Download as PDF, PPTX
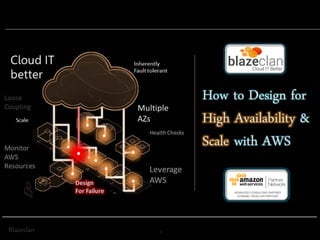
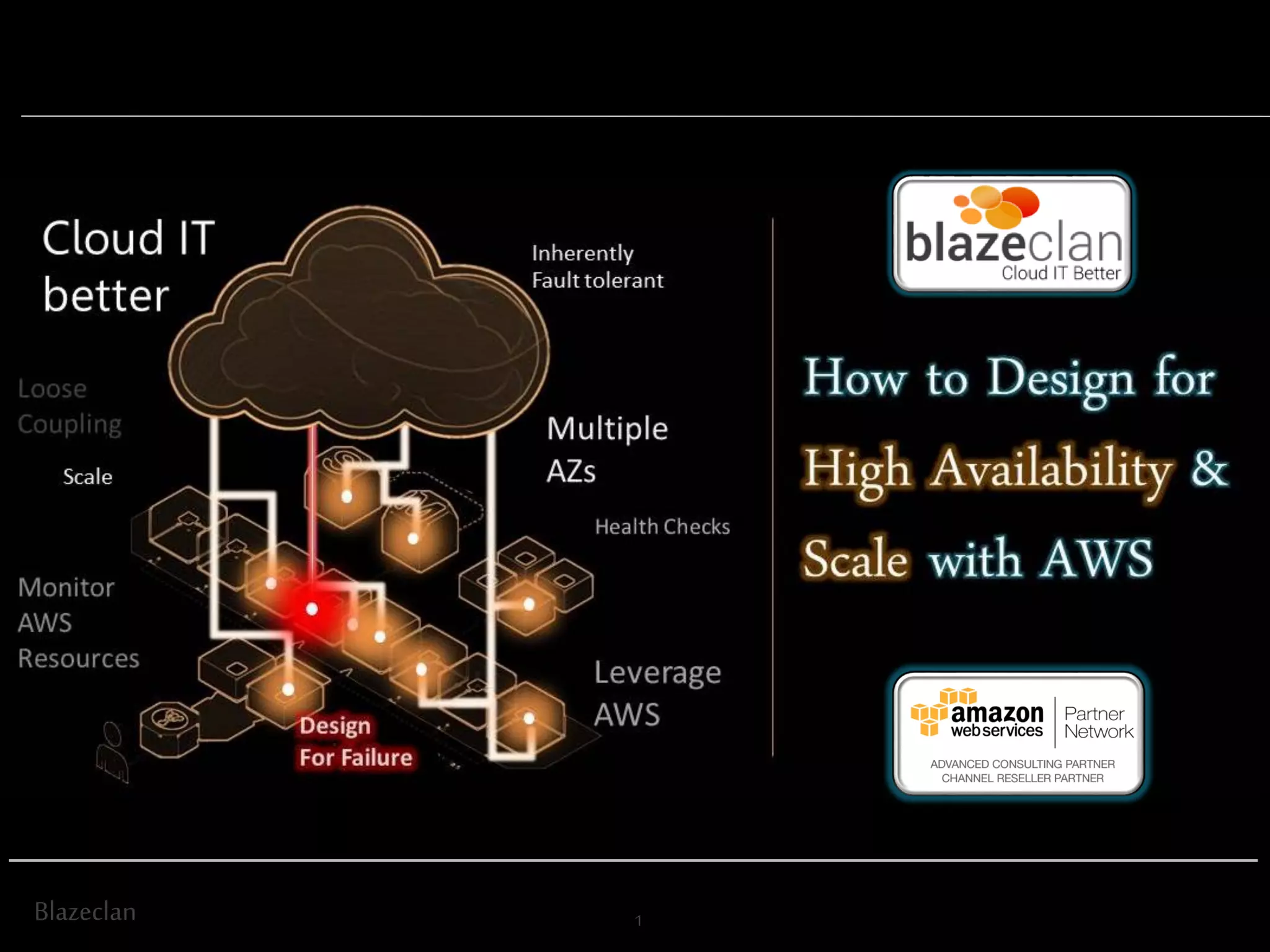






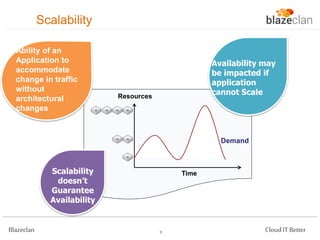


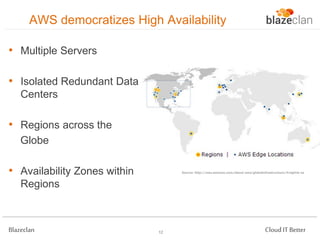





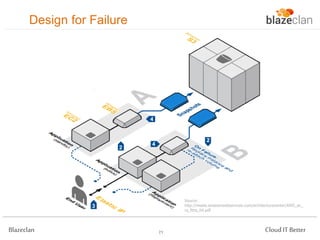
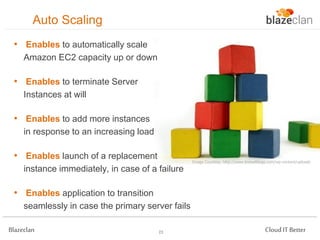
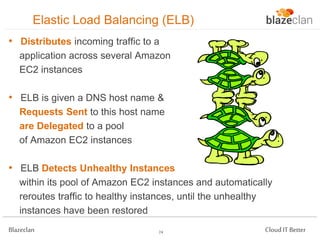
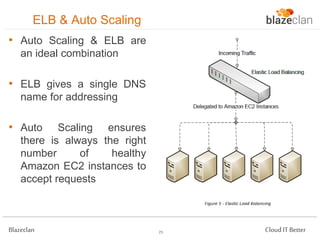



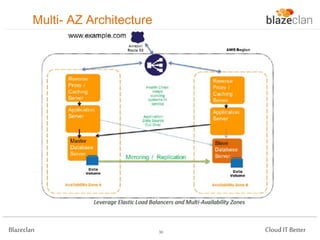


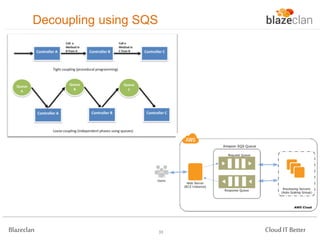


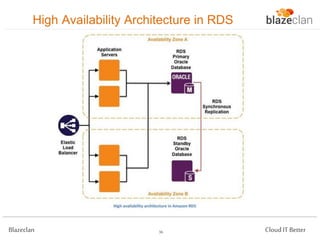
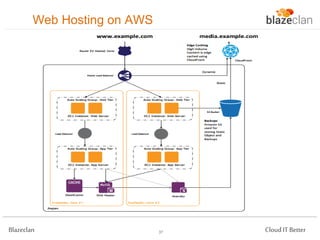
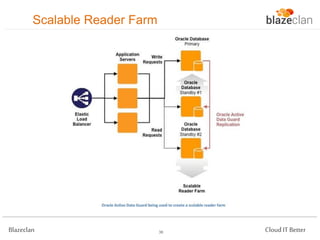




The document discusses best practices for building highly available, scalable, and fault-tolerant web applications on AWS. It emphasizes the importance of designing for failure, using multi-AZ architectures, and employing services like auto-scaling and elastic load balancing. Moreover, it highlights the financial impact of downtime and offers advice on avoiding single points of failure and implementing redundancy.






































![[TechTalks] Learning Configuration Management with SaltStack (Advanced Concepts)](https://cdn.slidesharecdn.com/ss_thumbnails/learningconfigurationmanagementwithsaltstackadvancedconcepts-160322054557-thumbnail.jpg?width=640&height=640&fit=bounds)




![[TechTalks] Effects of UI/ UX Designs on Customer Satisfaction & Loyalty](https://cdn.slidesharecdn.com/ss_thumbnails/effectsofuiuxdesignsoncustomersatisfactionandloyalty-151105071458-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)





















































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)