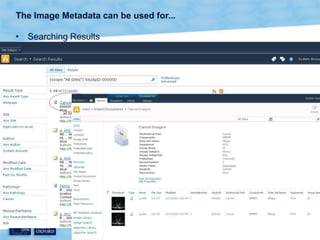
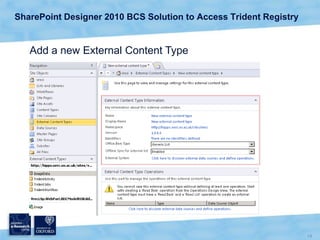
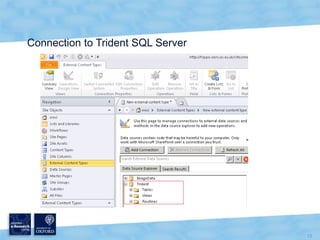
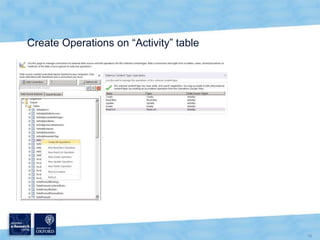
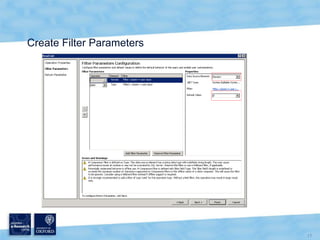
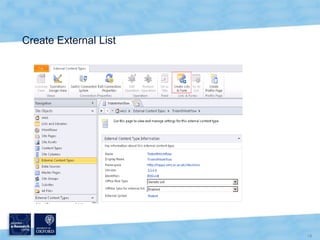
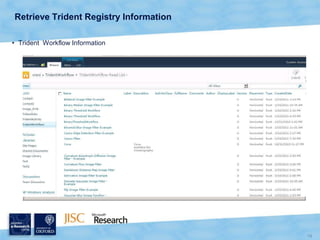
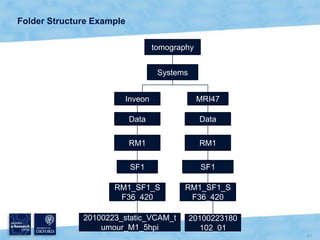
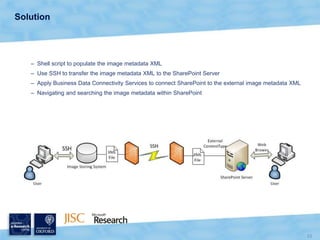
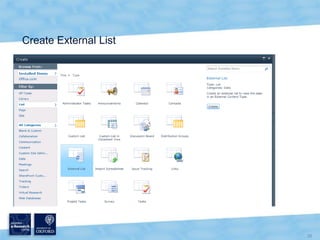
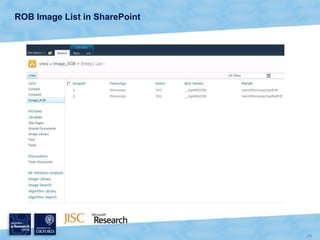
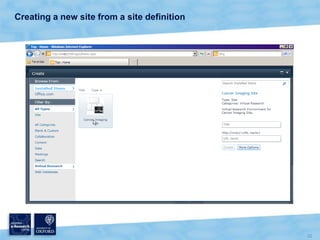
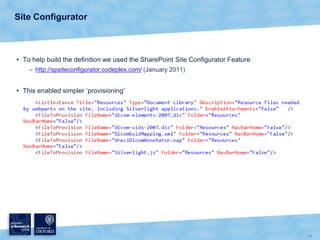
The document discusses the Virtual Research Environment for Cancer Imaging (VRE-CI) project which aims to provide a framework for researchers and clinicians to share cancer imaging information, images, and algorithms. It describes using Business Connectivity Services and managed metadata to organize and search image metadata, and building a reusable SharePoint site definition to manage DICOM files and extract metadata for search. Key aspects covered include mapping folders, issues with document library names, including external code, and adapting the DICOM field model.