Download to read offline





![Personal characteristics
Need for cognition
• Measurement of the tendency for an individual to engage in, and enjoy, effortful cognitive activities
• Measured by test of Cacioppo et al. [1984]
Visualisation literacy
• Measurement of the ability to interpret and make meaning from information presented in the form of
images and graphs
• Measured by test of Boy et al. [2014]
Locus of control (LOC)
• Measurement of the extent to which people believe they have power over events in their lives
• Measured by test of Rotter et al. [1966]
Visual working memory
• Measurement of the ability to recall visual patterns [Tintarev and Mastoff, 2016]
• Measured by Corsi block-tapping test
Musical experience
• Measurement of the ability to engage with music in a flexible, effective and nuanced way
[Müllensiefen et al., 2014]
• Measured using the Goldsmiths Musical Sophistication Index (Gold-MSI)
Tech savviness
• Measured by confidence in trying out new technology
10](https://image.slidesharecdn.com/xai-trail-230427115651-f3213389/75/Human-centered-AI-how-can-we-support-end-users-to-interact-with-AI-10-2048.jpg)





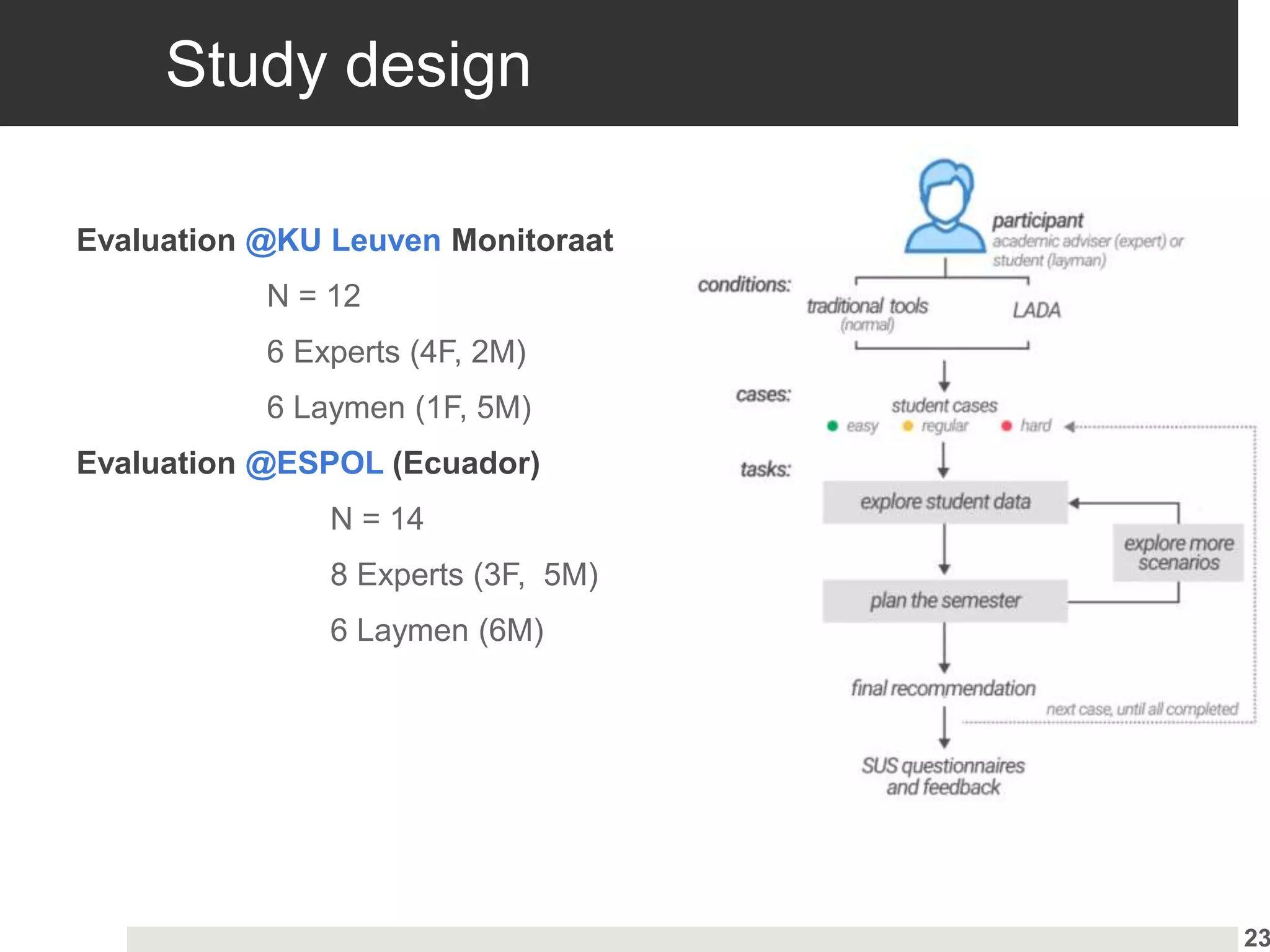
![Study design
Between-subjects – 240 participants recruited with AMT
Independent variable: settings of user control
2x2x2 factorial design
Dependent variables:
Acceptance (ratings)
Cognitive load (NASA-TLX), Musical Sophistication, Visual Memory
Framework Knijnenburg et al. [2012]](https://image.slidesharecdn.com/xai-trail-230427115651-f3213389/75/Human-centered-AI-how-can-we-support-end-users-to-interact-with-AI-18-2048.jpg)









![Case Study – Grape Quality Prediction
40
Grape Quality Prediction Scenario [Tag14]
Data
Years 2010, 2011 (train) 2012 (test)
48 cells (Central Greece)
Knowledge-based rules
[Tag14] Tagarakis, A., et al. "A fuzzy inference system to model
grape quality in vineyards." Precision Agriculture 15.5 (2014):
555-578.
Source: [Tag14]](https://image.slidesharecdn.com/xai-trail-230427115651-f3213389/75/Human-centered-AI-how-can-we-support-end-users-to-interact-with-AI-40-2048.jpg)














Human-centered AI: how can we support end-users to interact with AI? This document discusses how to design human-centered AI systems that support end-users. It explores explaining model outcomes to increase trust and acceptance, and enabling users to interact with explanation processes. Personal characteristics like need for cognition impact how users respond to explanations. Explanations should be personalized and allow different levels of detail. Evaluations show explanations improve understanding but also increase cognitive load, so simplification is important. The goal is to preserve human control and ensure AI meets user needs.
Introduction to Human-Centered AI and its relevance for end-user interaction.
Human-Centered AI aims to enhance human capabilities and ensure transparency, equity, and privacy.
Focus on AI model explanations to build user trust and improve interaction through personalized explanations.
Identifying personal traits (e.g., need for cognition) affecting user interaction with AI recommendations.
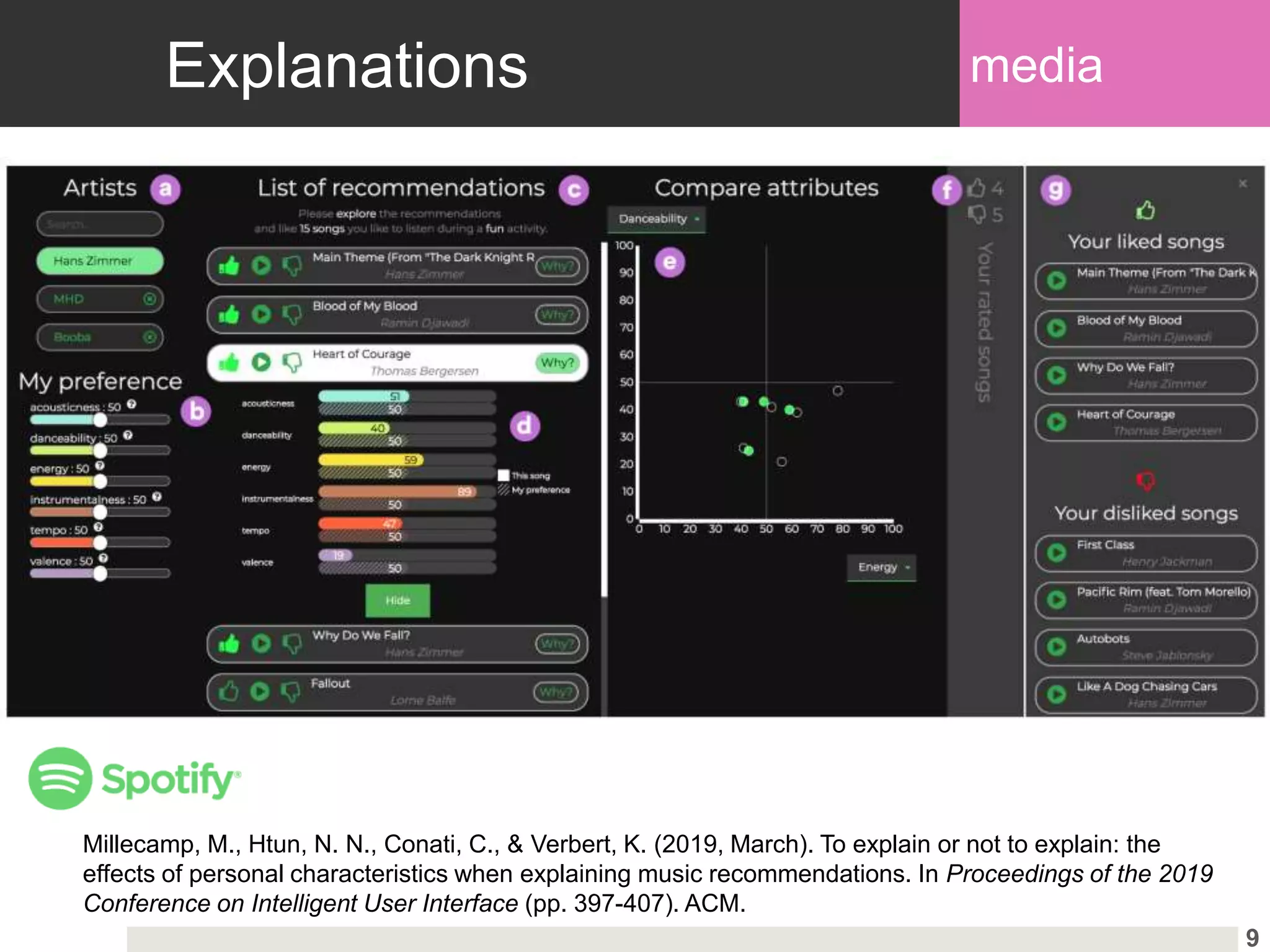
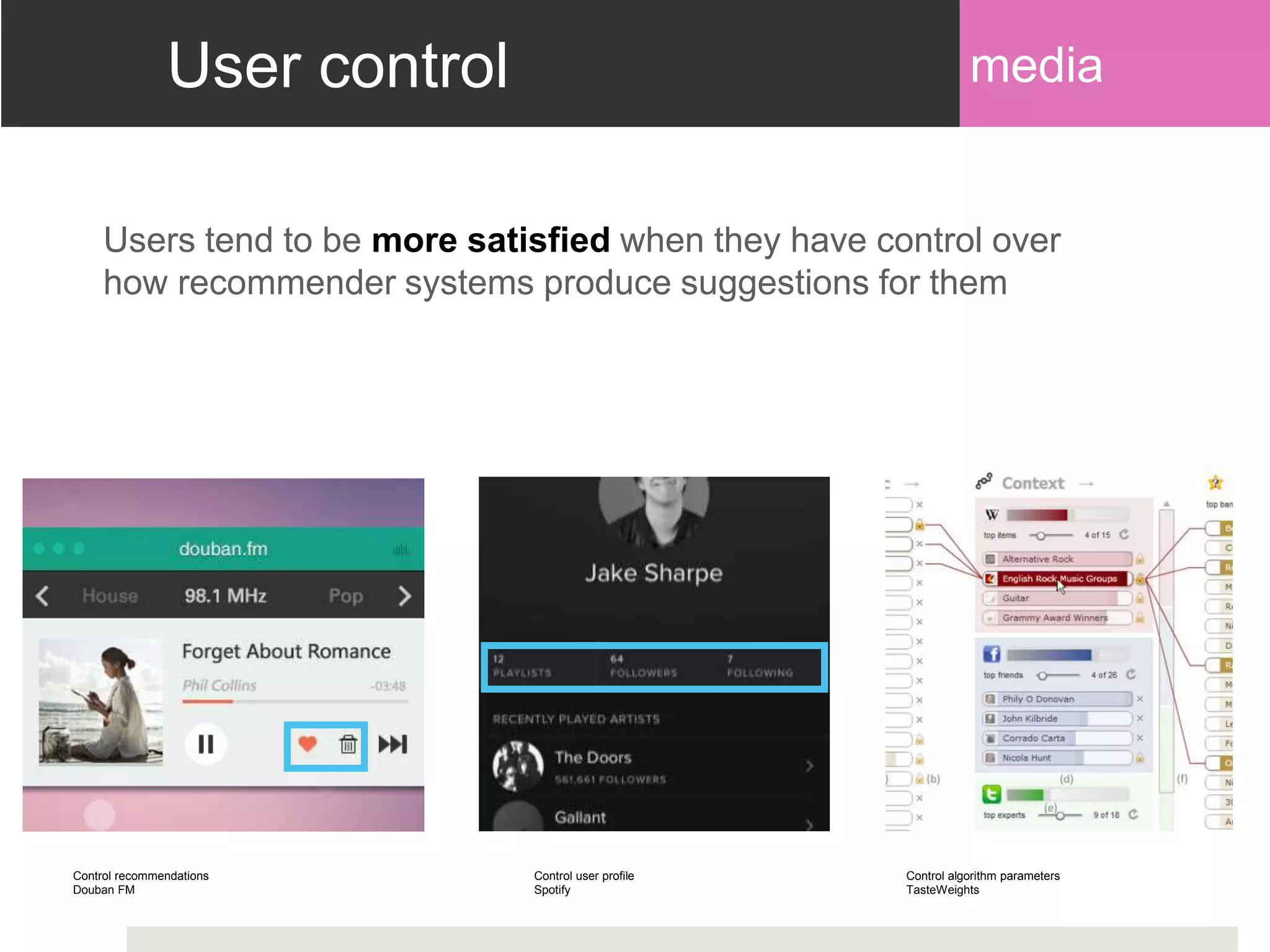
Highlighting personalized explanations, user control over recommendations, and study outcomes on user satisfaction.
Examining various fields (like learning analytics) where context-specific AI applications can enhance decision-making.
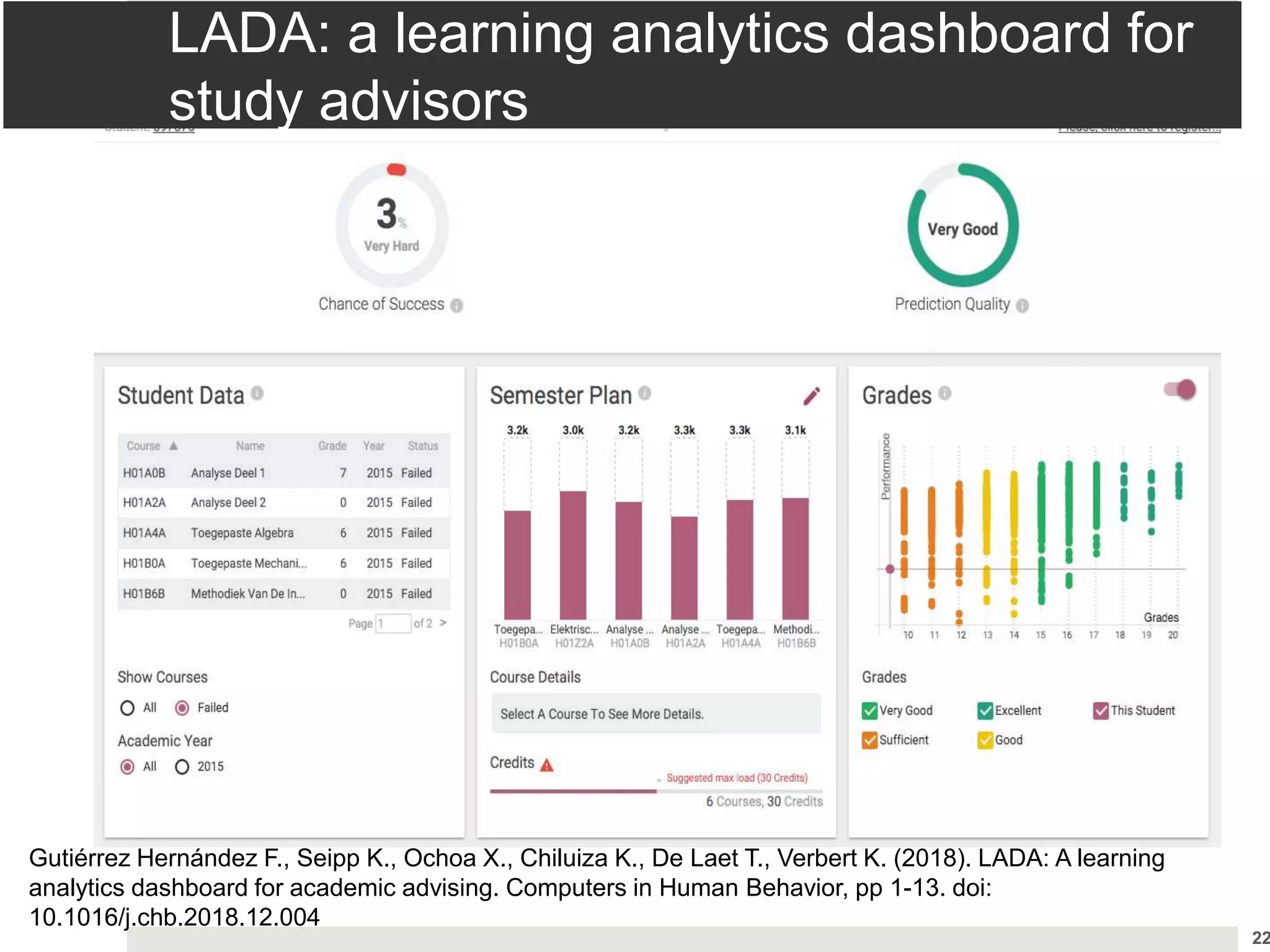
Study findings on the effectiveness of learning dashboards and the need for improved transparency and user needs.
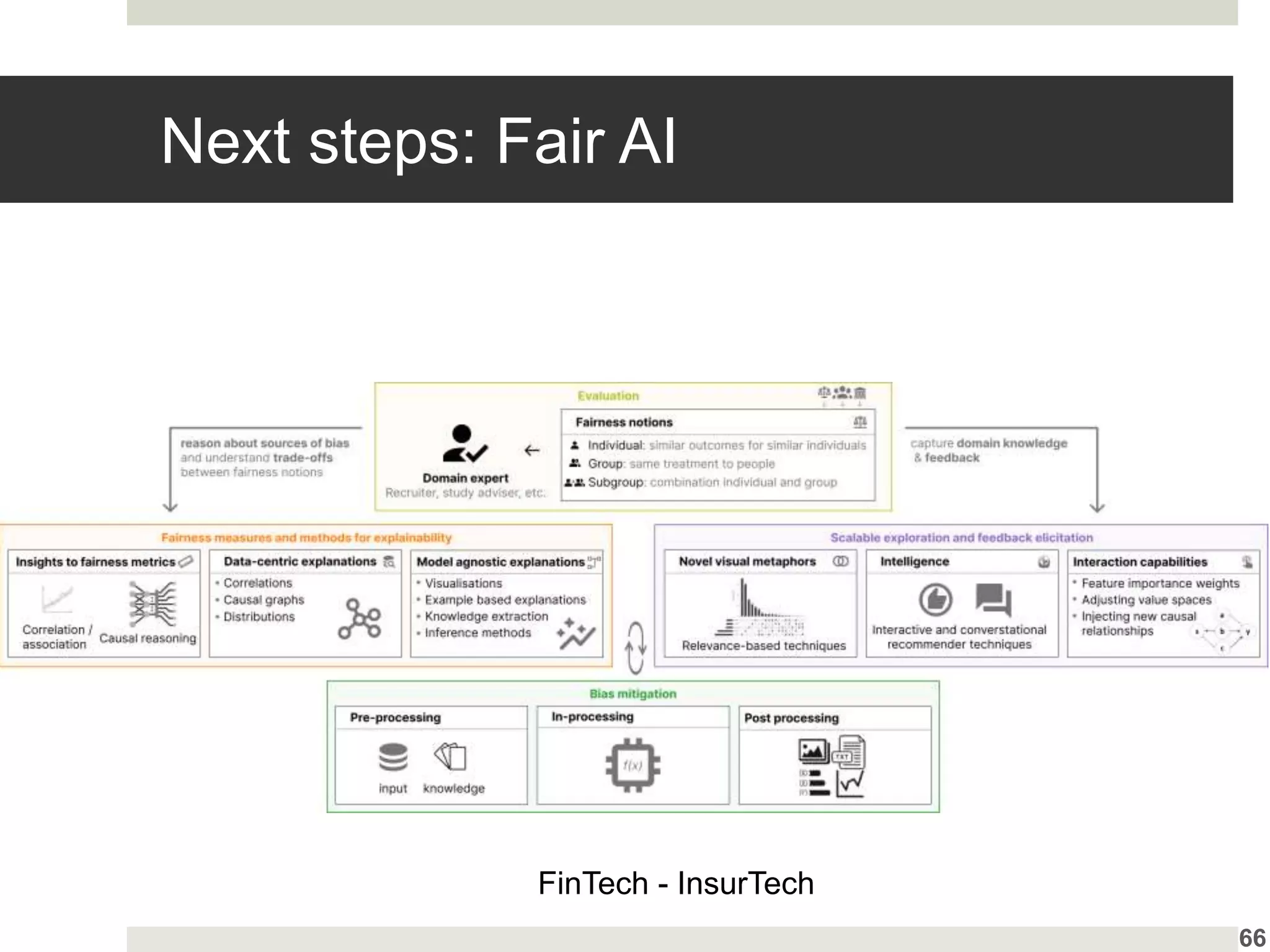
Proposing strategic approaches in AI explanations while underscoring the need for user-centered design.
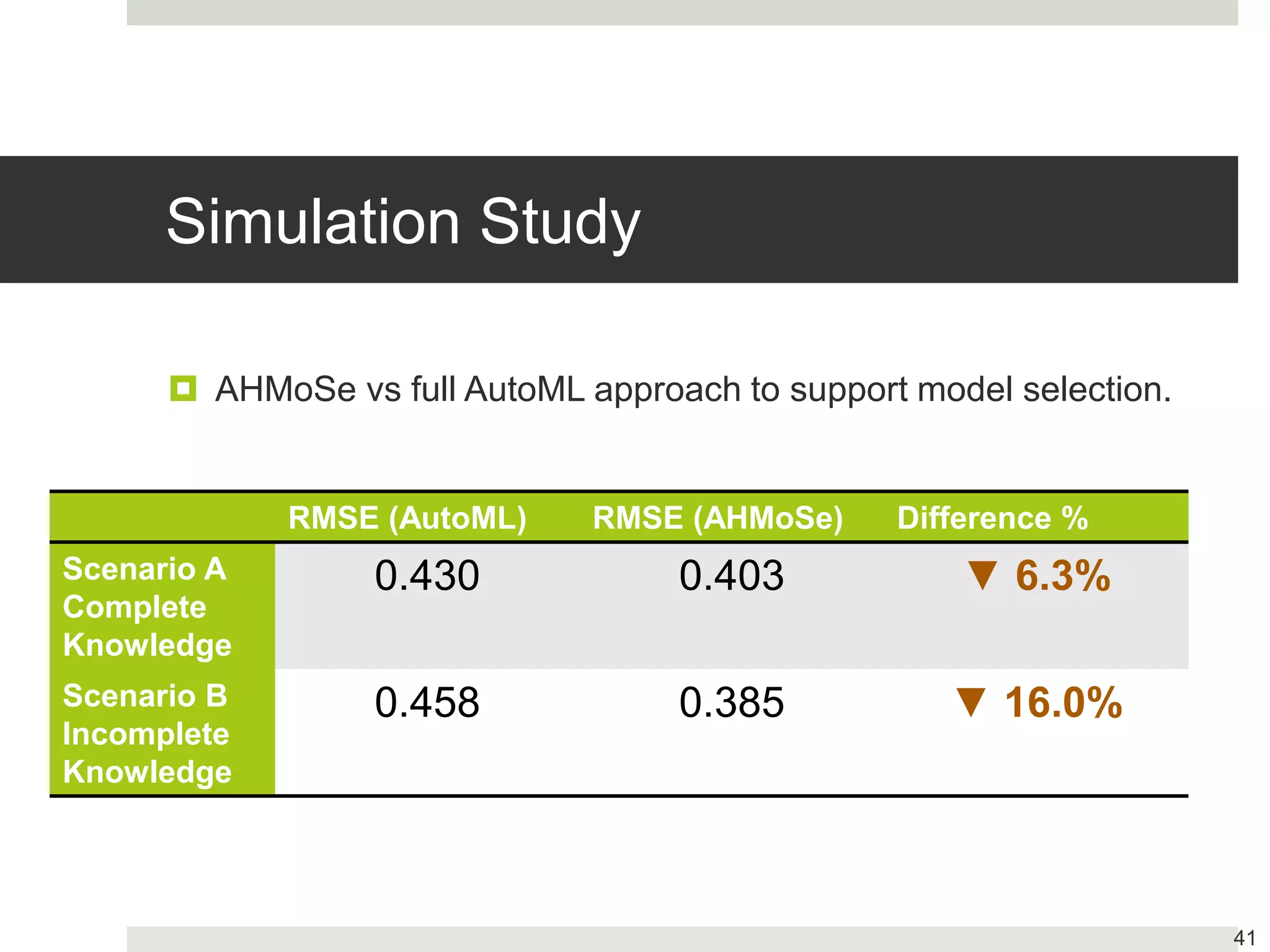
Discussion on model explanations in precision agriculture, presenting case studies and evaluation metrics.
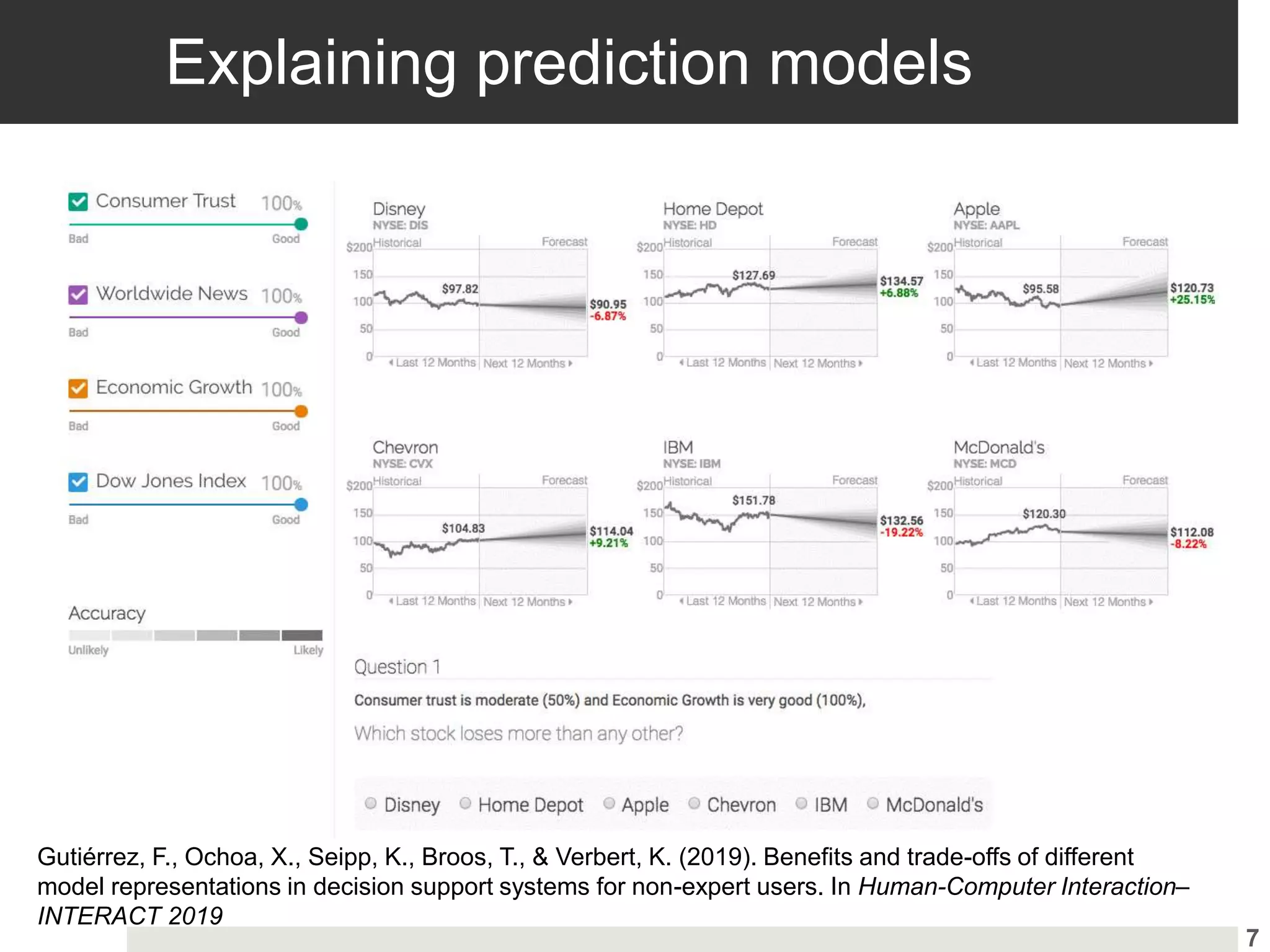
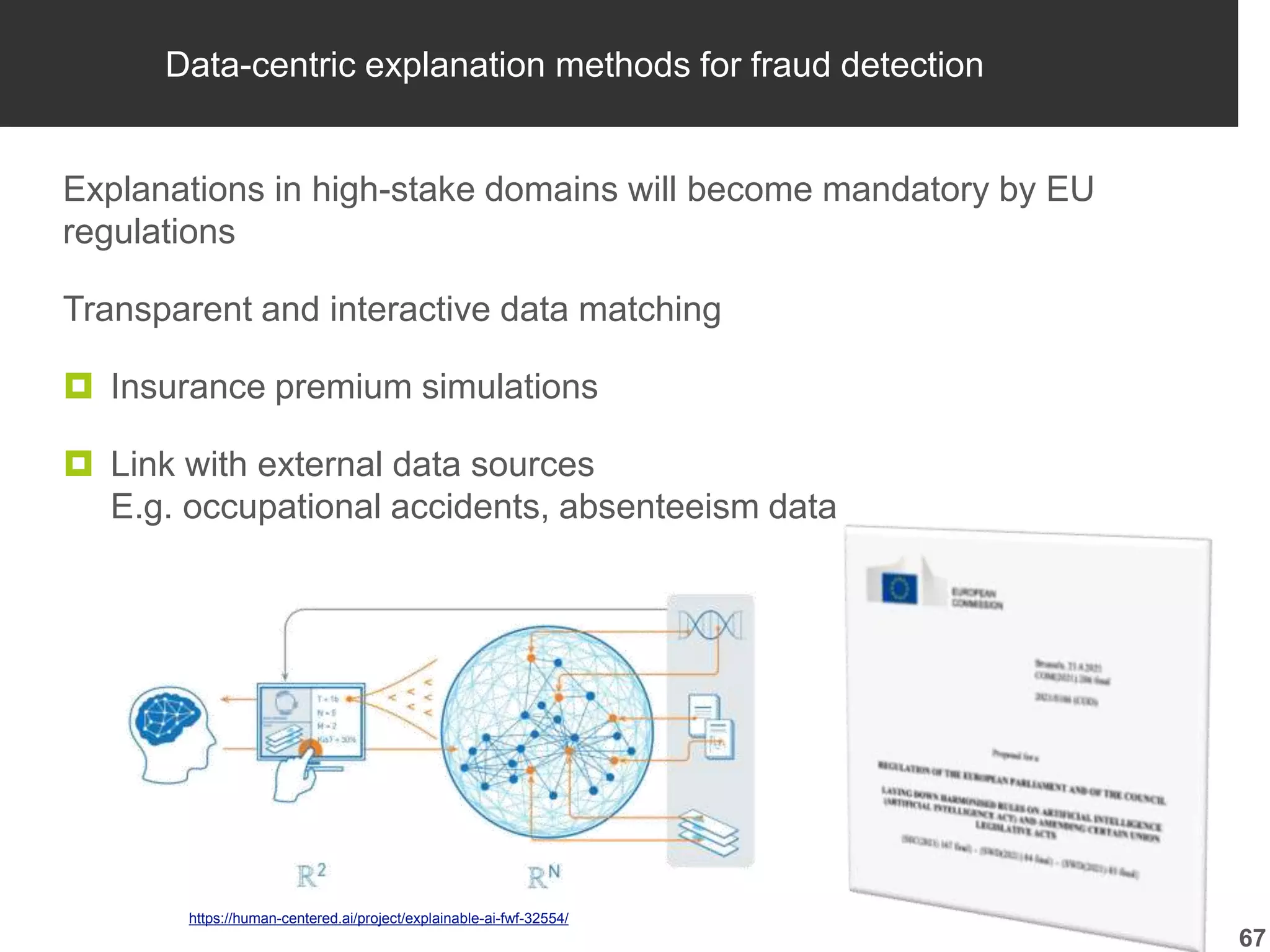
Importance of explanations in high-stakes contexts and trust-building through model evaluation.
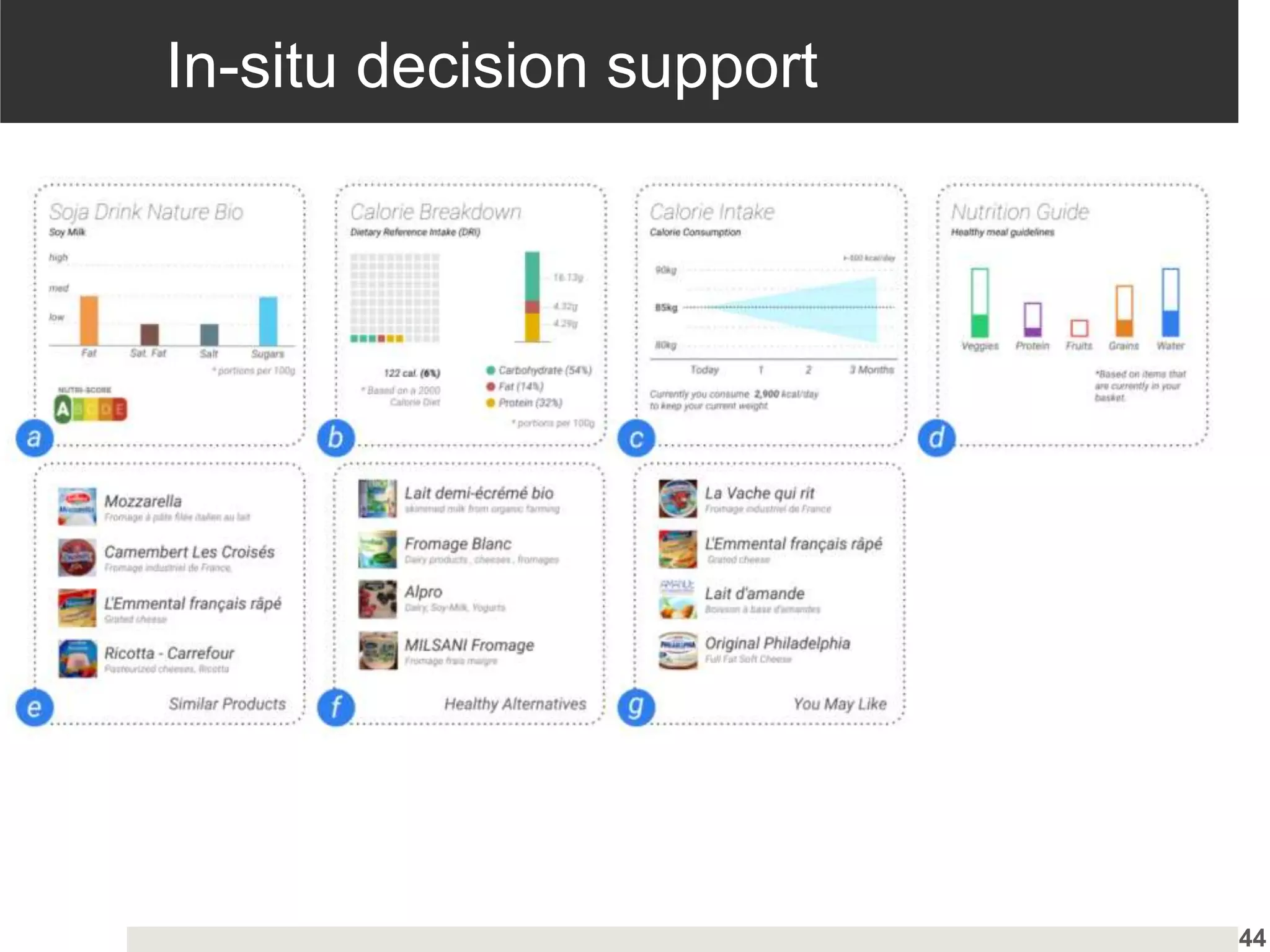
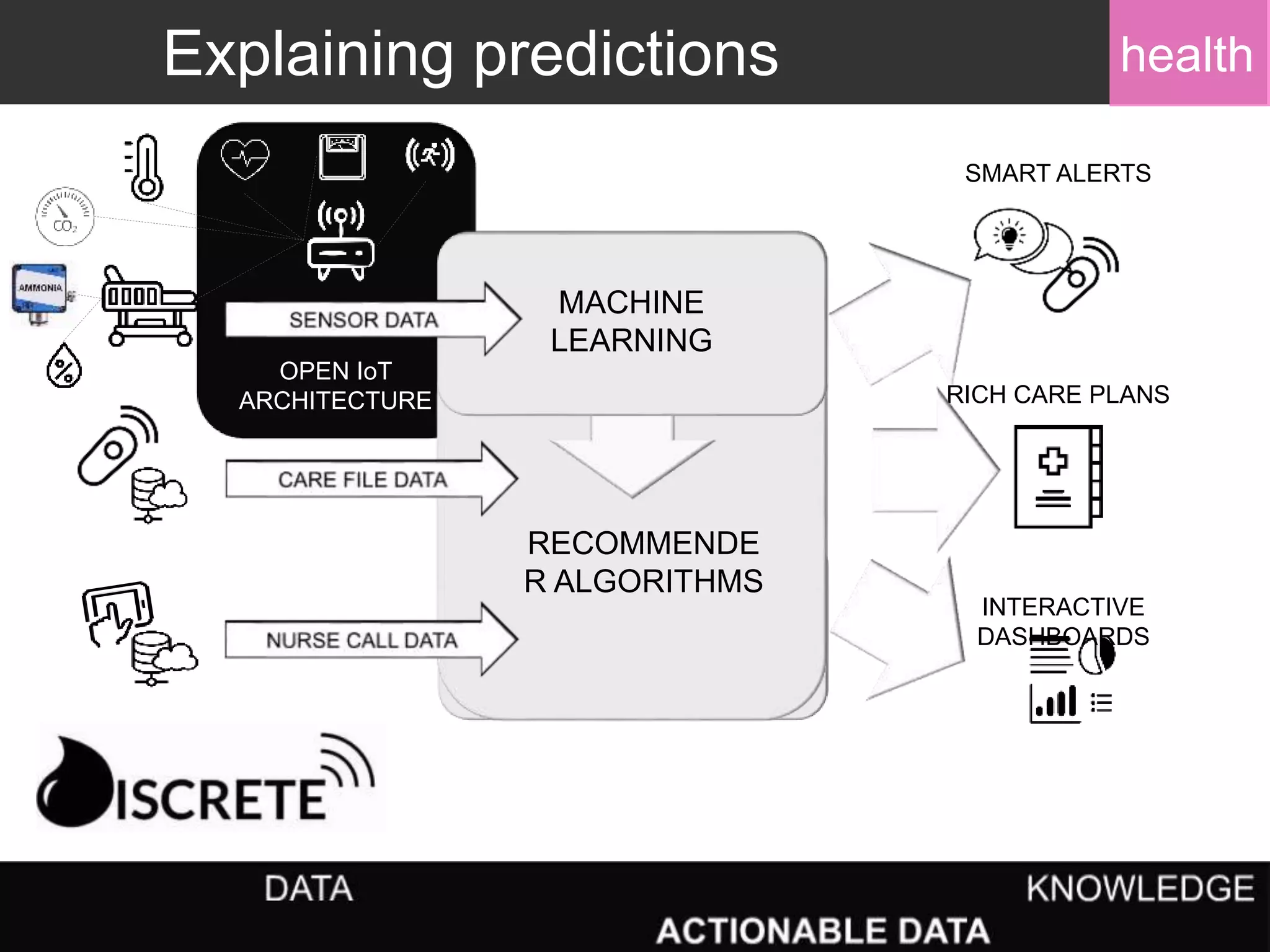
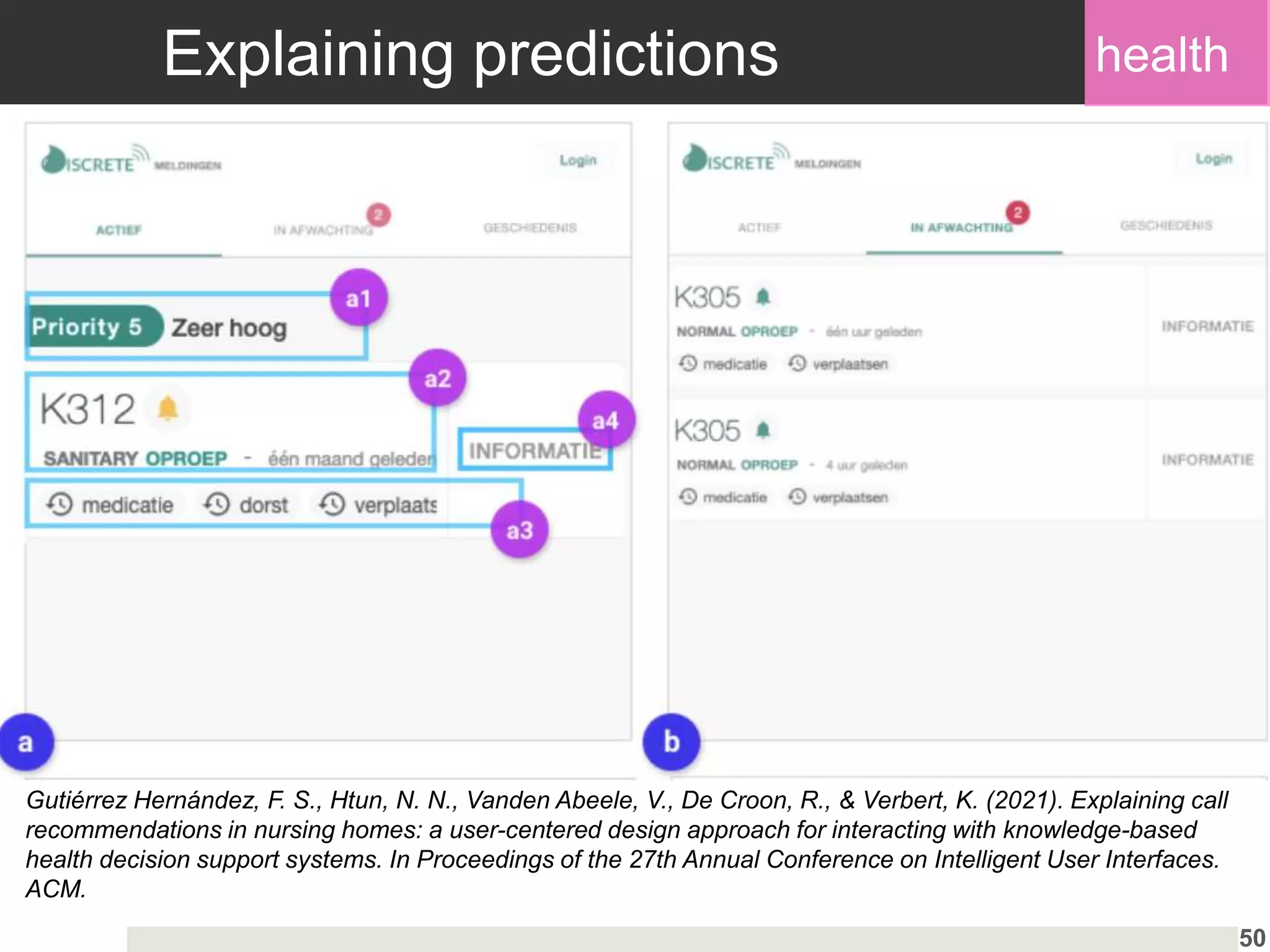
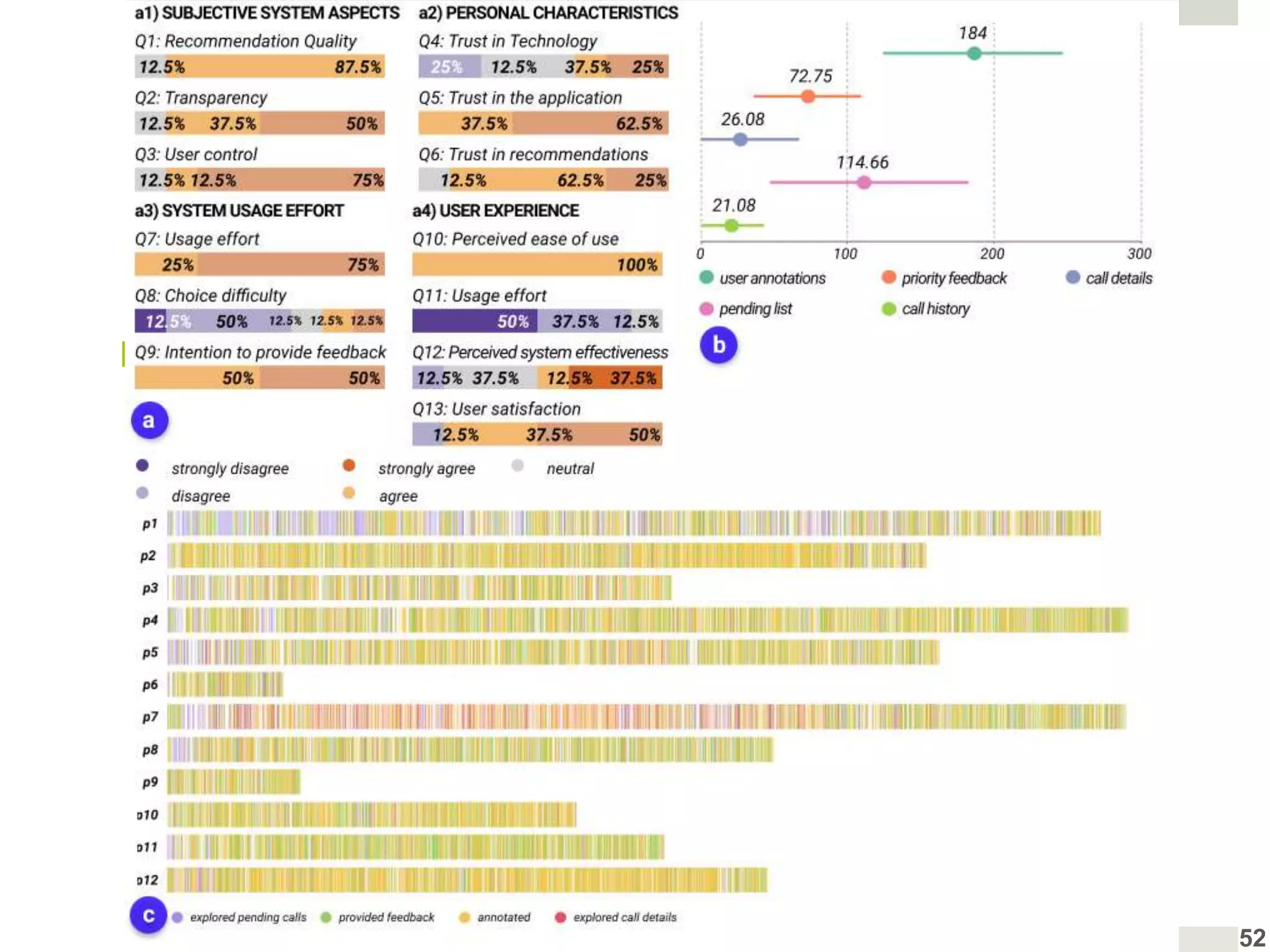
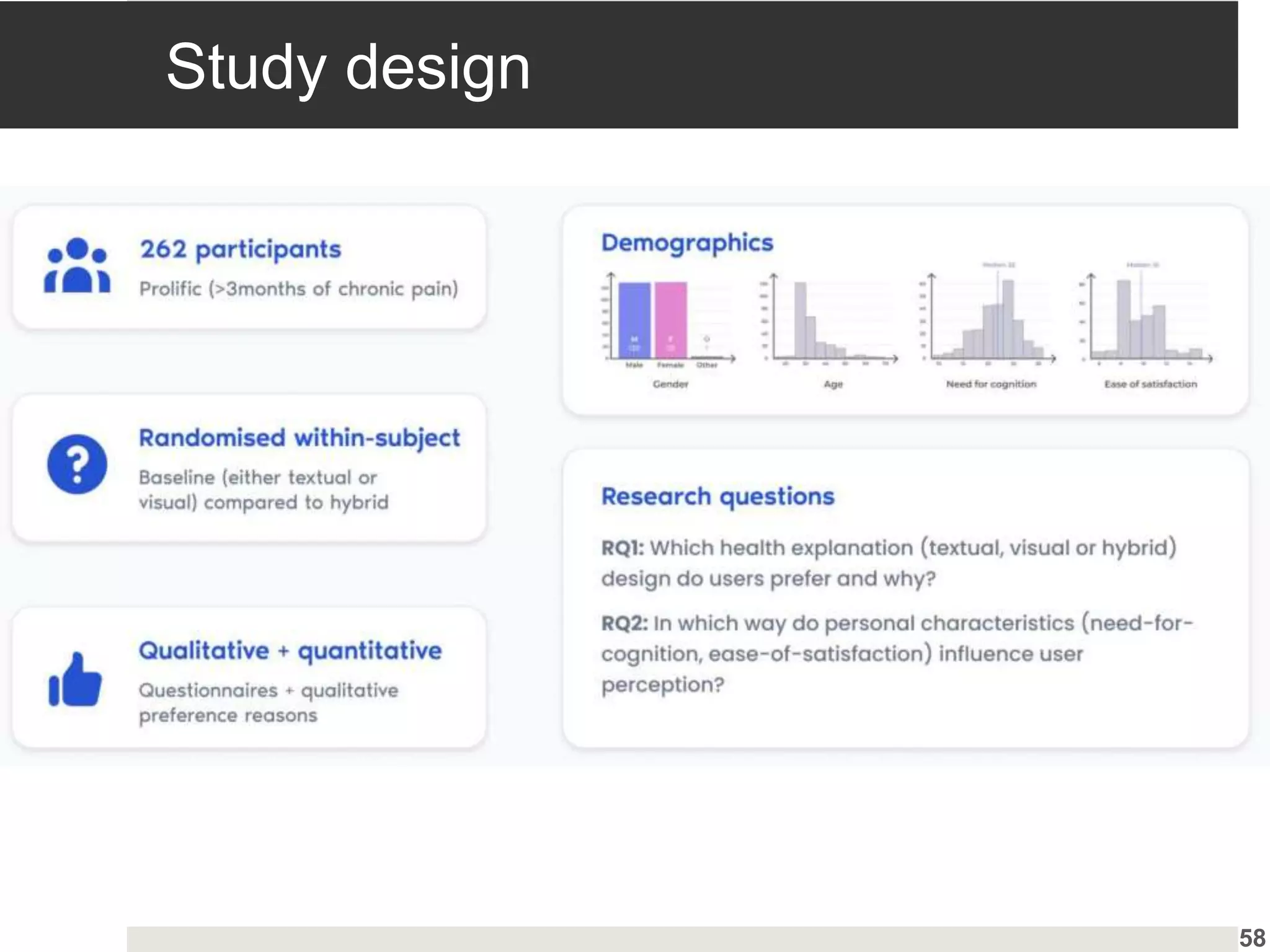
Evaluation of health decision-support systems through user interactions and feedback, emphasizing transparency.
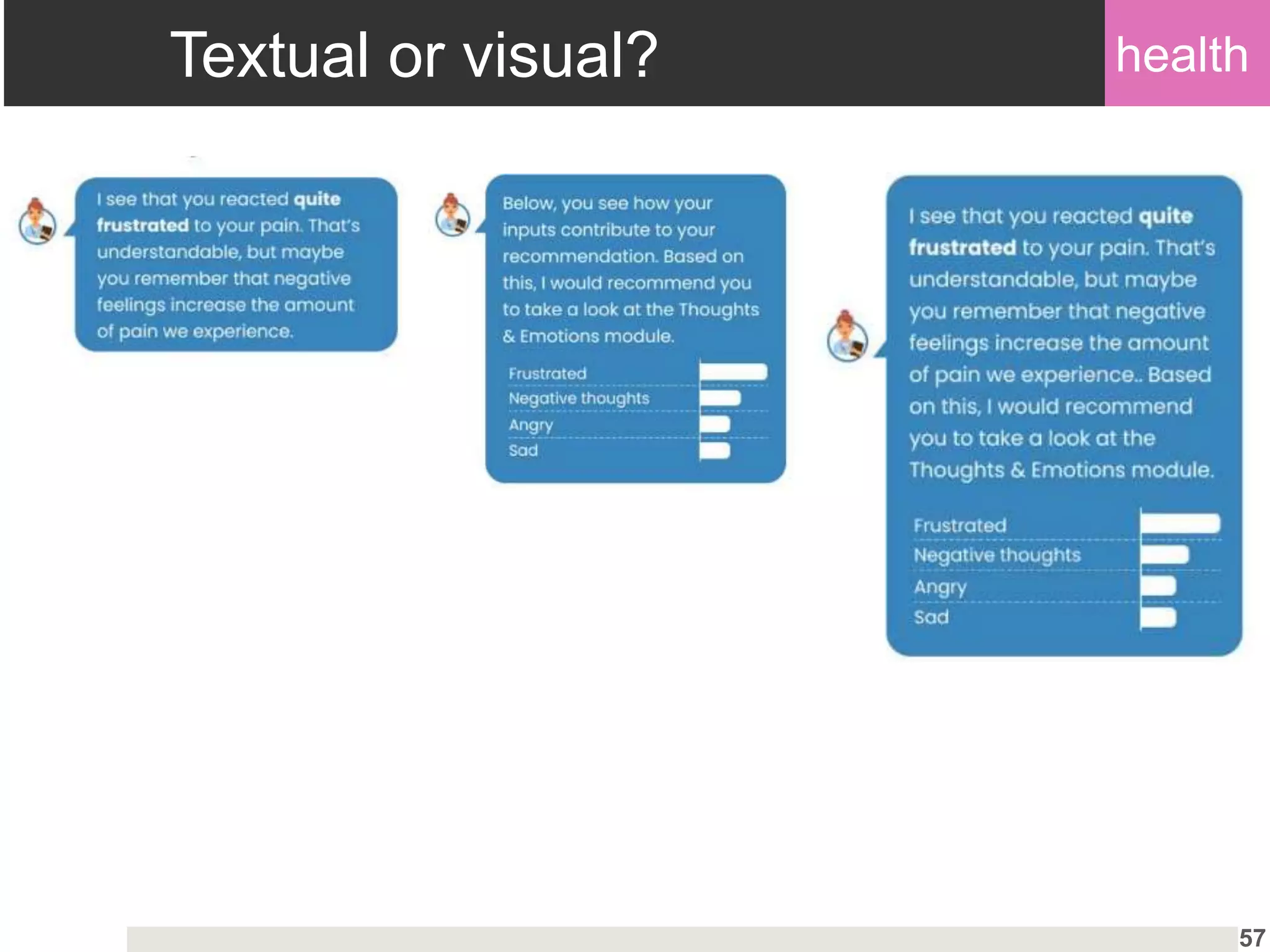
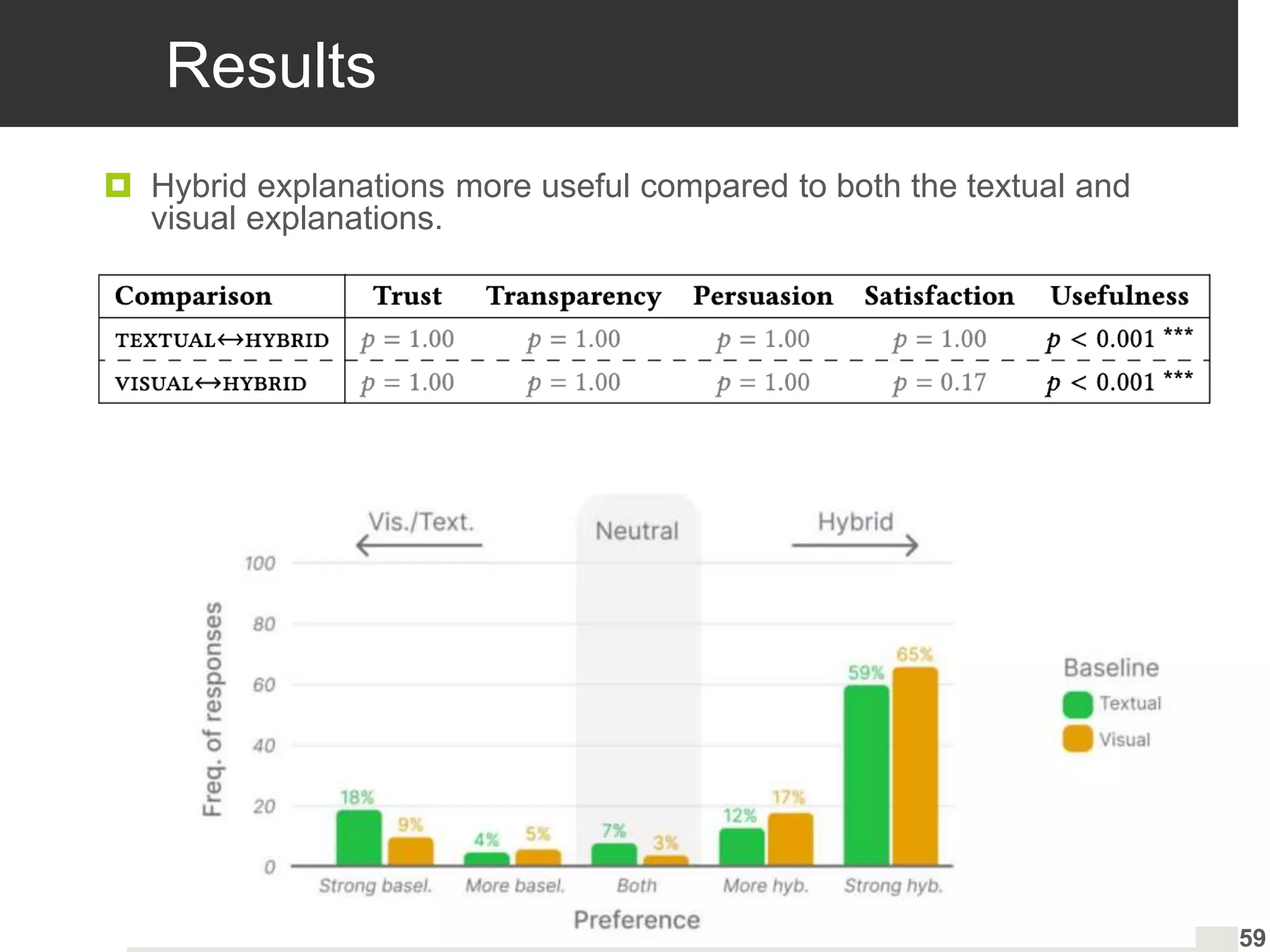
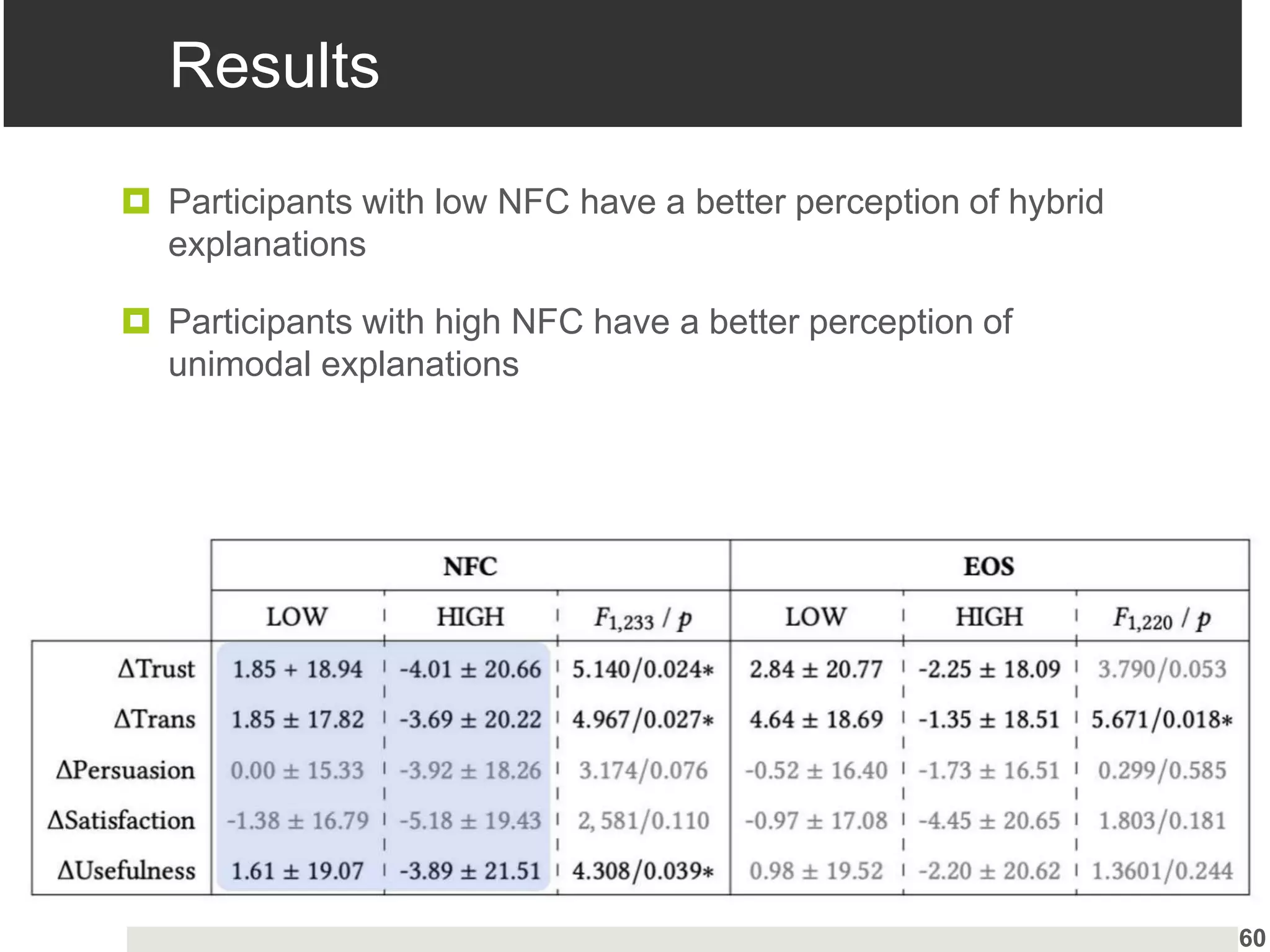
Insights into user preferences for explanation types and hybrid explanations based on individual characteristics.
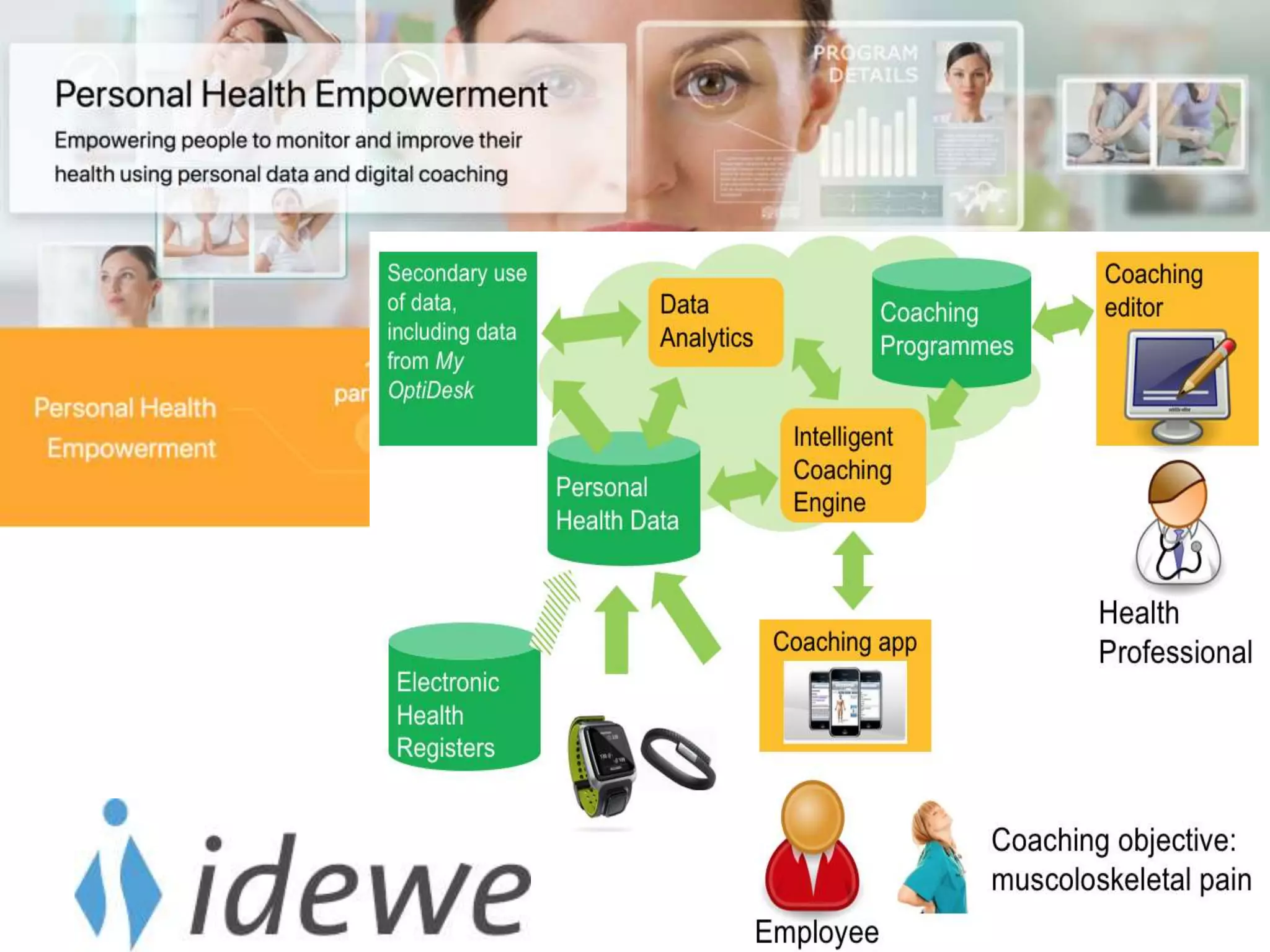
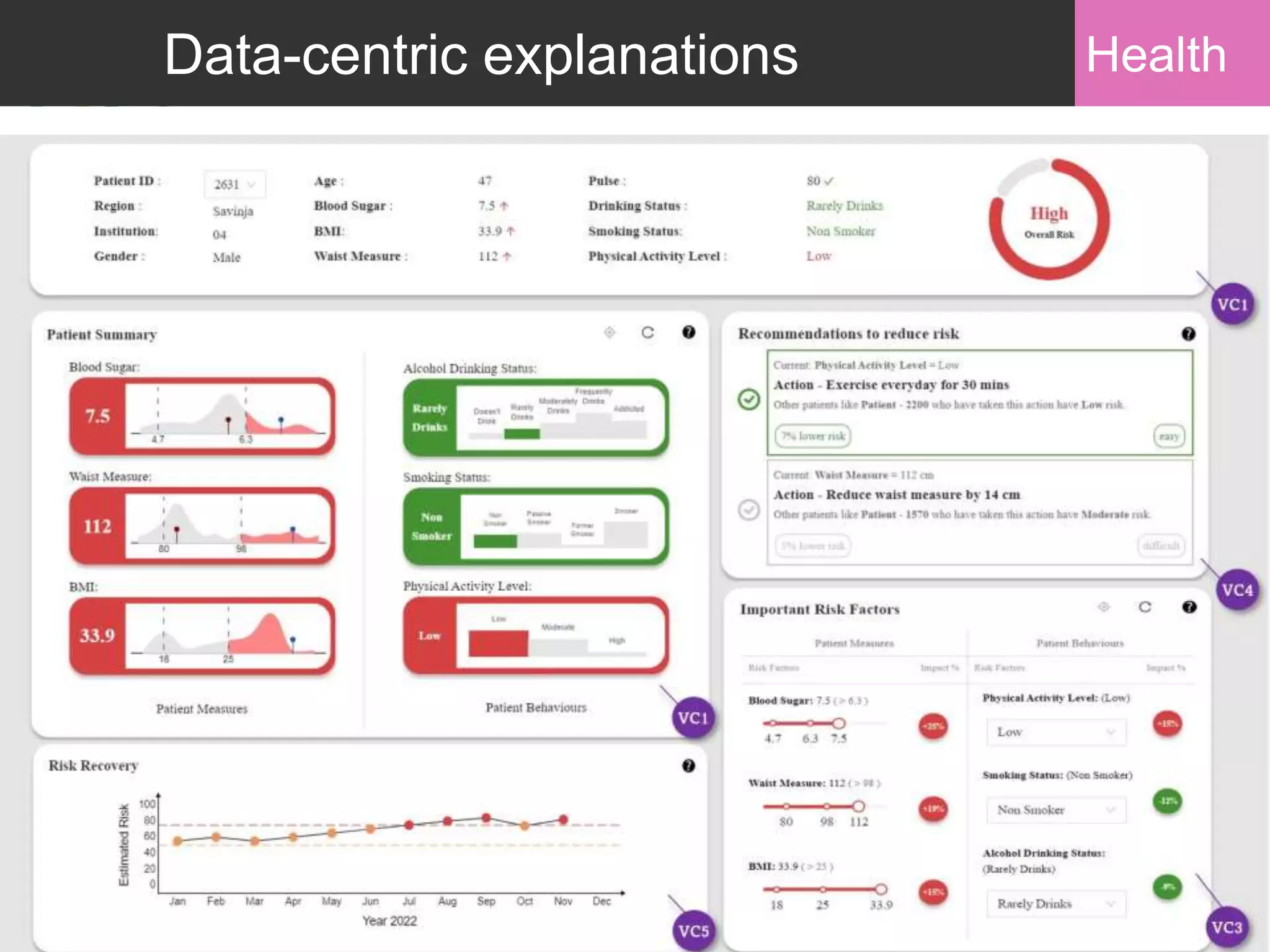
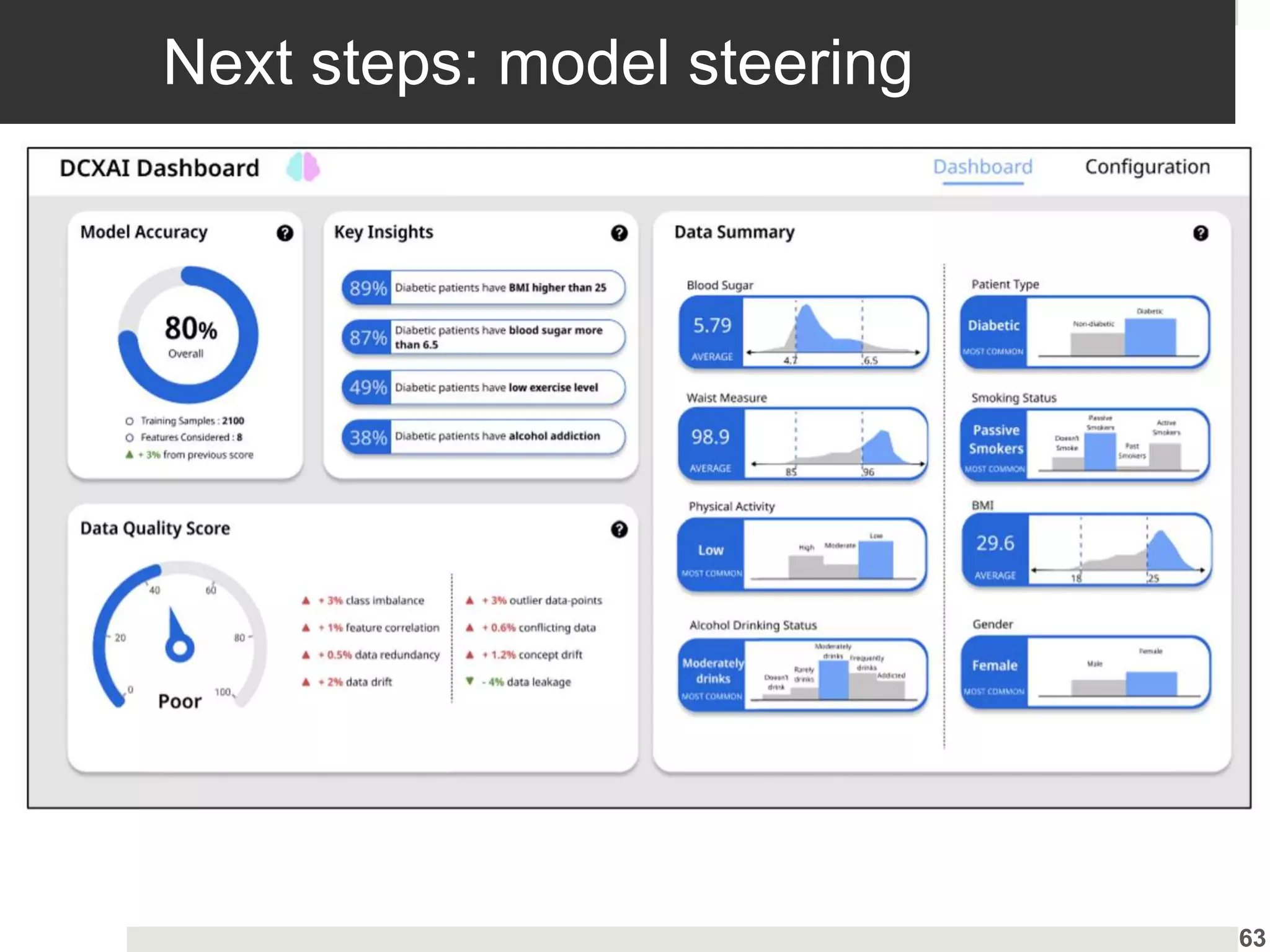
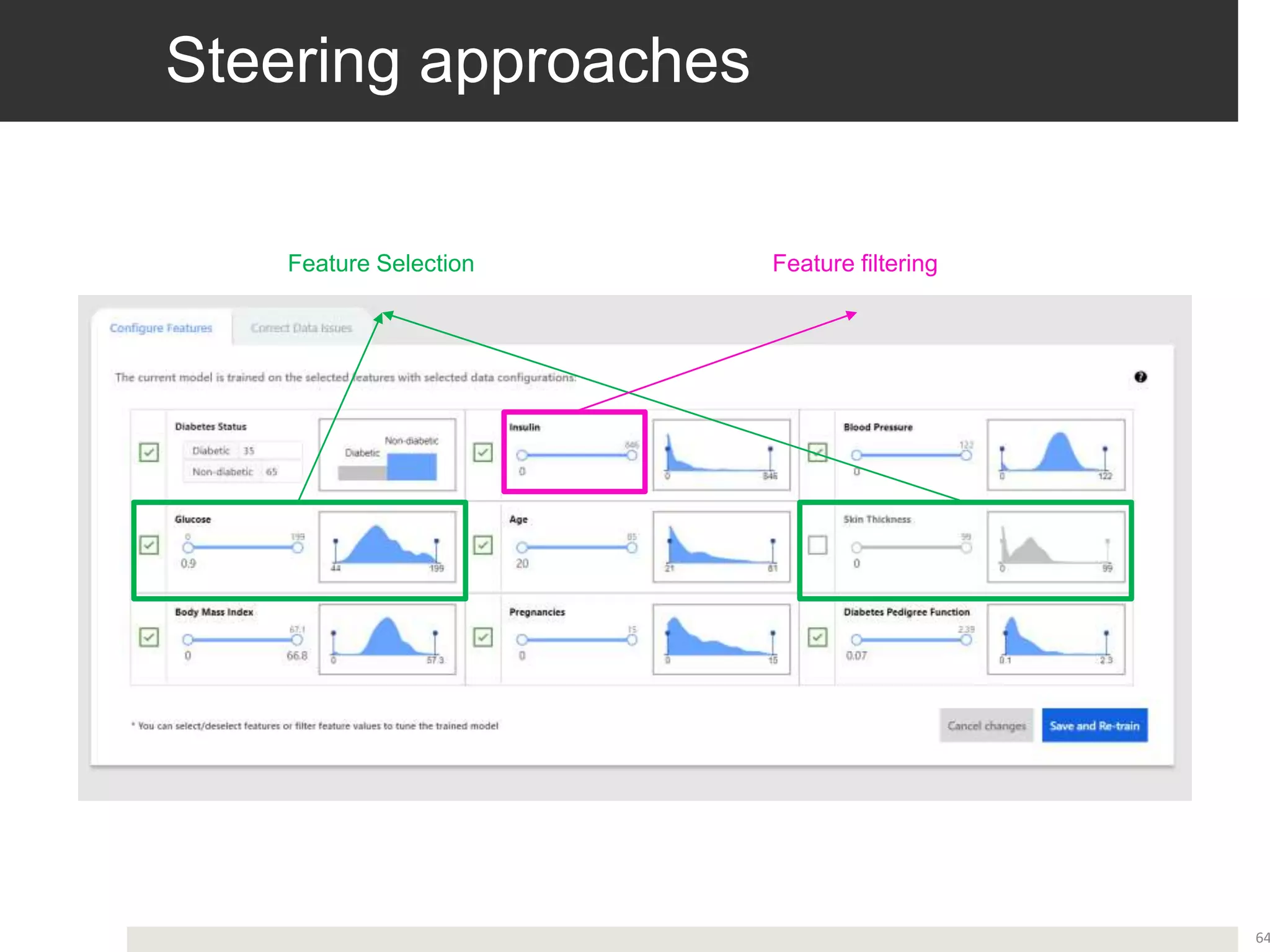
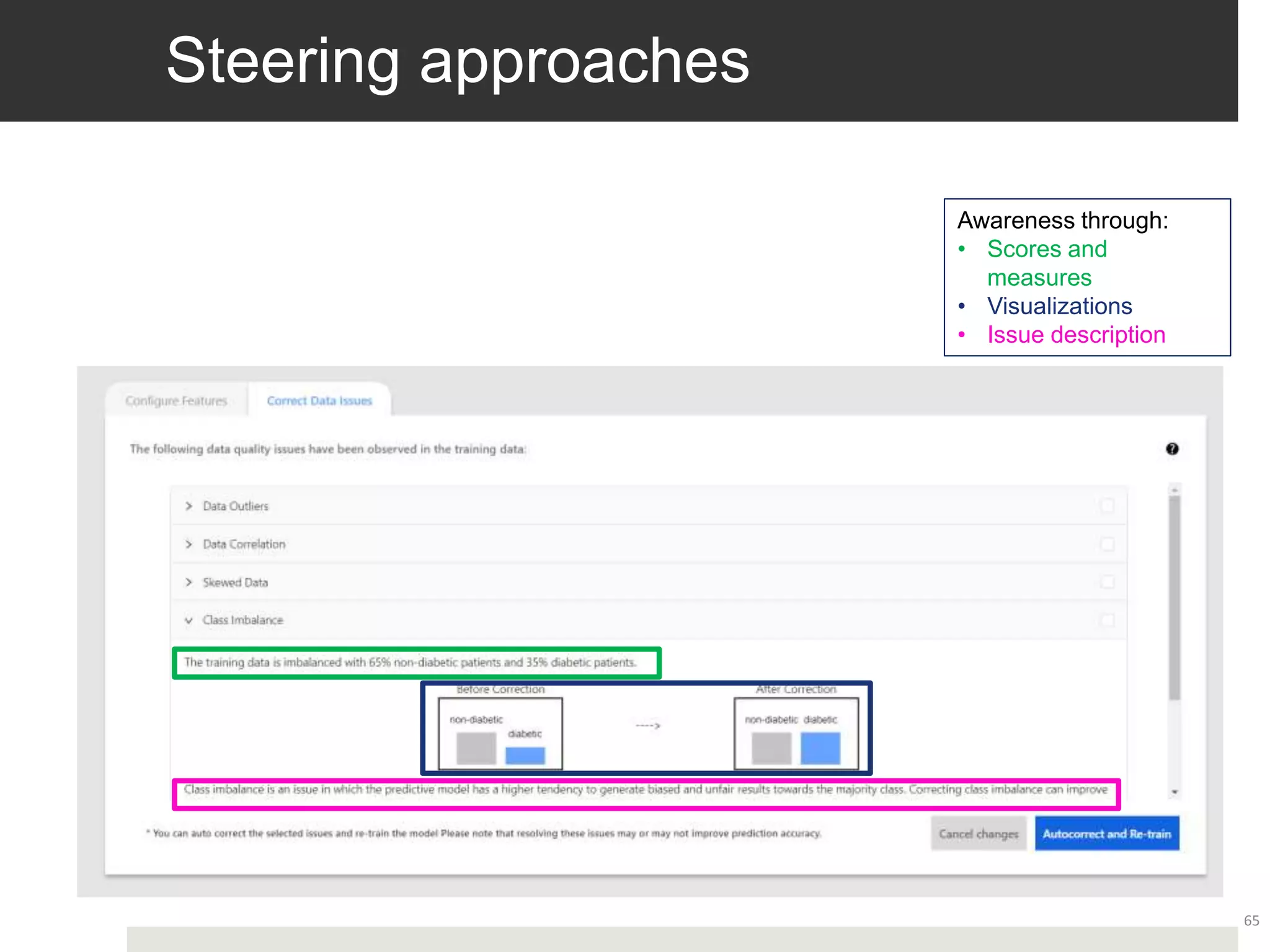
Advancements in data-centric explanatory methods and user involvement to tailor AI solutions in healthcare.
Collaboration acknowledgments and invitation for questions regarding the research presented.

































































