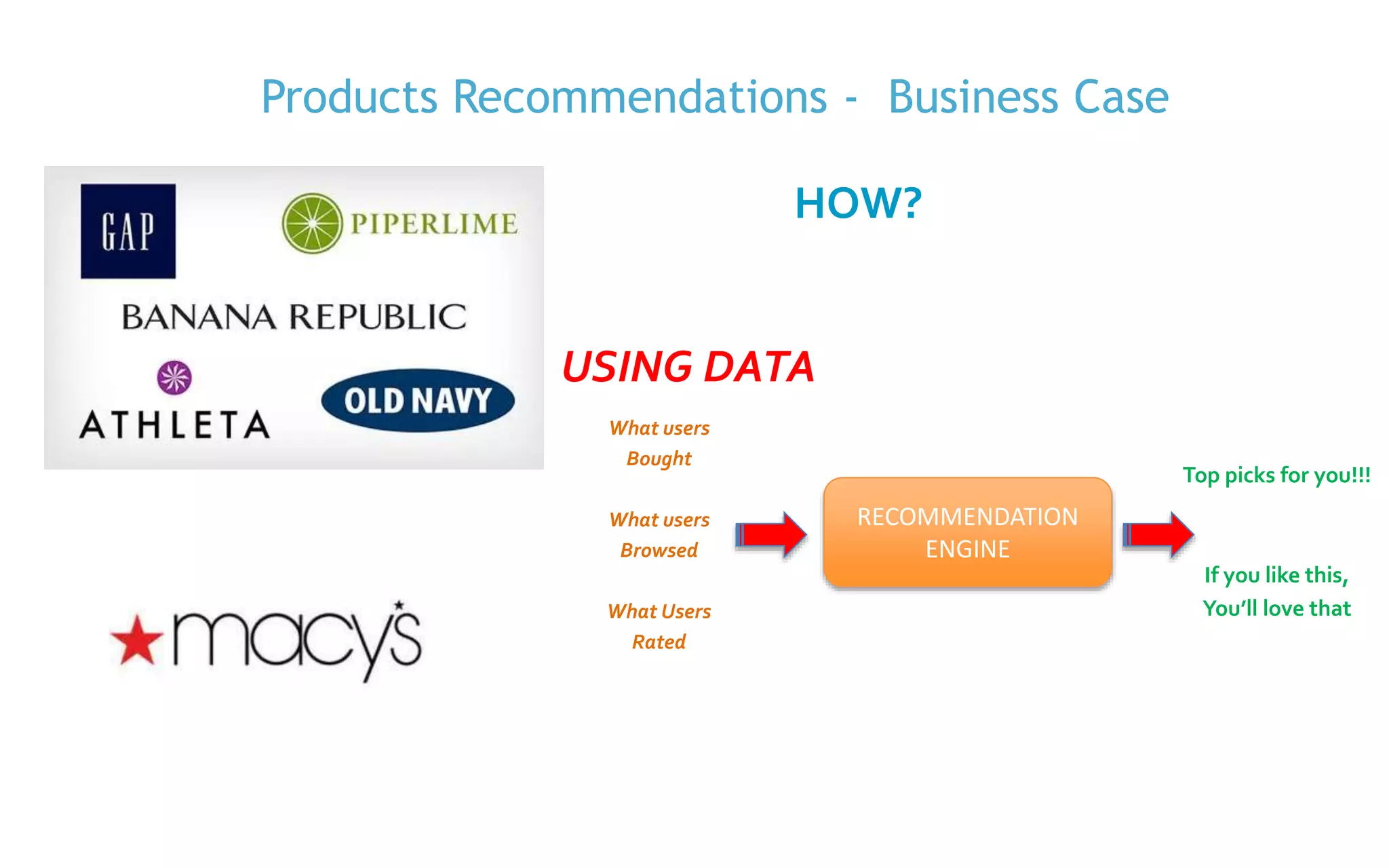
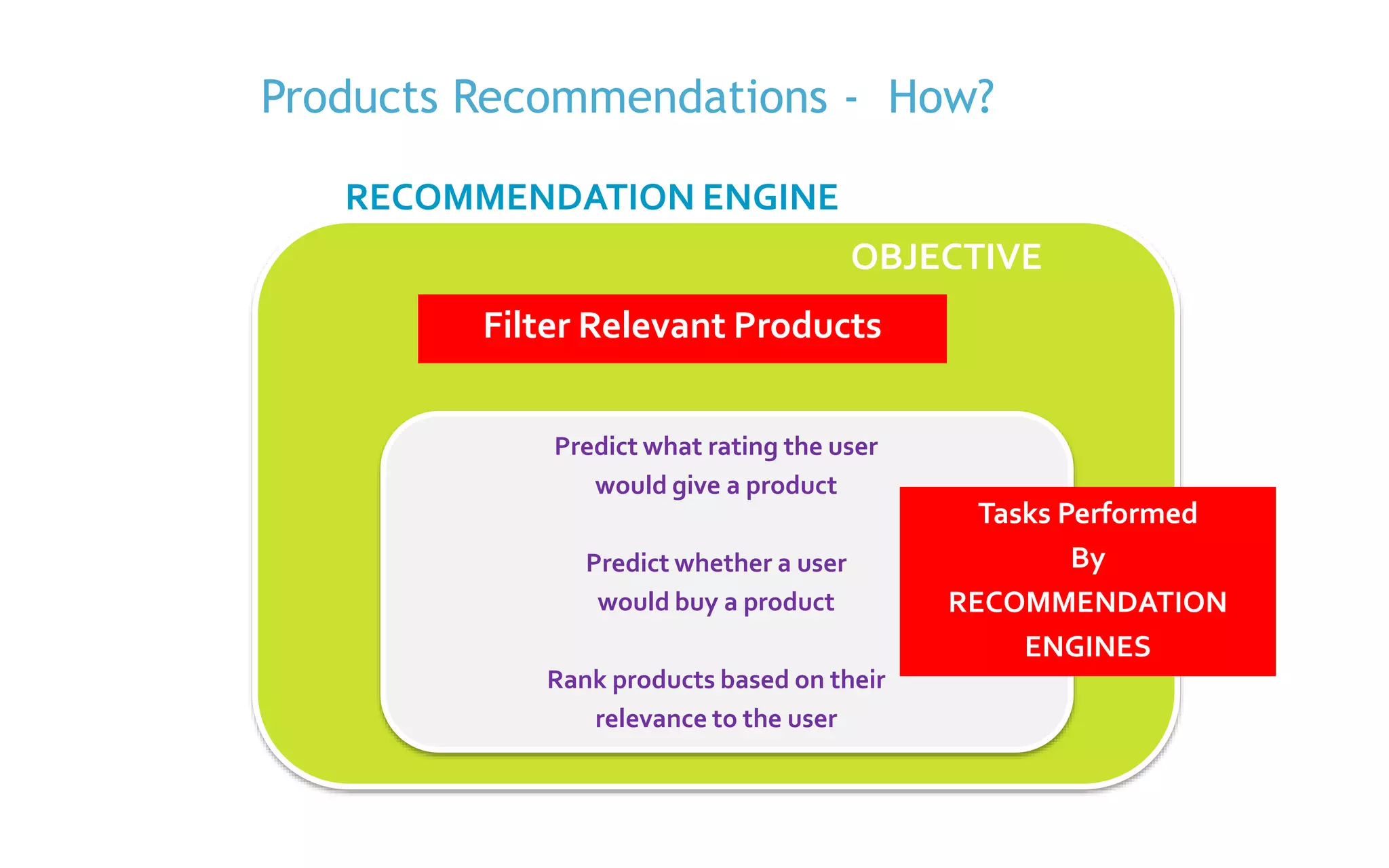
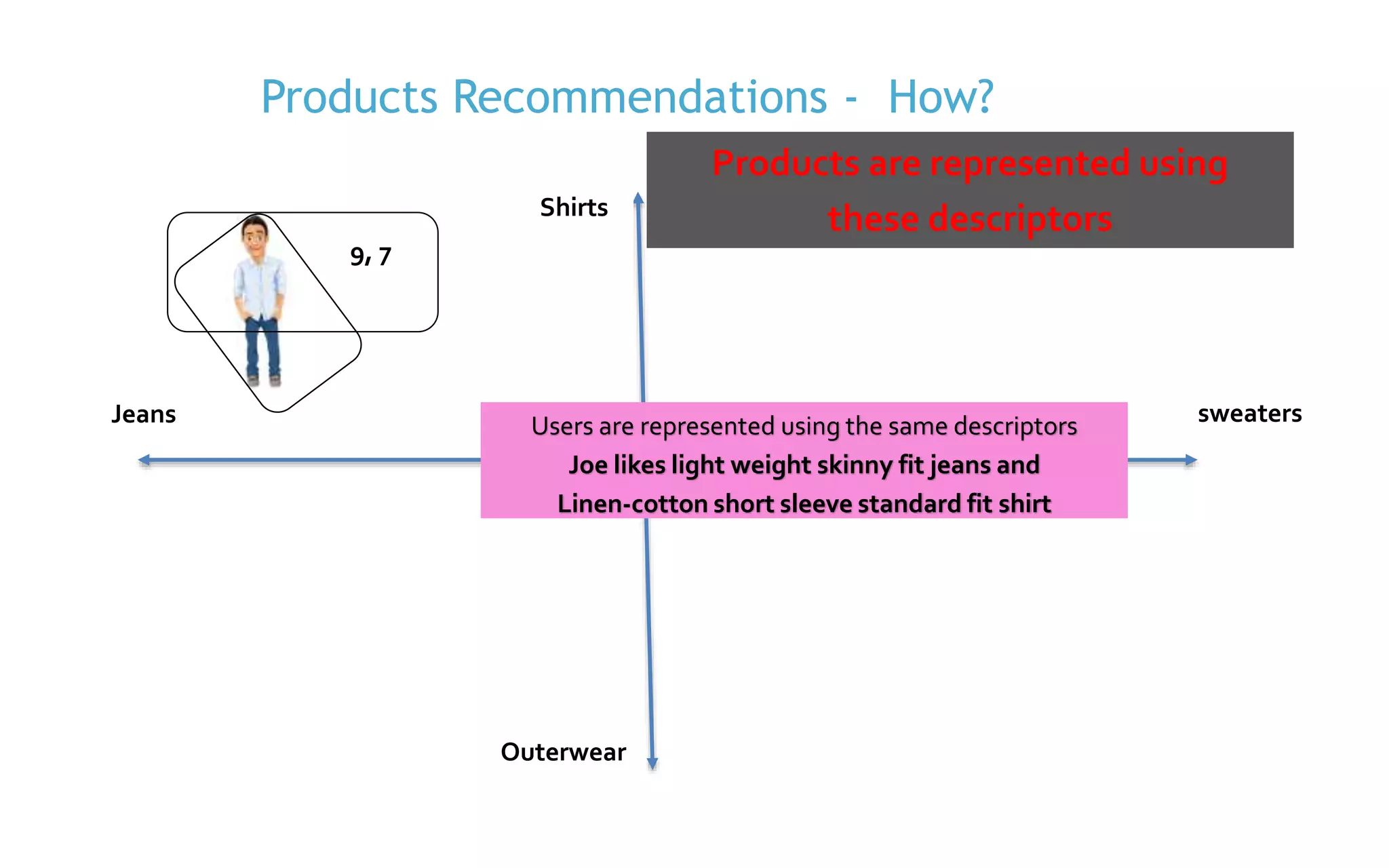
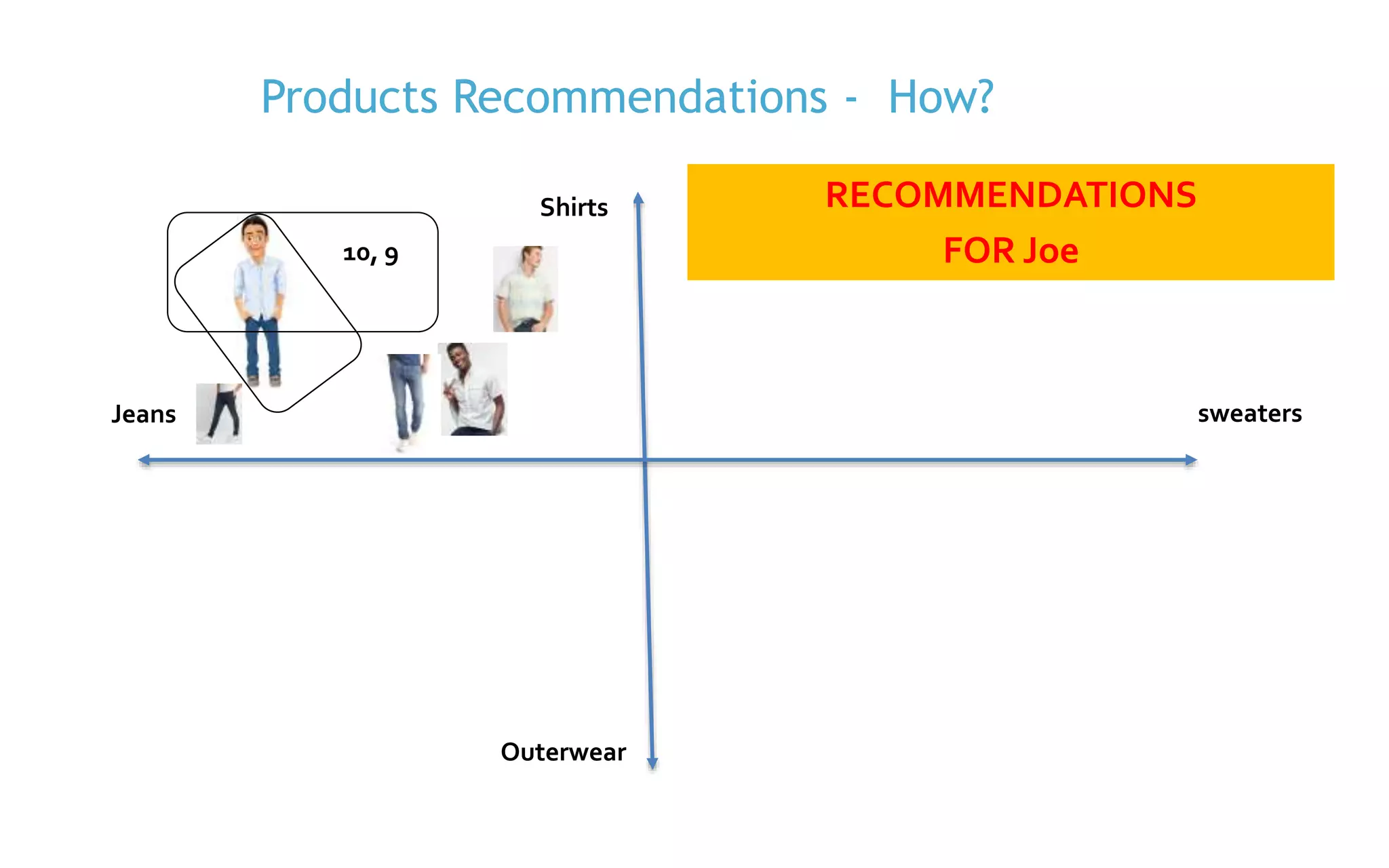
The document discusses the implementation of product recommendations using machine learning techniques, specifically through collaborative filtering and Apache Spark's MLlib. It explains the process of creating a recommendation engine, from data collection and model training to predictions and evaluations. The document emphasizes the role of big data and machine learning in personalizing user experiences by improving the accuracy of product suggestions.





























































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)


















