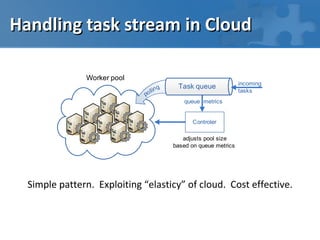
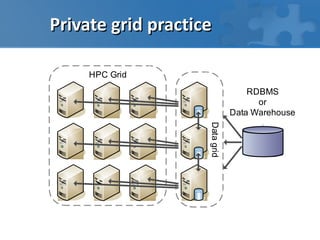
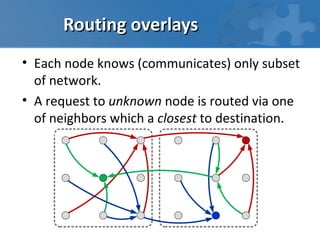
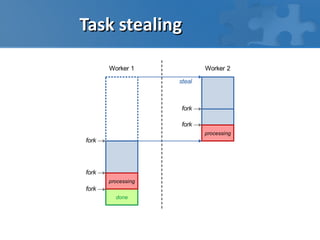
This document discusses high performance computing in the cloud. It covers different types of workloads like I/O bound, CPU bound, and latency bound tasks. It also discusses handling task streams and structured batch jobs in the cloud. It proposes using techniques like worker pools, task queues, routing overlays, and task stealing for scheduling tasks. It discusses challenges around distributing large data sets across cloud resources and proposes solutions like caching data in memory grids. Finally, it argues that frameworks like Hadoop are not well suited for the cloud and proposes cloud-friendly alternatives like Peregrine and Spark.



































































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)





