Downloaded 63 times









![21
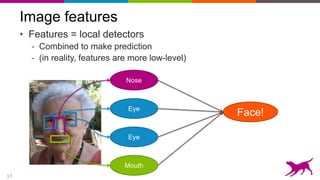
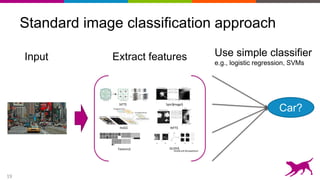
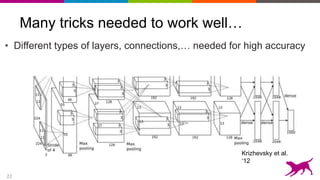
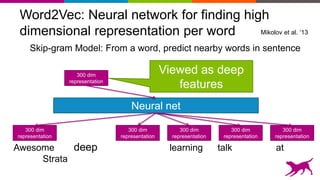
Use neural network to learn features
Each layer learns features, at different levels of abstraction
Y LeCun
MA Ranzato
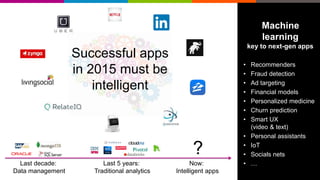
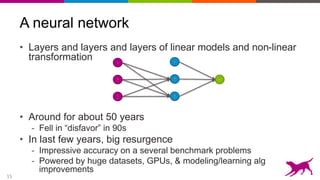
Deep Learning = Learning Hierarchical Representations
It's deep if it has more than one stage of non-linear feature
transformation
Trainable
Classifier
Low-Level
Feature
Mid-Level
Feature
High-Level
Feature
Feature visualization of convolutional net trained on ImageNet from [ Zeiler & Fergus 2013]](https://image.slidesharecdn.com/strata-london-deeplearning-05-2015-150507163508-lva1-app6891/85/Strata-London-Deep-Learning-05-2015-21-320.jpg)
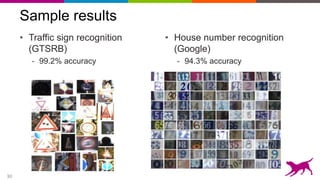

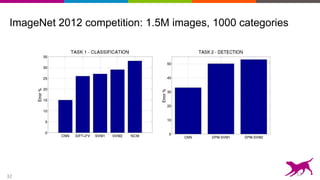

![34
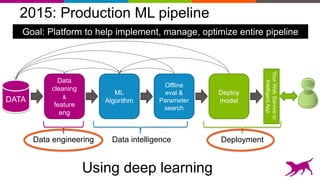
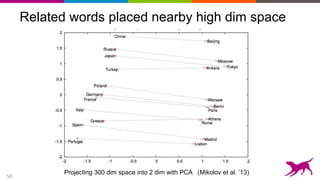
Application to scene parsing
©Carlos Guestrin 2005-2014
Y LeCun
MA Ranzato
Semantic Labeling:
Labeling every pixel with the object it belongs to
[ Farabet et al. ICML 2012, PAMI 2013]
Would help identify obstacles, targets, landing sites, dangerous areas
Would help line up depth map with edge maps](https://image.slidesharecdn.com/strata-london-deeplearning-05-2015-150507163508-lva1-app6891/85/Strata-London-Deep-Learning-05-2015-28-320.jpg)




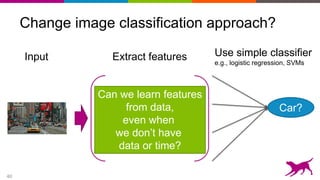

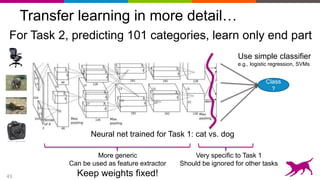
![44
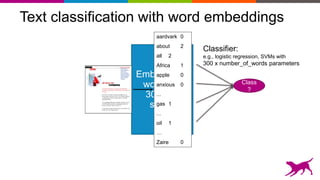
Careful where you cut…
Last few layers tend to be too specific
Y LeCun
MA Ranzato
Deep Learning = Learning Hierarchical Representations
It's deep if it has more than one stage of non-linear feature
transformation
Trainable
Classifier
Low-Level
Feature
Mid-Level
Feature
High-Level
Feature
Feature visualization of convolutional net trained on ImageNet from [ Zeiler & Fergus 2013]
Too specific for
car detectionUse these!](https://image.slidesharecdn.com/strata-london-deeplearning-05-2015-150507163508-lva1-app6891/85/Strata-London-Deep-Learning-05-2015-38-320.jpg)
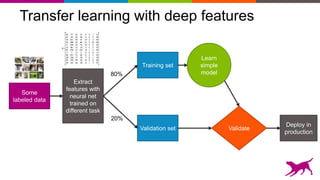





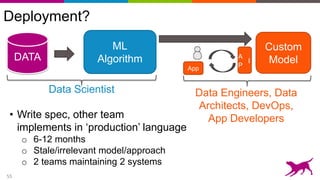
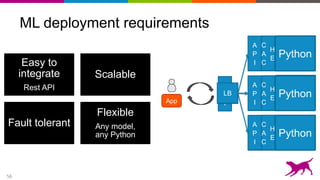
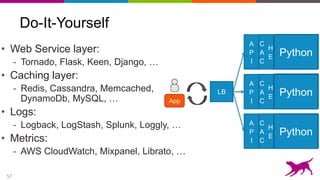
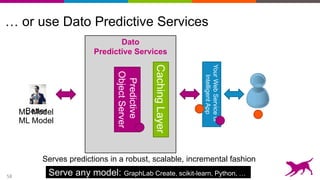
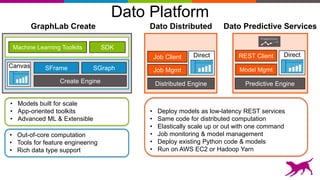

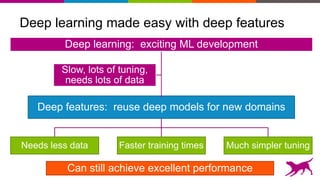

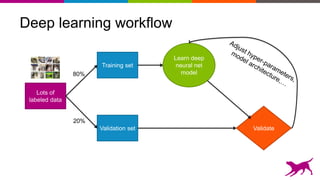
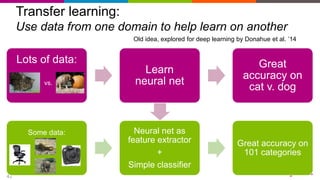
Deep learning techniques can be used to learn features from data rather than relying on hand-crafted features. This allows neural networks to be applied to problems in computer vision, natural language processing, and other domains. Transfer learning techniques take advantage of features learned from one task and apply them to another related task, even when limited data is available for the second task. Deploying machine learning models in production requires techniques for serving predictions through scalable APIs and caching layers to meet performance requirements.

































































![[DSC Europe 25] Andrzej Kowalczyk - AI - how to start small and grow in the f...](https://cdn.slidesharecdn.com/ss_thumbnails/oy1zmo94qv6vpcqjvno2-andrzej-kowalczyk-ai-how-to-start-small-and-grow-in-the-future-1-260119121559-cf093b23-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Stefan Brankovic - #ResumeIsDead. AI-Powered Interviews and C...](https://cdn.slidesharecdn.com/ss_thumbnails/qnmbsv0xq3uysdrq3sev-2-stefan-brankovic-job-bolt-260114111931-a065aa3d-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DSC Europe 25] Slobodan Dolinic - Smart and Intelligent Green Region.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/0bribinjsp6ghwtvsvor-2-sigre-slobodan-dolinic-260115093812-c9c10e90-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Bojan Djuricic - Predictive Design Process.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/5awdrbedqdek3gqu2ezy-4-the-predictive-design-bojan-djuricic-260120105856-6c399e9b-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dragan Jerosimovic - The Anatomy of a Narrative Simulation.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/vzputuprdqr6zwbrwdcw-1-dragan-jerosimovic-the-anatomy-of-a-narrative-simulation-260114111931-9d04fba2-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Danilo Djukanovic - From Vibes to KPIs: Turning Culture Into ...](https://cdn.slidesharecdn.com/ss_thumbnails/inqestws5wf0cik2glgv-3-danilo-djukanovic-from-vibes-to-kpis-presentation-260114111931-dacff81f-thumbnail.jpg?width=640&height=640&fit=bounds)






