Downloaded 77 times











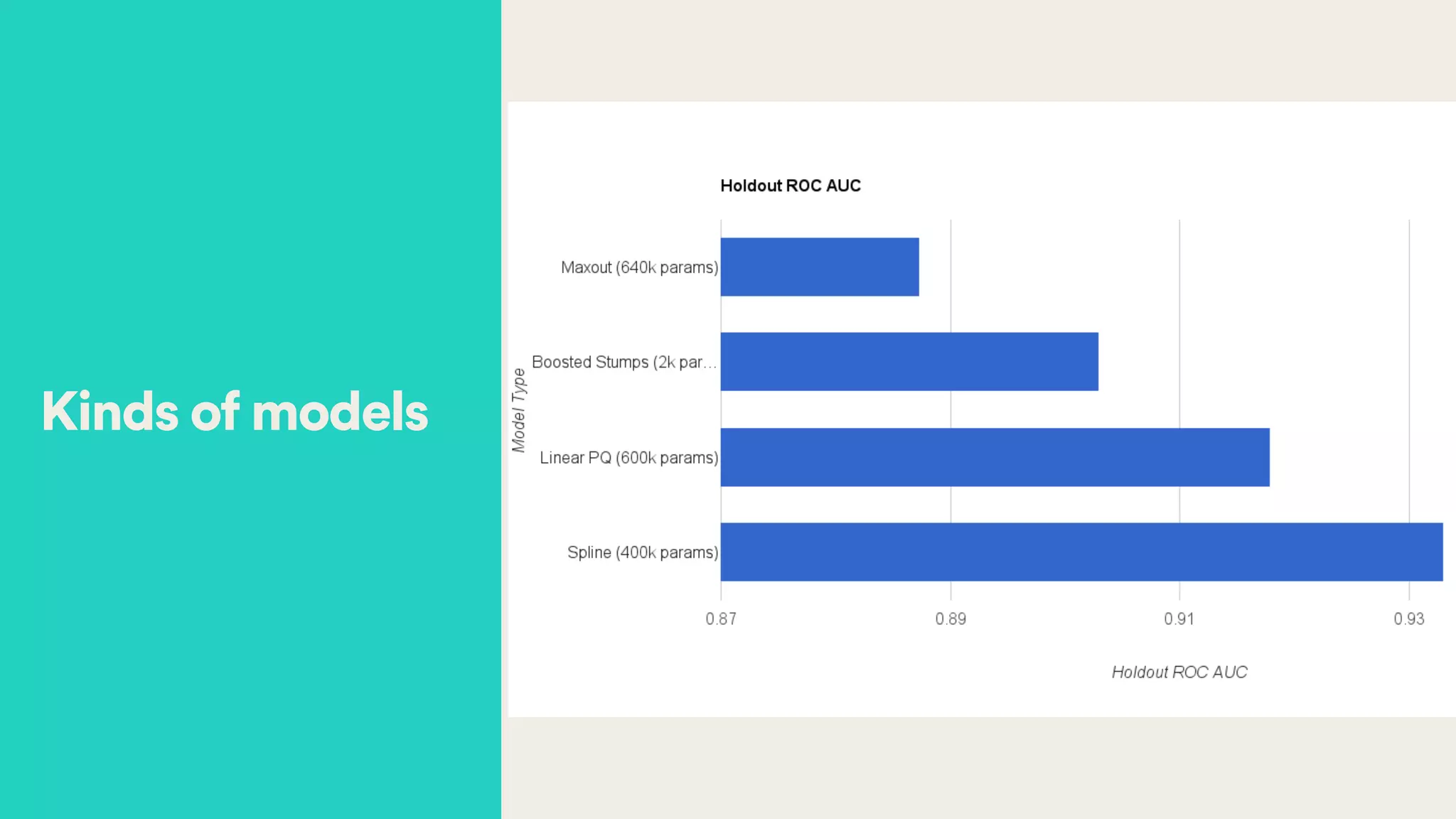
![• Control quantization
• Control interaction (crosses)
• O(millions) of sparse parameters
• O(tens) active any timeGlass box model
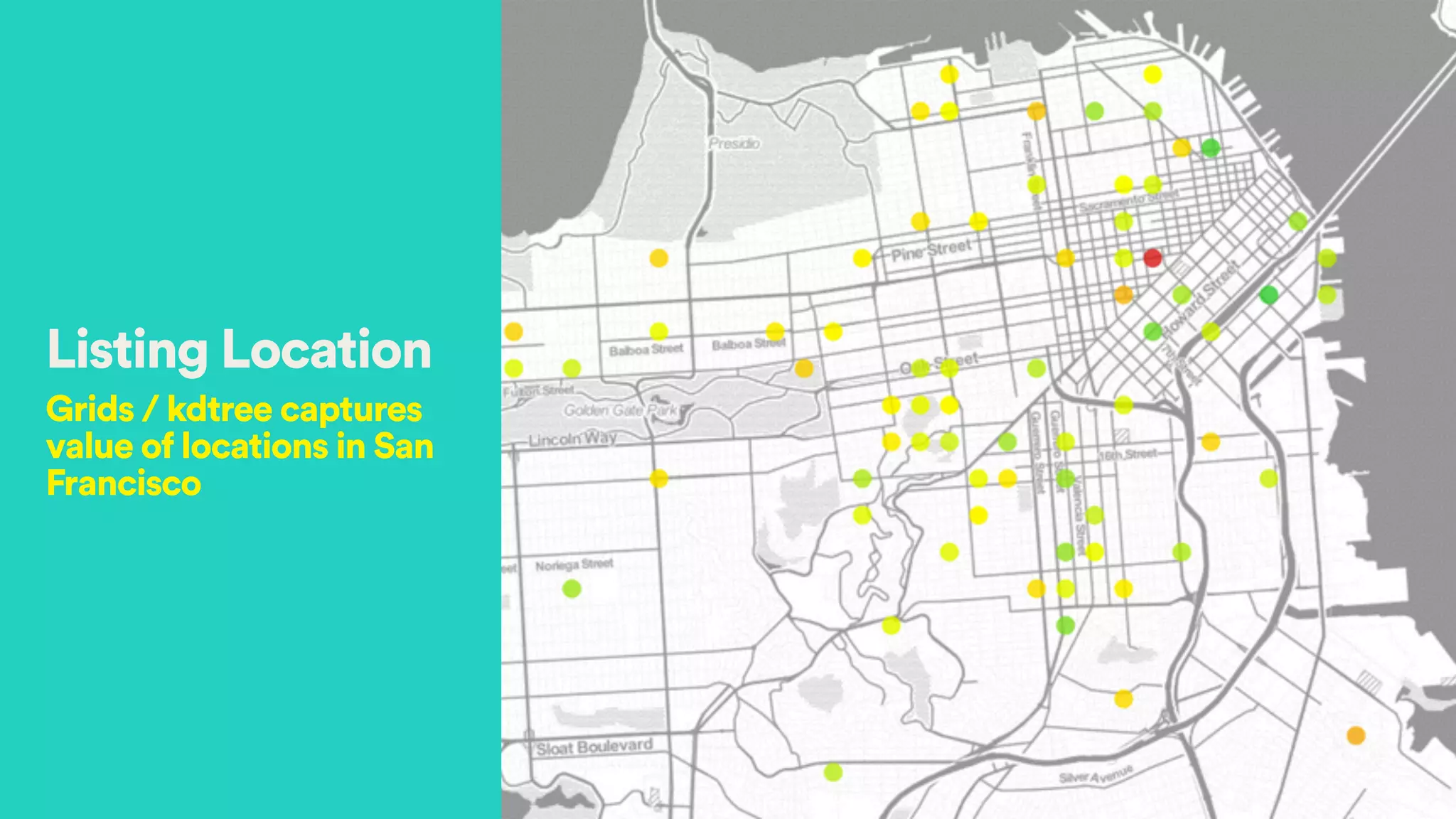
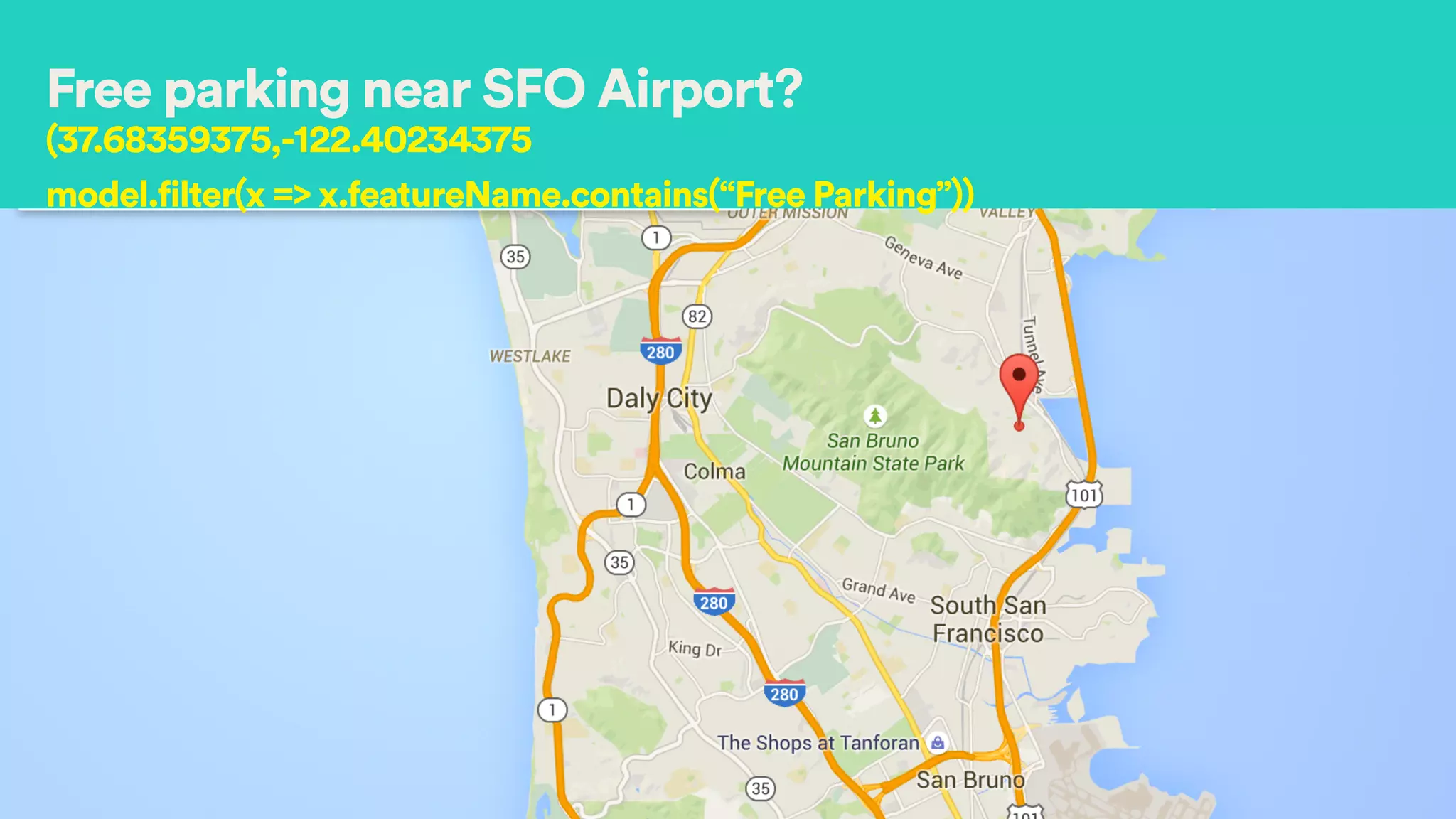
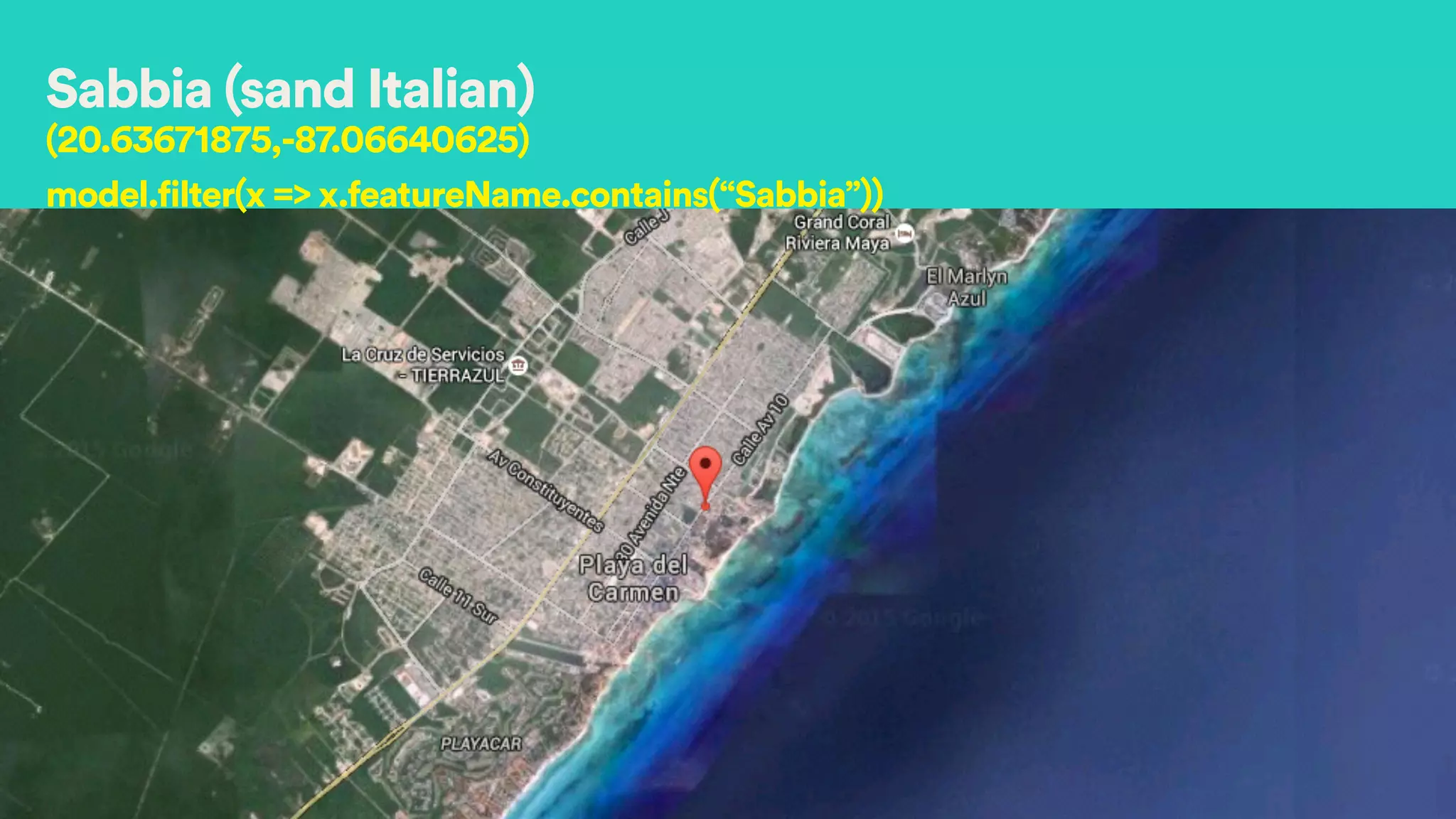
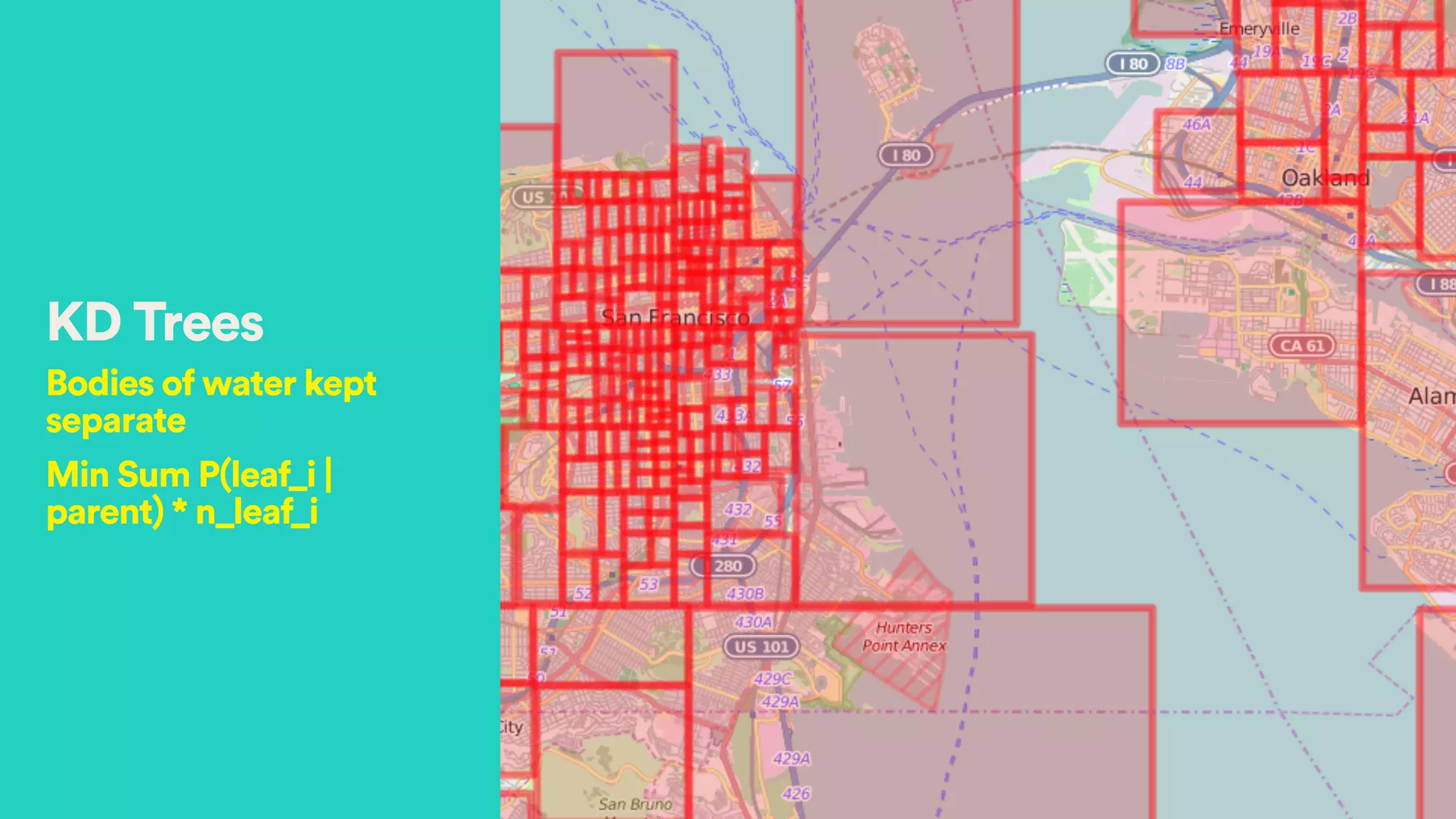
Lat :37.7841593
Long :-122.4031865
Price : 500
(37.7,-122.4) AND Price in [500, 550]
Good location High price!](https://image.slidesharecdn.com/hectoryeesparksummit2015-150616002420-lva1-app6892/75/Appraiser-How-Airbnb-Generates-Complex-Models-in-Spark-for-Demand-Prediction-20-2048.jpg)
![Feature transforms
Control feature engineering
quantize_listing_location {
transform : multiscale_grid_quantize
field1: "LOC"
buckets : [ 0.1, 0.01 ]
value1 : "Latitude"
value2 : "Longitude"
output : "QLOC"
}
!
quantize_price {
transform : multiscale_quantize
field1: "PRICE"
buckets : [ 10.0, 100.0 ]
value1 : "$"
output : “QPRICE" }
Price_X_Location {
transform : cross
field1 : "QPRICE"
field2 : "QLOC"
output : “PRICE_AND_LOCATION”
}
!
combined_transform {
transform : list
transforms : [
quantize_listing_location,
quantize_price,
Price_X_Location ]
}](https://image.slidesharecdn.com/hectoryeesparksummit2015-150616002420-lva1-app6892/75/Appraiser-How-Airbnb-Generates-Complex-Models-in-Spark-for-Demand-Prediction-21-2048.jpg)


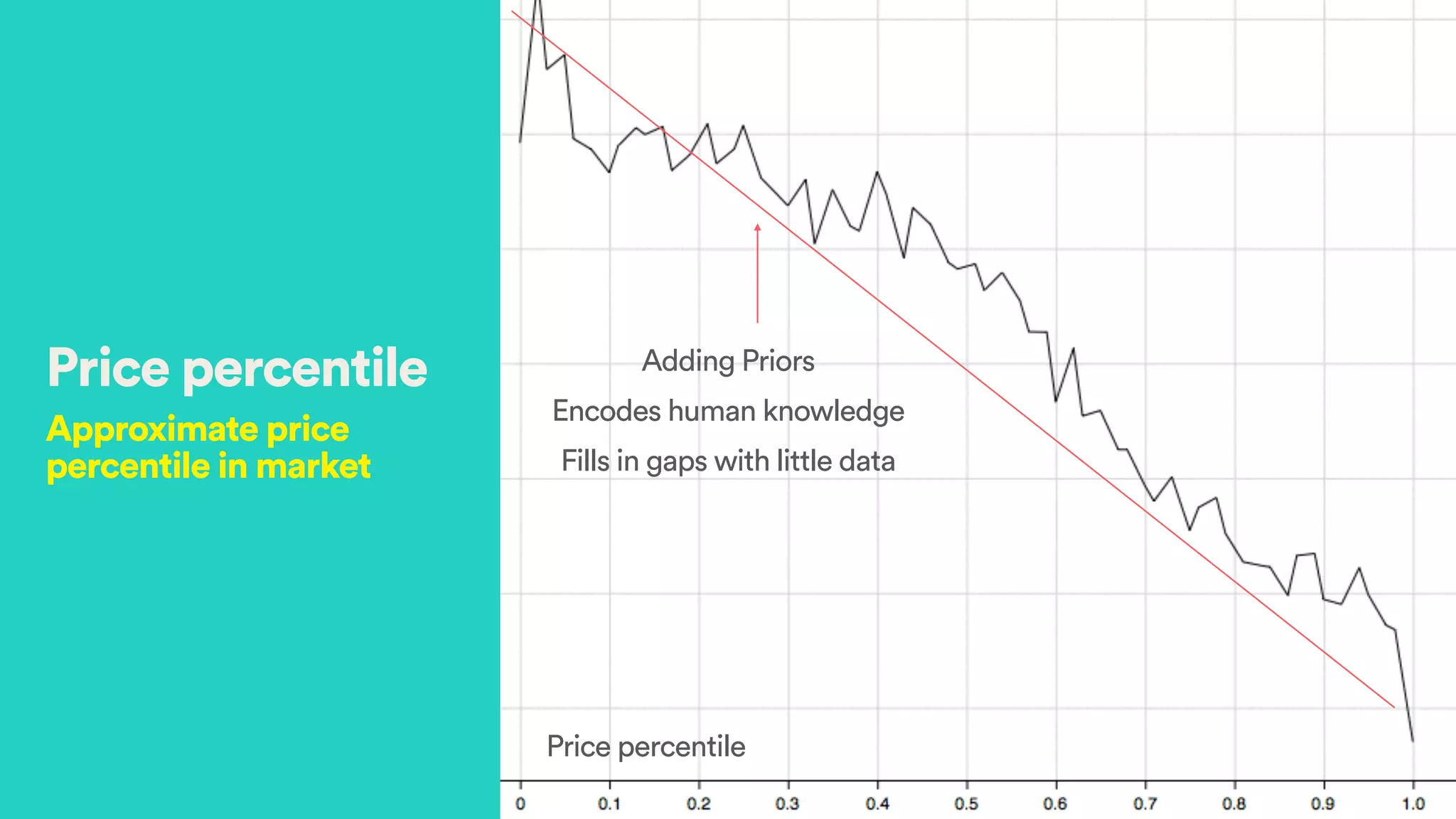
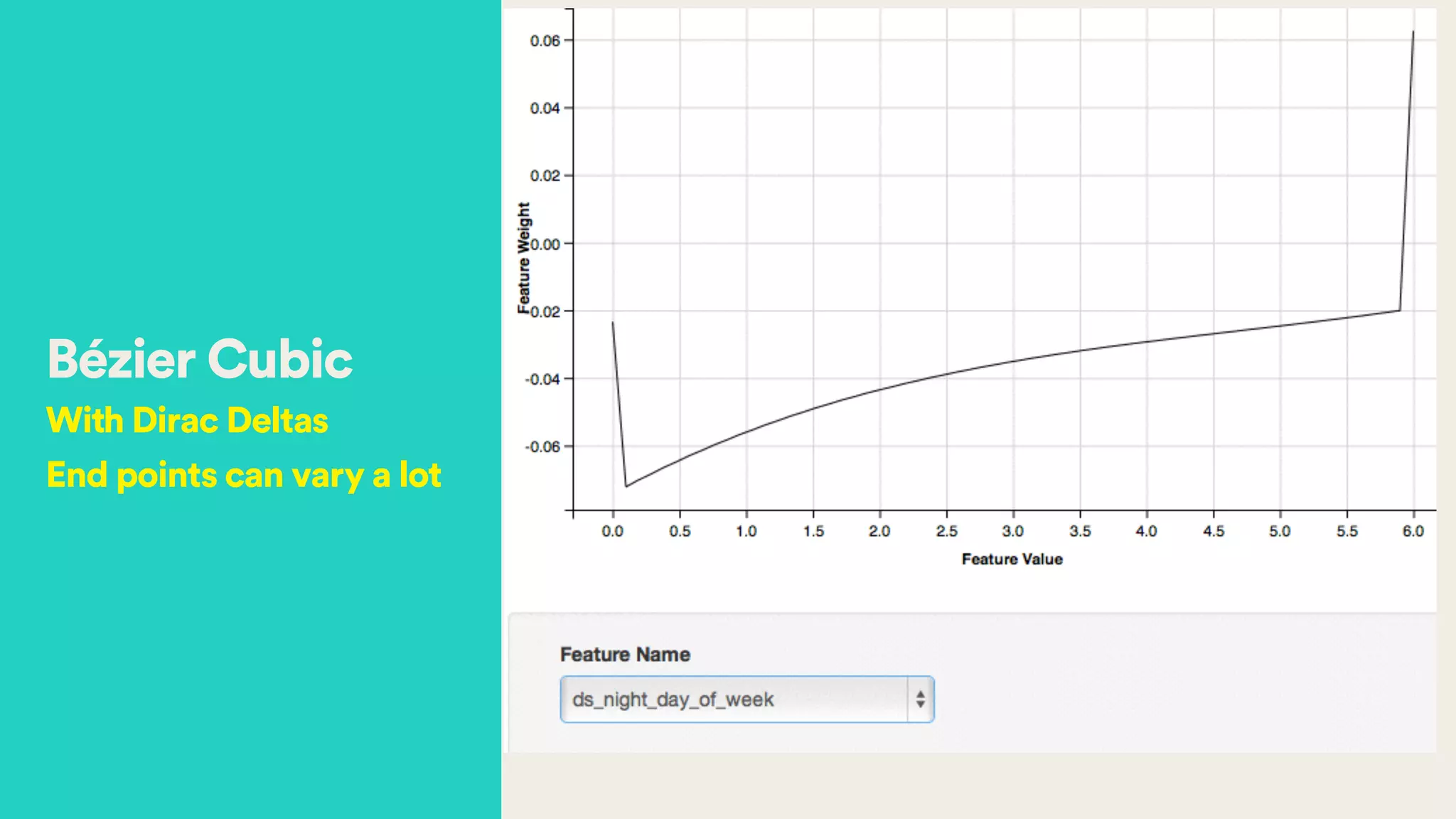
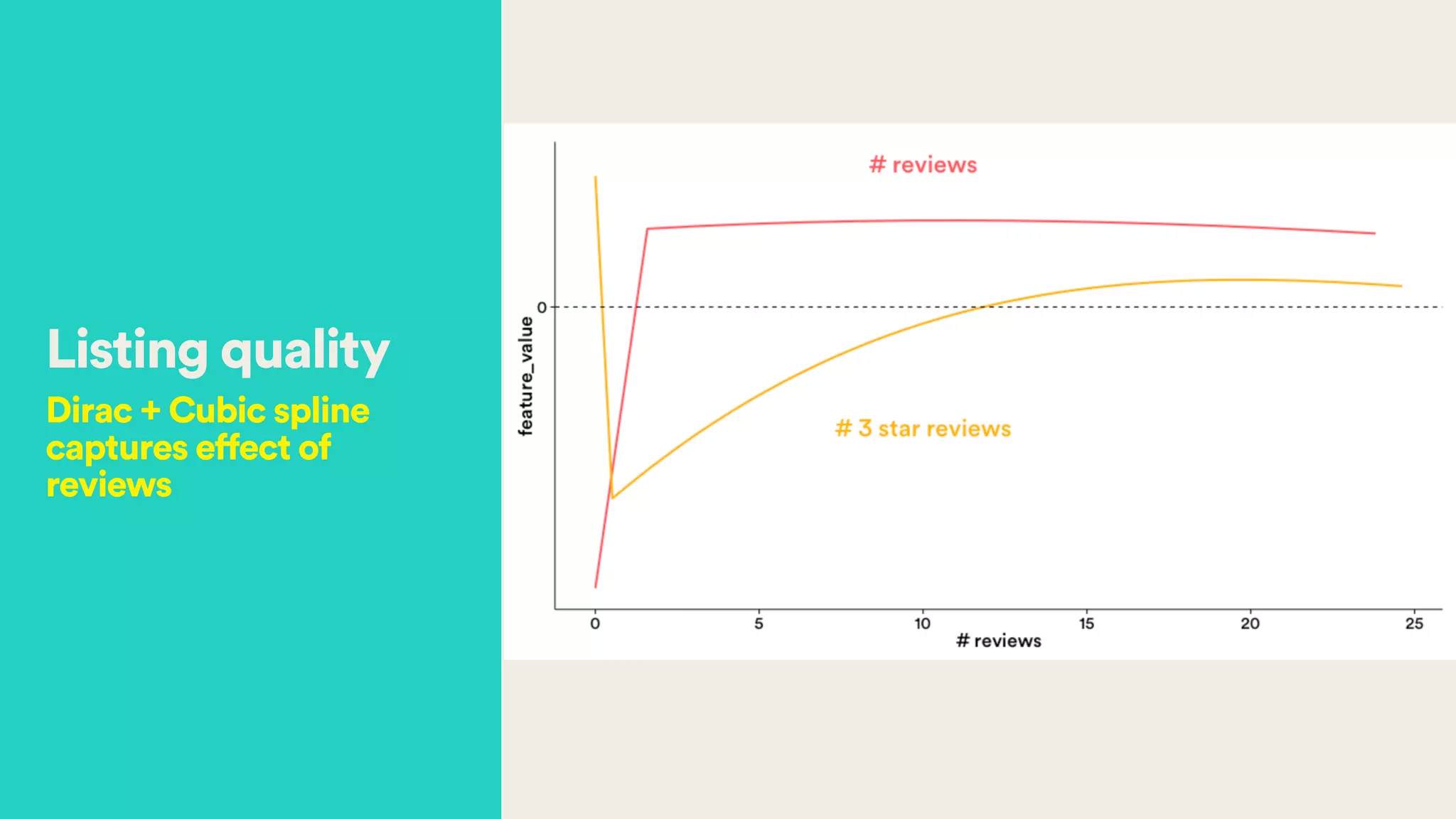
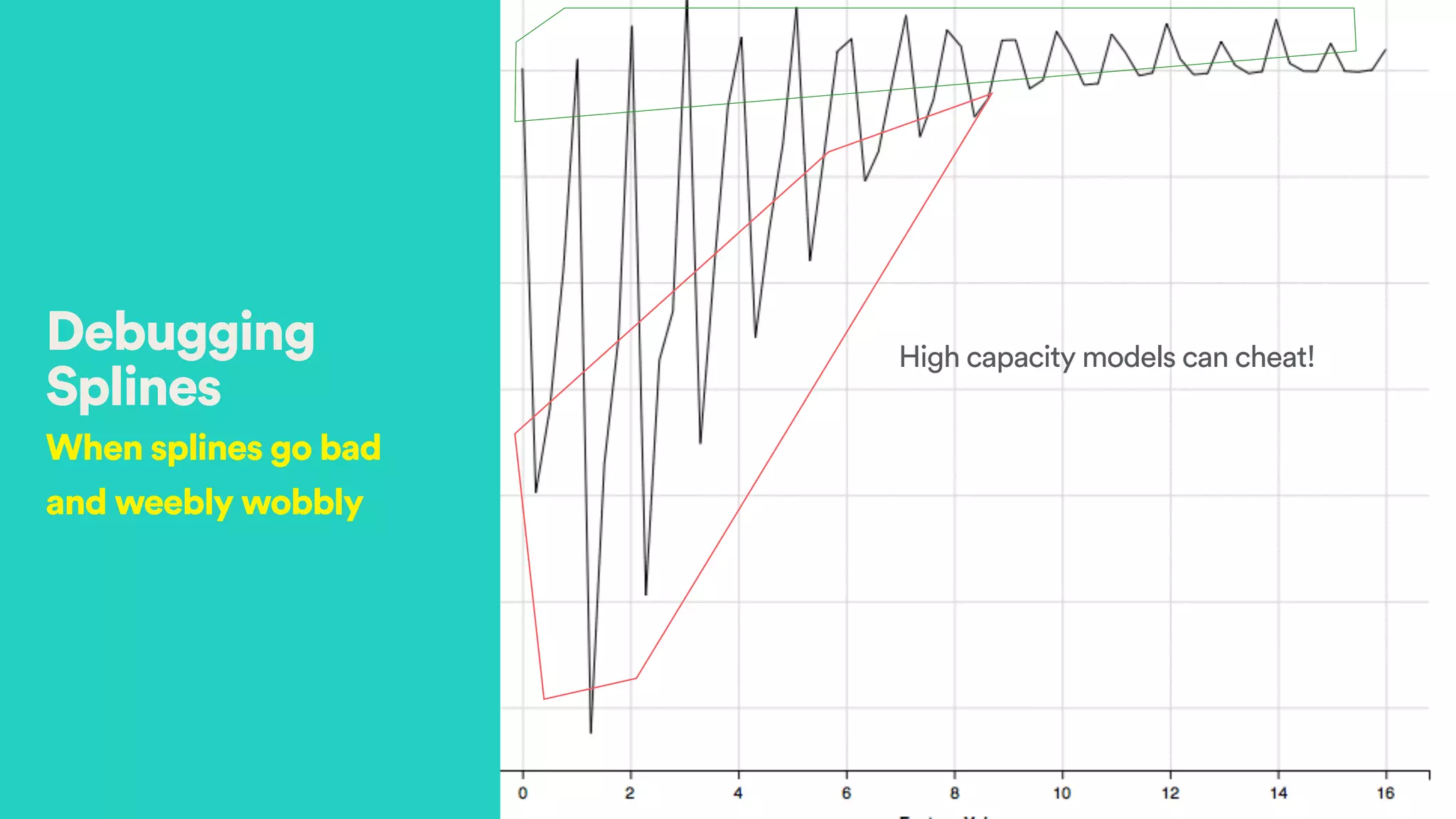







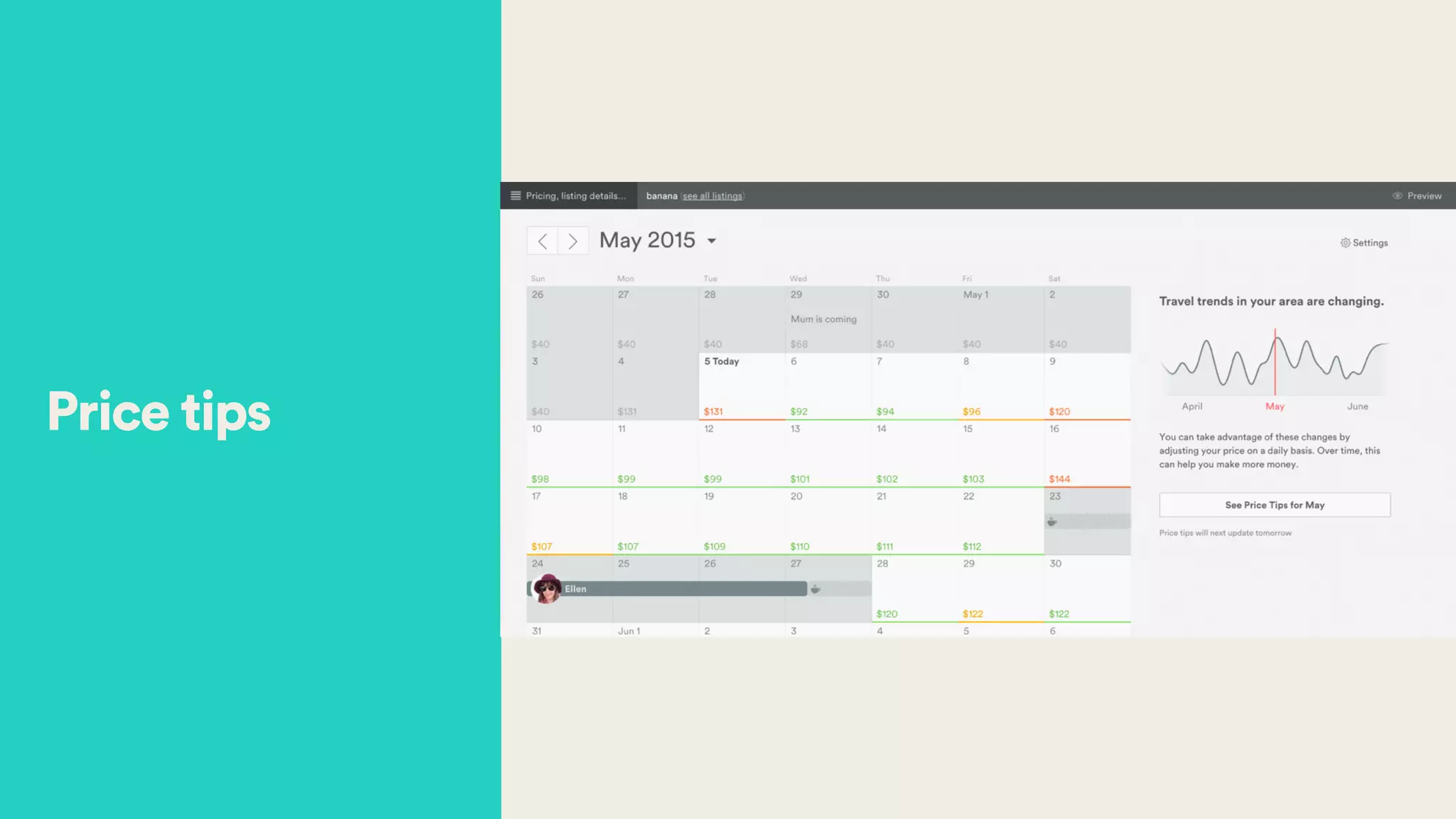
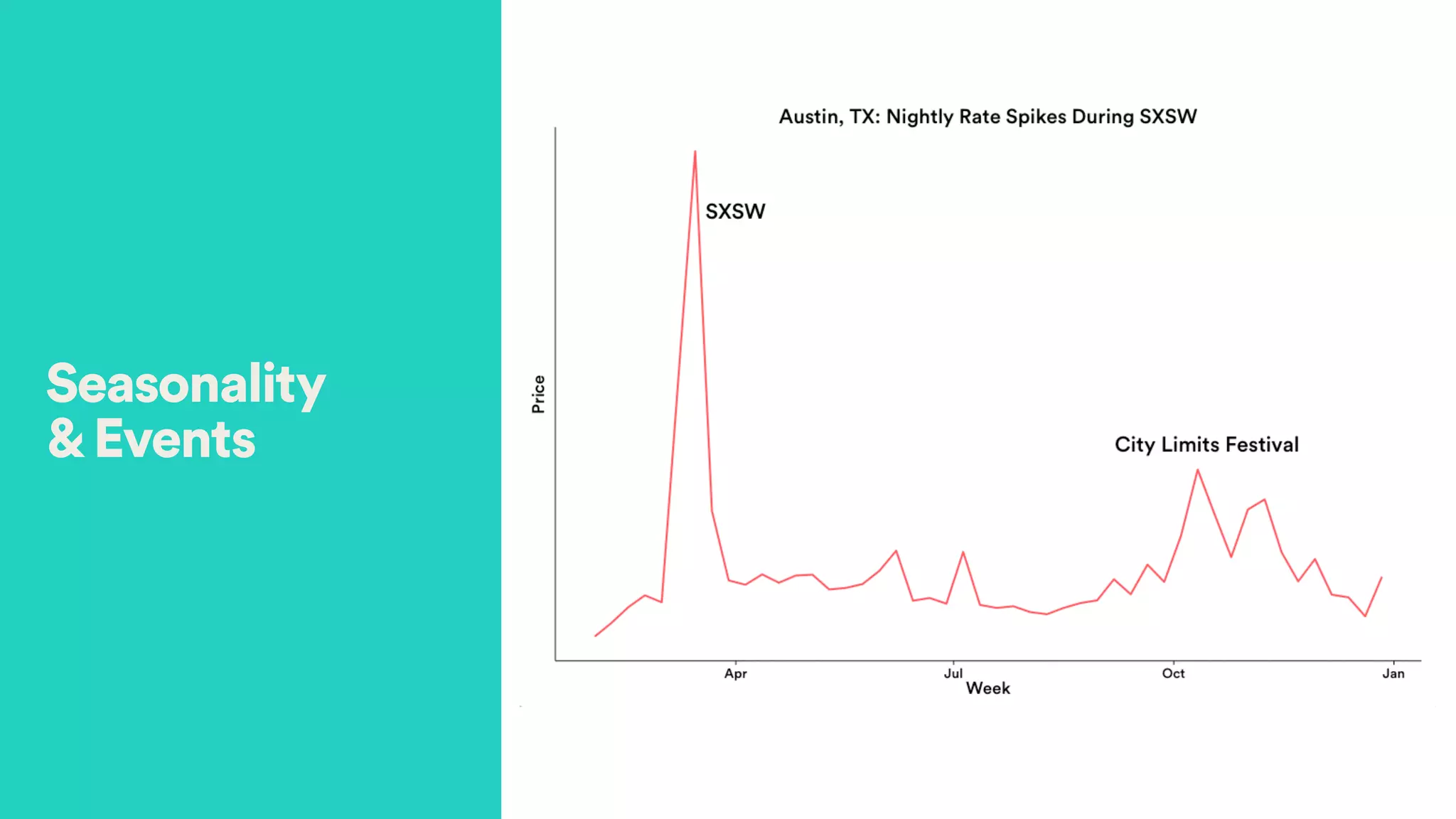
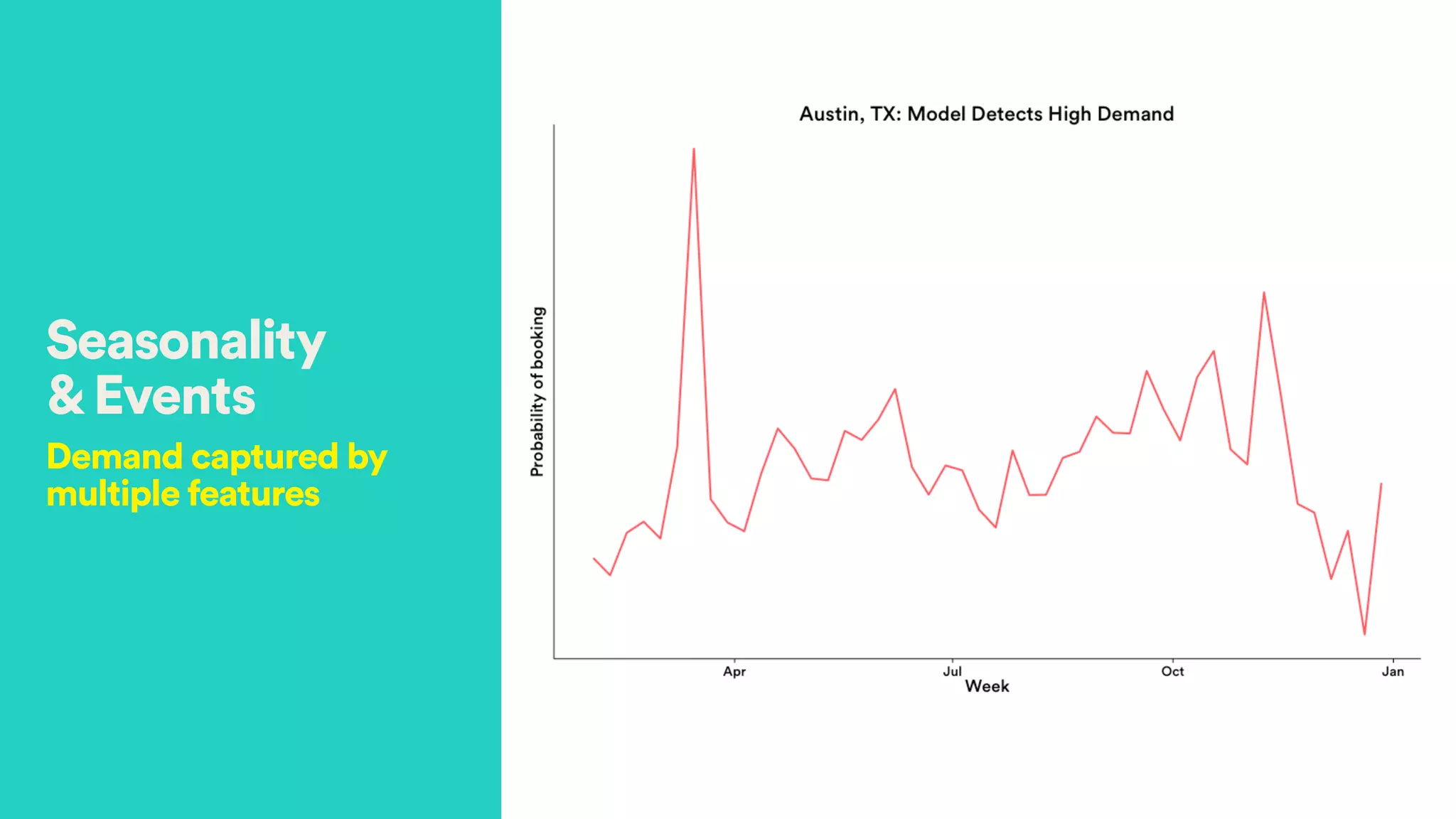
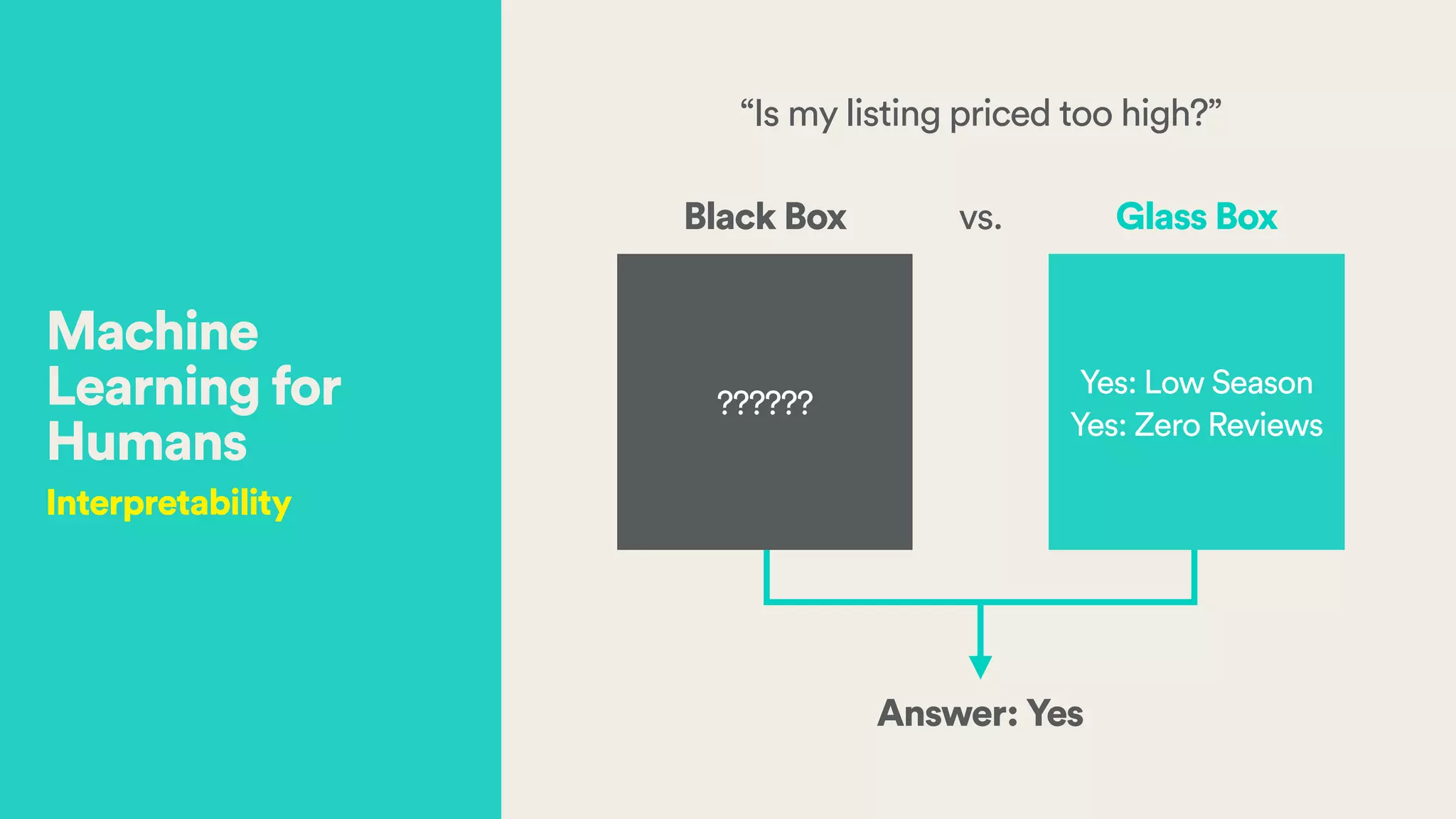
The document discusses Hector Yee's work on Airbnb's complex demand prediction models using machine learning and Spark, highlighting the challenges of pricing in a two-sided marketplace. It covers various modeling techniques, including the use of features related to demand, seasonality, listing type, and location to predict booking probabilities. Additionally, the document emphasizes the need for model interpretability and the trade-offs associated with different modeling approaches.





























![[Airbnb Embedding] Real-time Personalization using Embeddings for Search Rank...](https://cdn.slidesharecdn.com/ss_thumbnails/airbnbembeddingreal-timepersonalizationusingembeddingsforsearchrankingatairbnbairbnb2018-250128024550-f8ecfde5-thumbnail.jpg?width=640&height=640&fit=bounds)





















![ANPARA THERMAL POWER STATION[1] sangam.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/anparathermalpowerstation1sangam-251121115219-9261cde4-thumbnail.jpg?width=640&height=640&fit=bounds)









