Downloaded 54 times


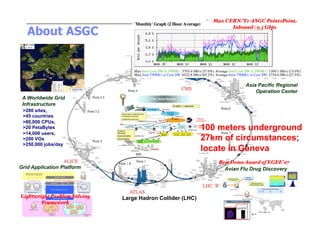
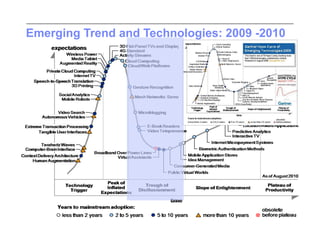
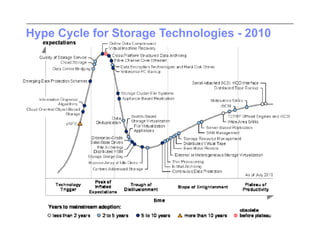

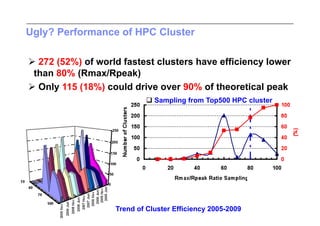
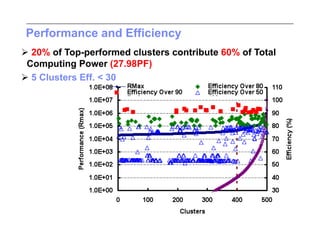
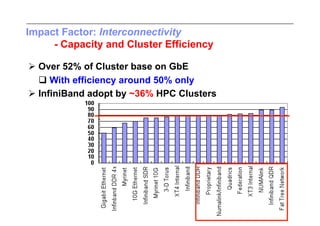
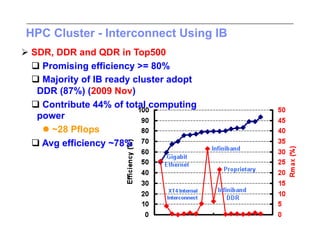
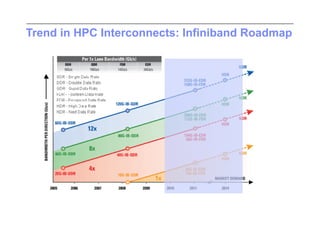

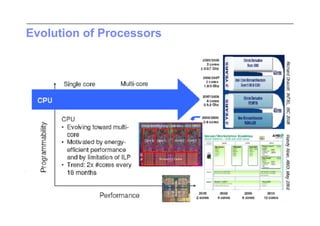
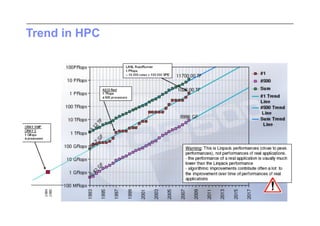




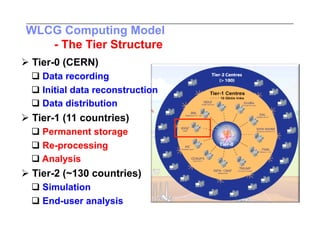





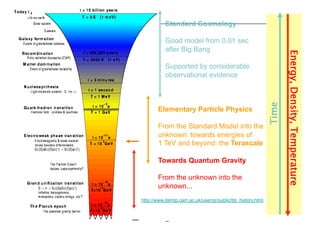


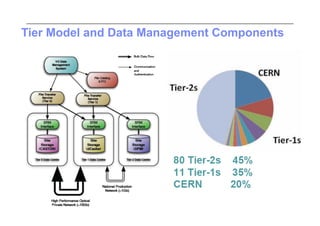
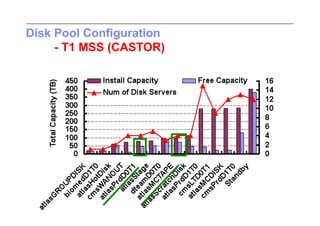
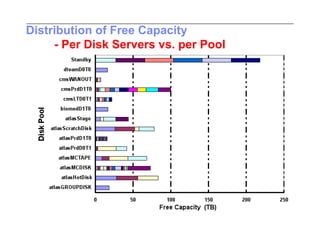
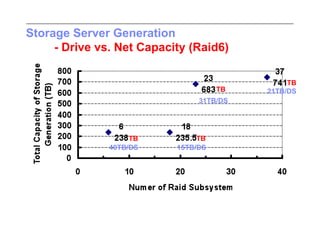


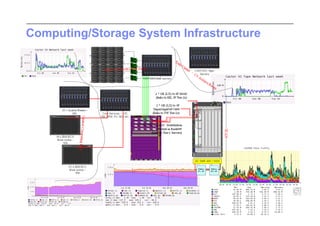
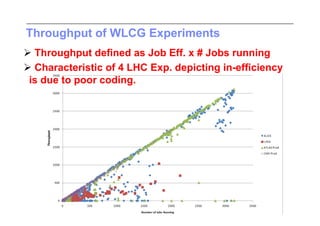
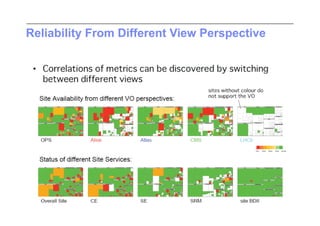
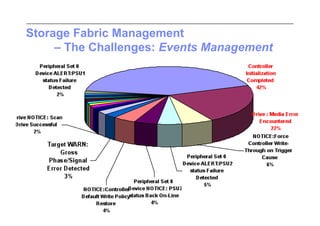

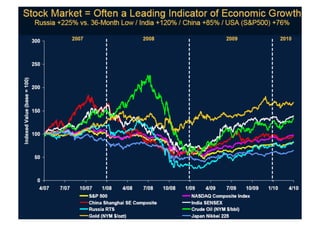
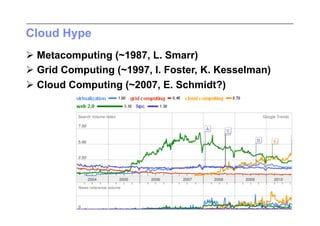

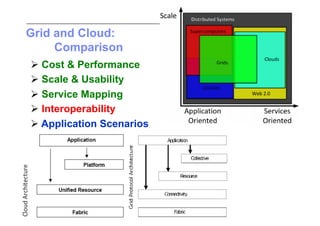
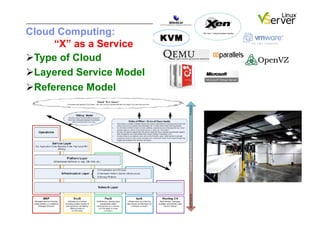
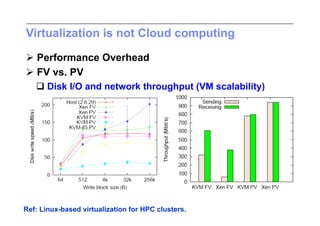
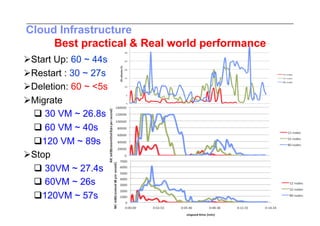
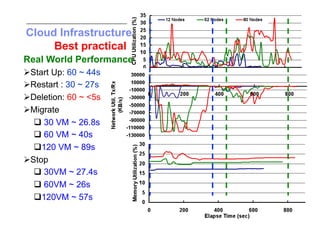
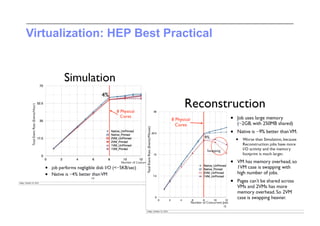

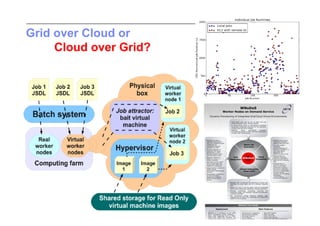
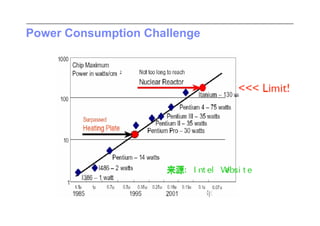



This document discusses trends in high performance computing (HPC), grid computing, and cloud computing. It provides an overview of HPC cluster performance and interconnects. Grid computing enabled large-scale scientific collaboration through infrastructures like EGEE. The LHC requires petascale computing capabilities. Cloud computing hype is discussed alongside observations of performance and virtualization challenges. The future of computing may involve more sophisticated tools and dynamic, small computing elements.



































































