Download as PDF, PPTX

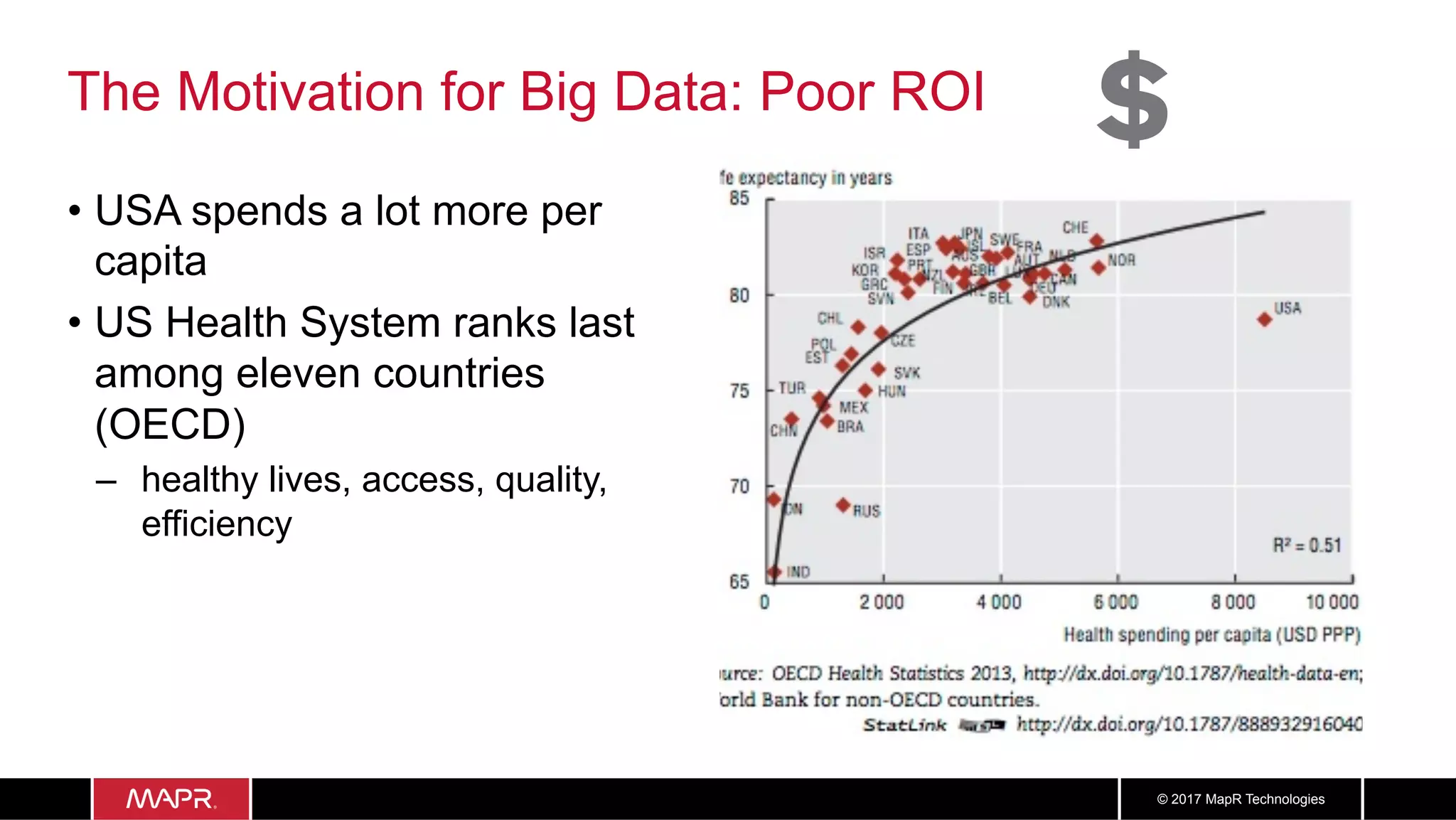

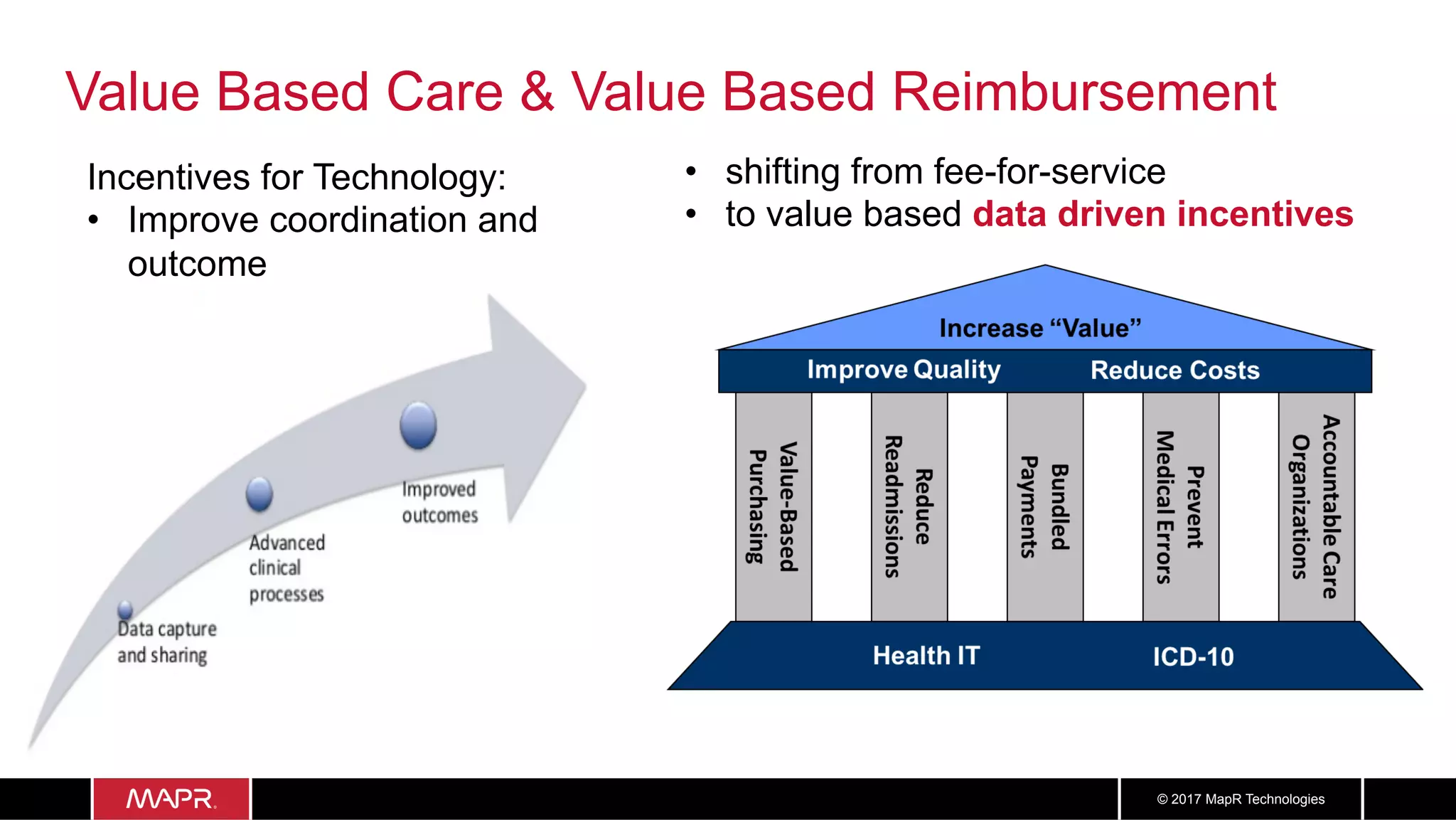


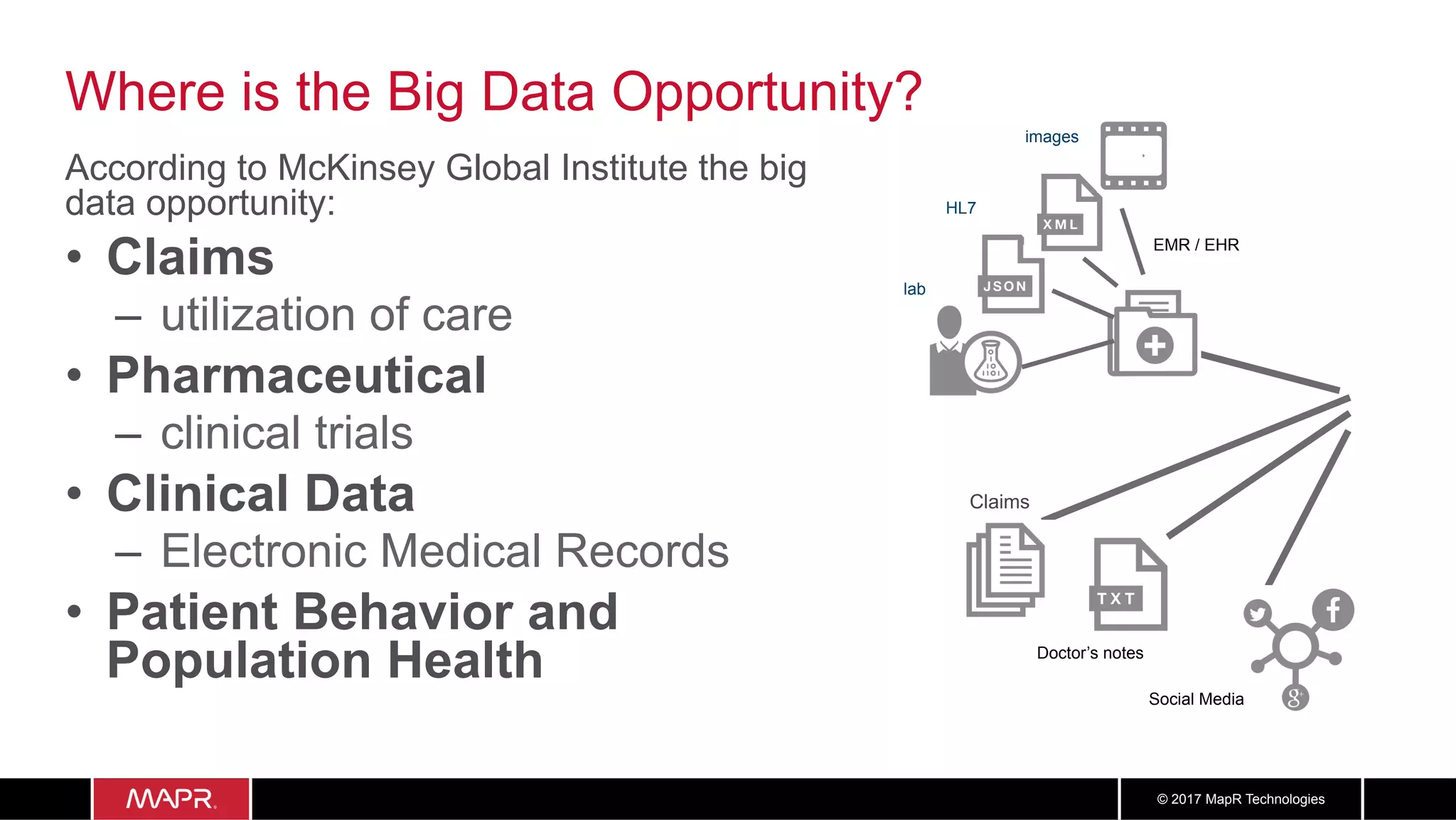
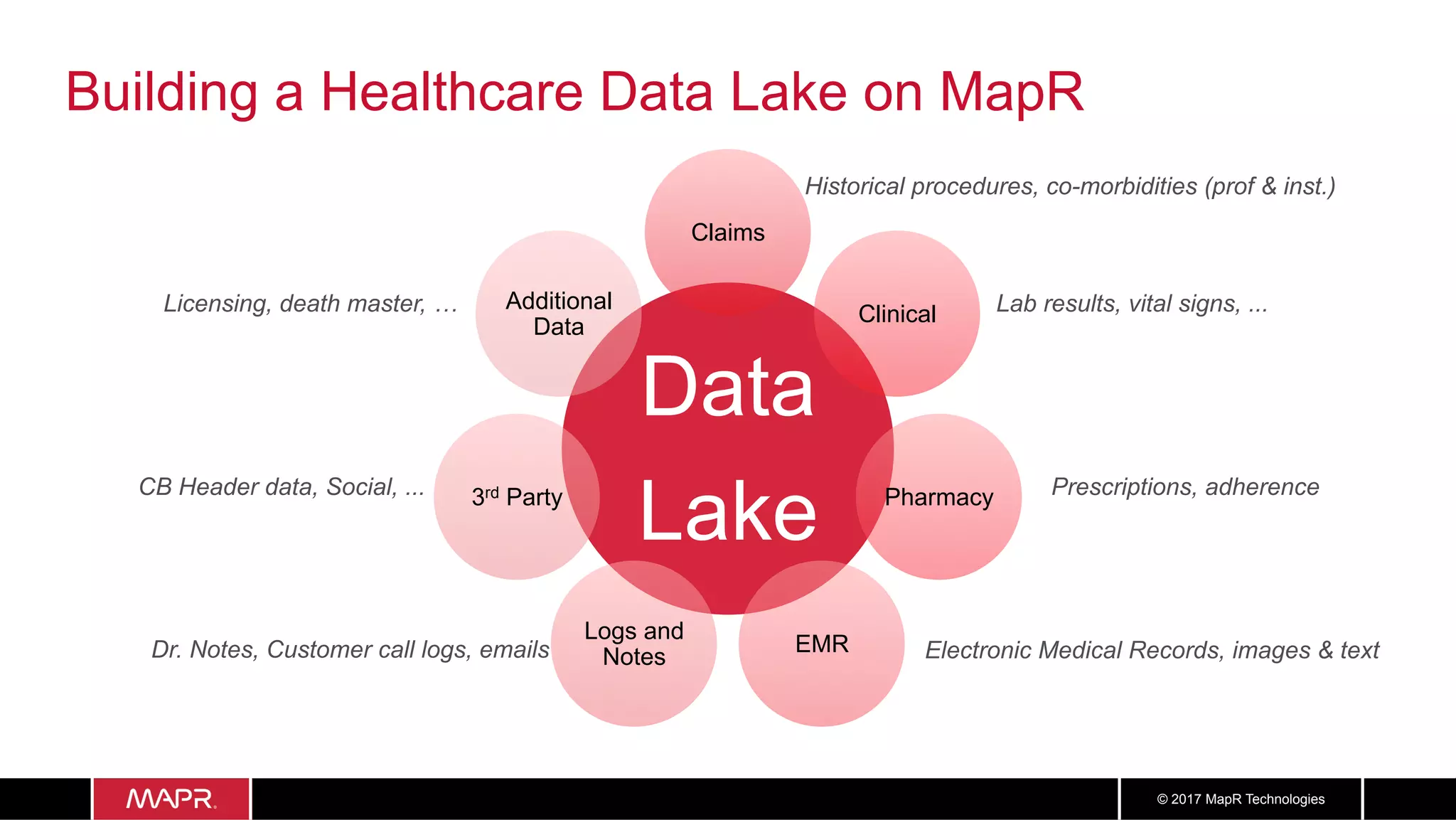

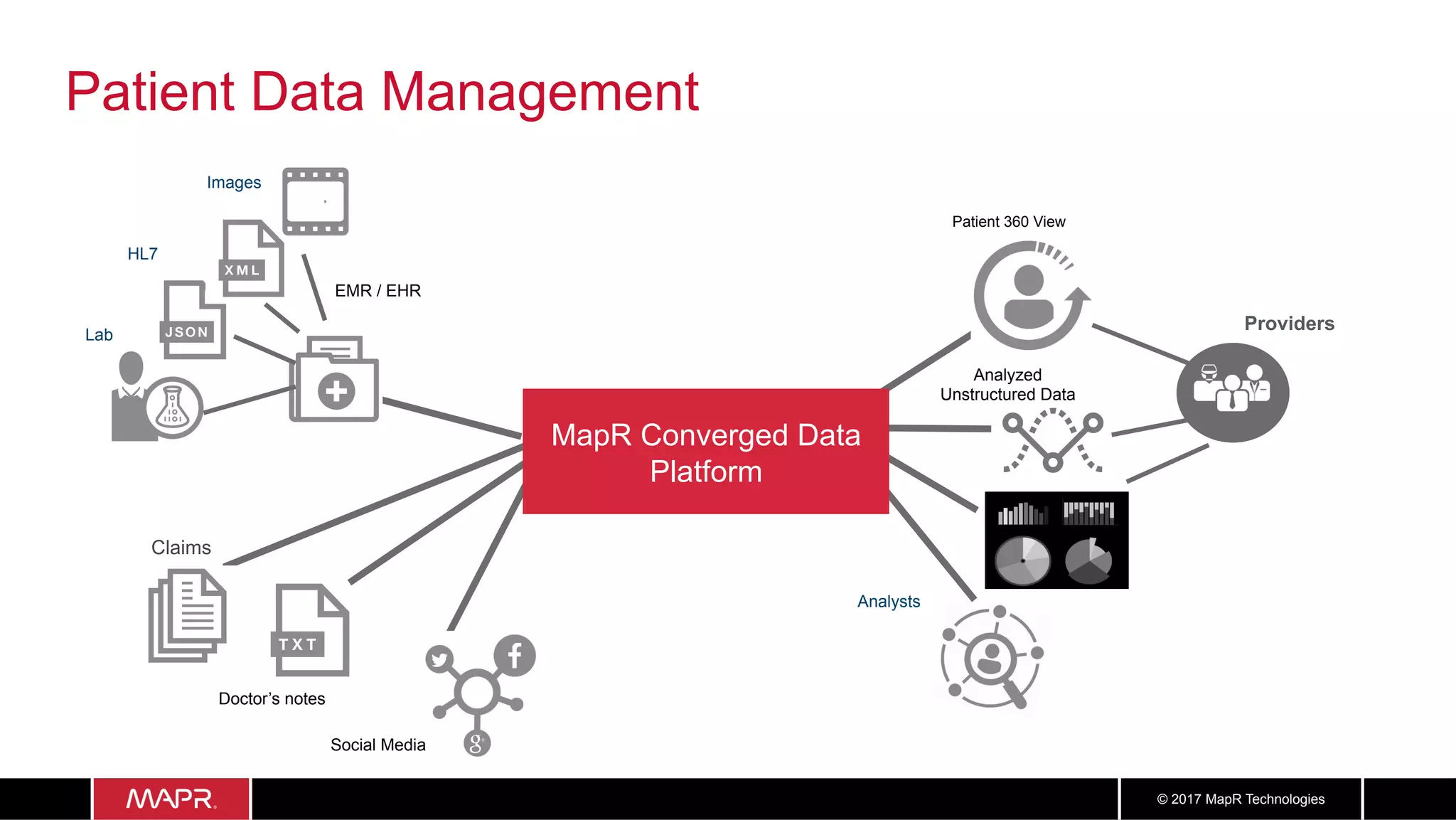

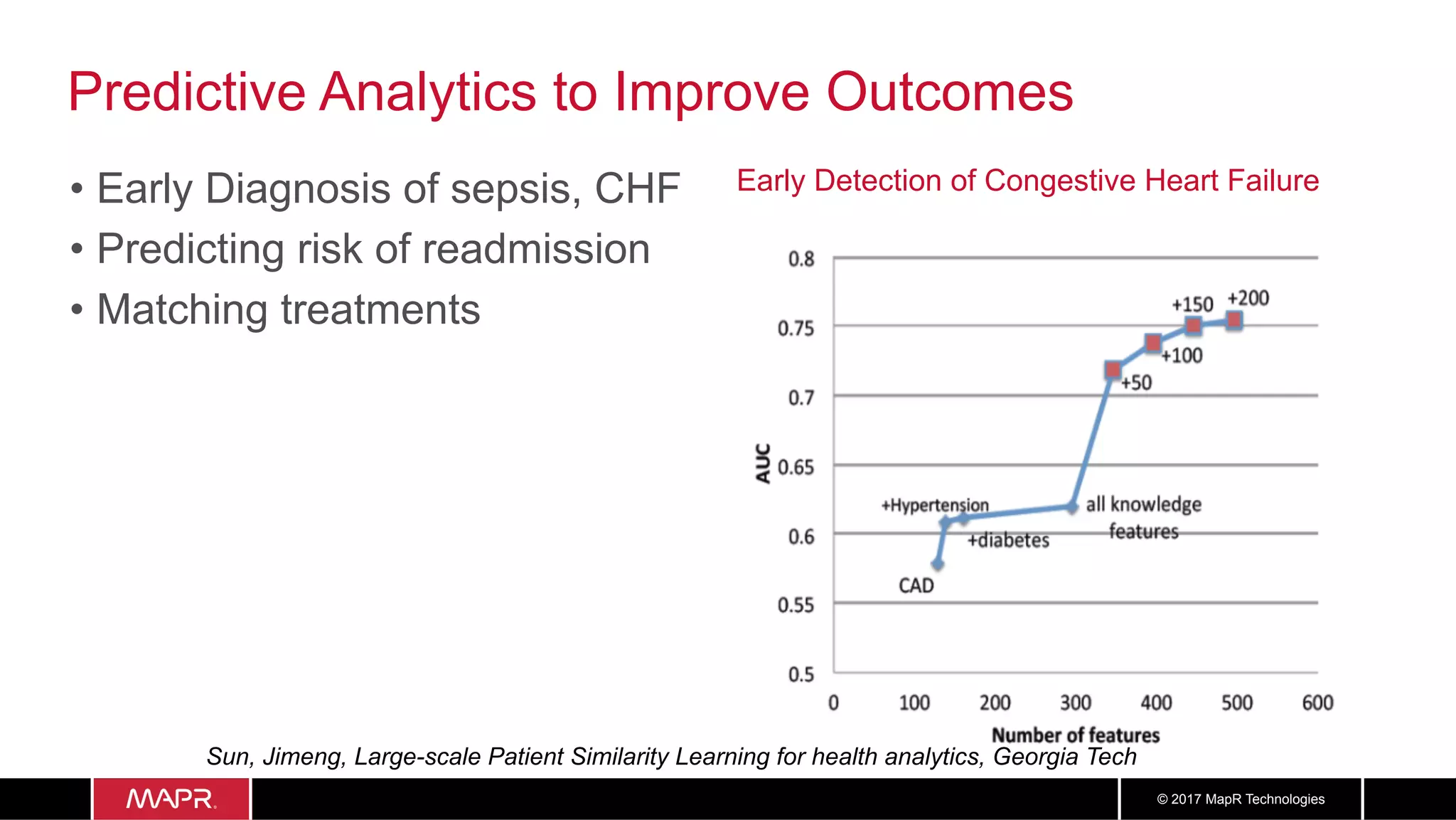
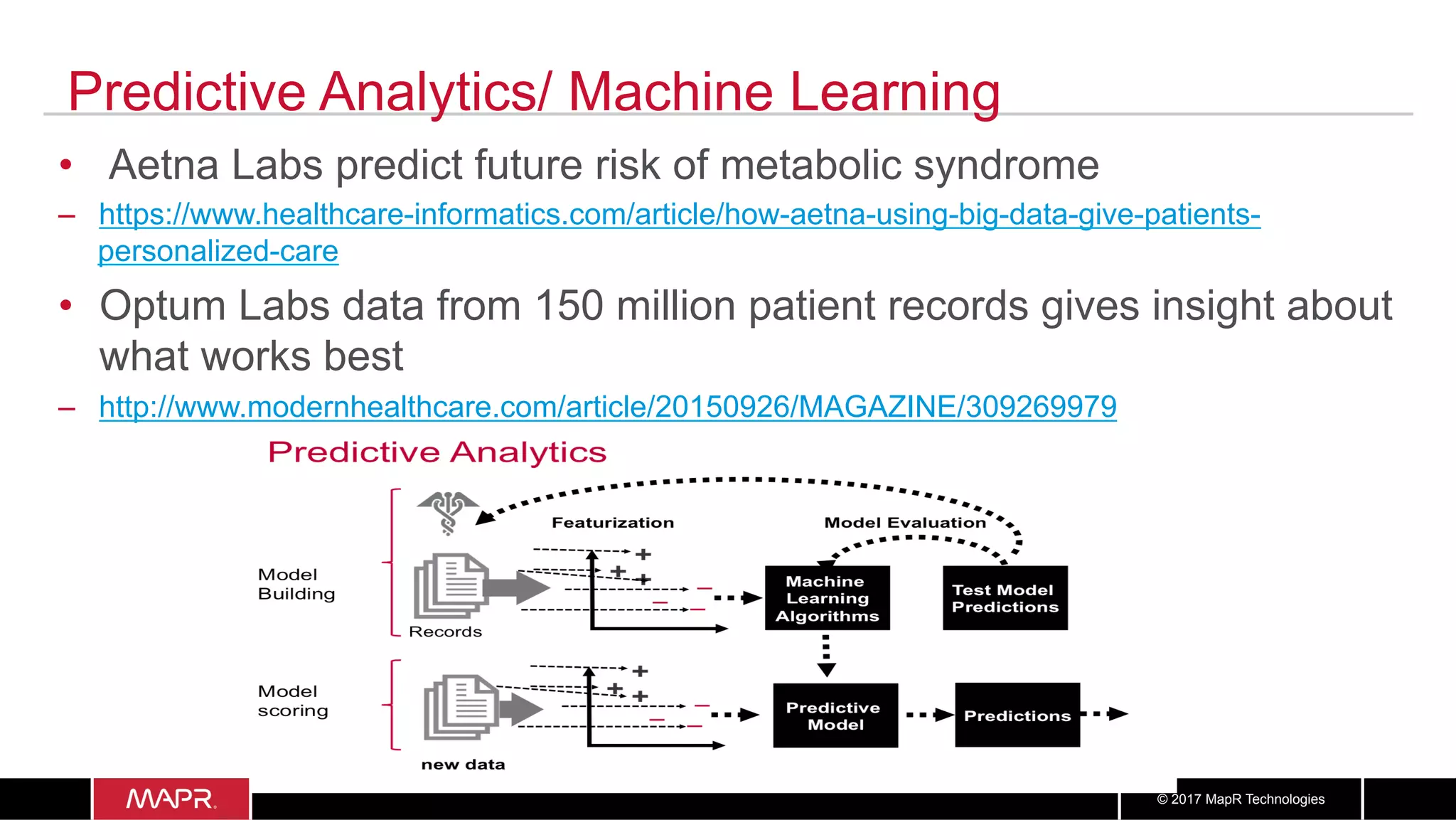
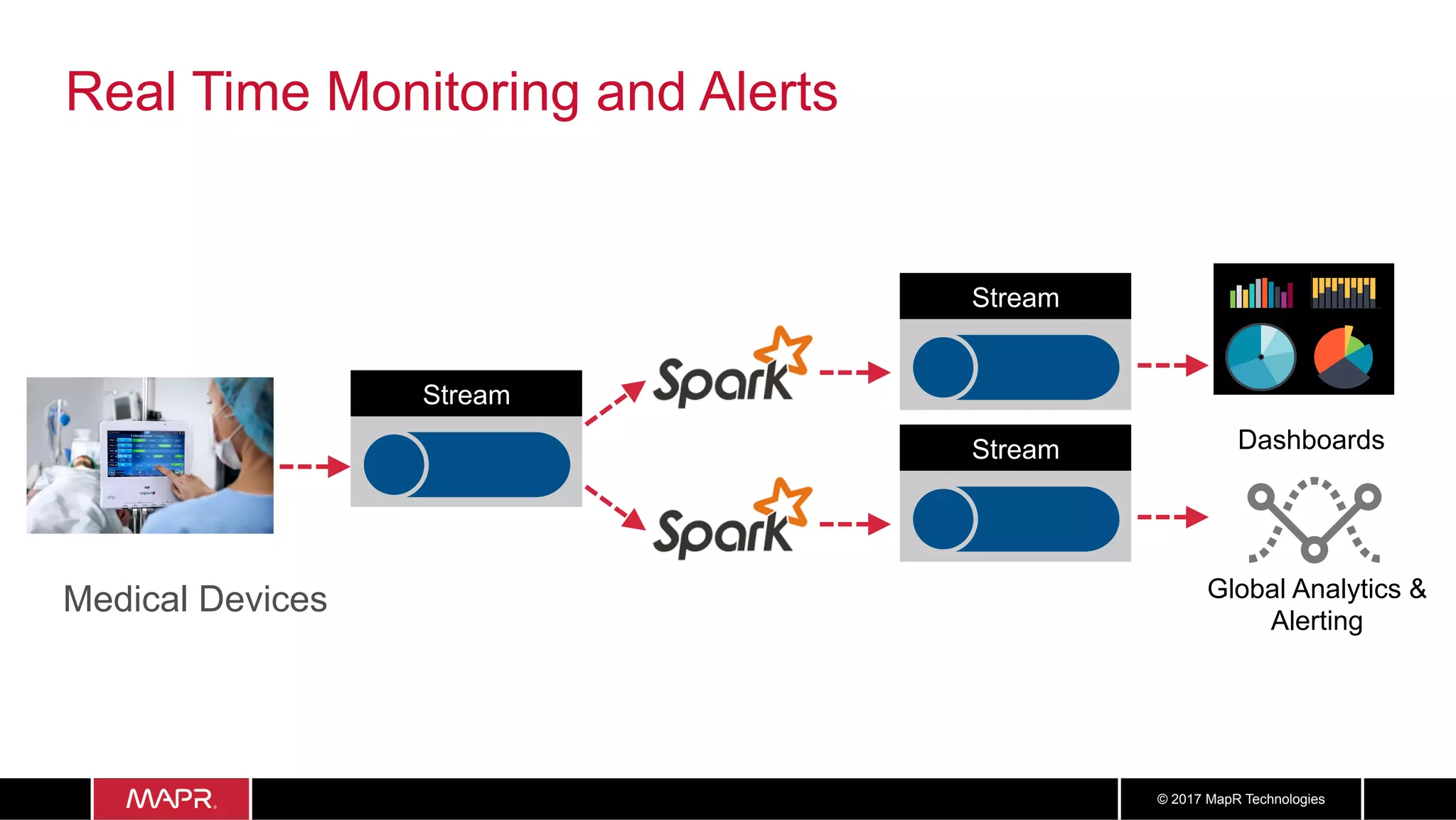






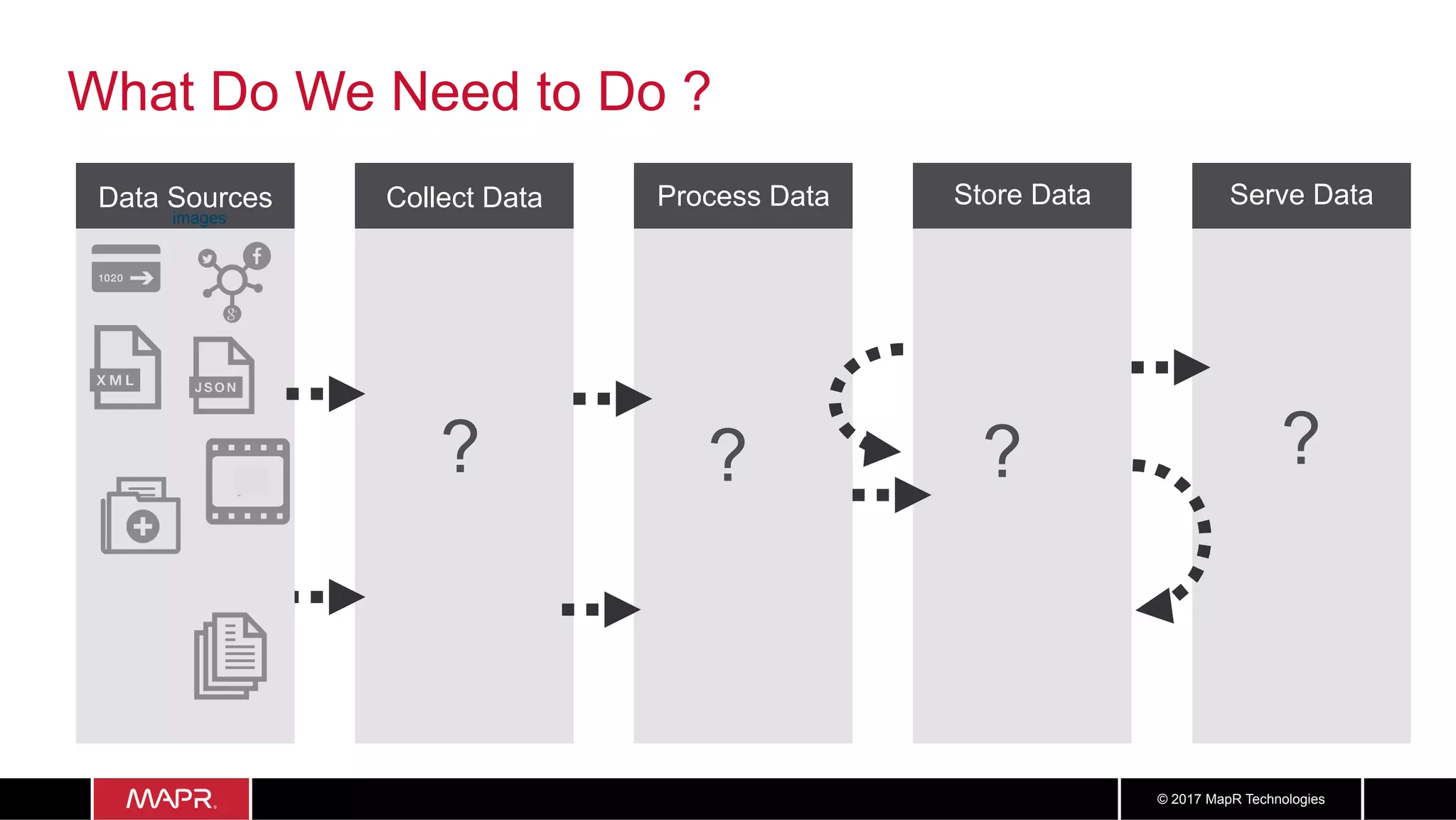
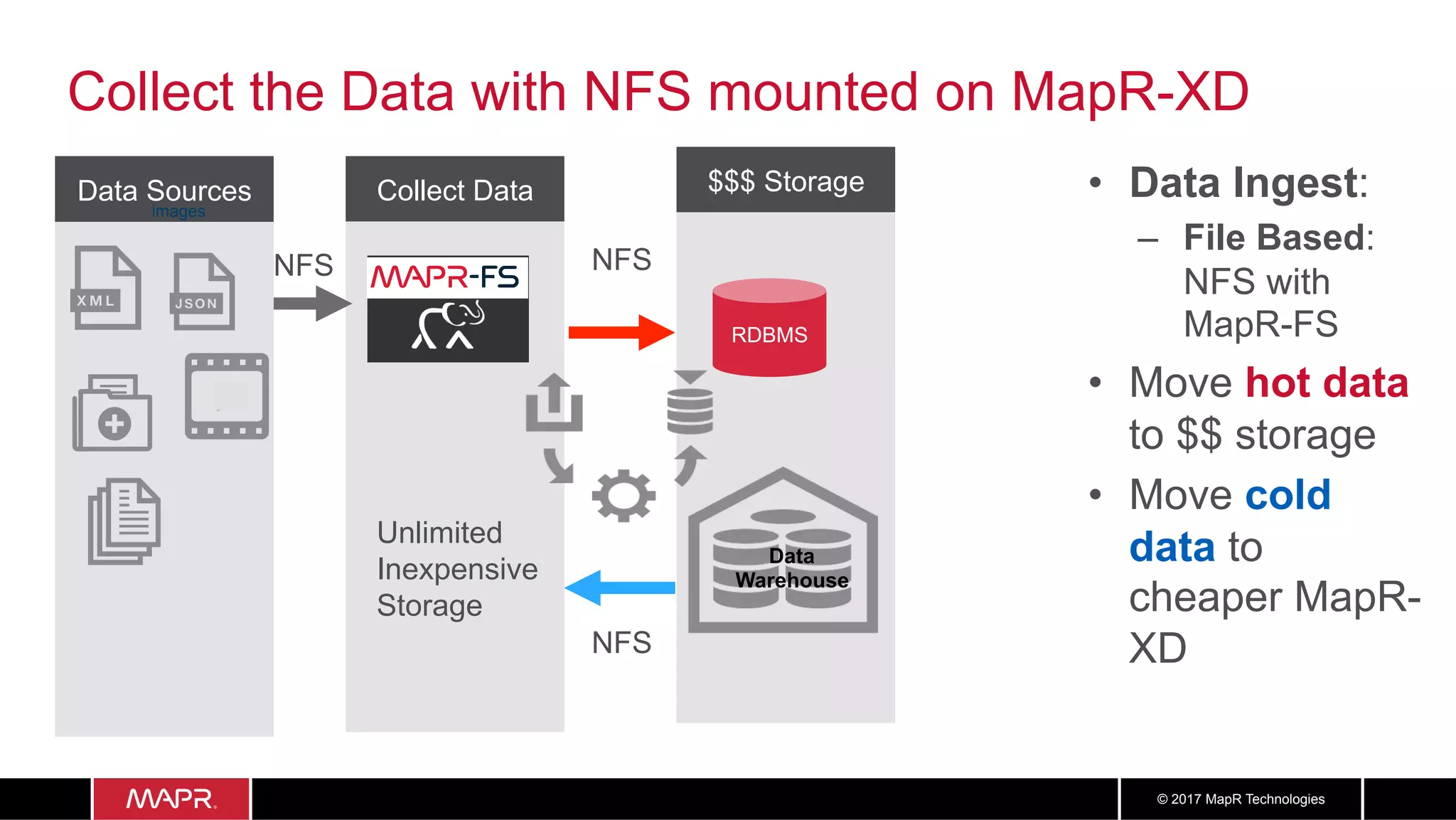
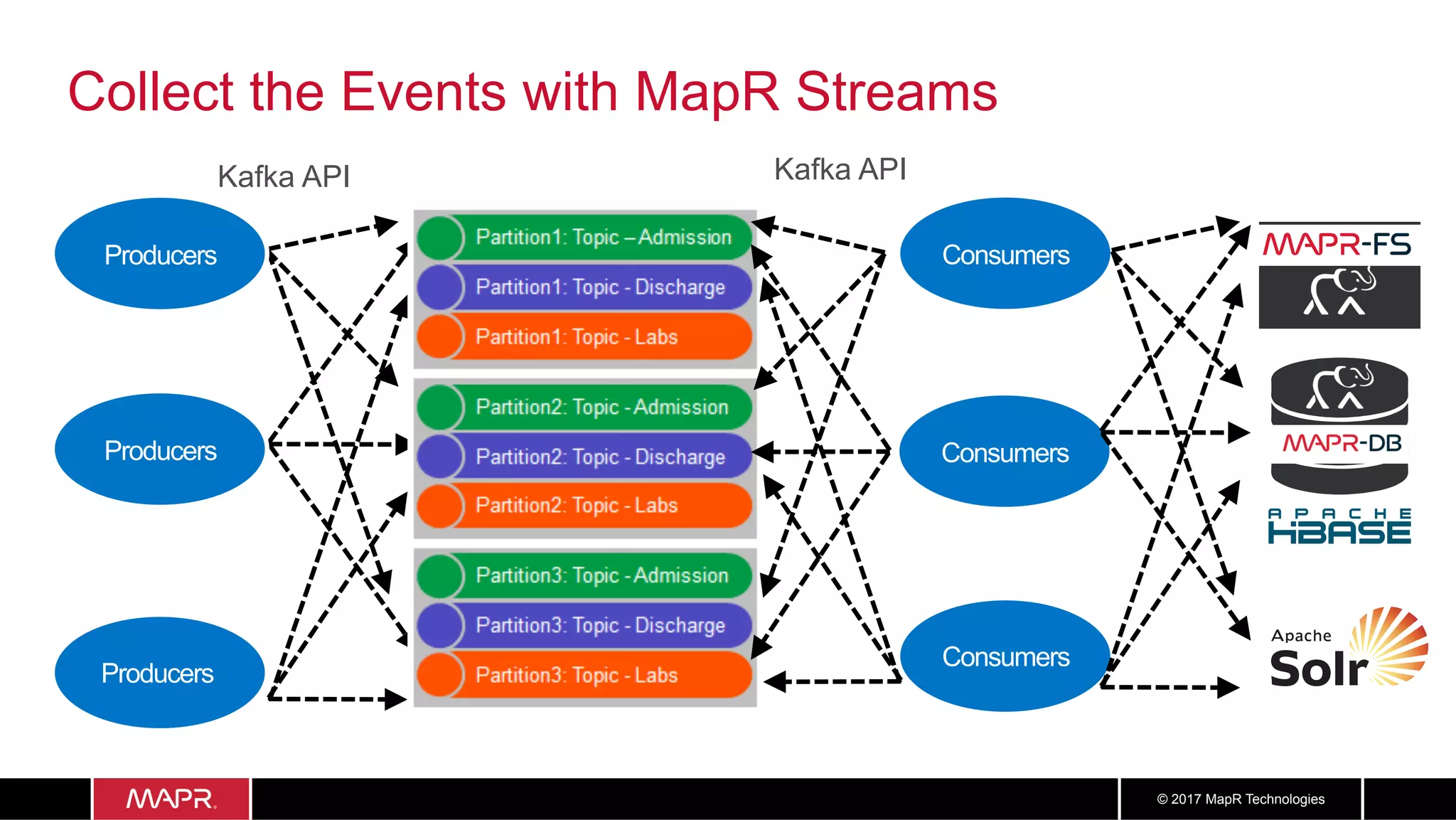
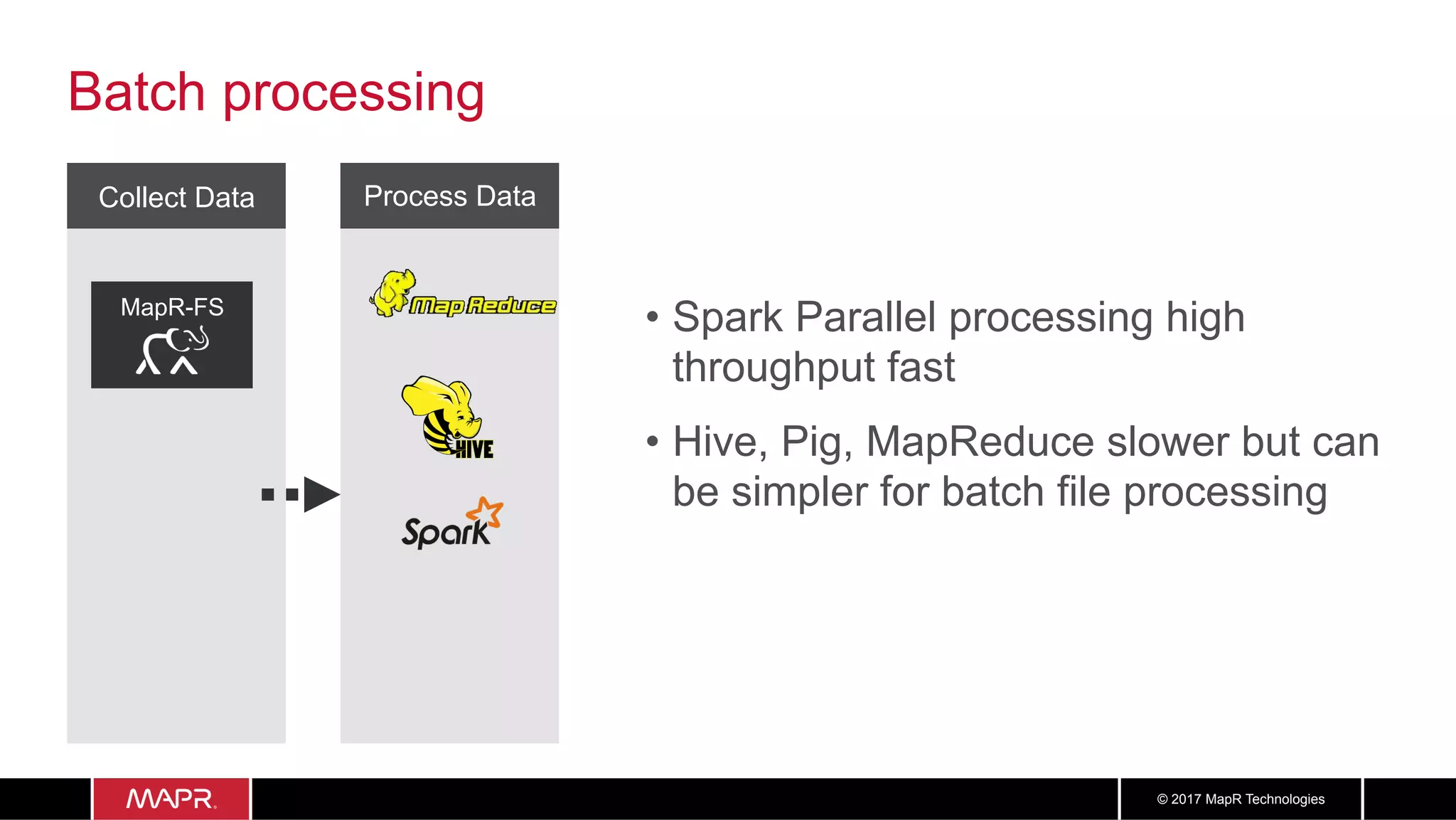
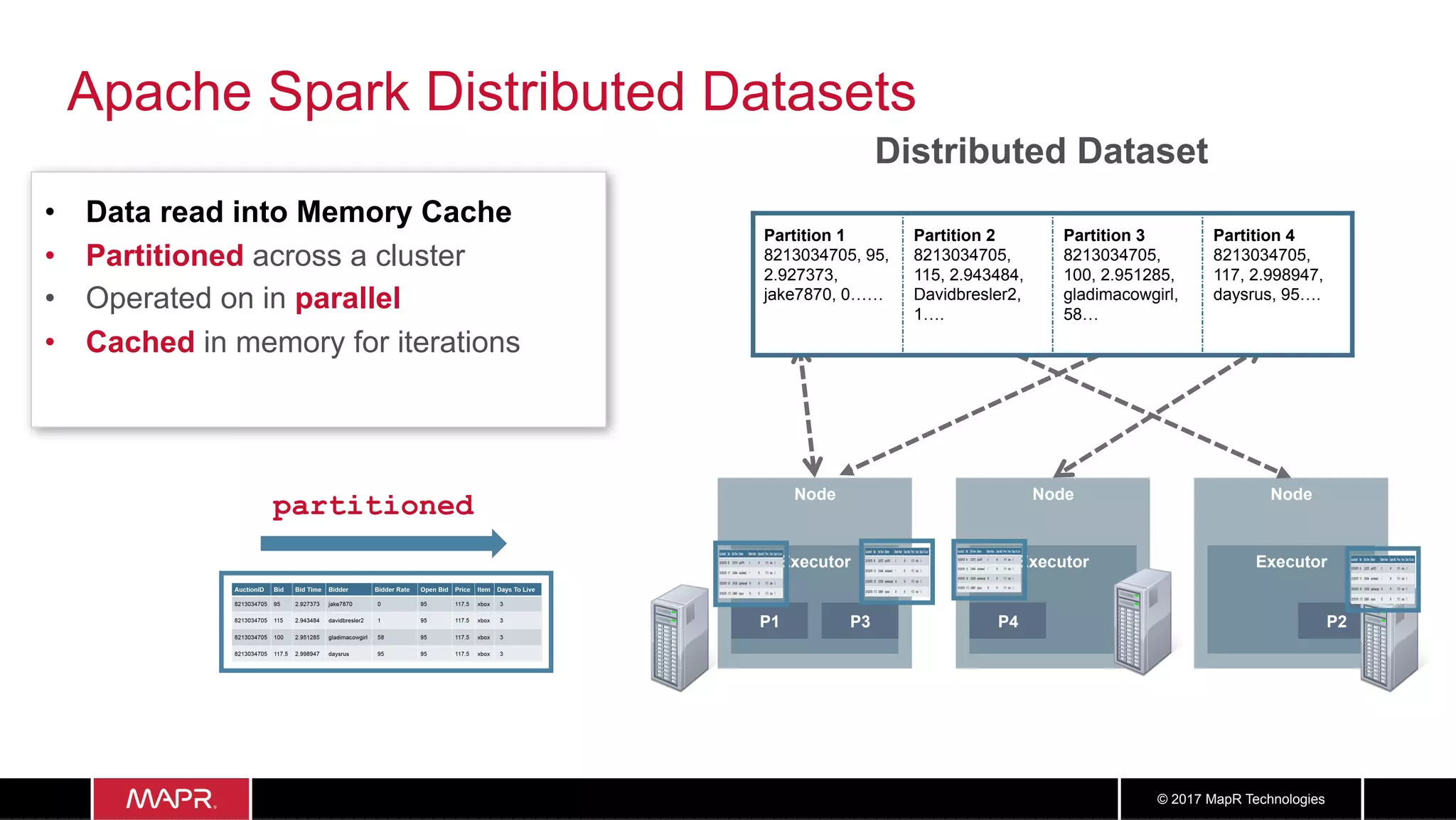

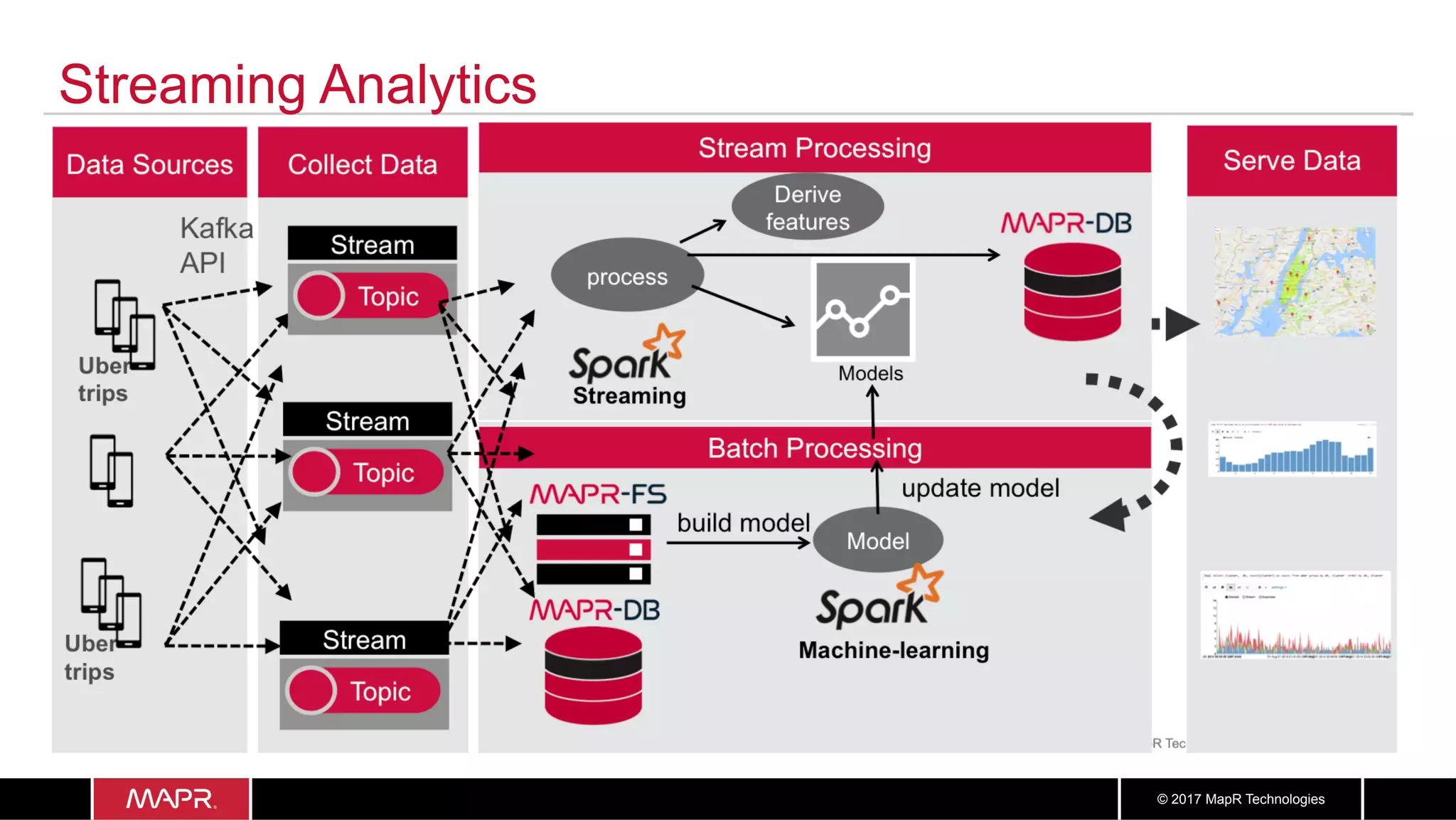
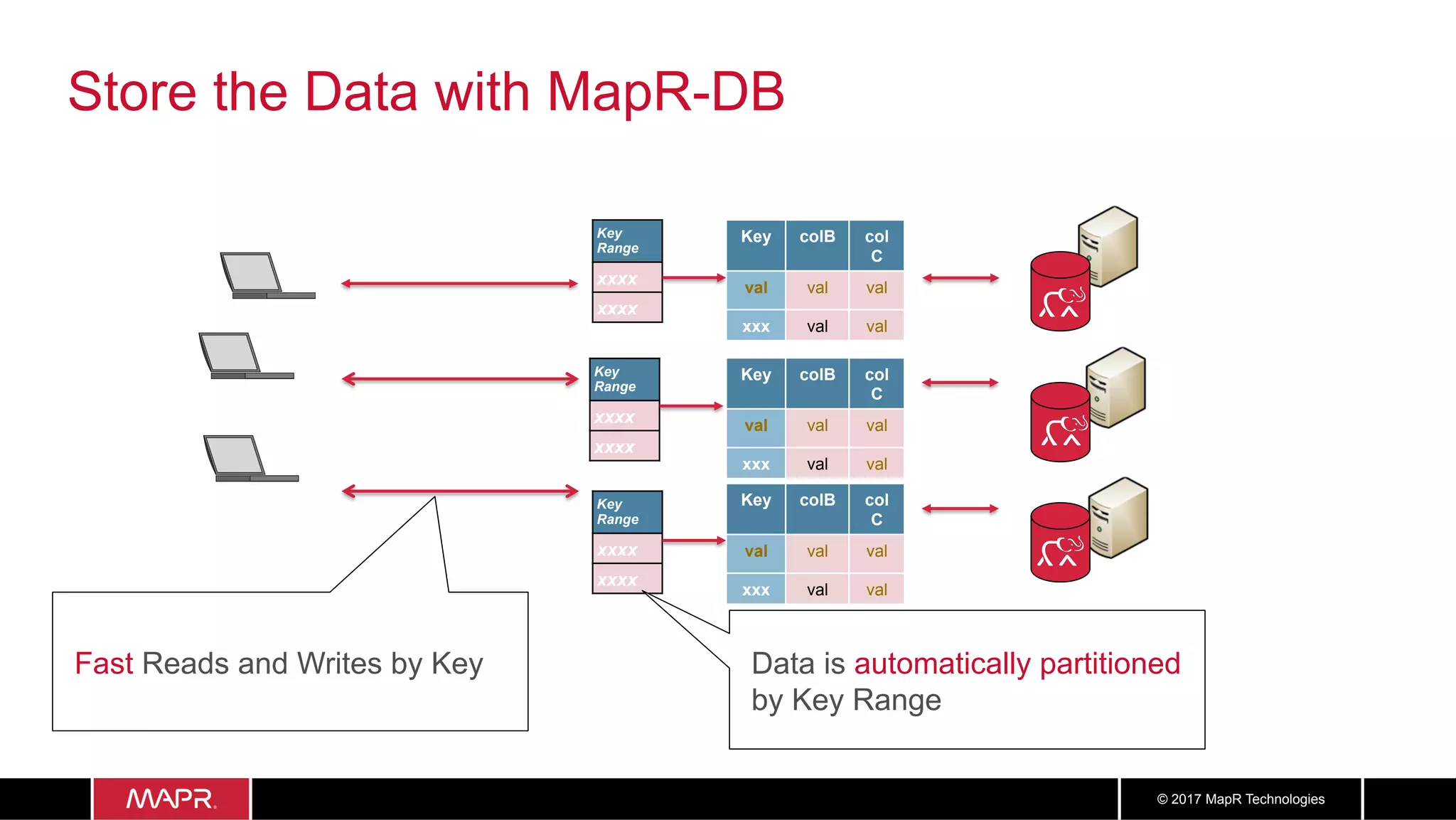
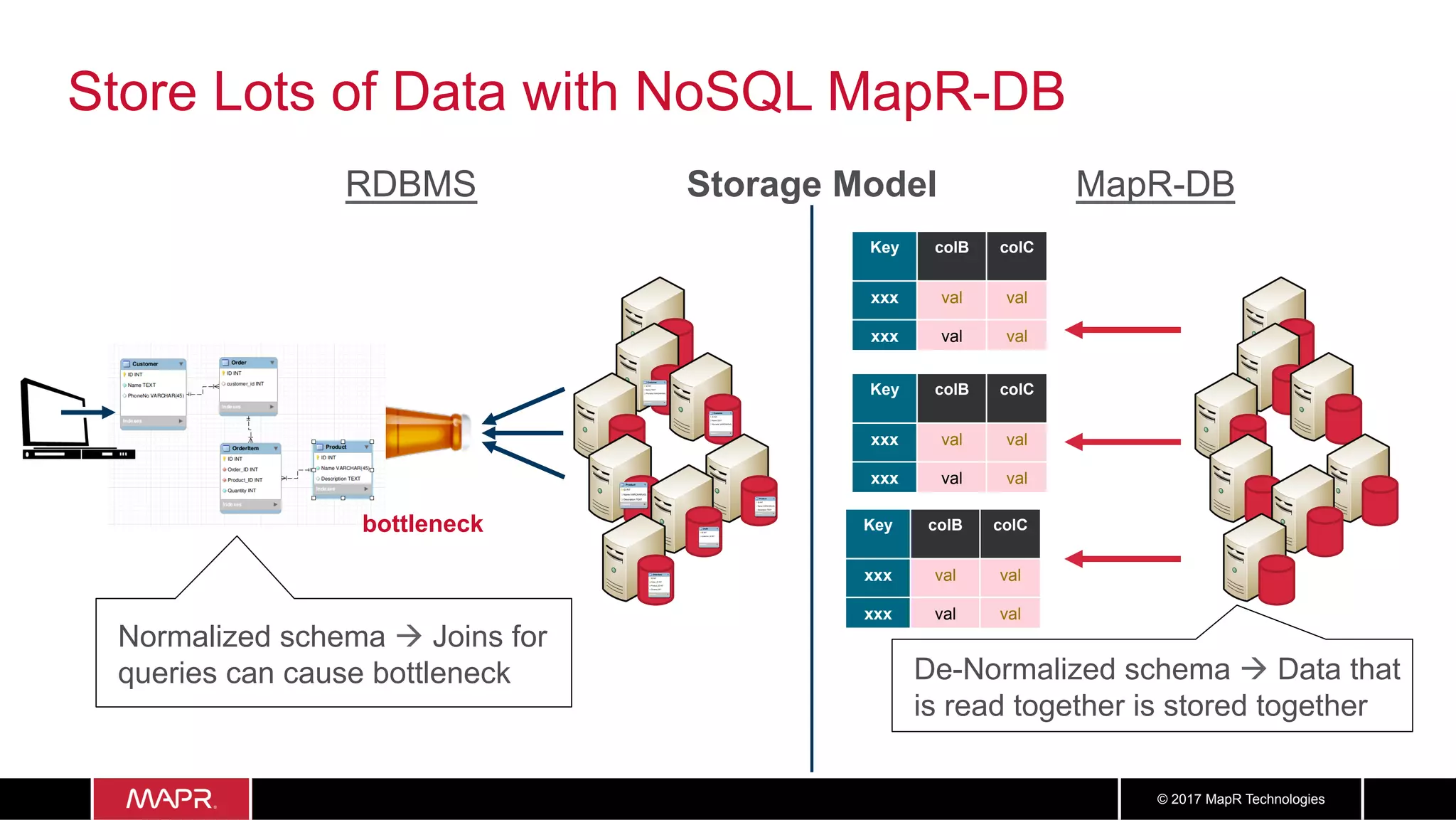

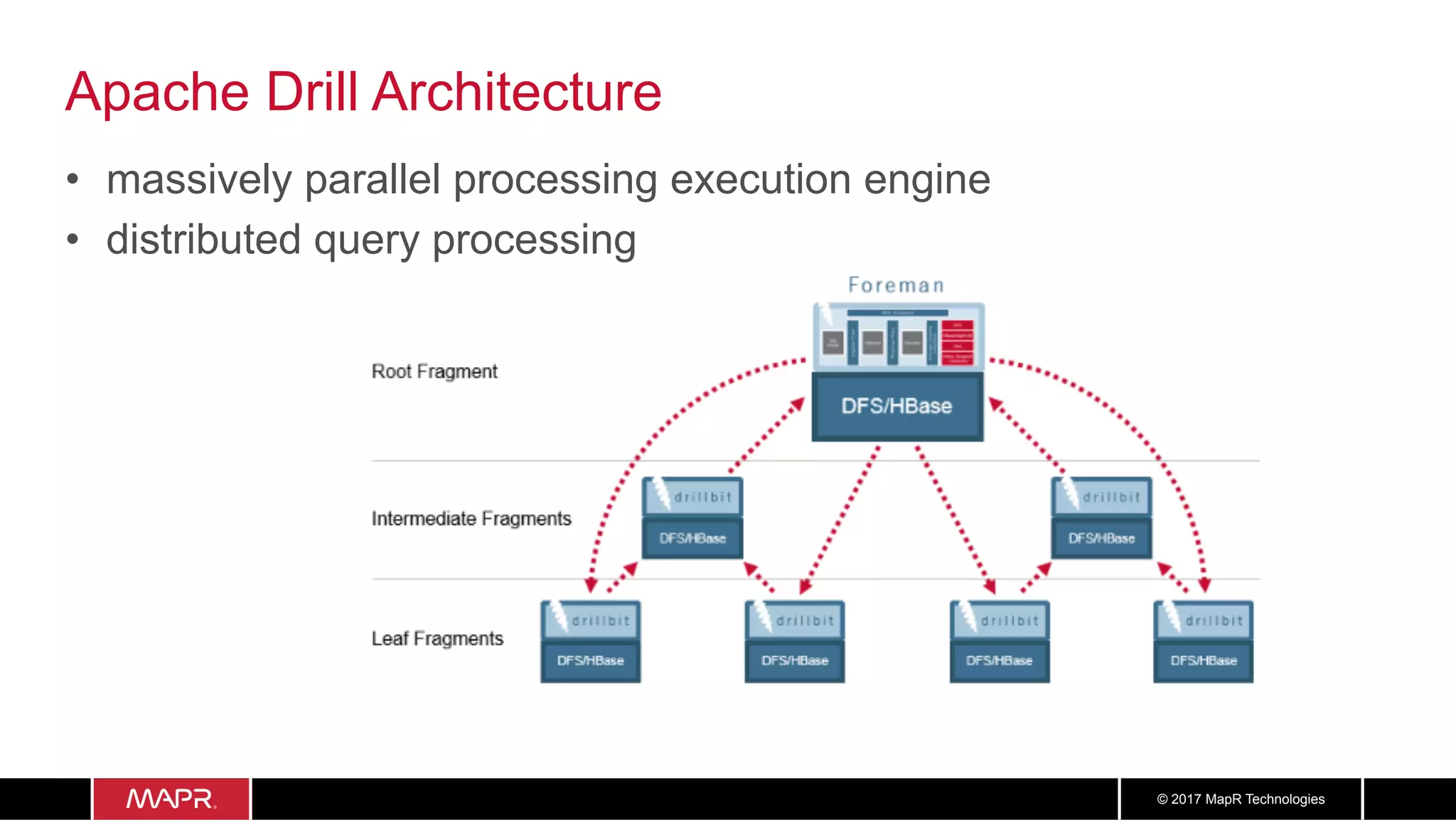
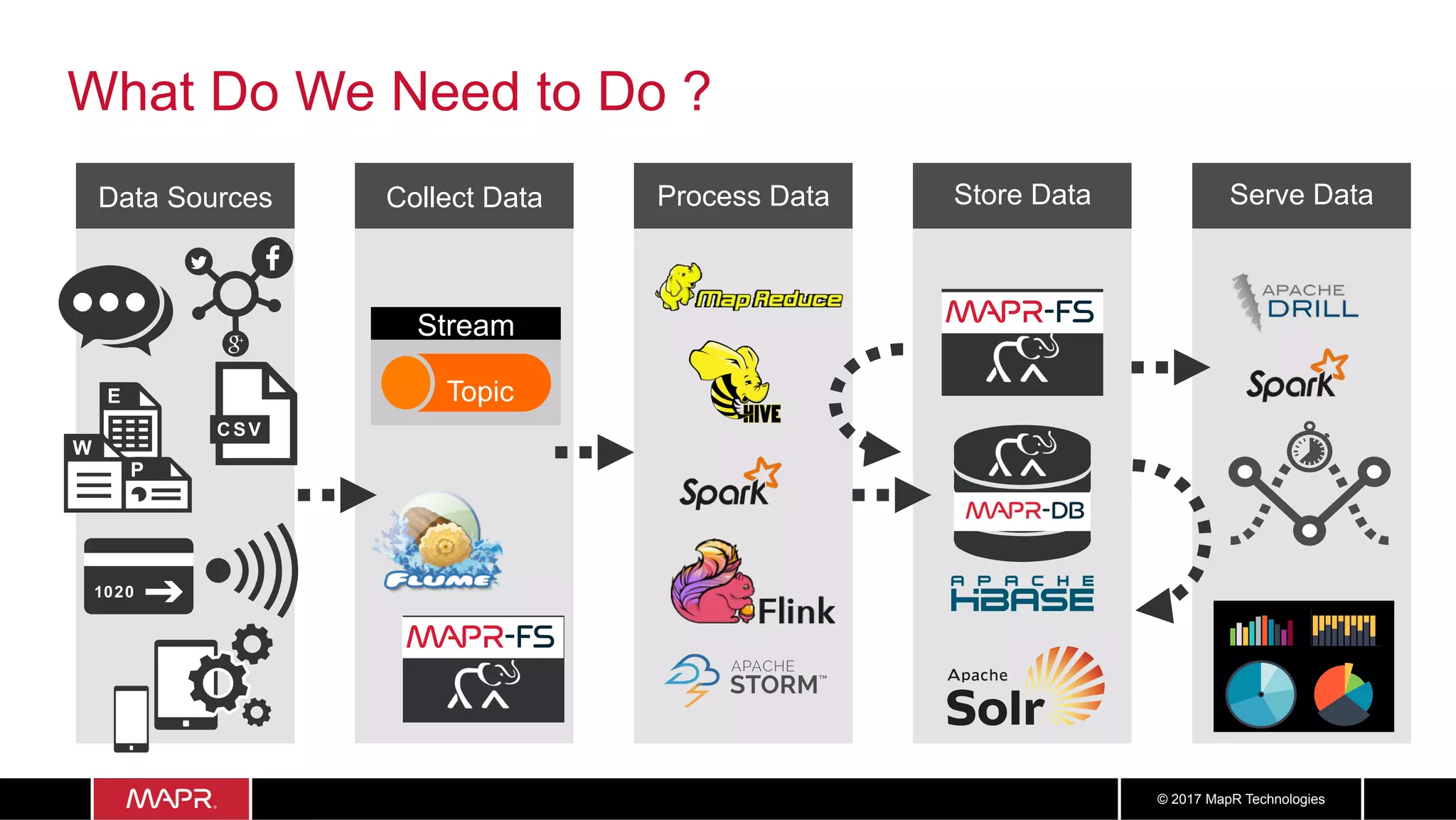

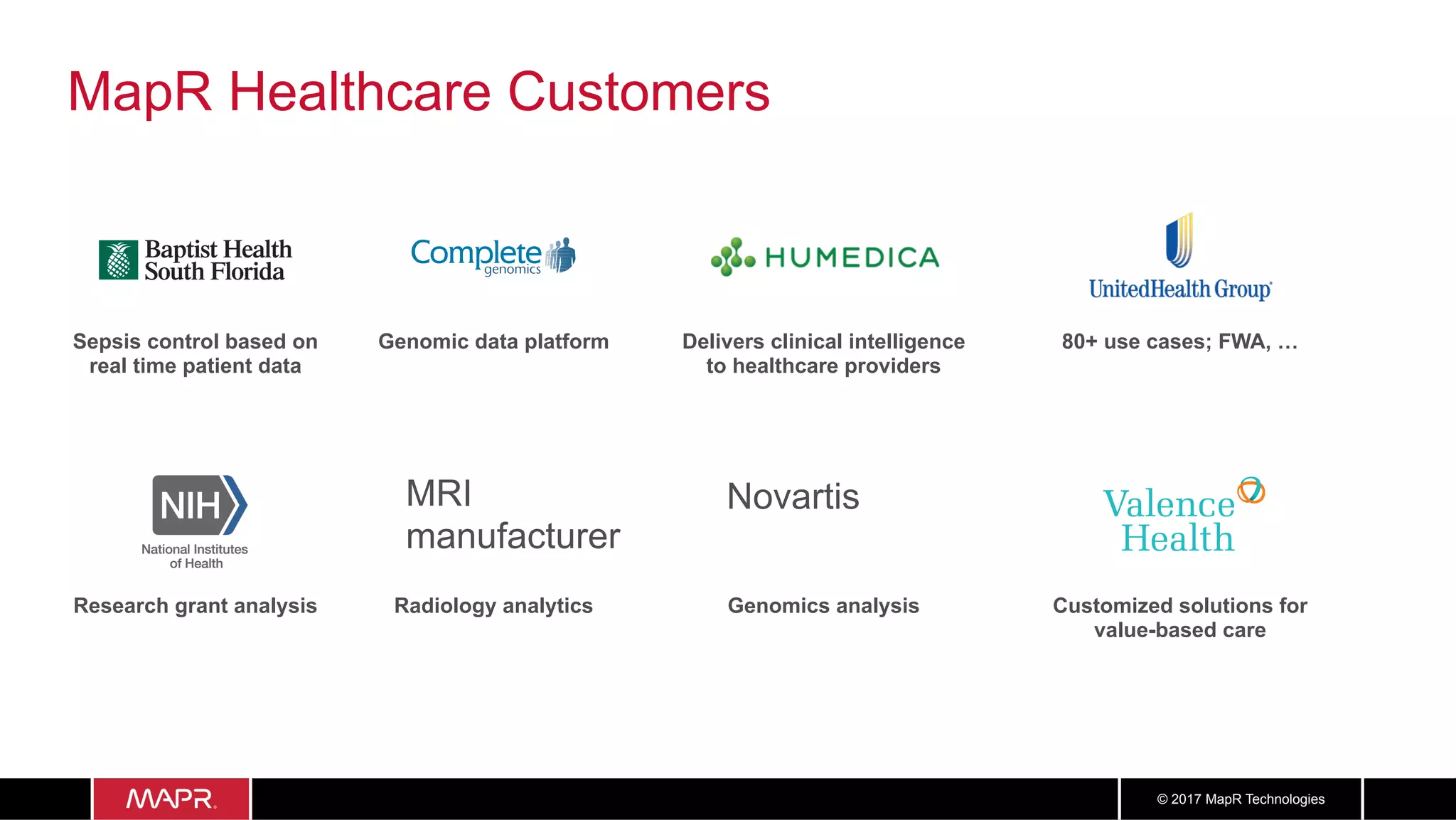
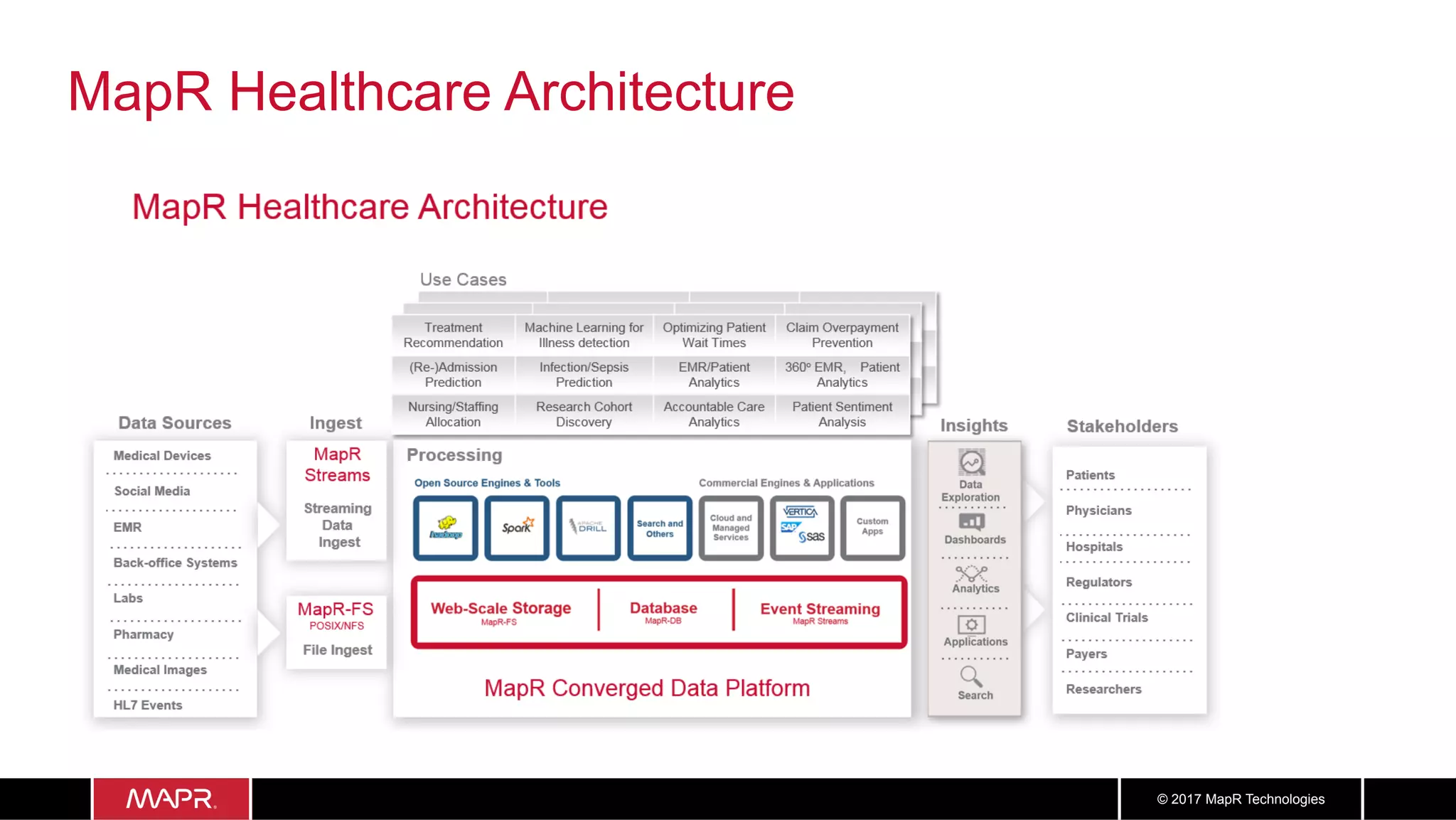
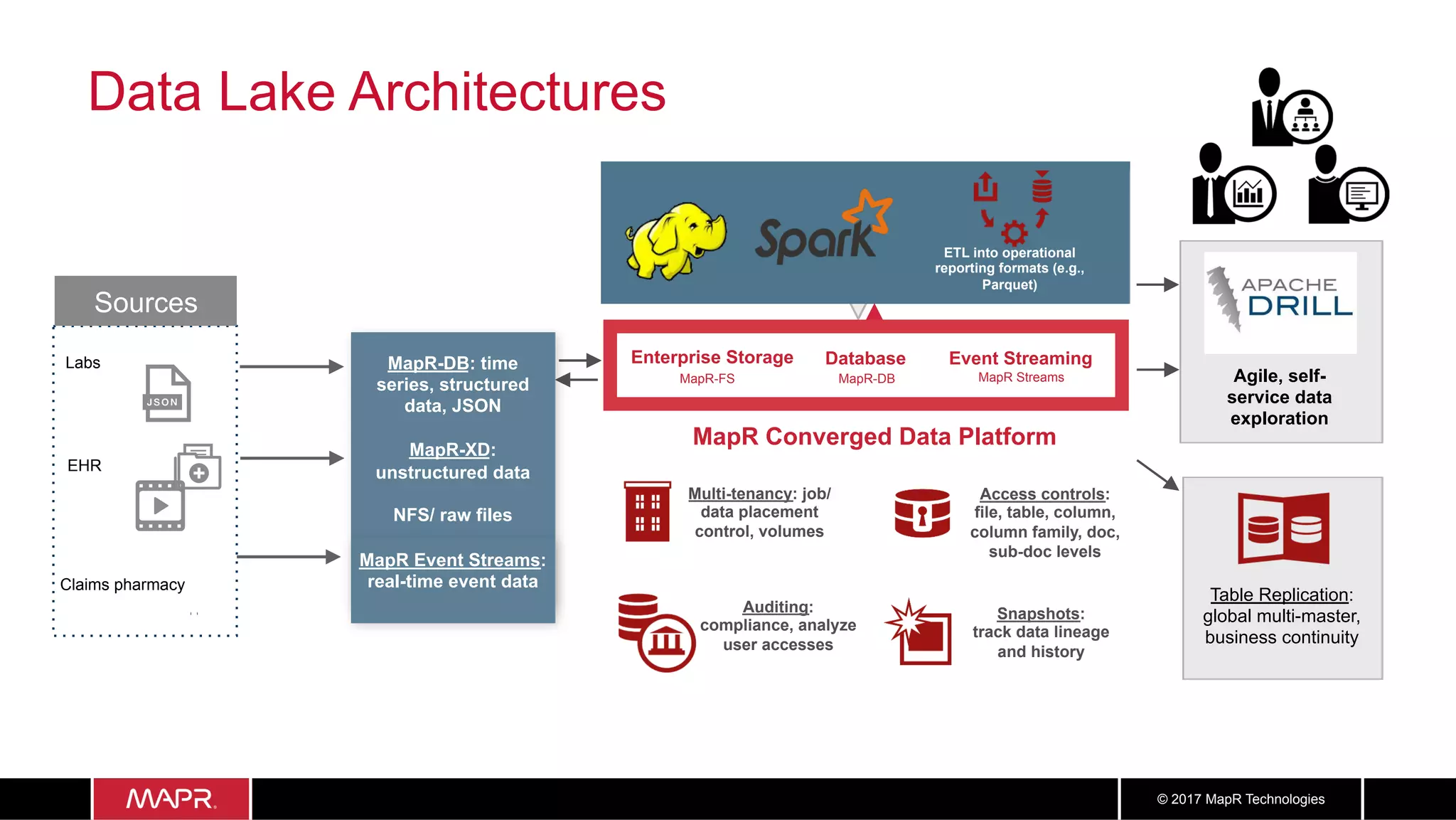



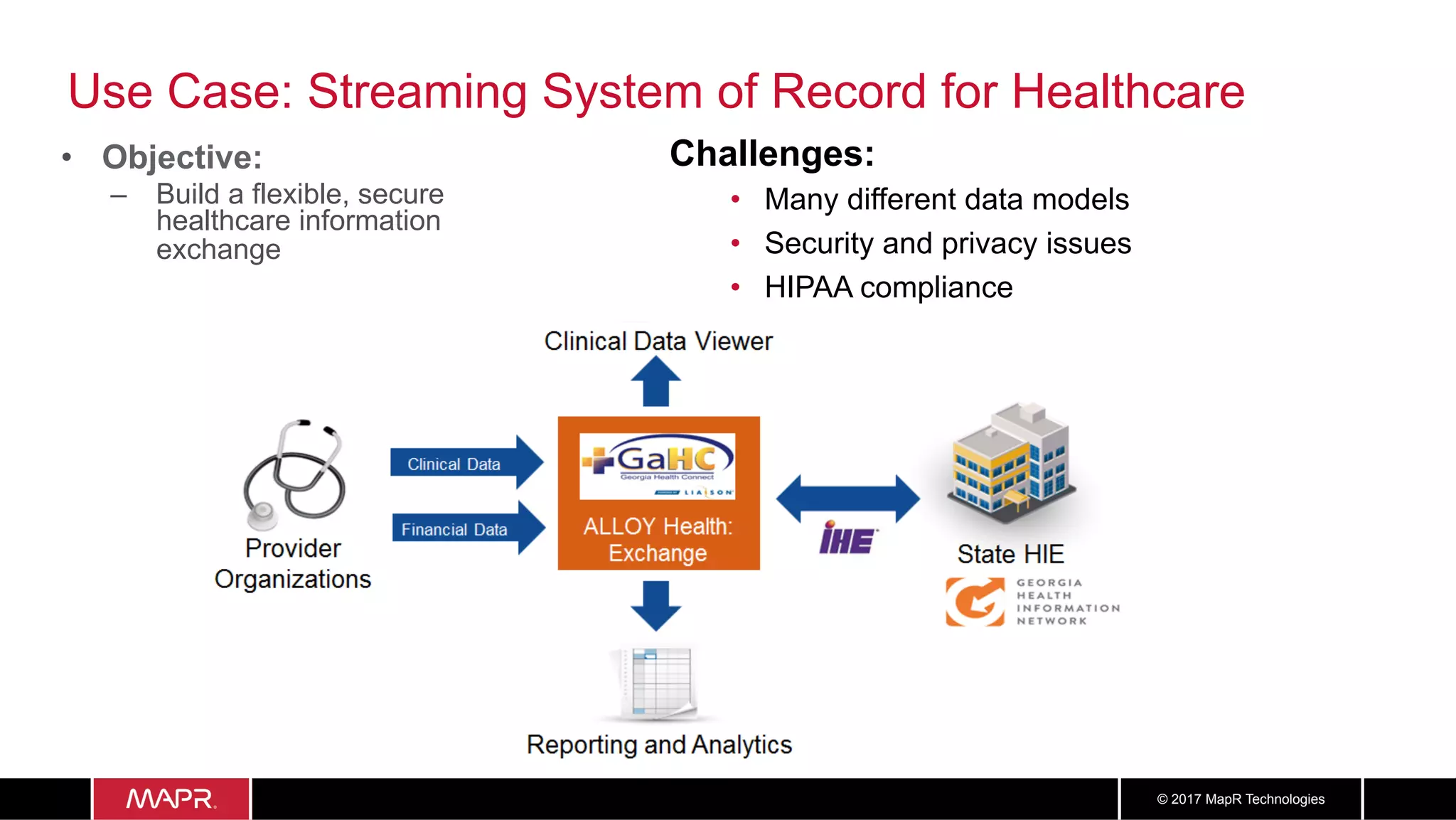
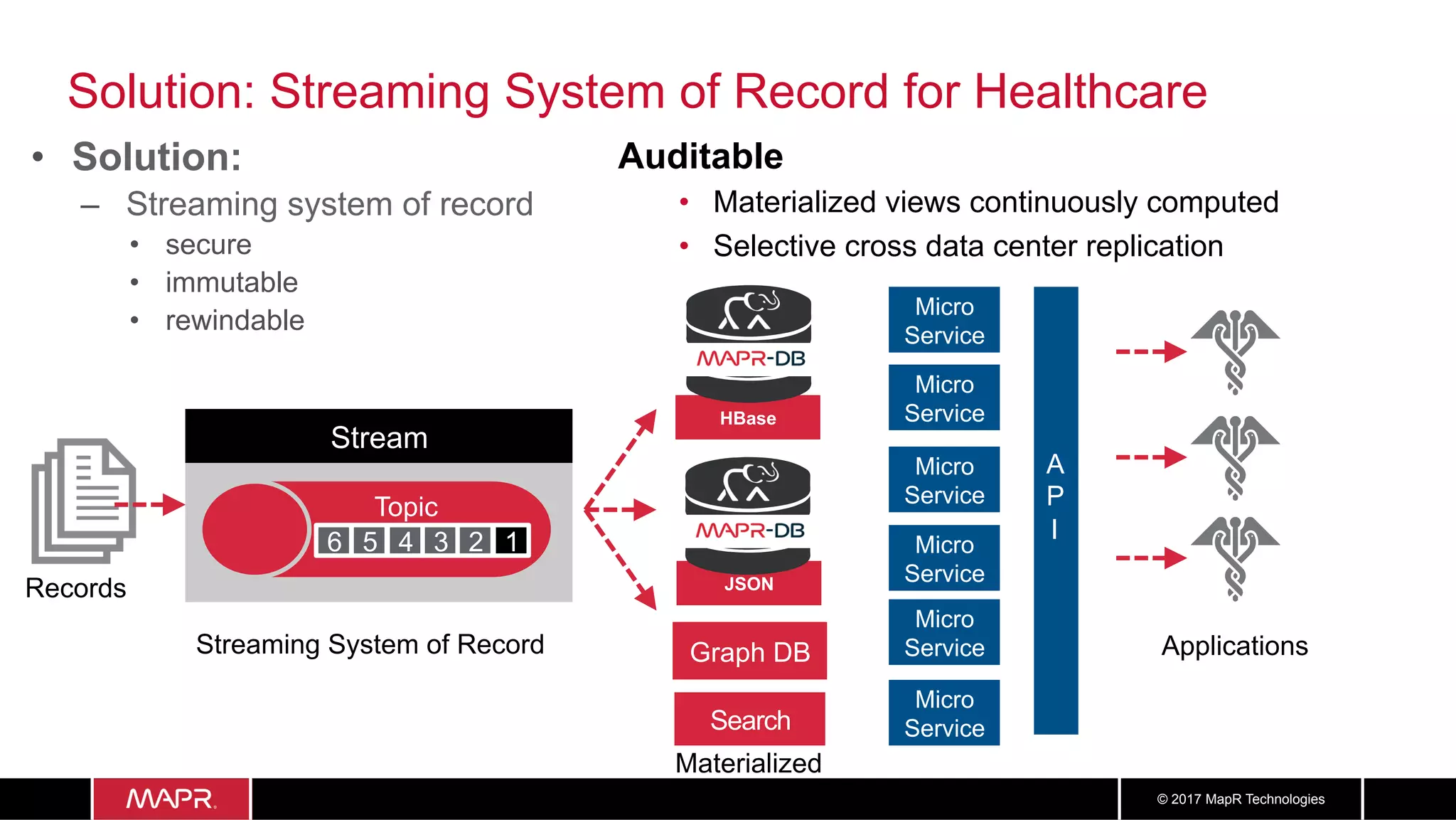
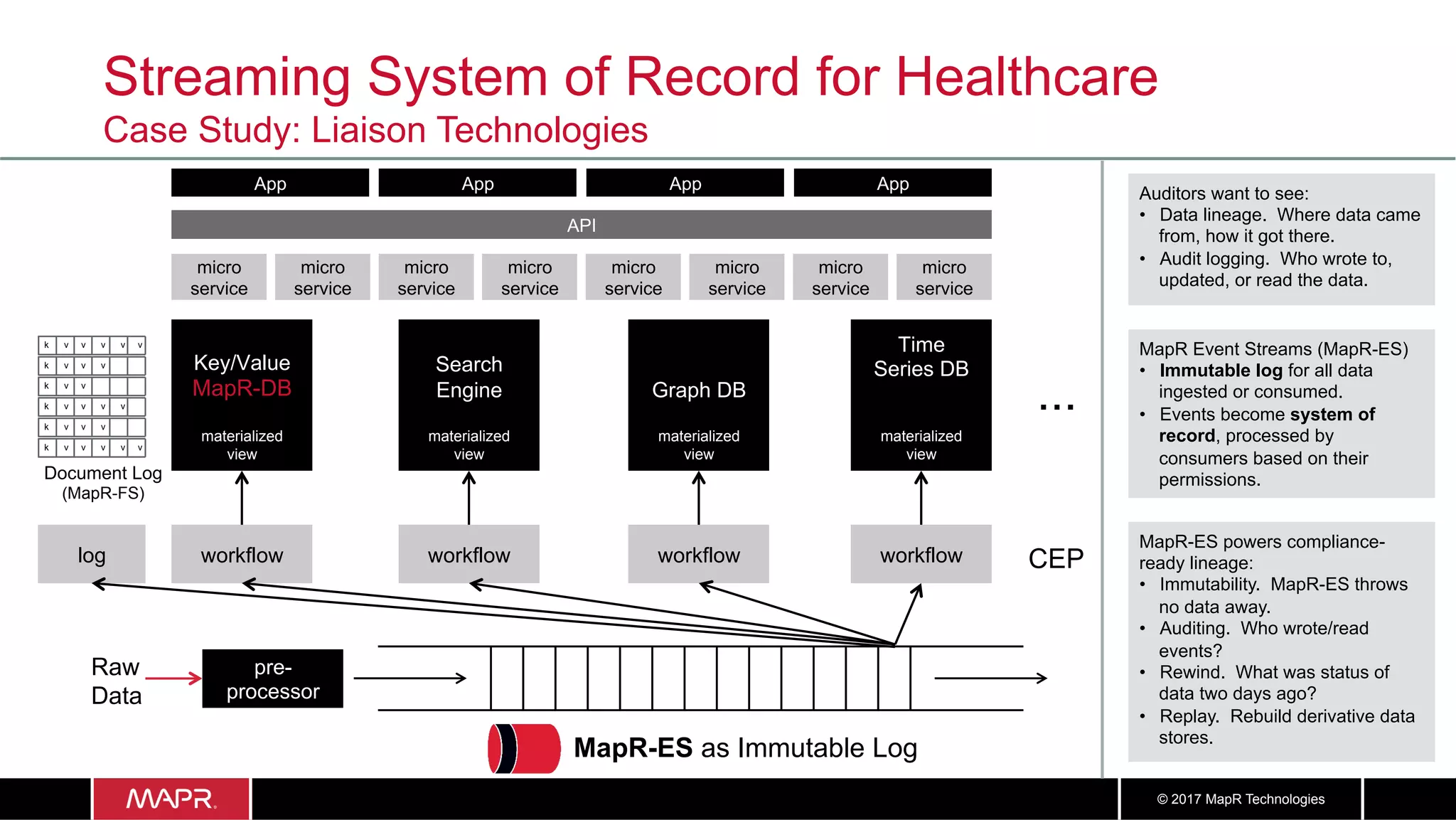


The document discusses the application of big data in healthcare, highlighting the need for improved healthcare outcomes, value-based care, and data-driven decision-making. It emphasizes the potential of big data for reducing costs, detecting fraud, and enhancing patient management through analysis of various data sources and predictive analytics. Additionally, it outlines technological solutions, including a data lake architecture and the integration of machine learning and IoT for real-time patient monitoring and treatment optimization.















































































