










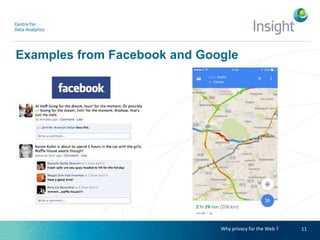


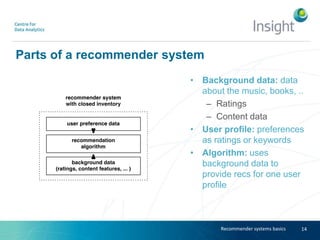

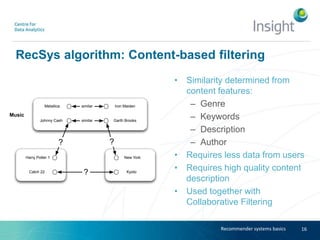
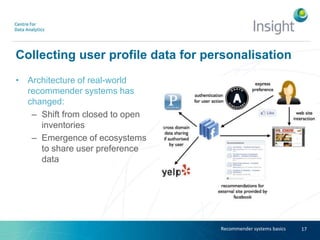



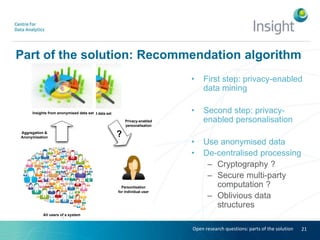





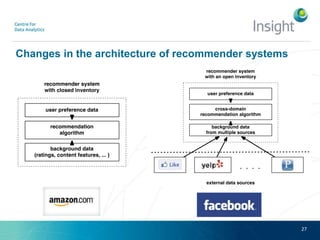
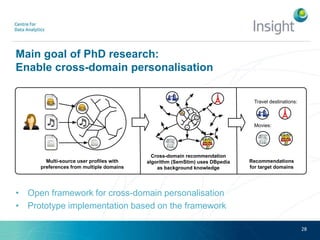



Dr. Benjamin Heitmann discusses the balance between privacy and personalization in recommender systems, highlighting the growing consumer preference for personalized services despite increasing privacy concerns. He explains the essential data requirements for effective recommender systems and emphasizes the need for privacy-enabled personalized algorithms, user experience adjustments, and consumer-centric business models. The talk also calls for open research into innovative methods for integrating privacy into personalization without sacrificing performance.









































































