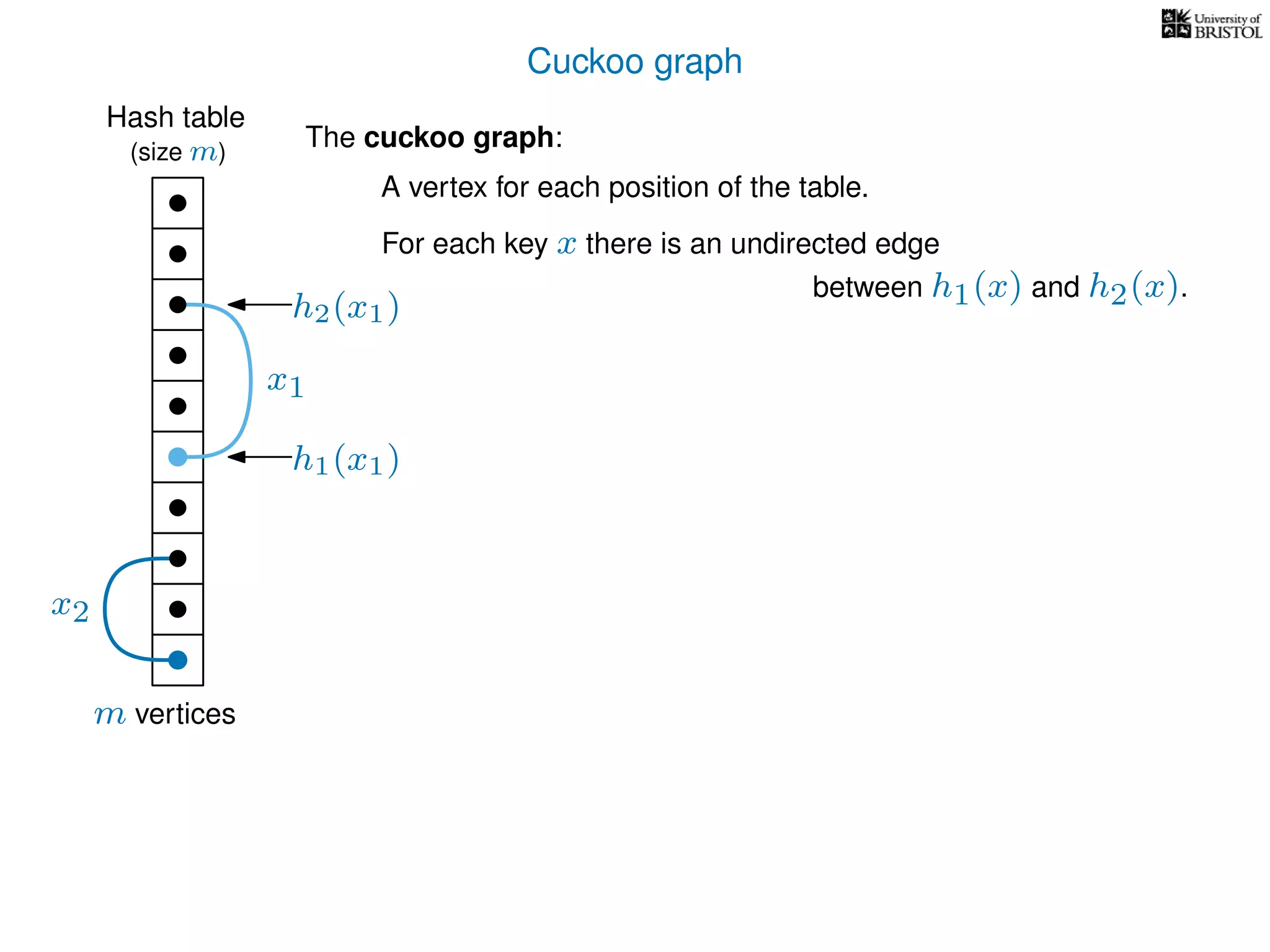
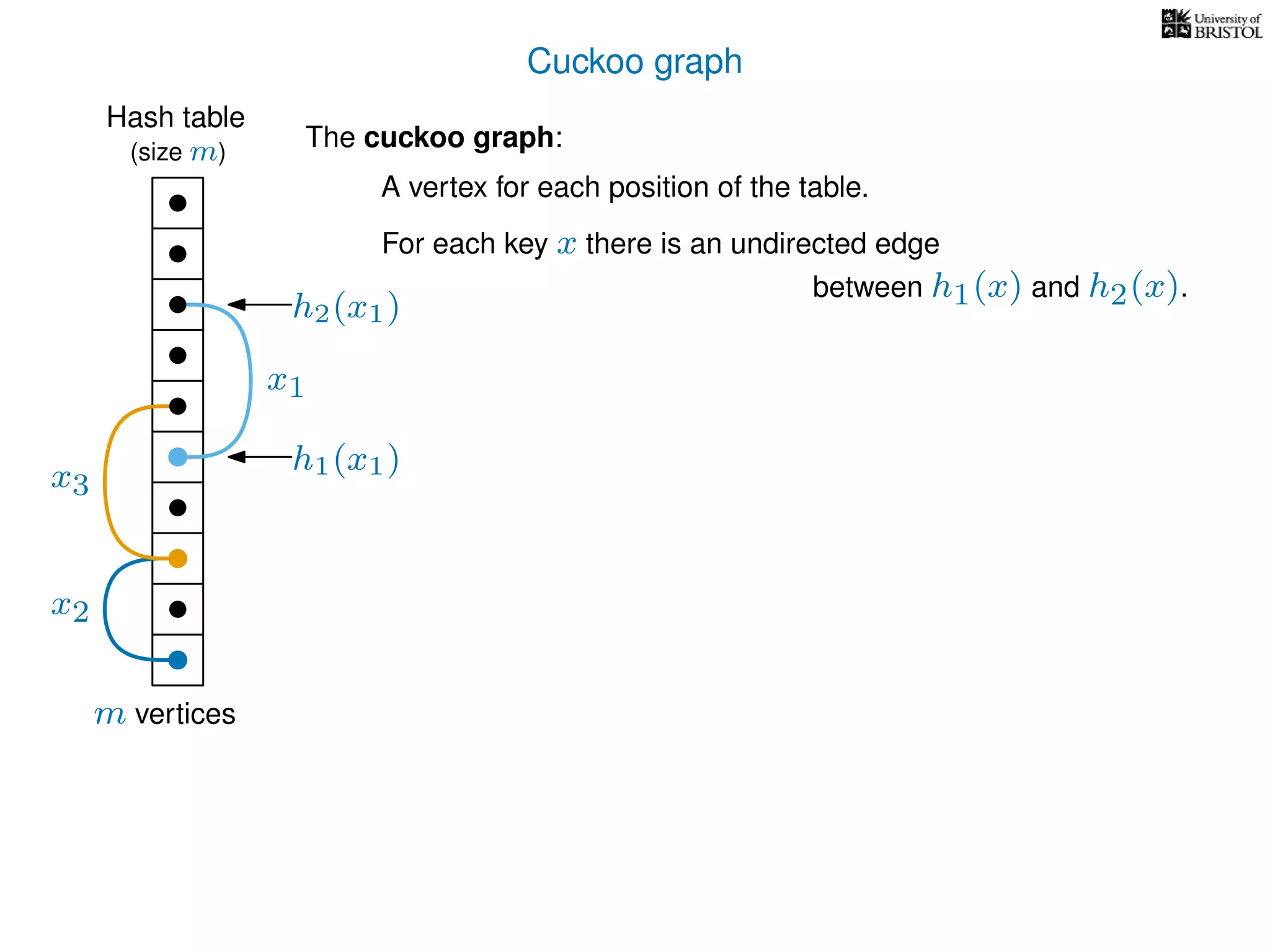
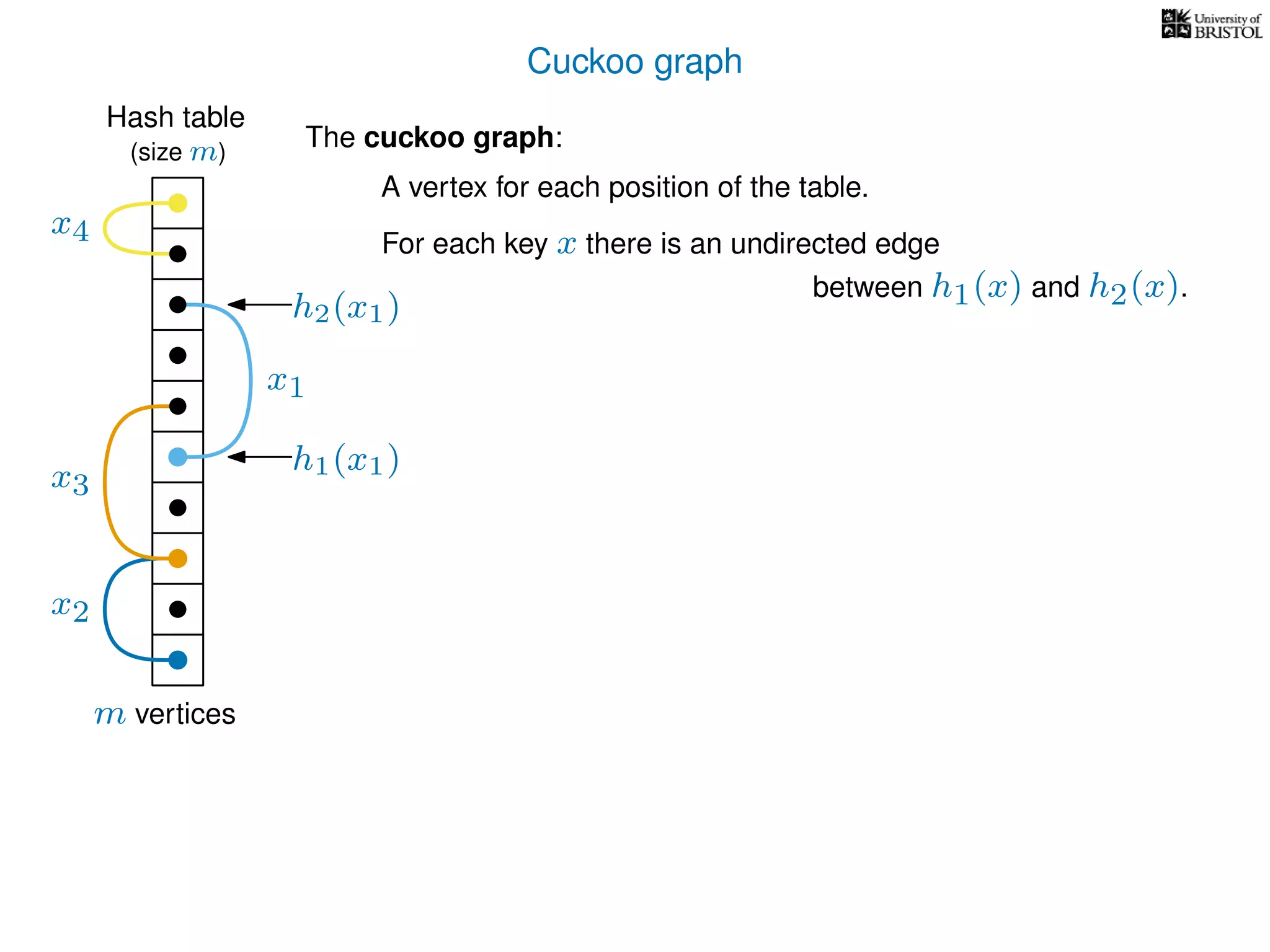
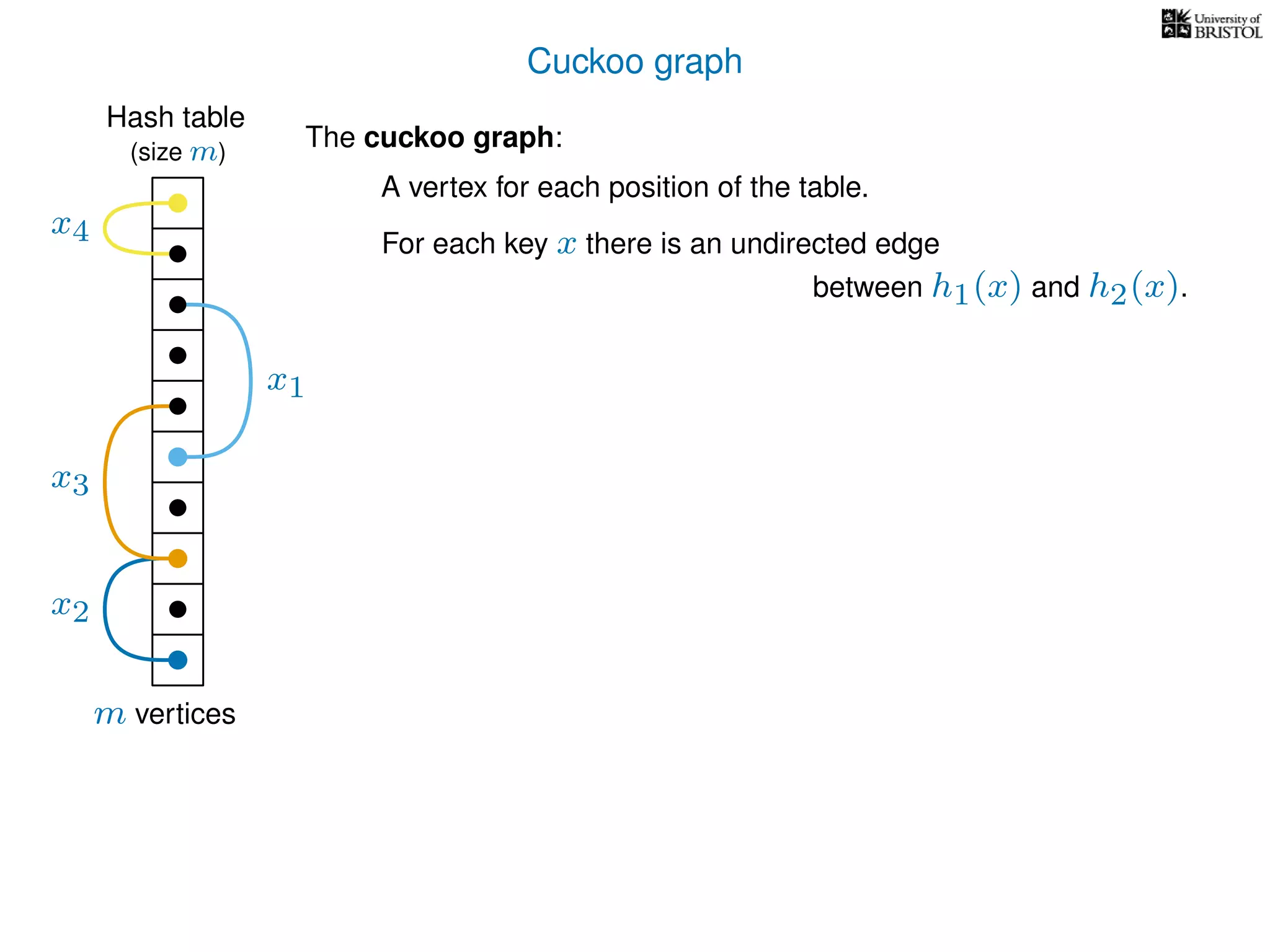
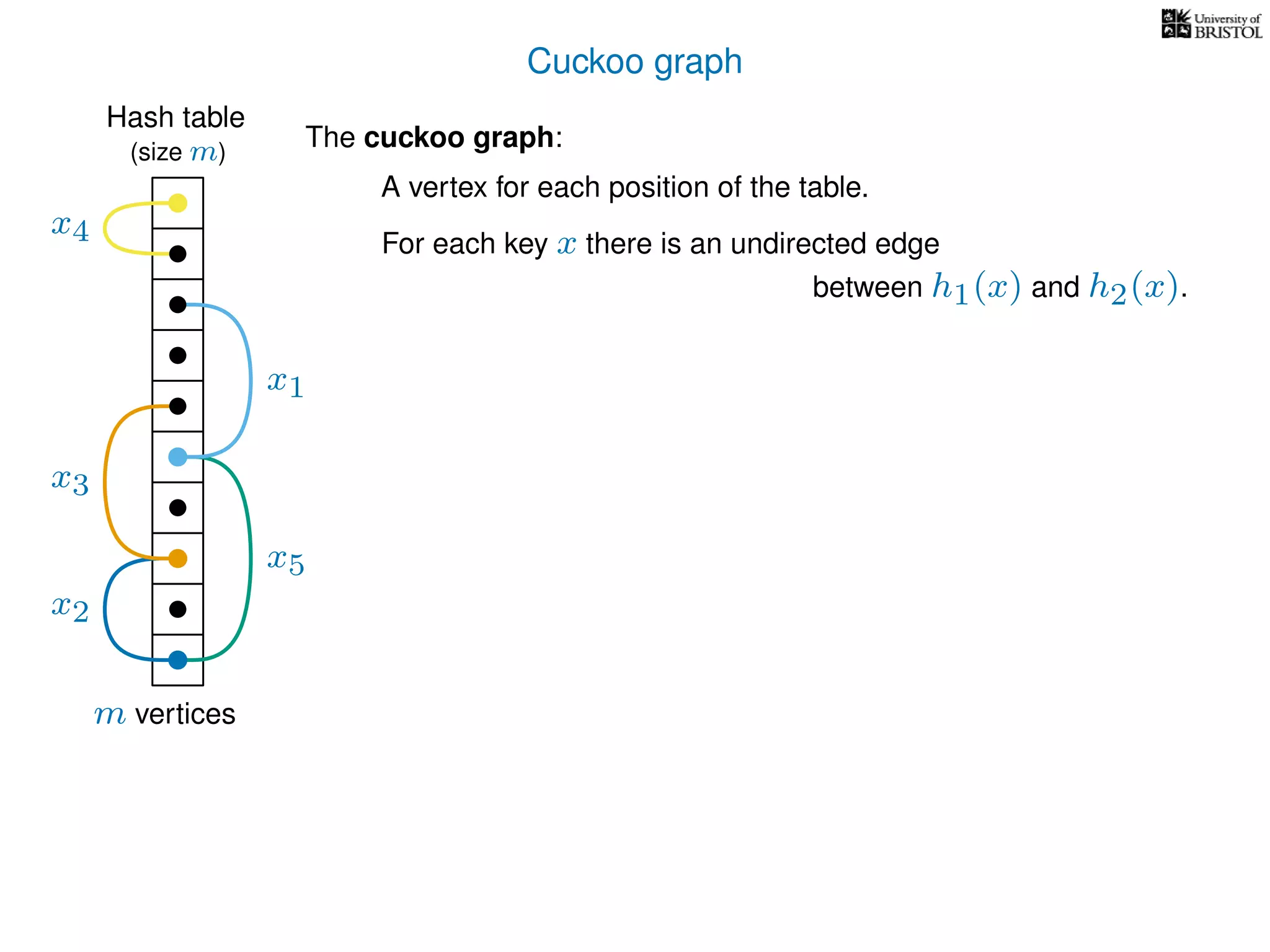
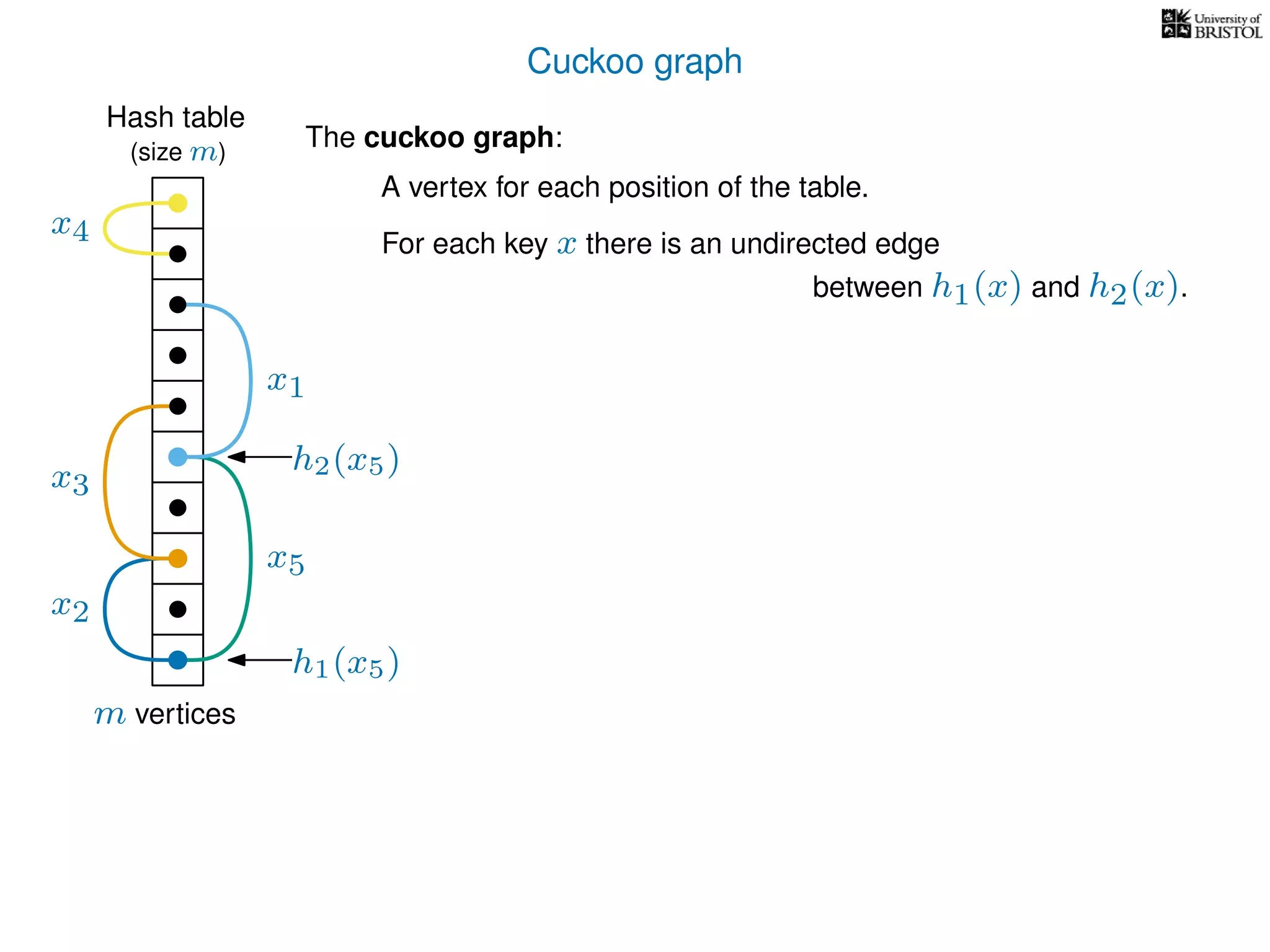
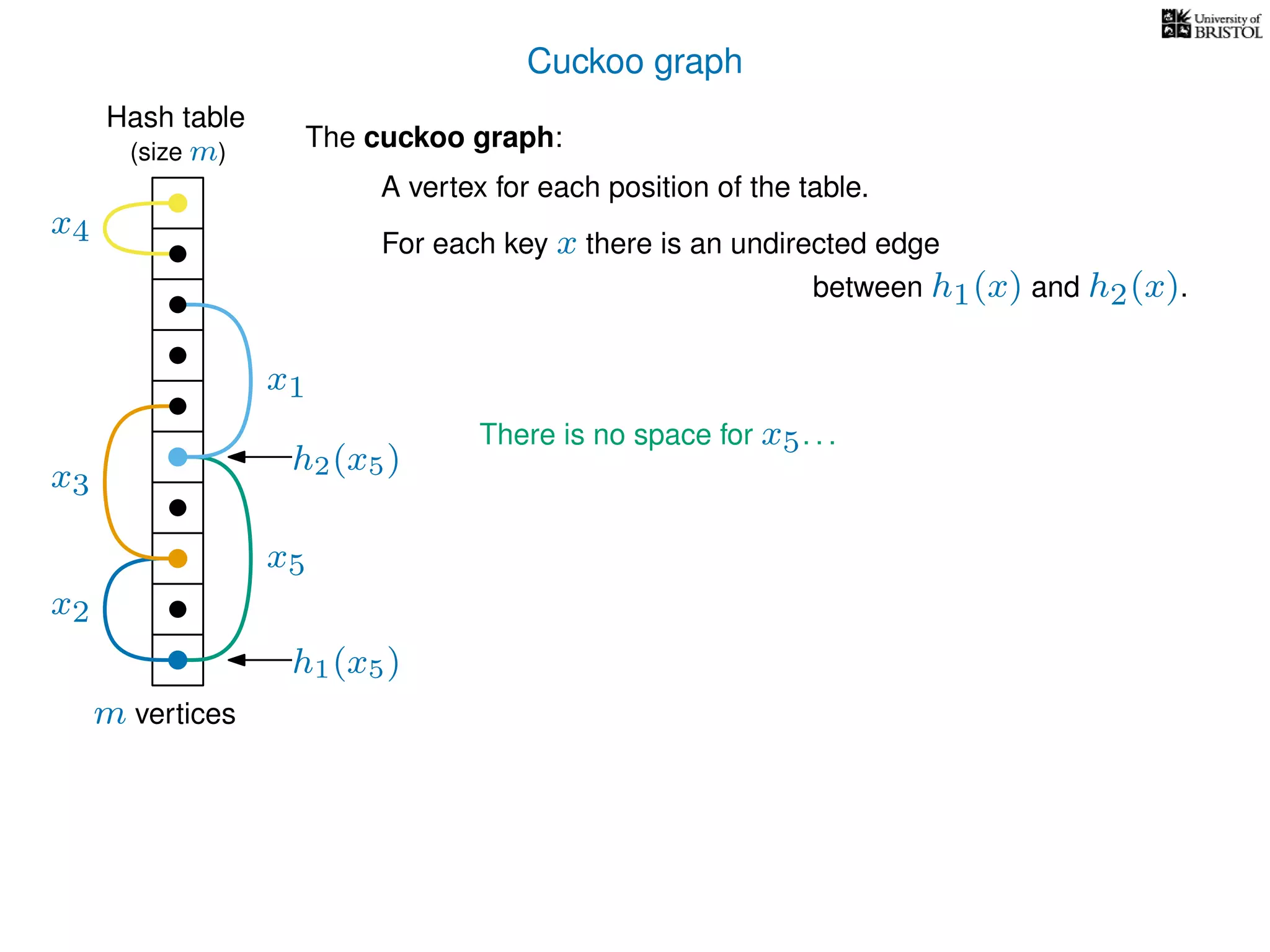
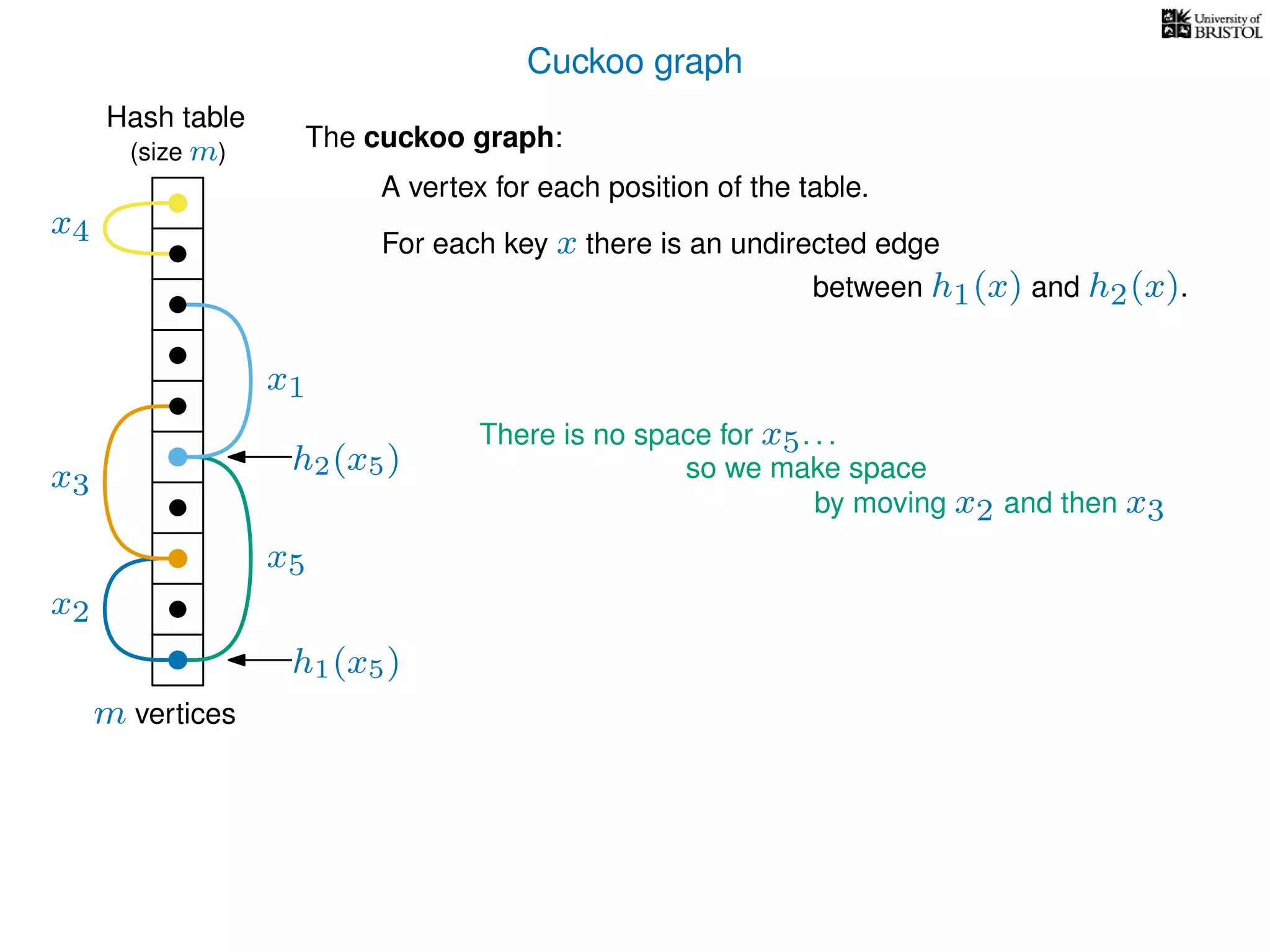
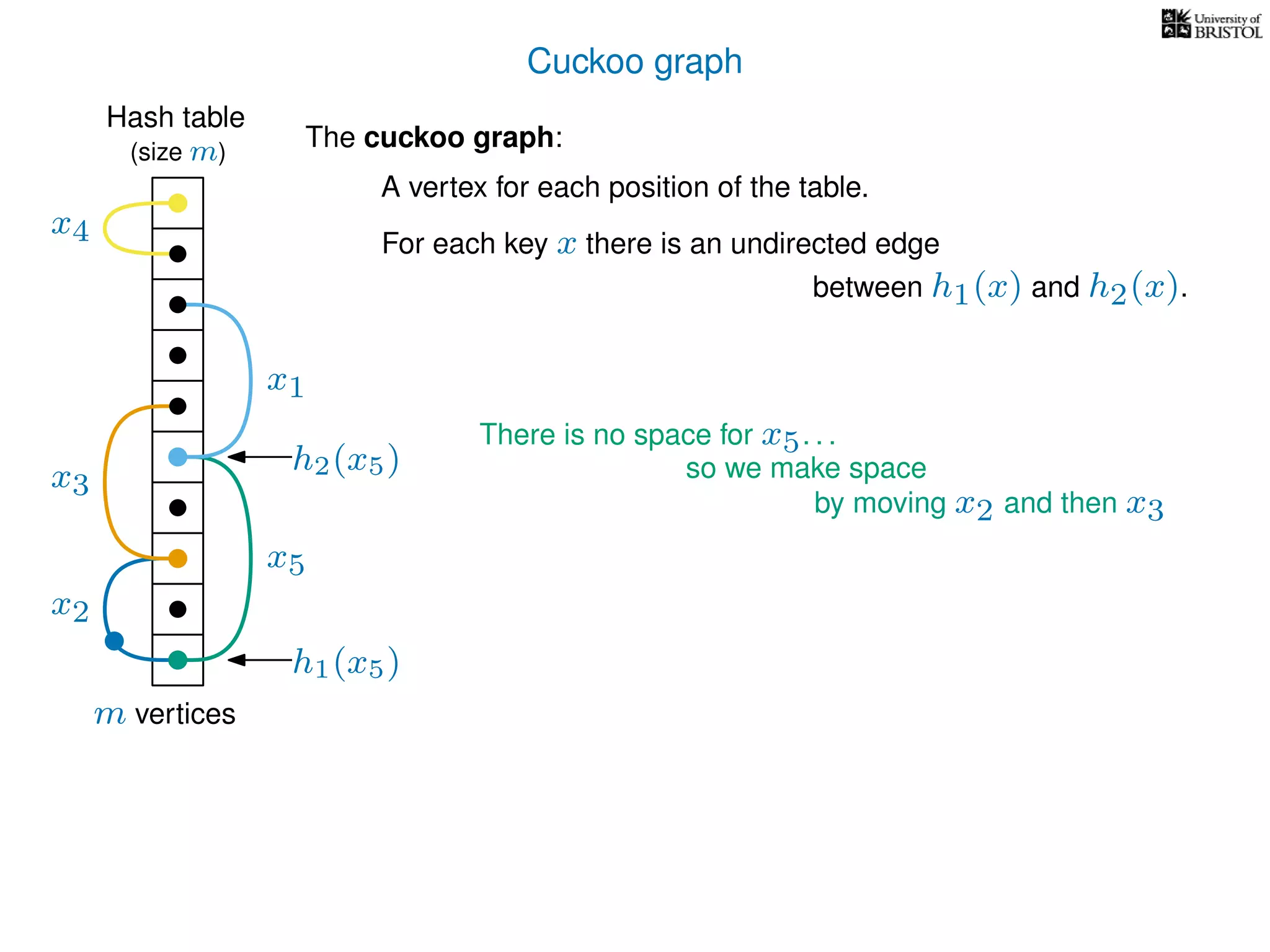
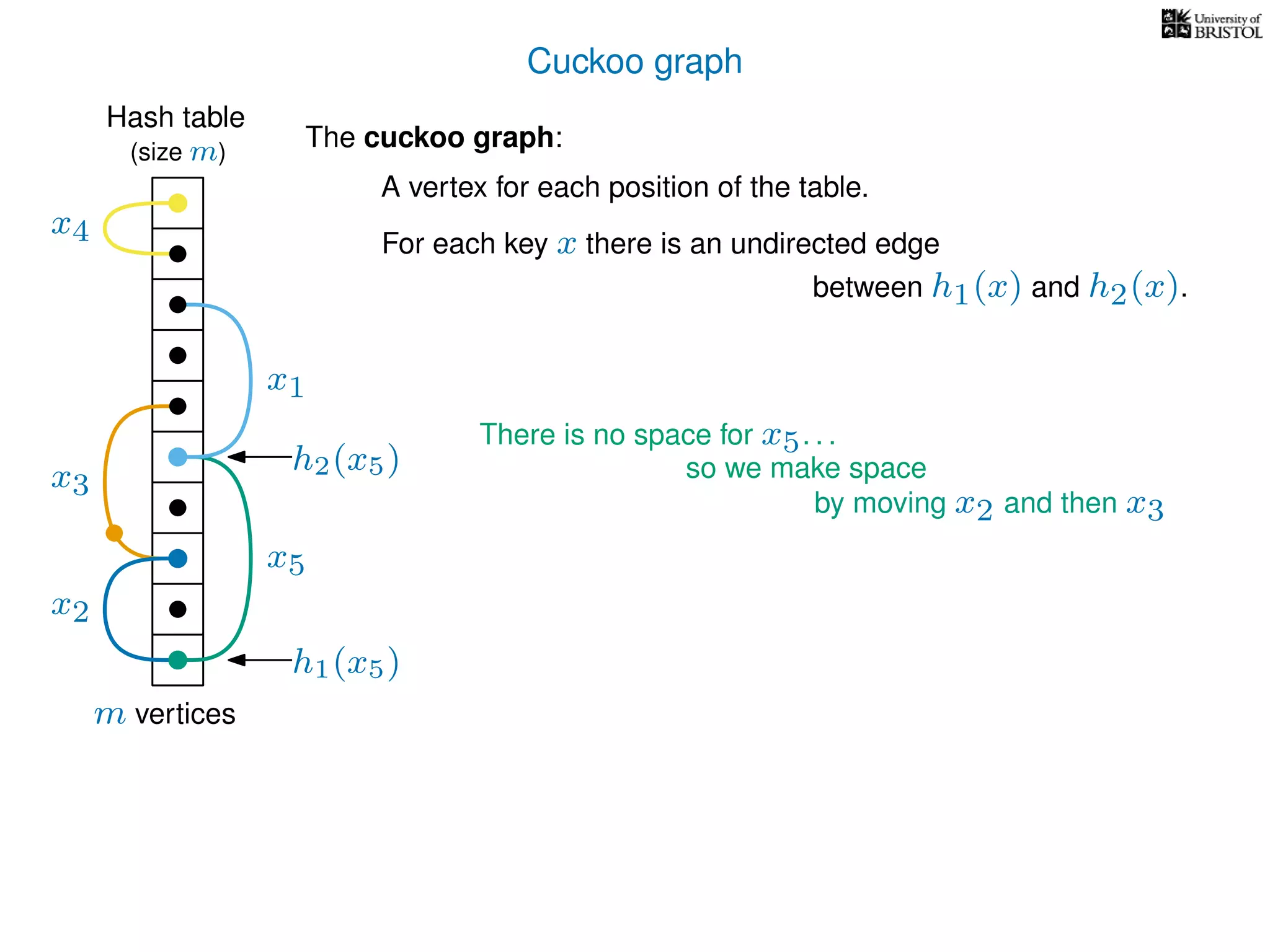
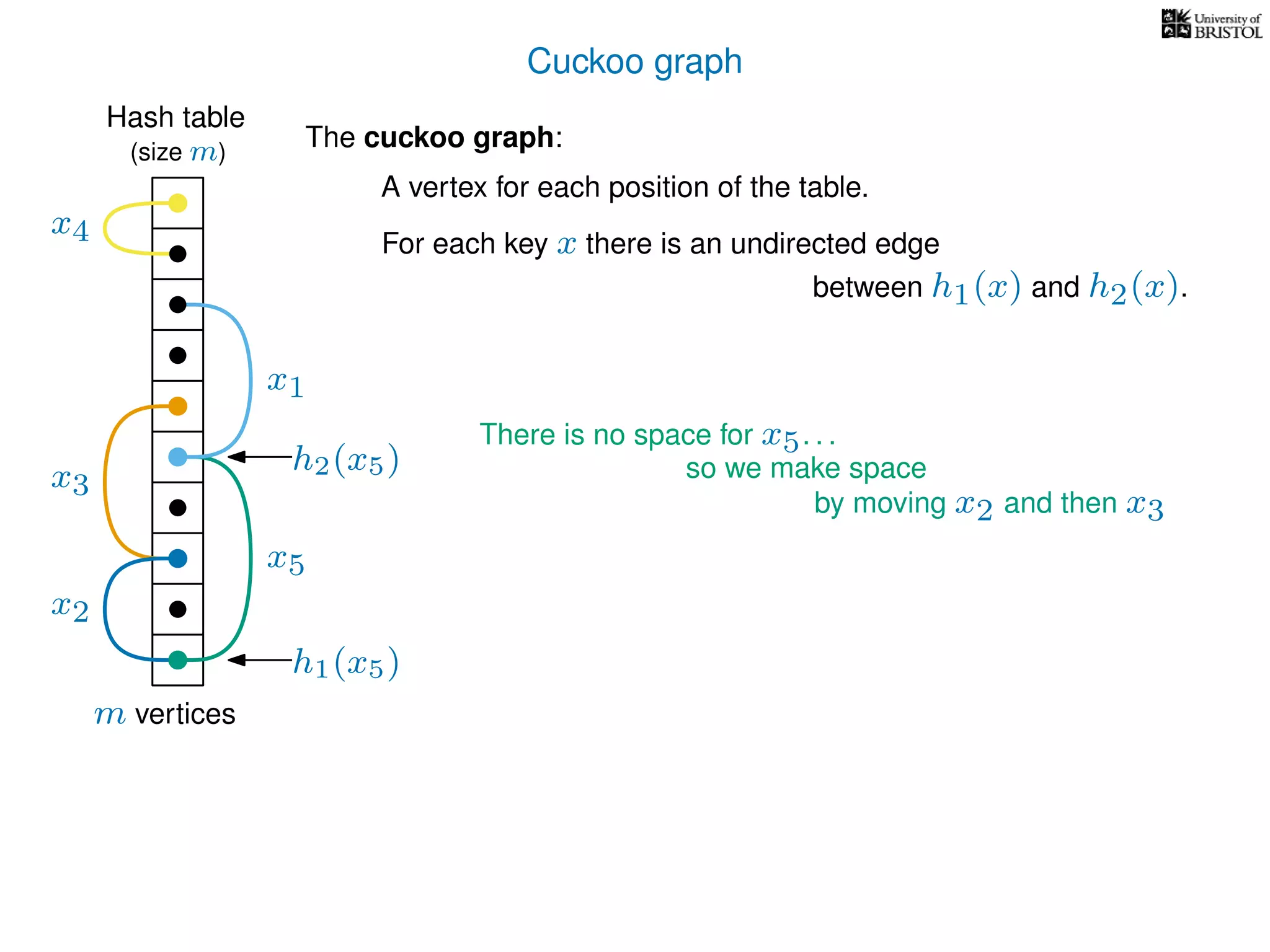
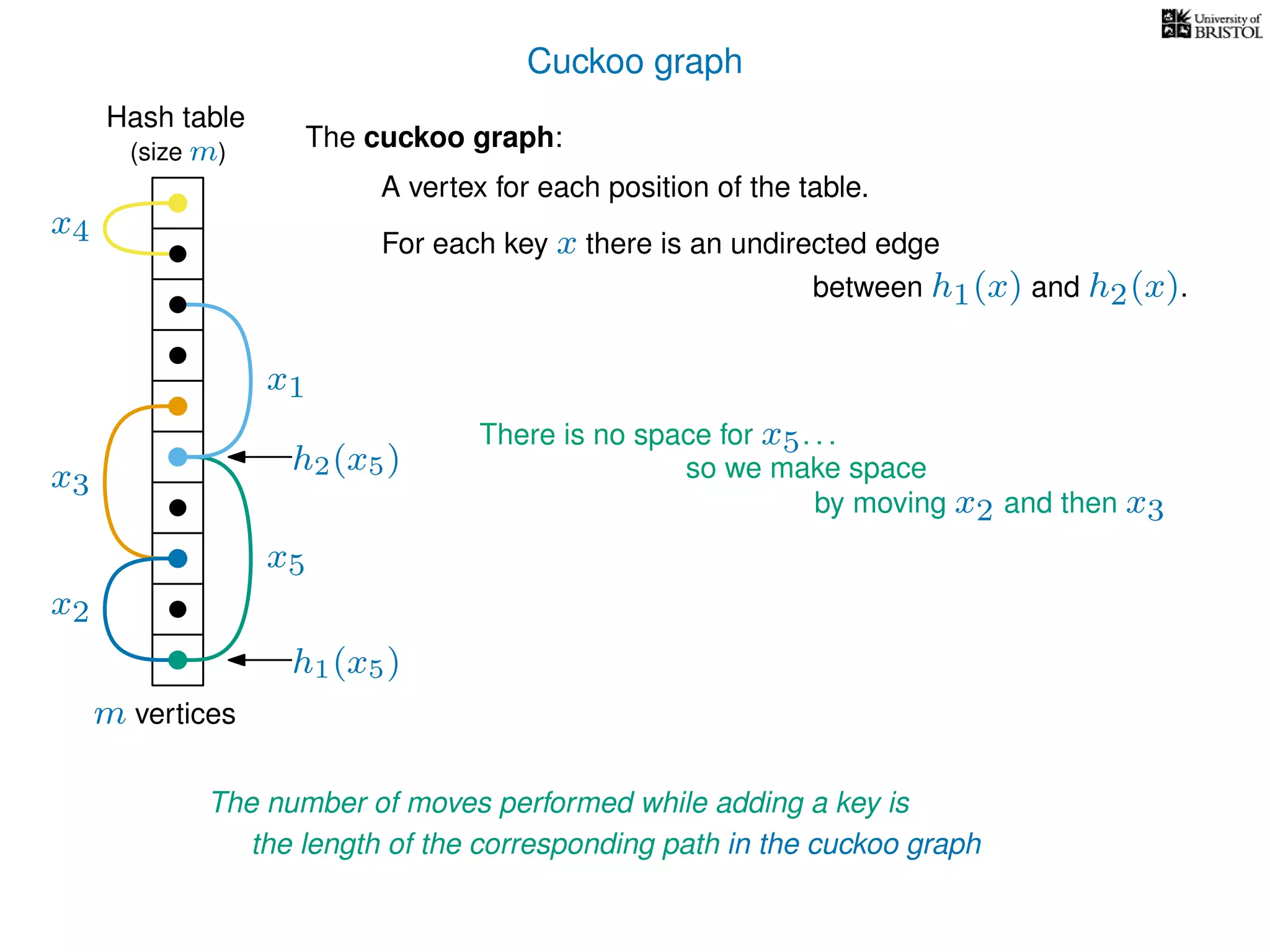
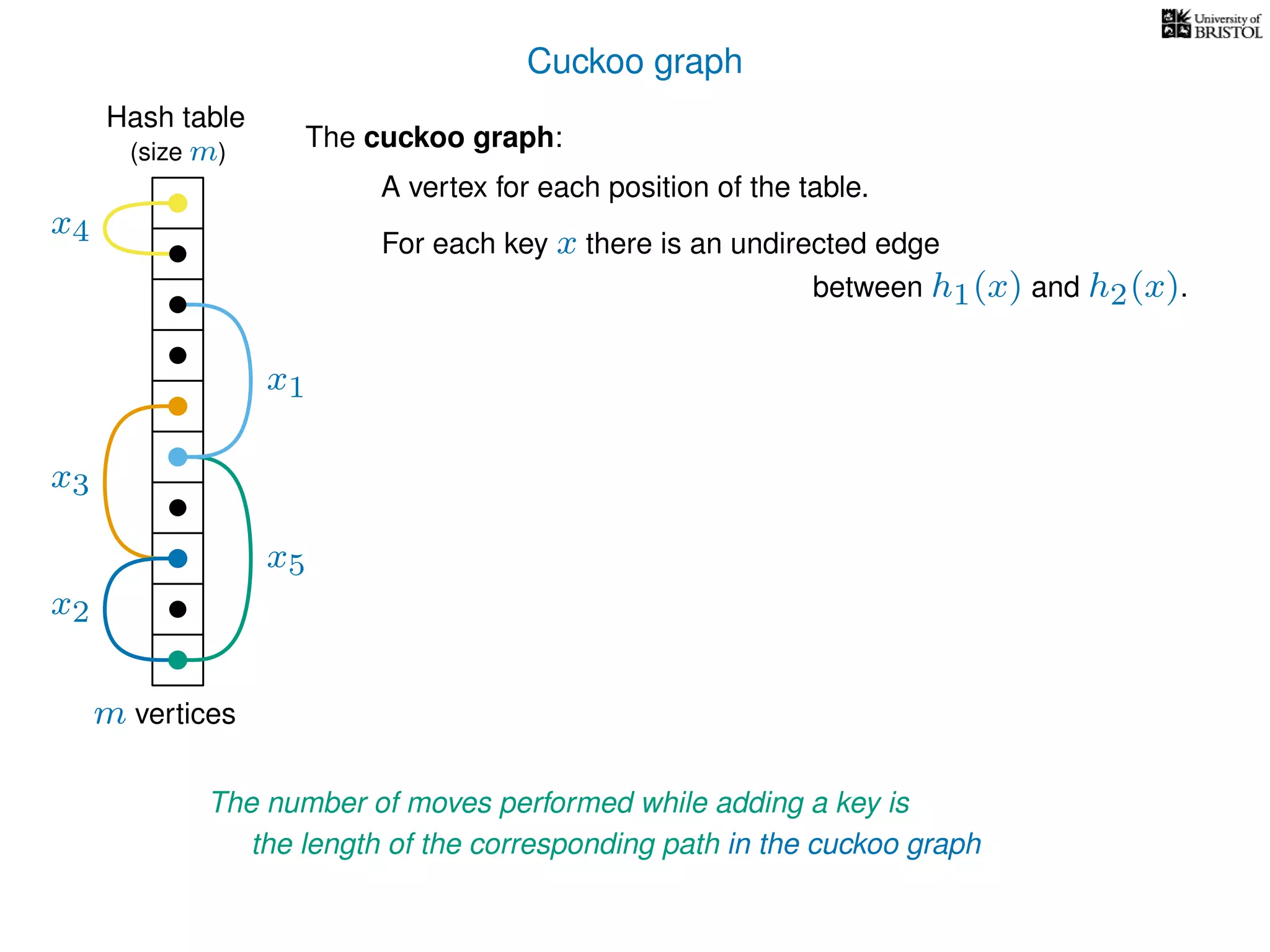
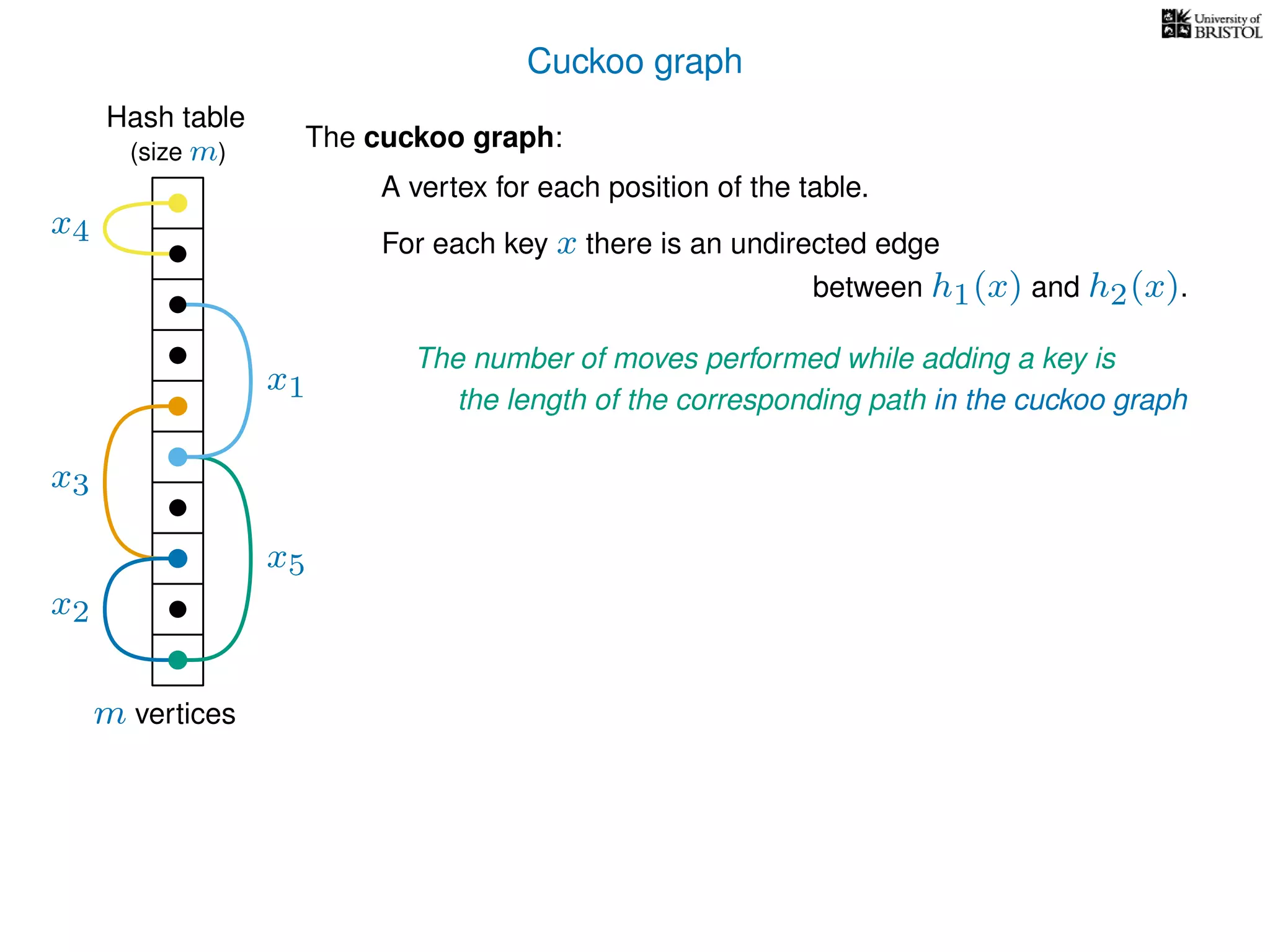
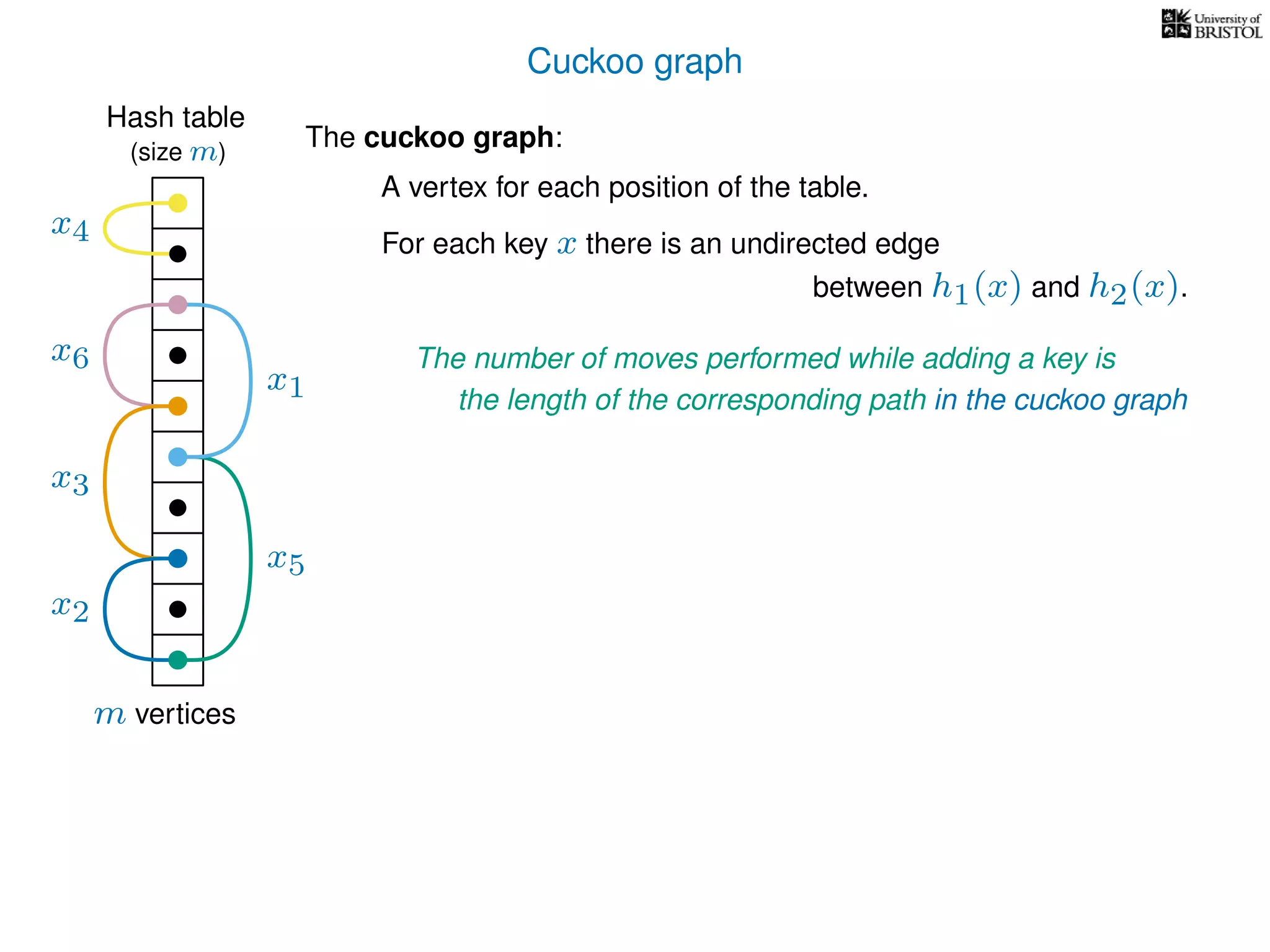
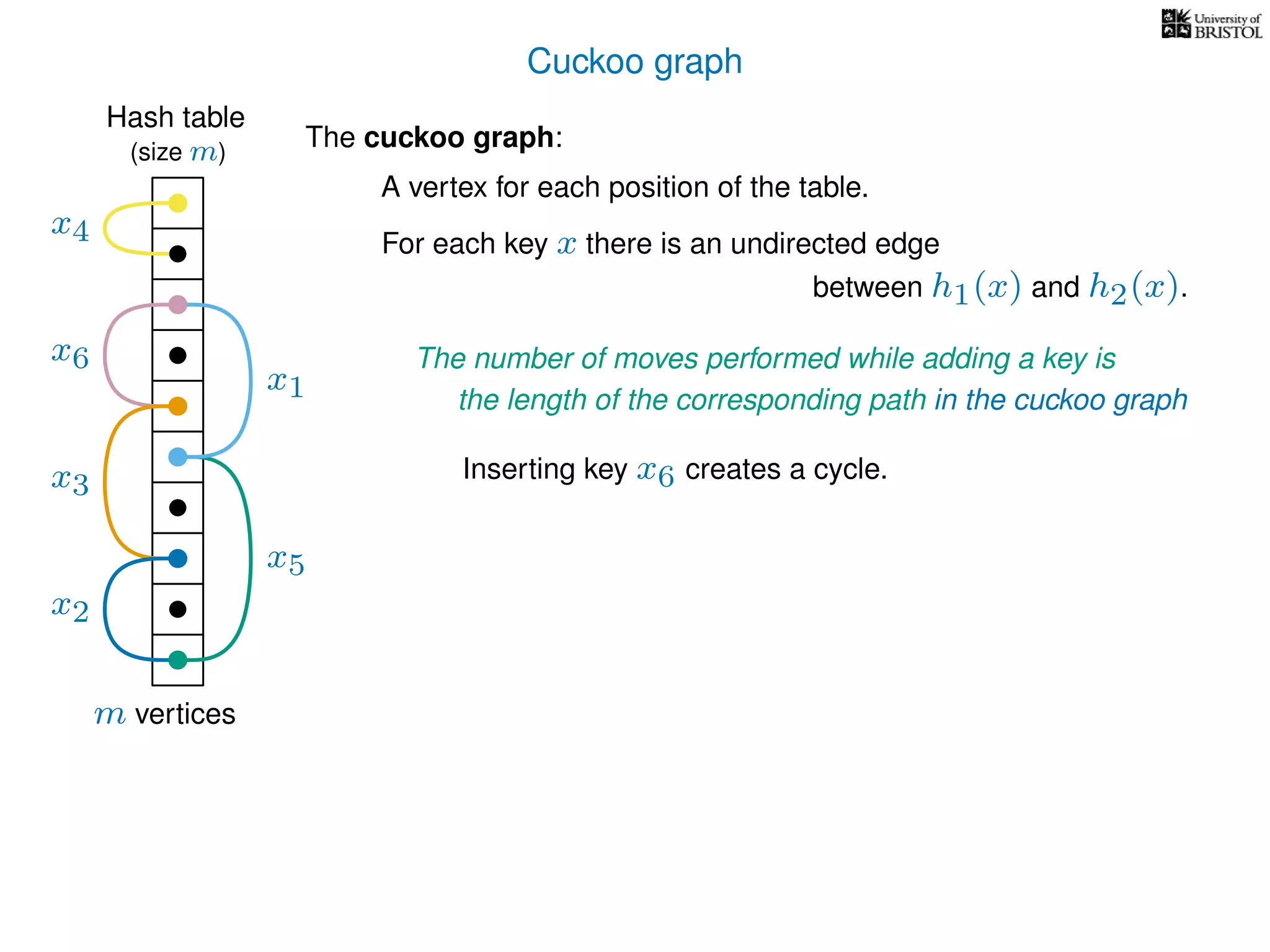
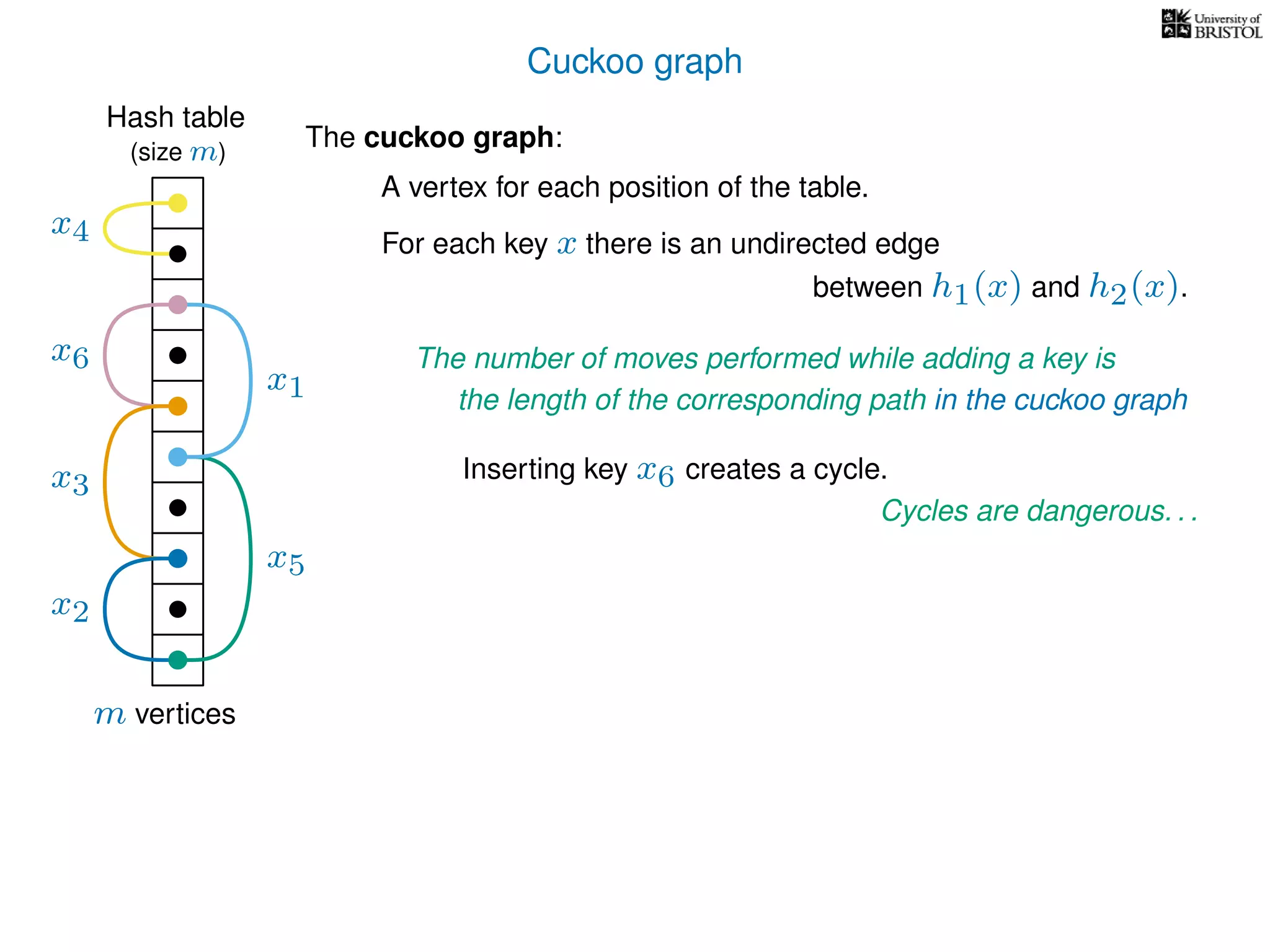
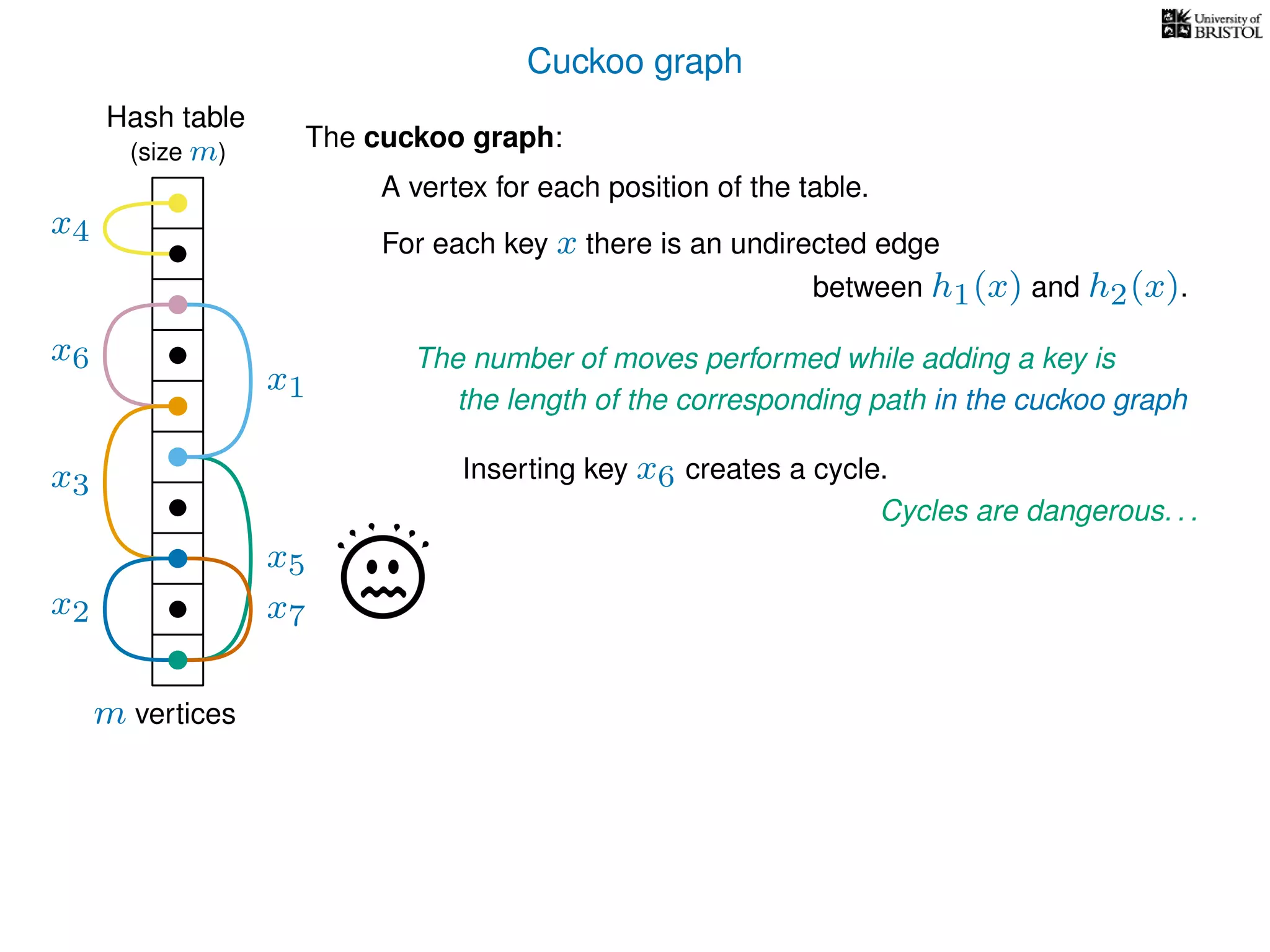
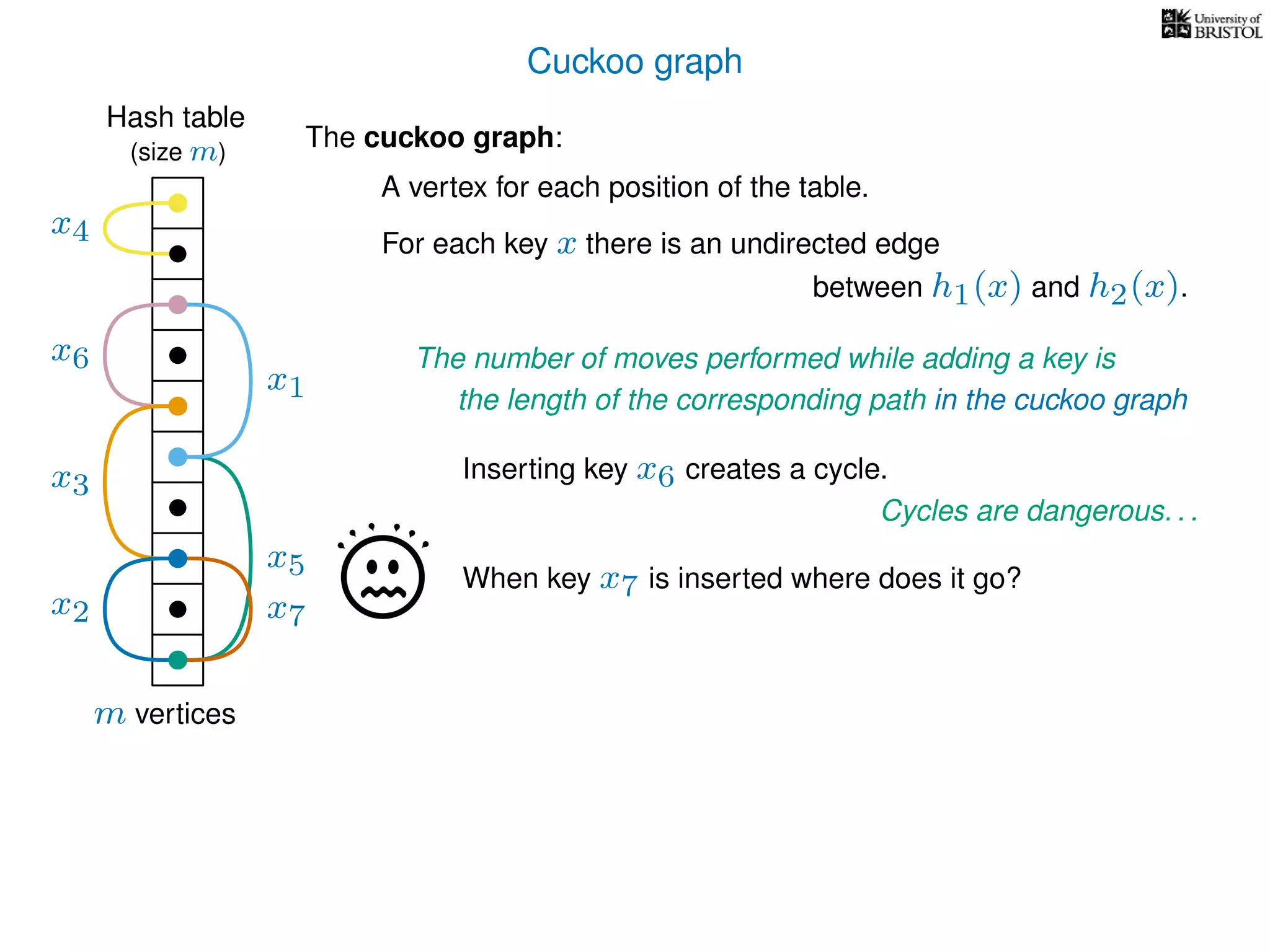
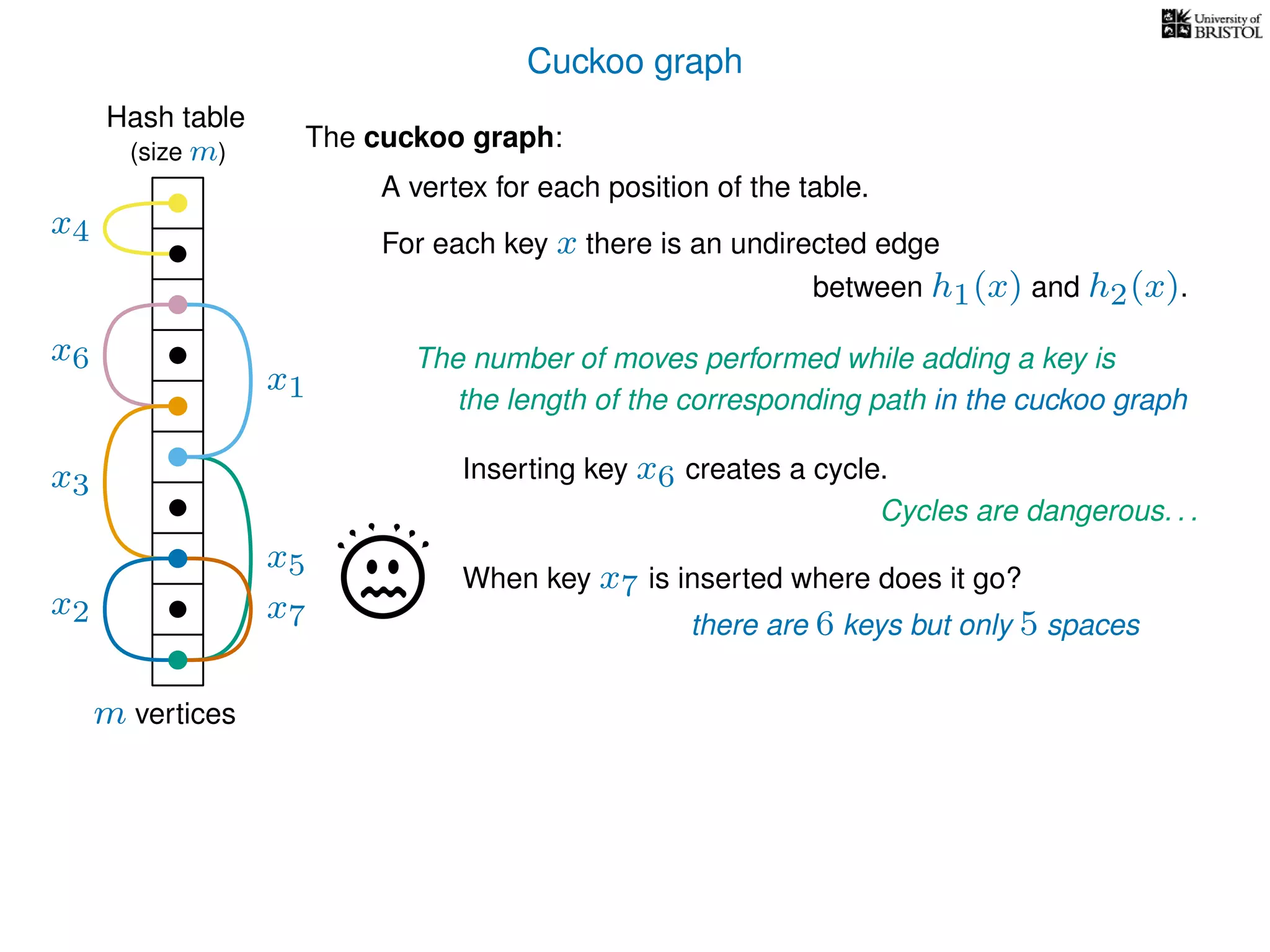
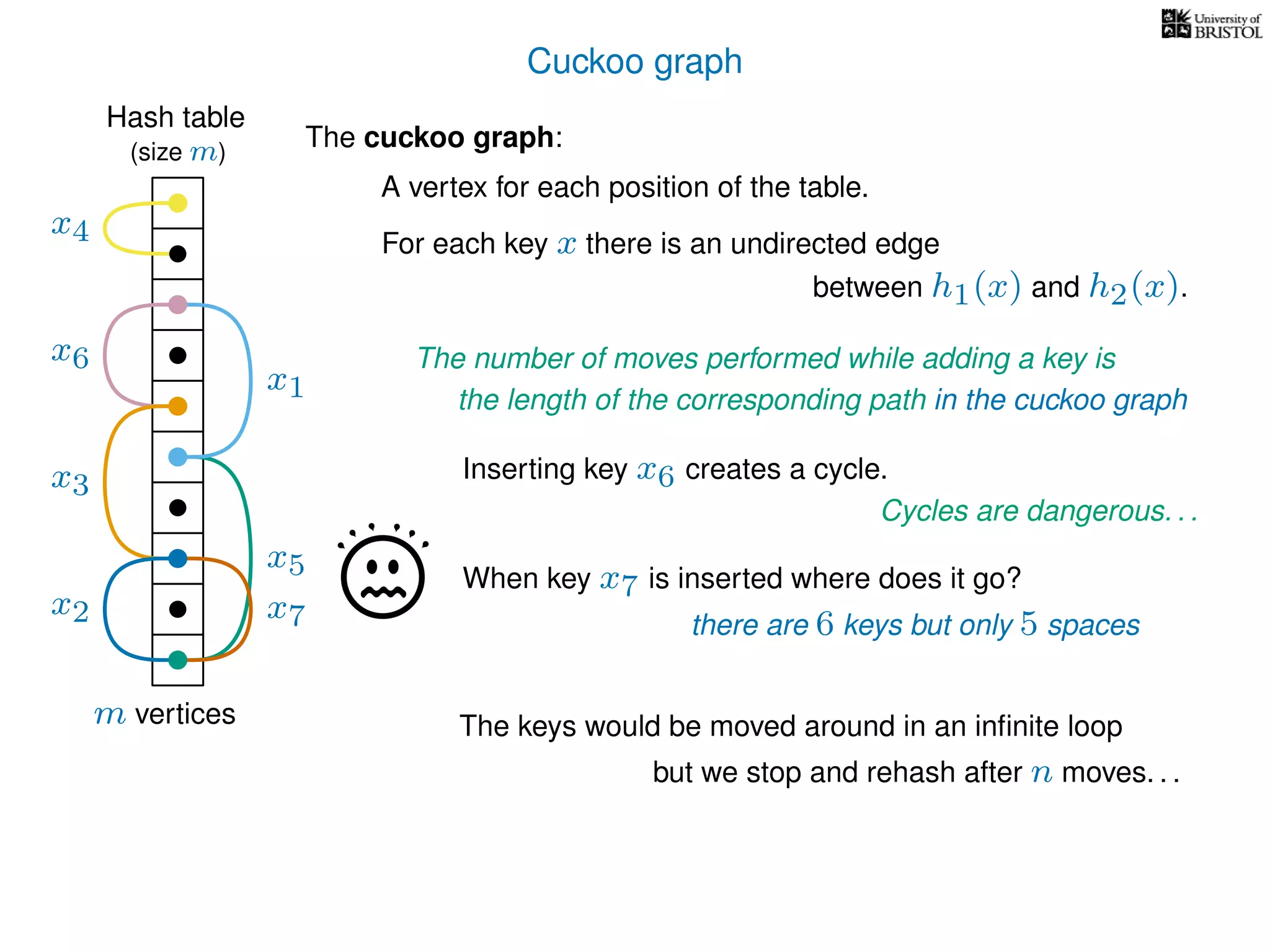
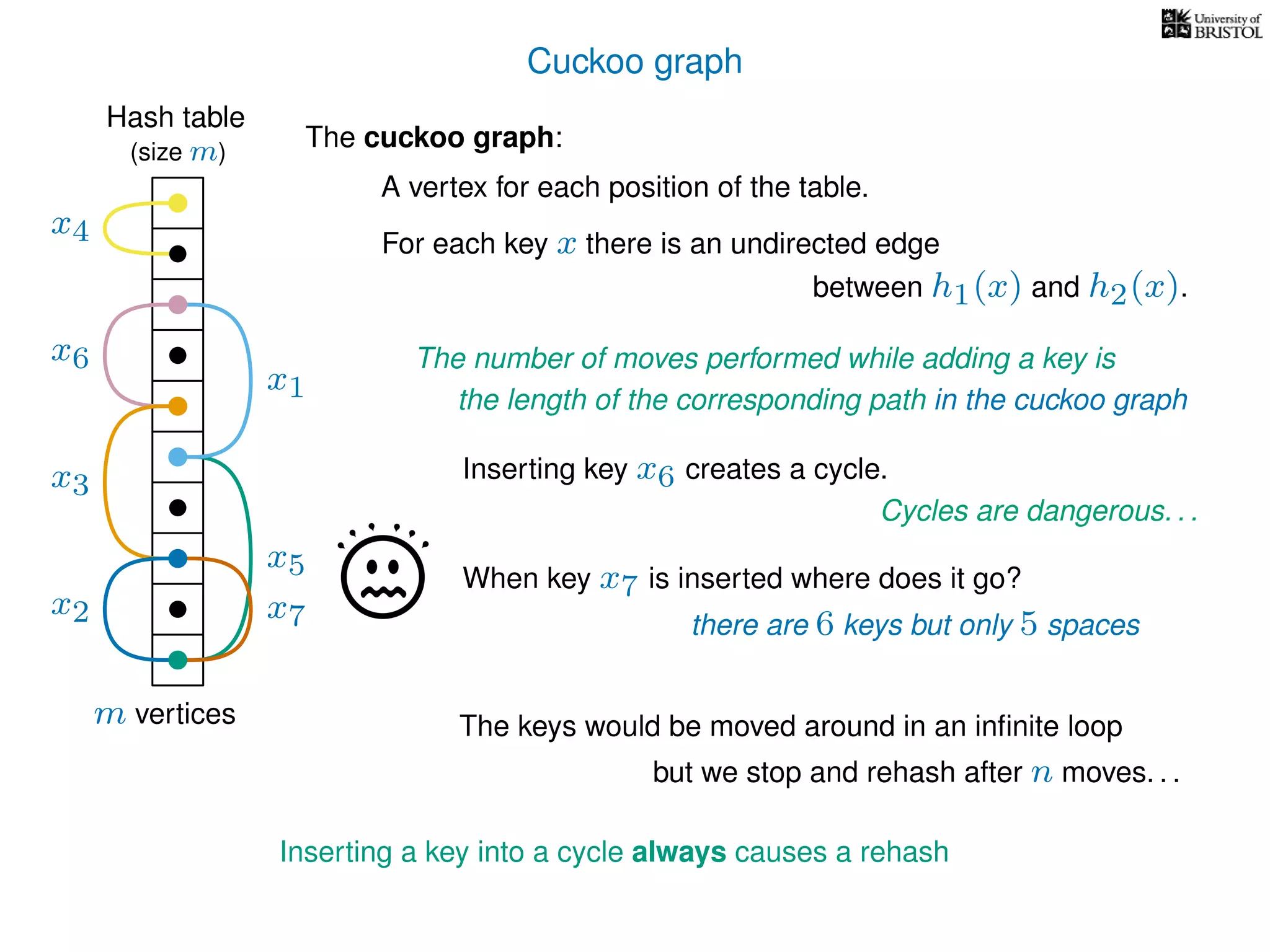
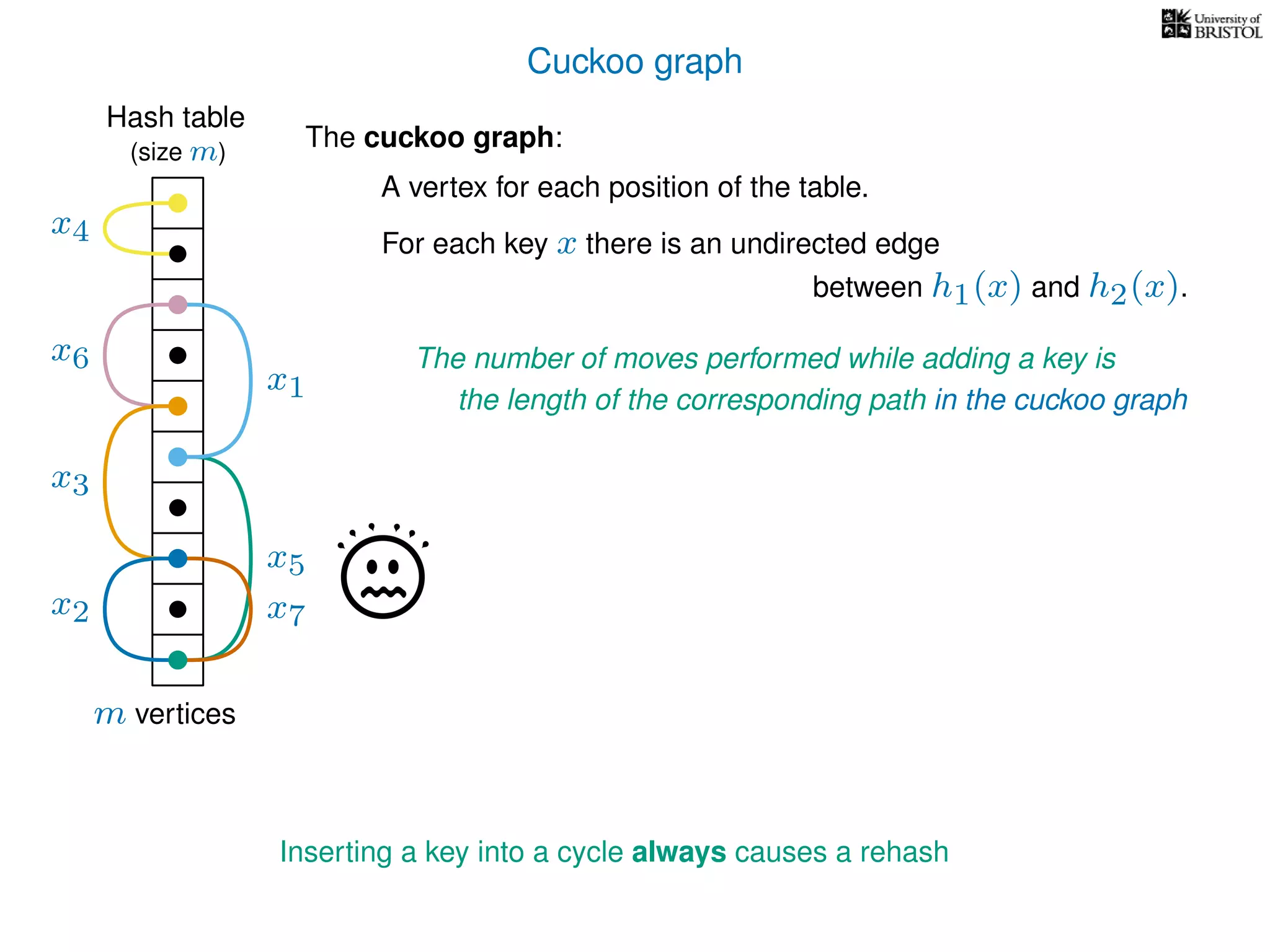
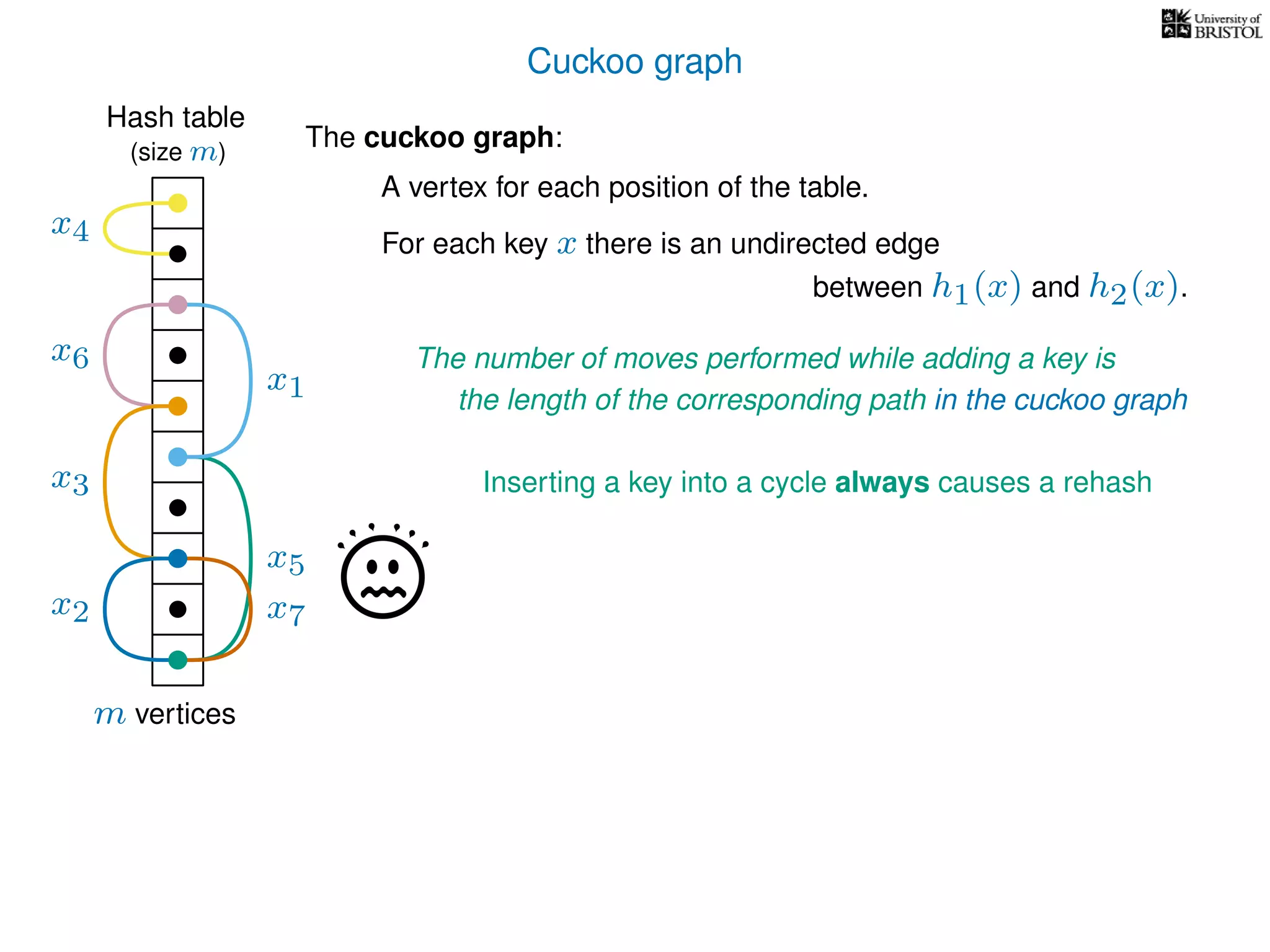
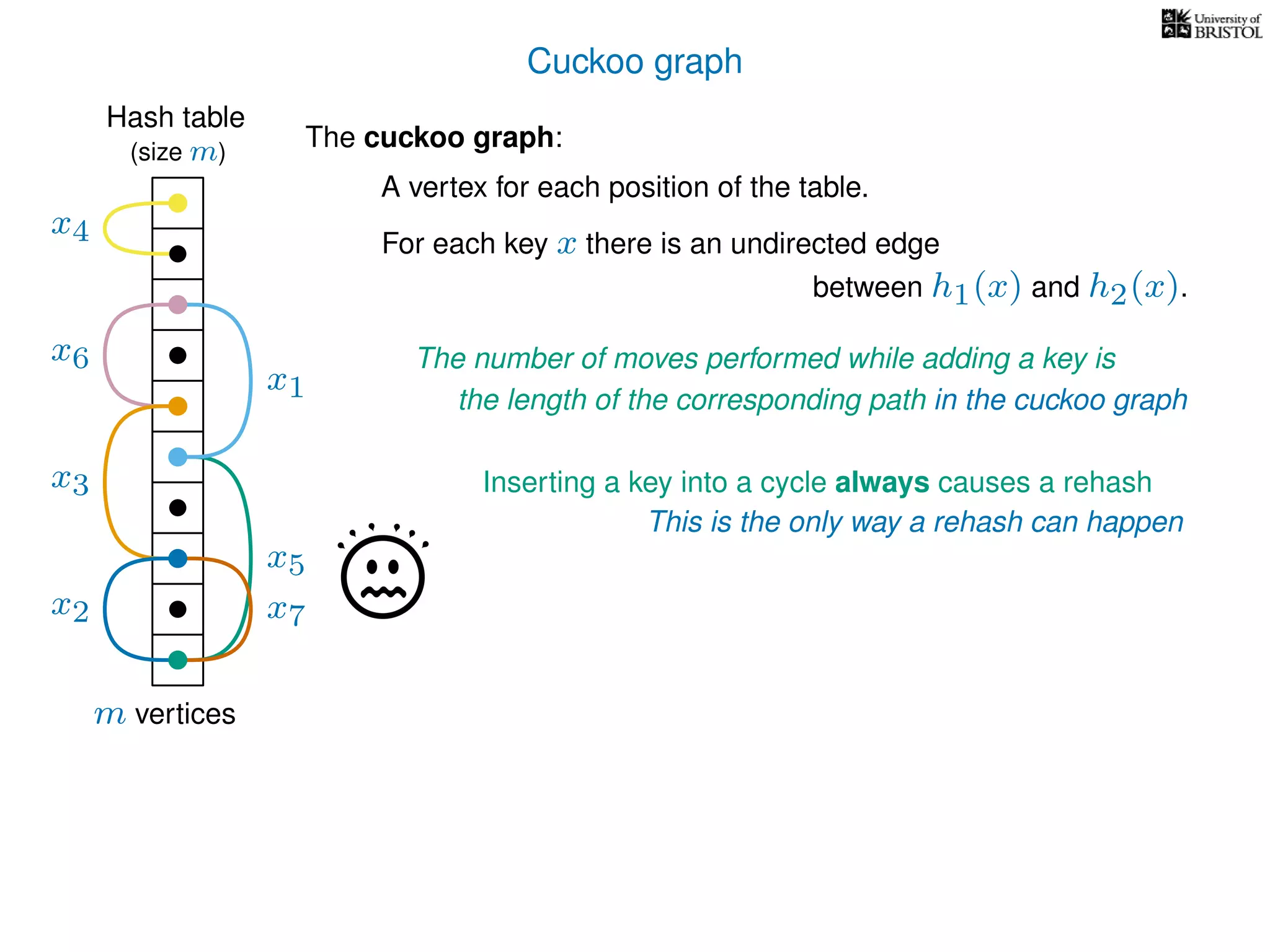
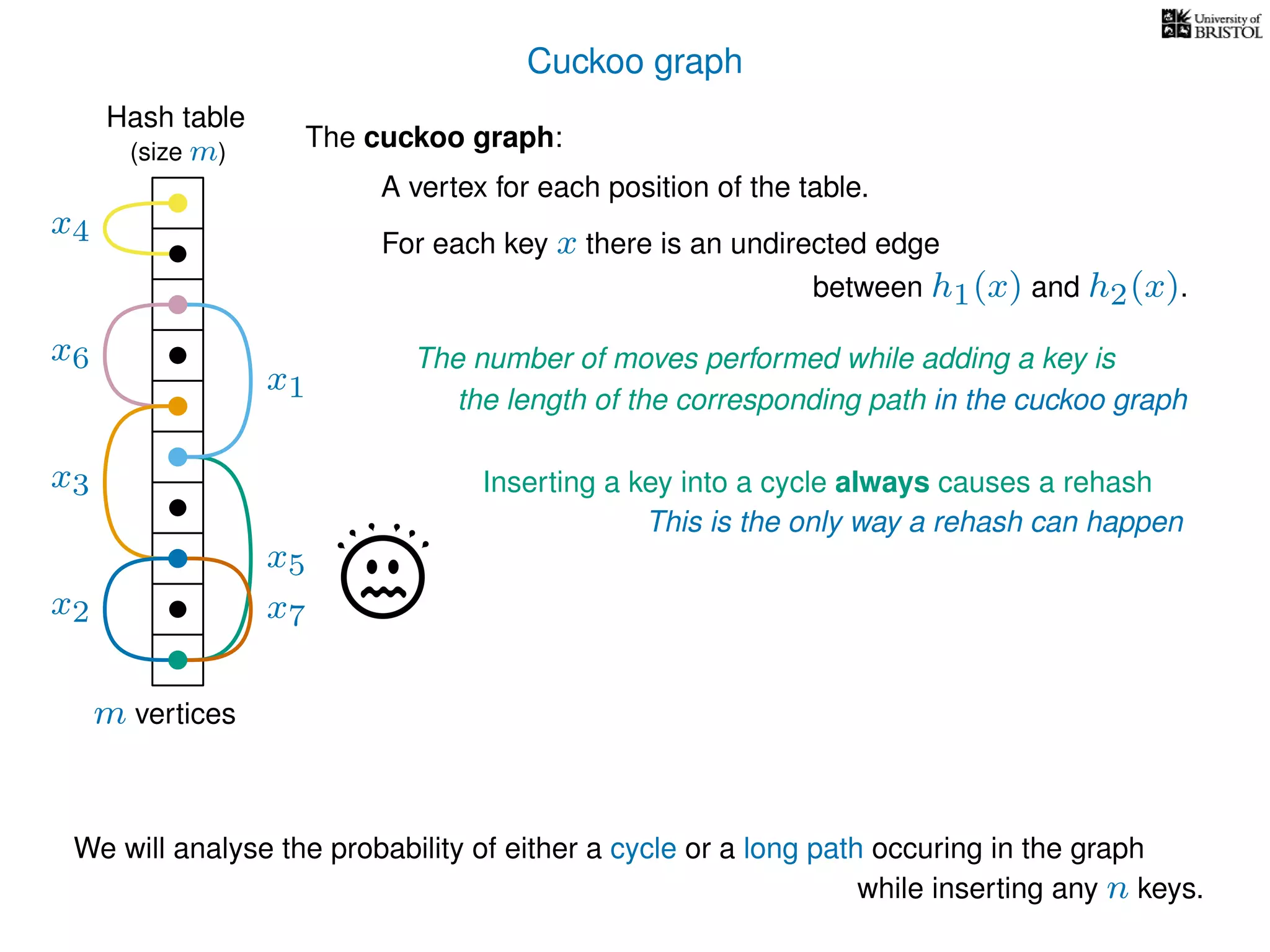
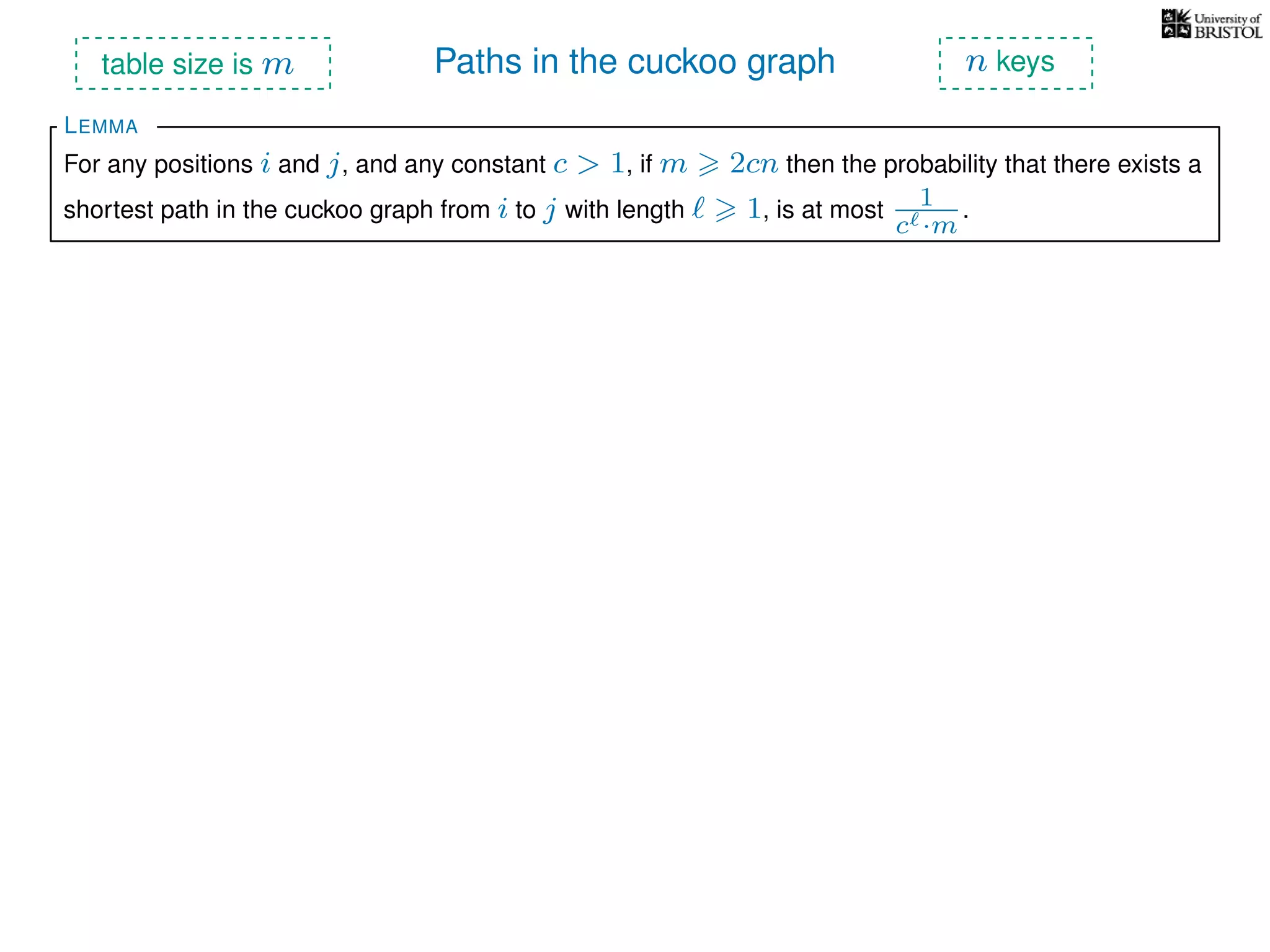
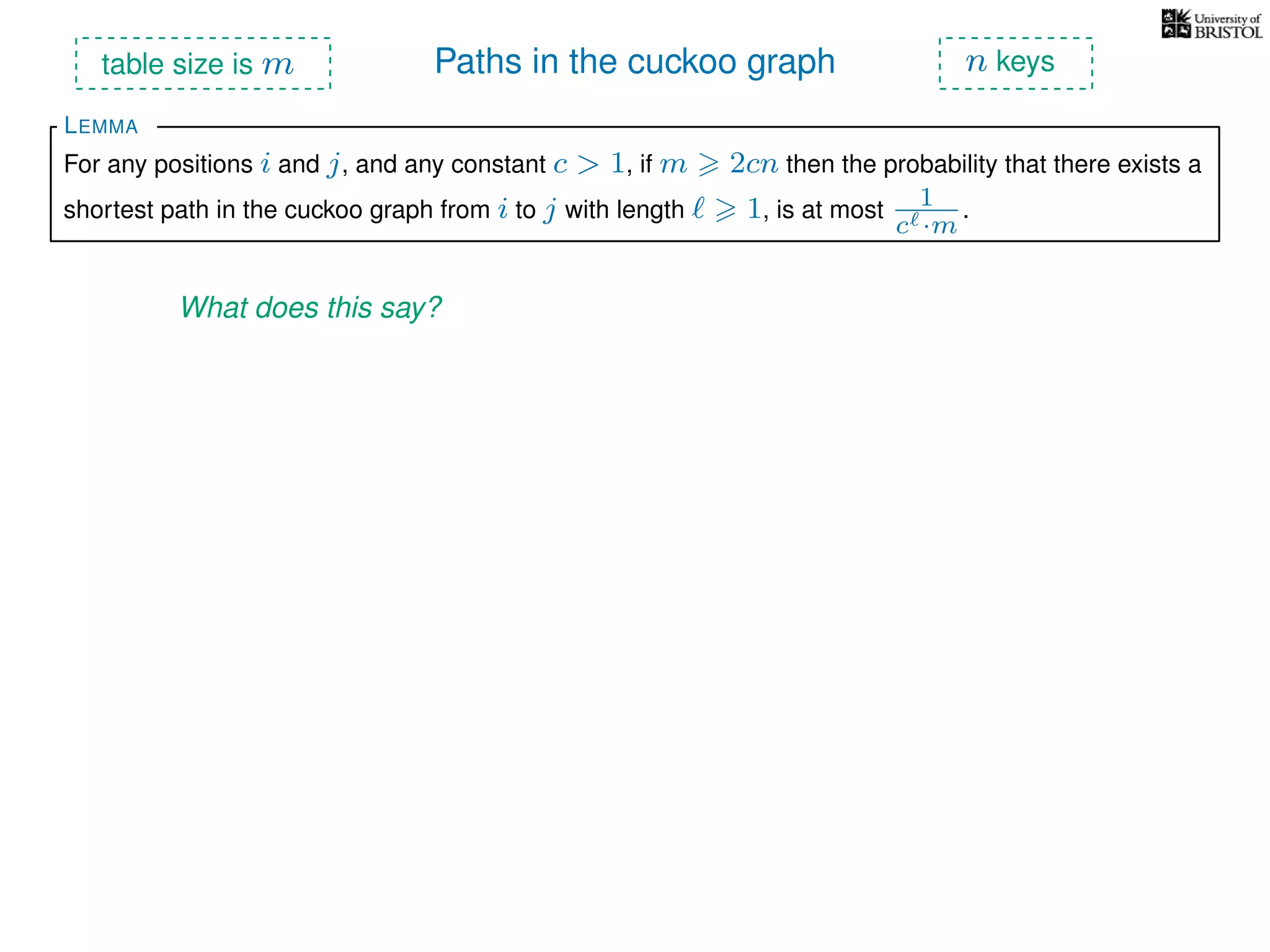
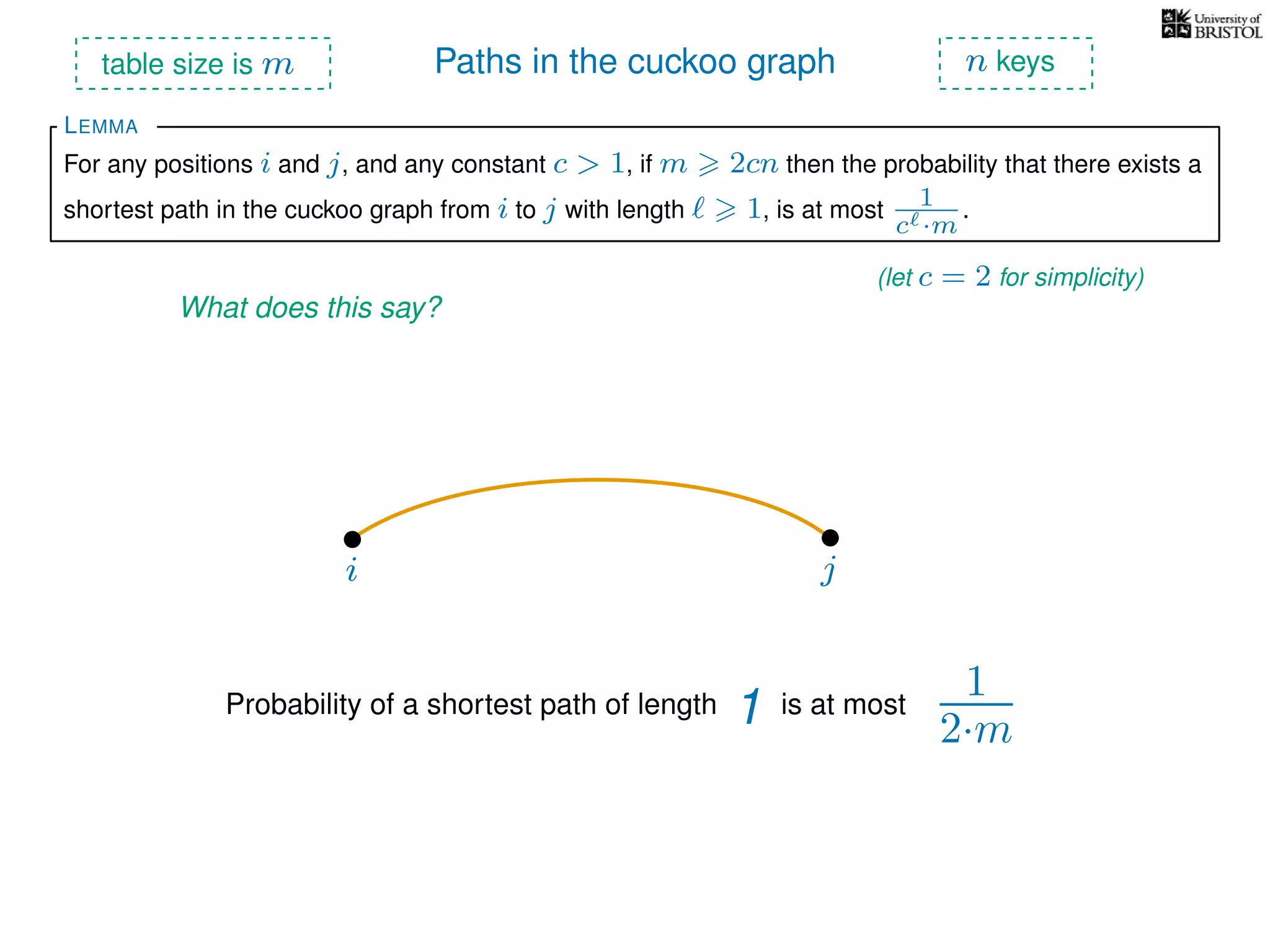
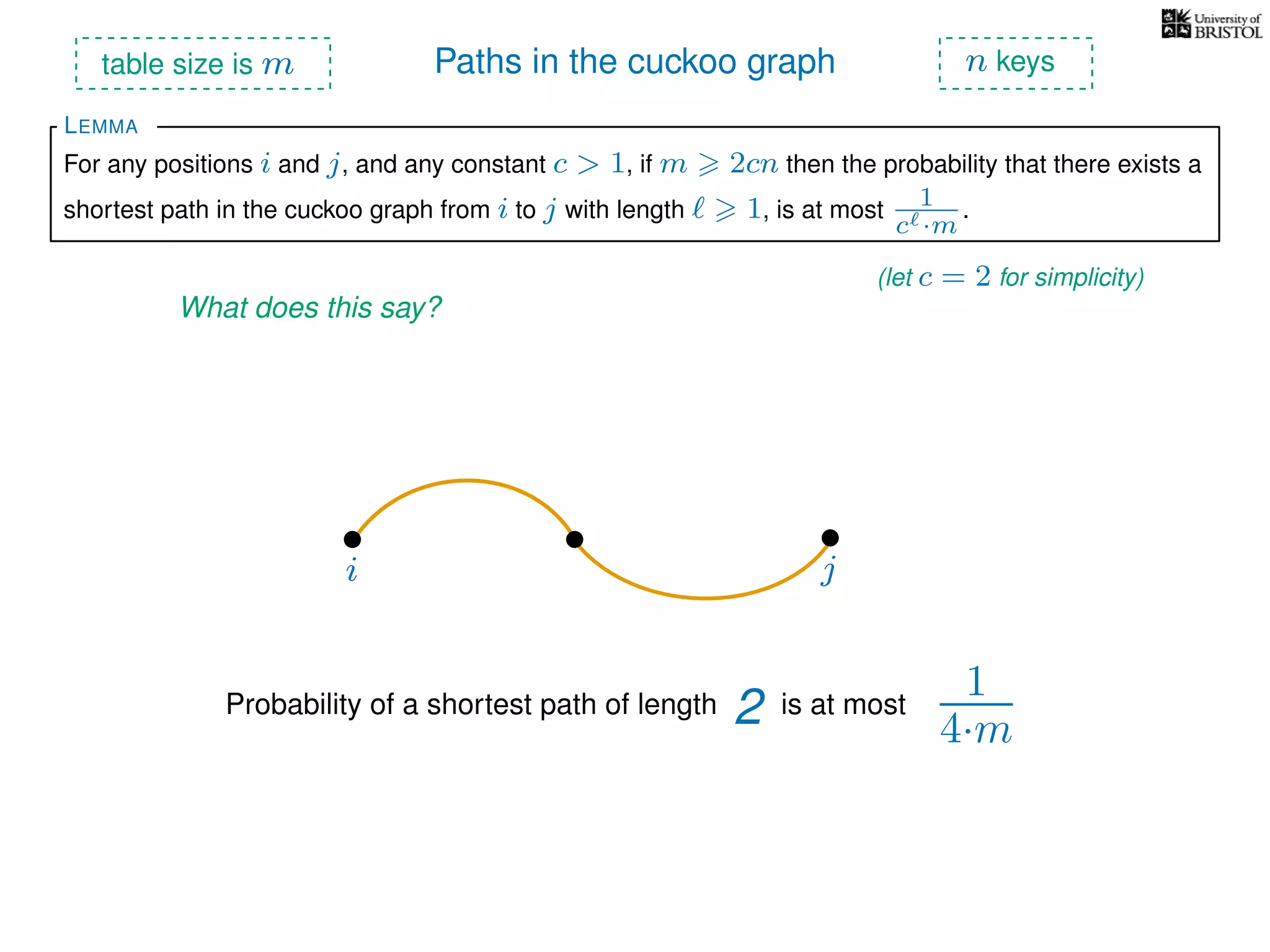
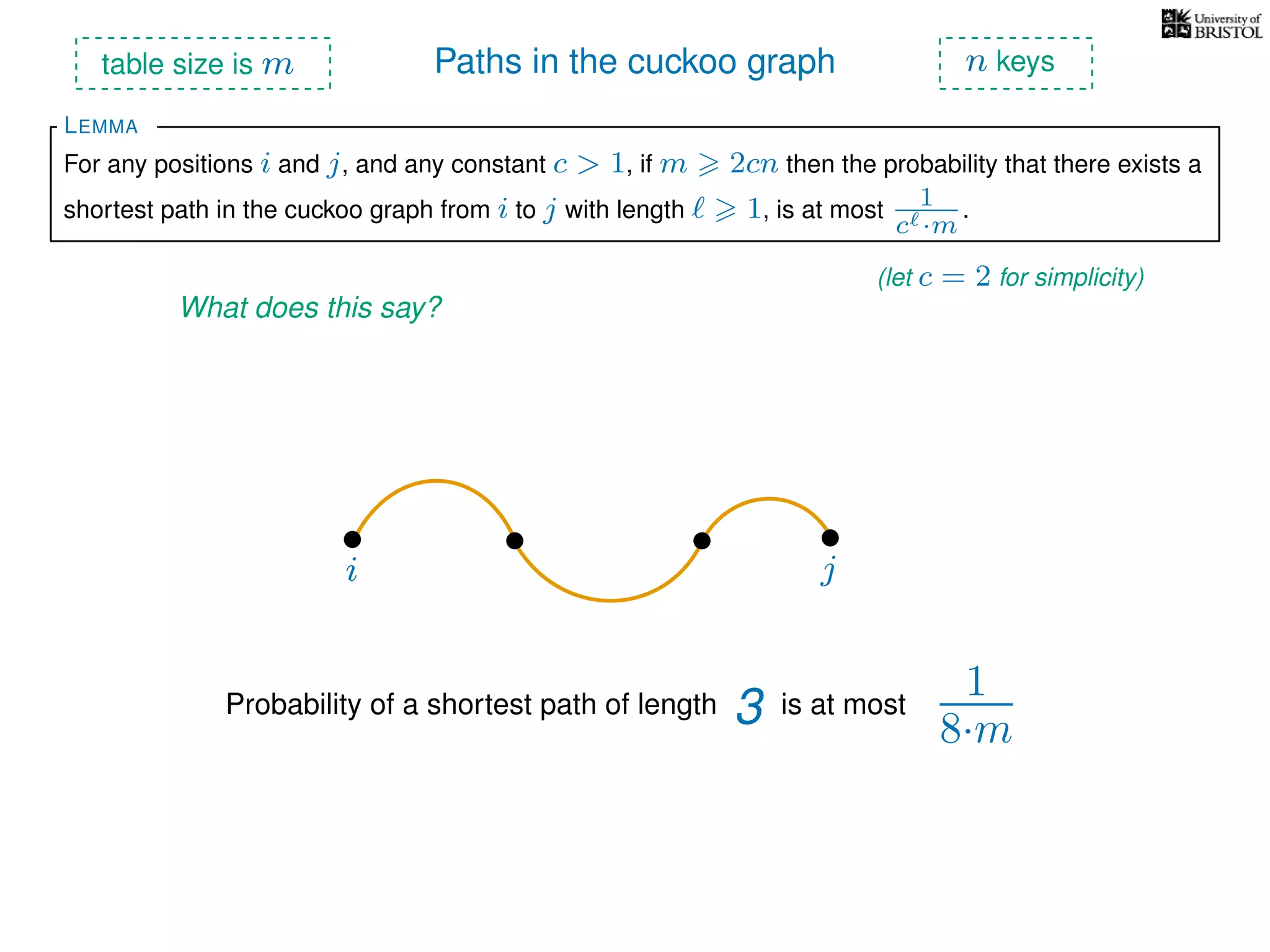
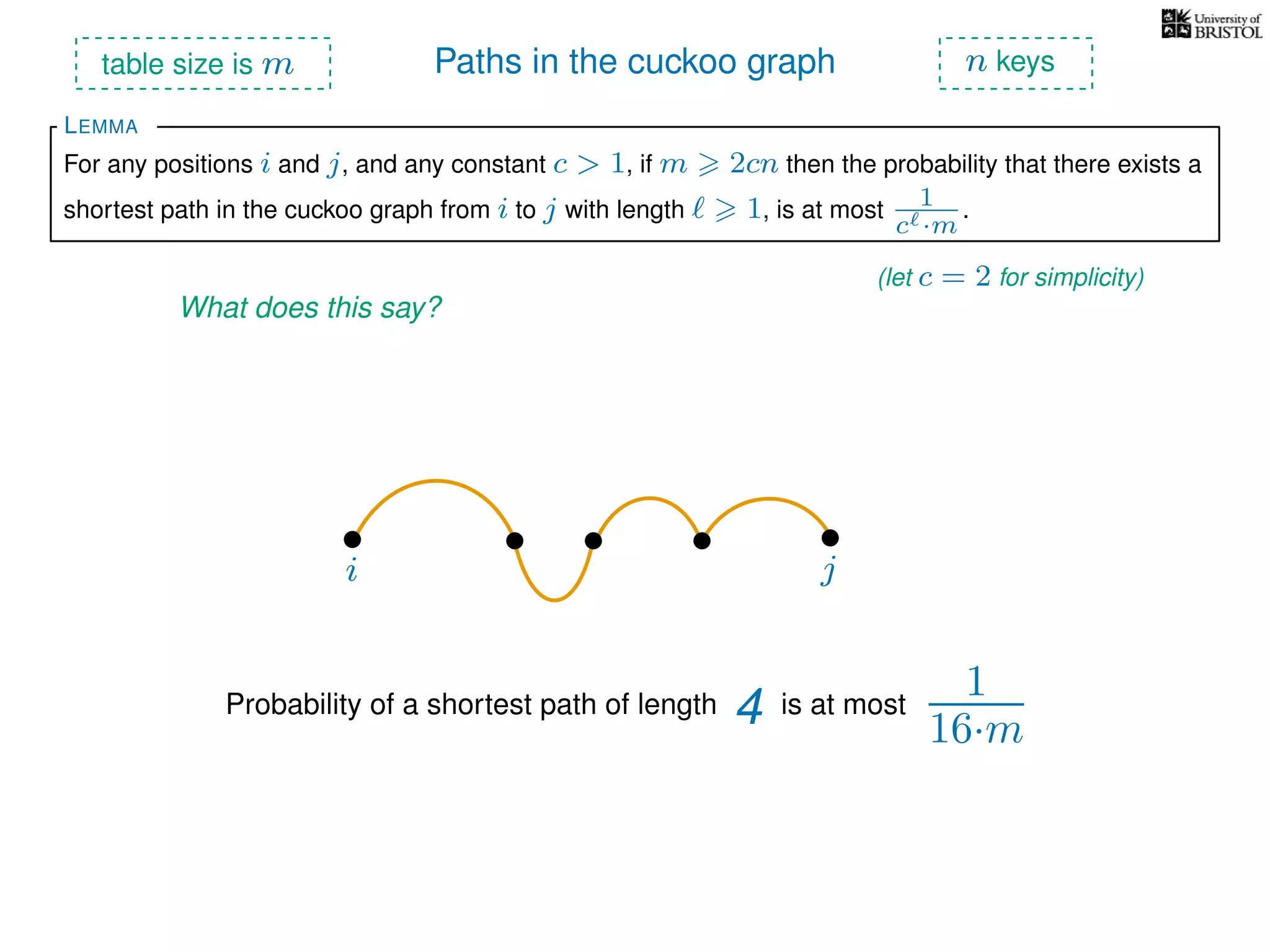
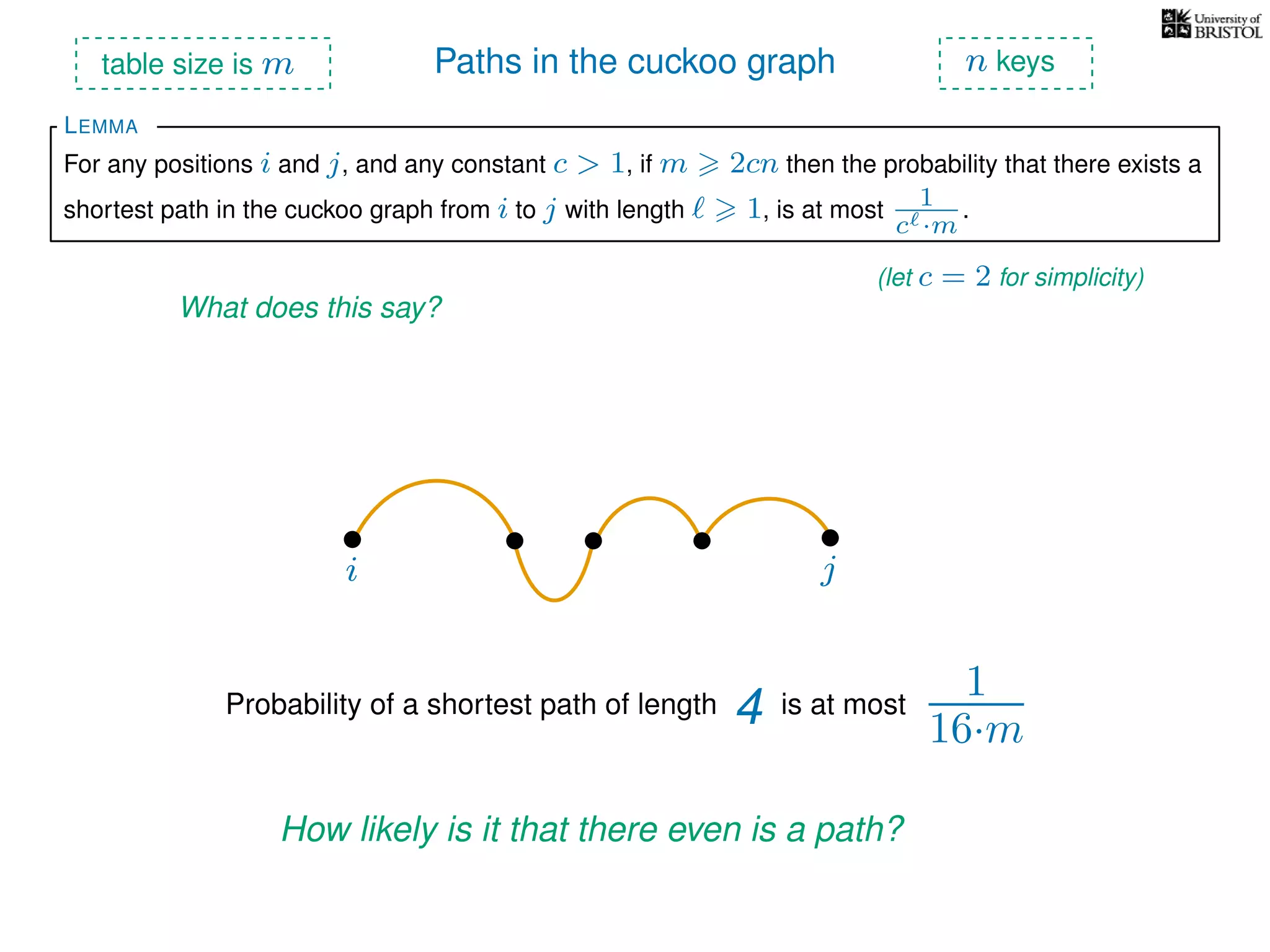
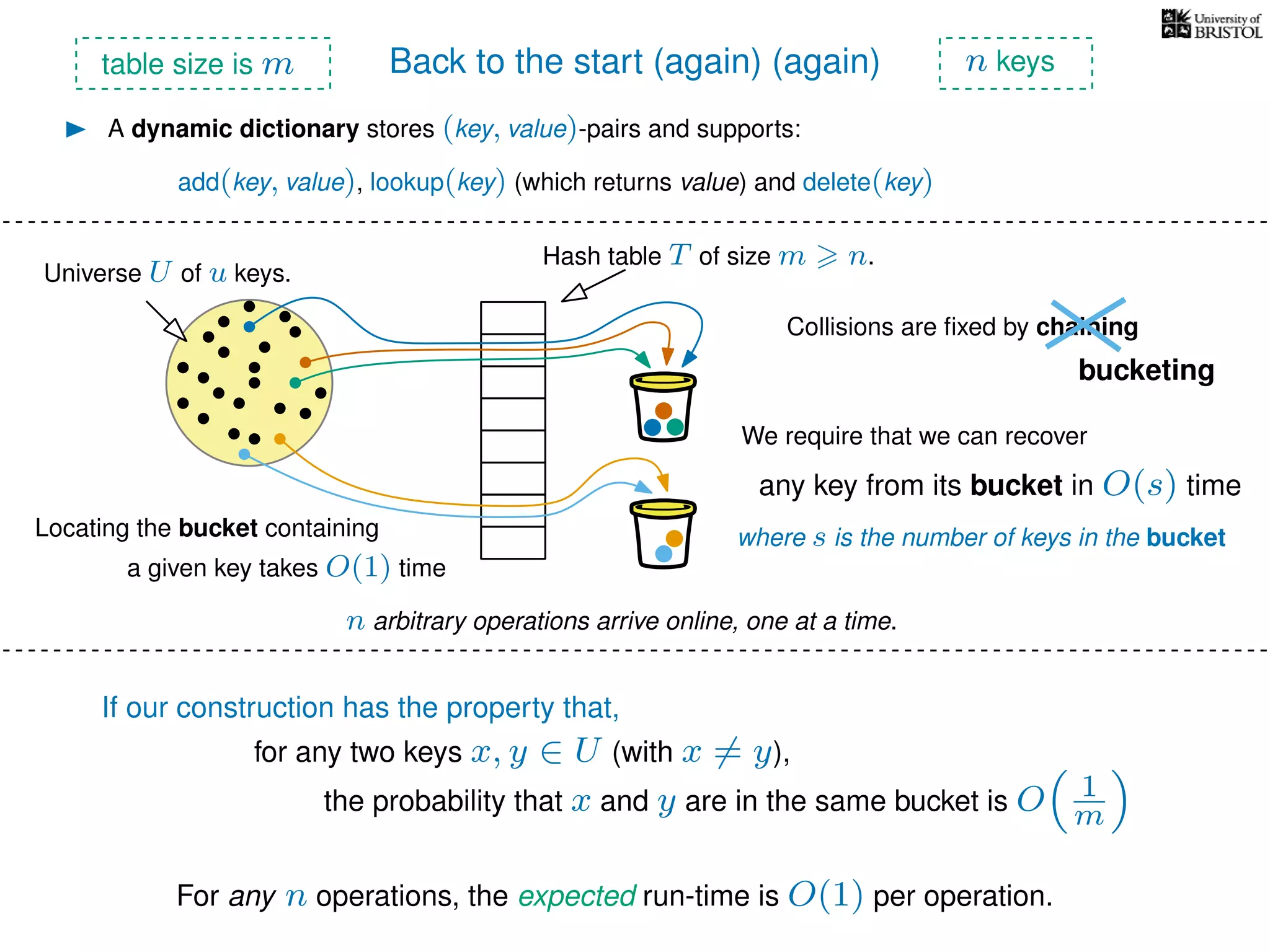
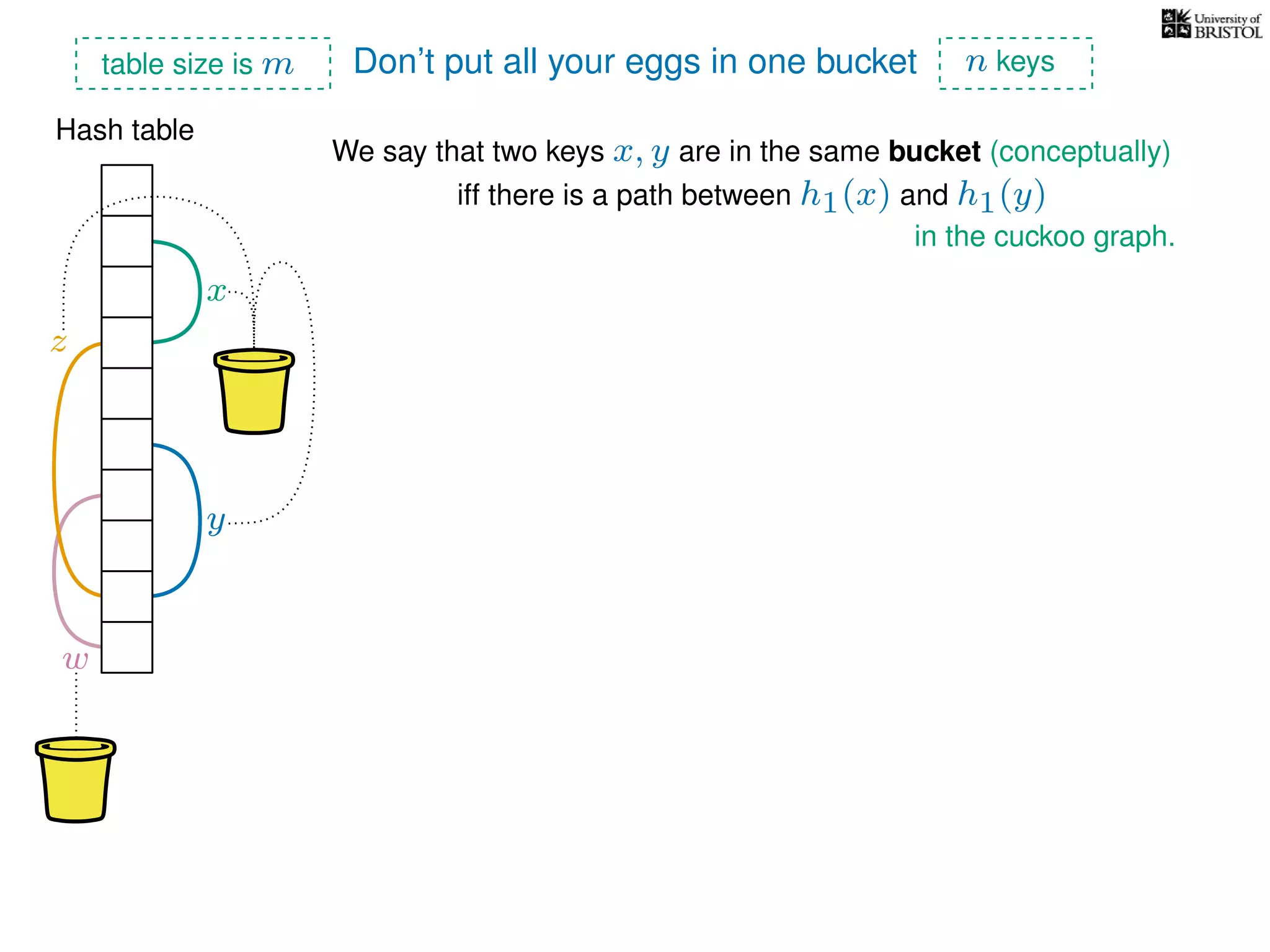
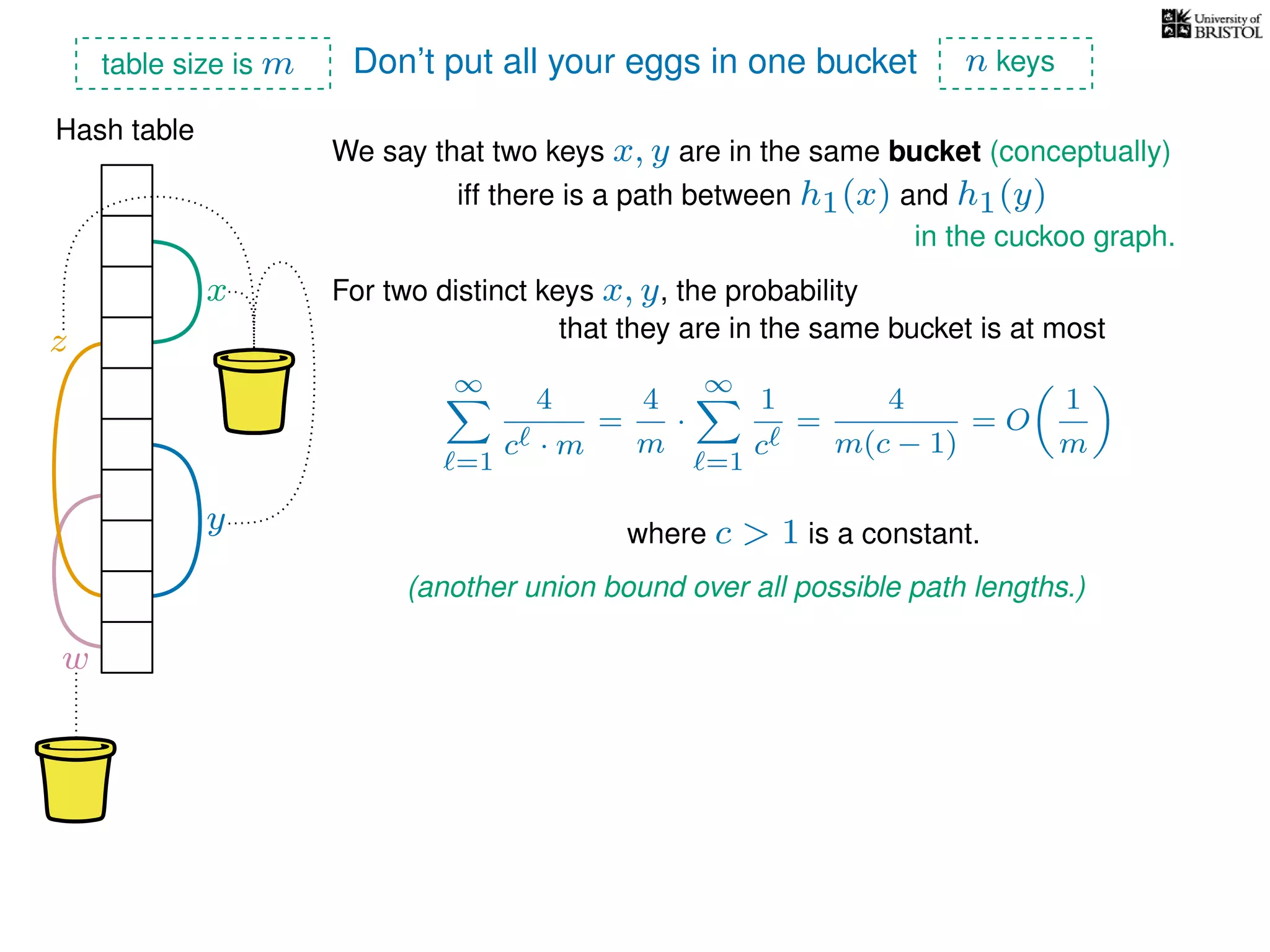
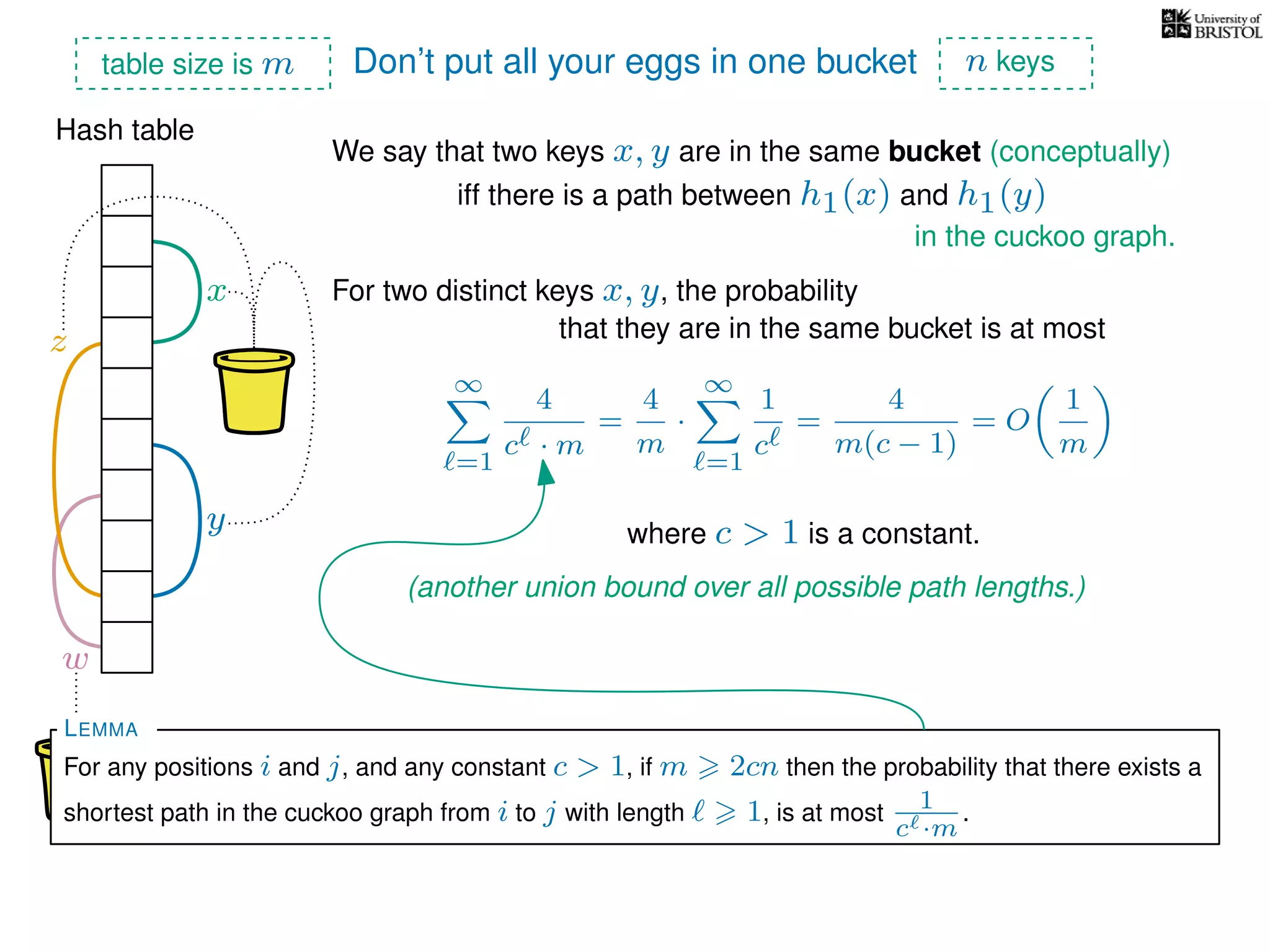
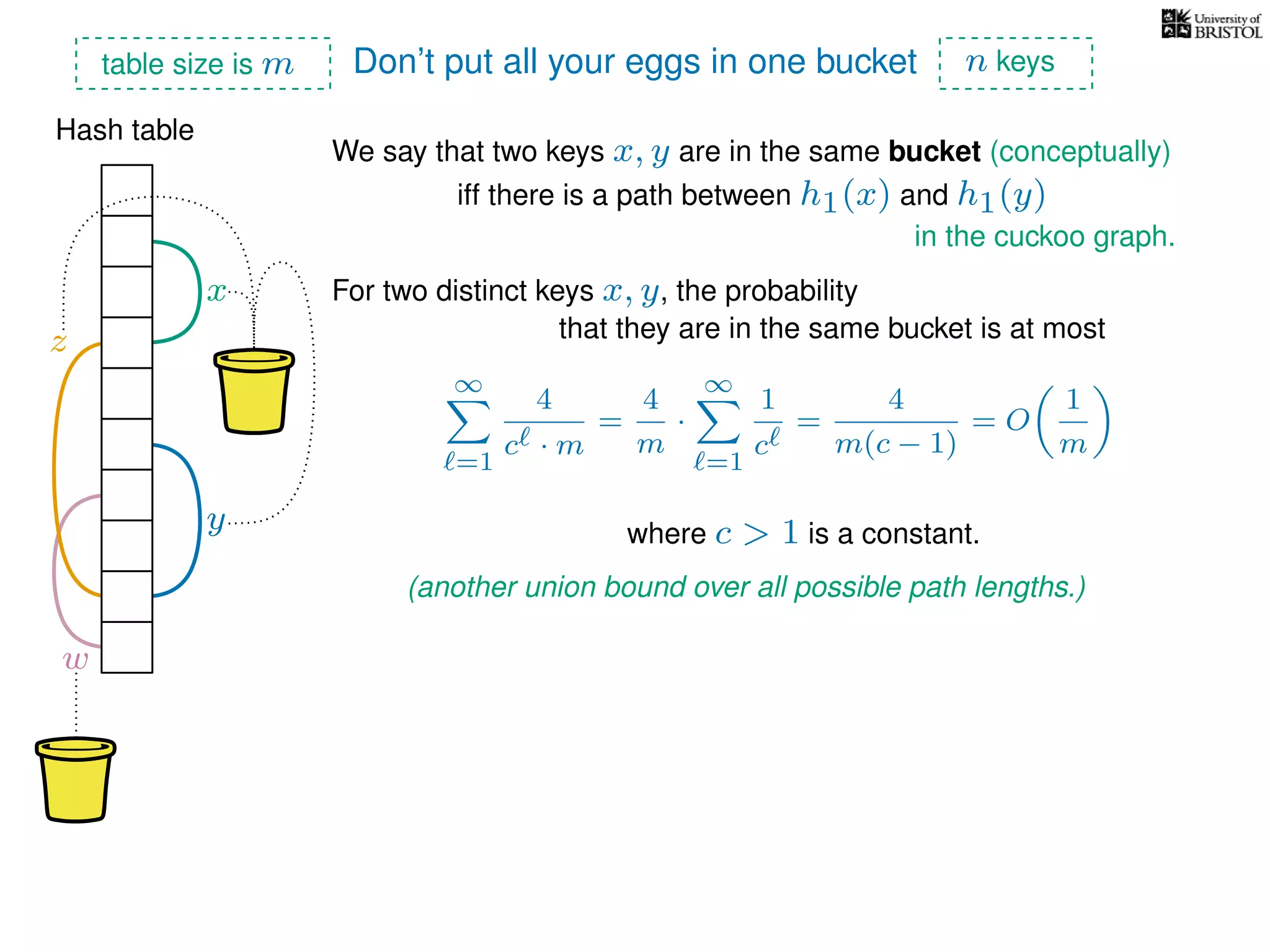
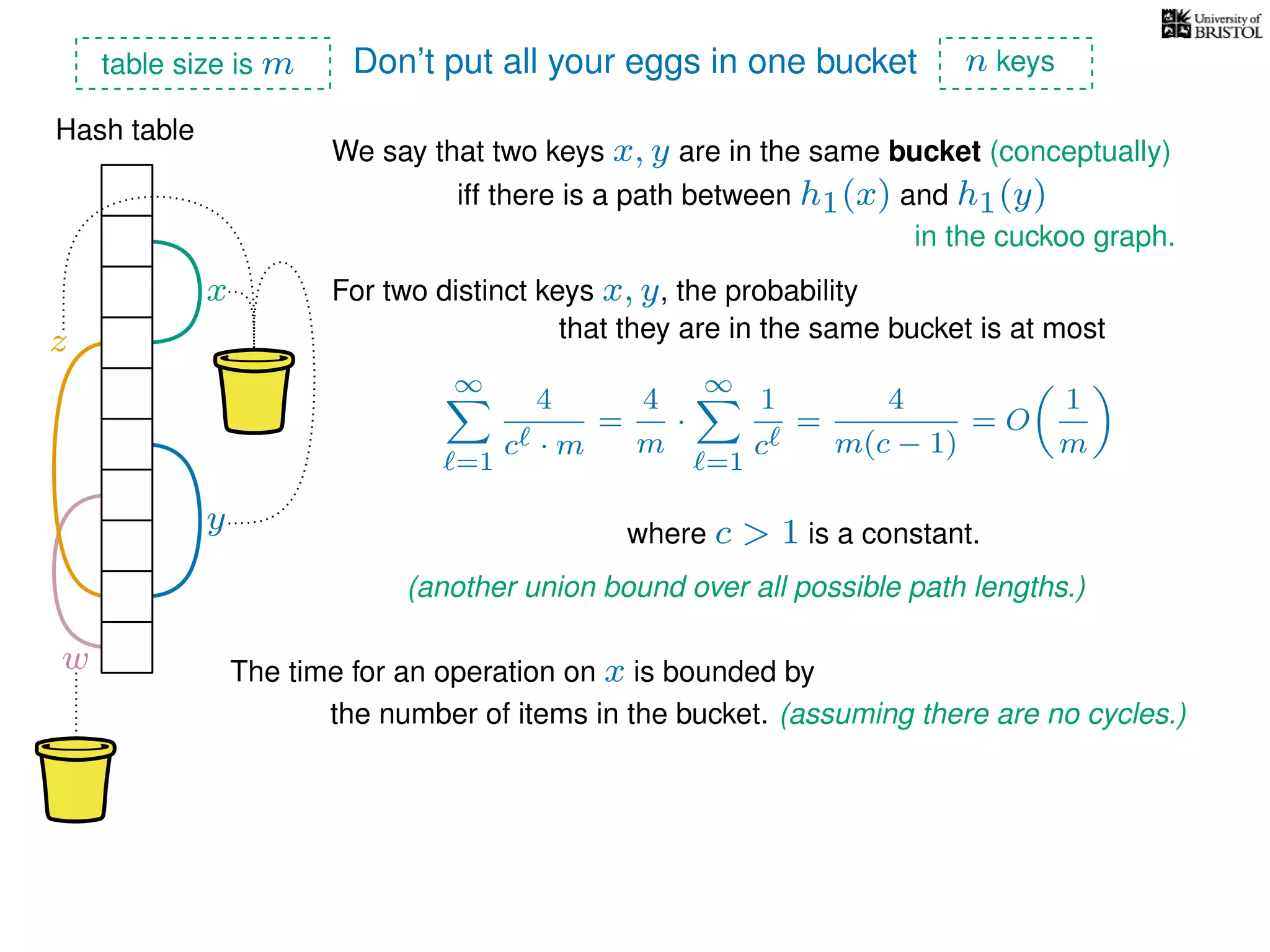
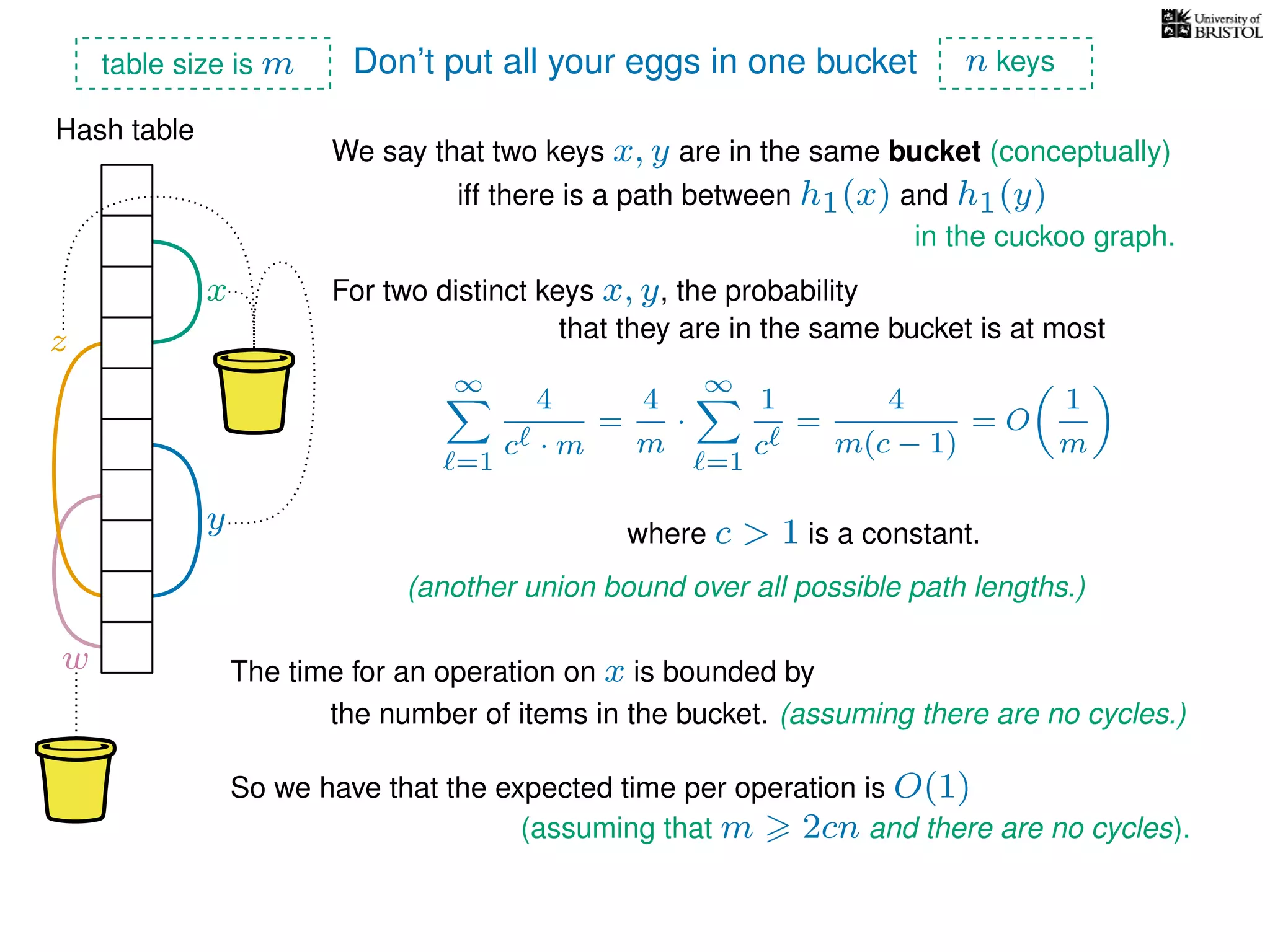
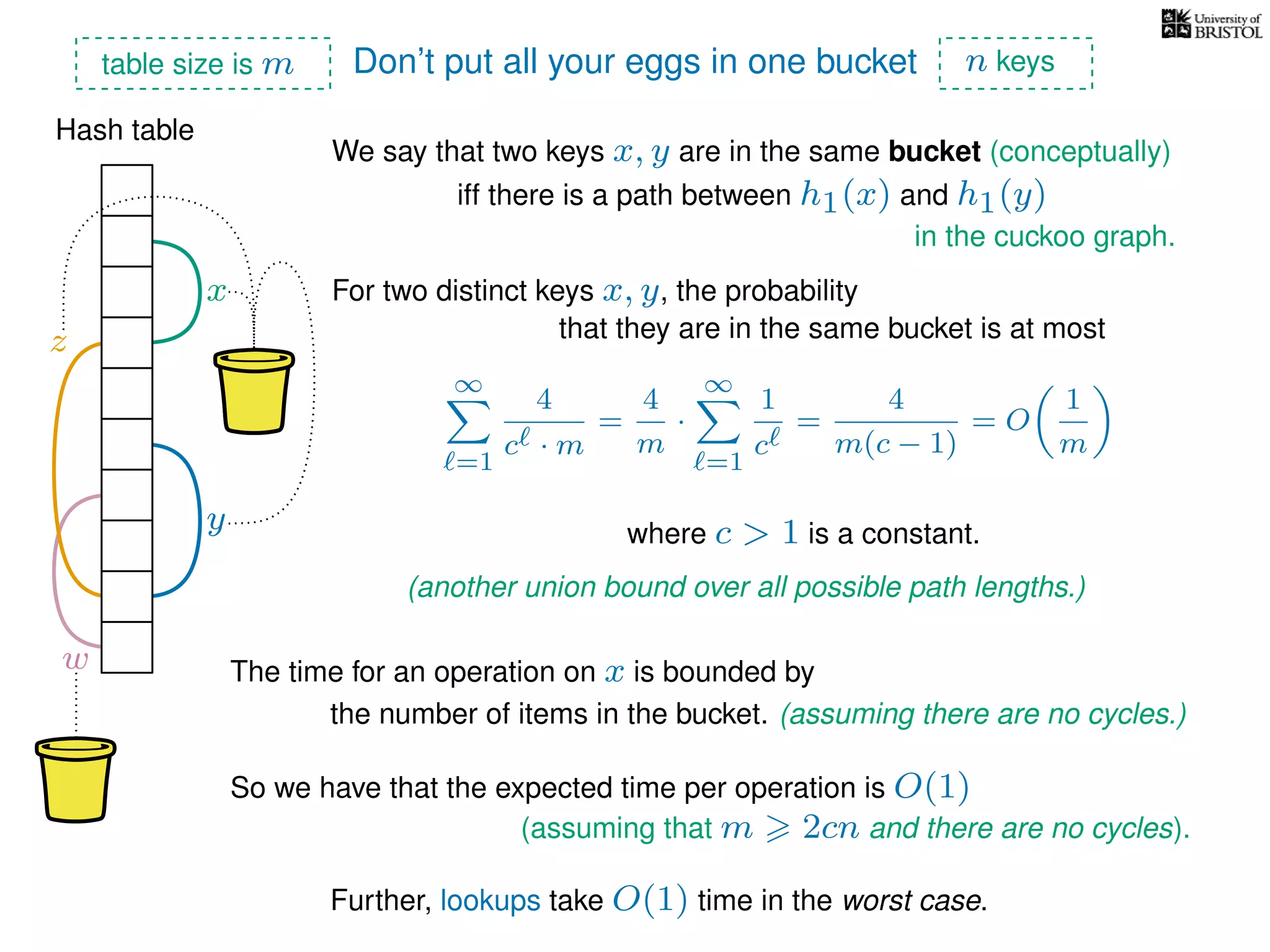
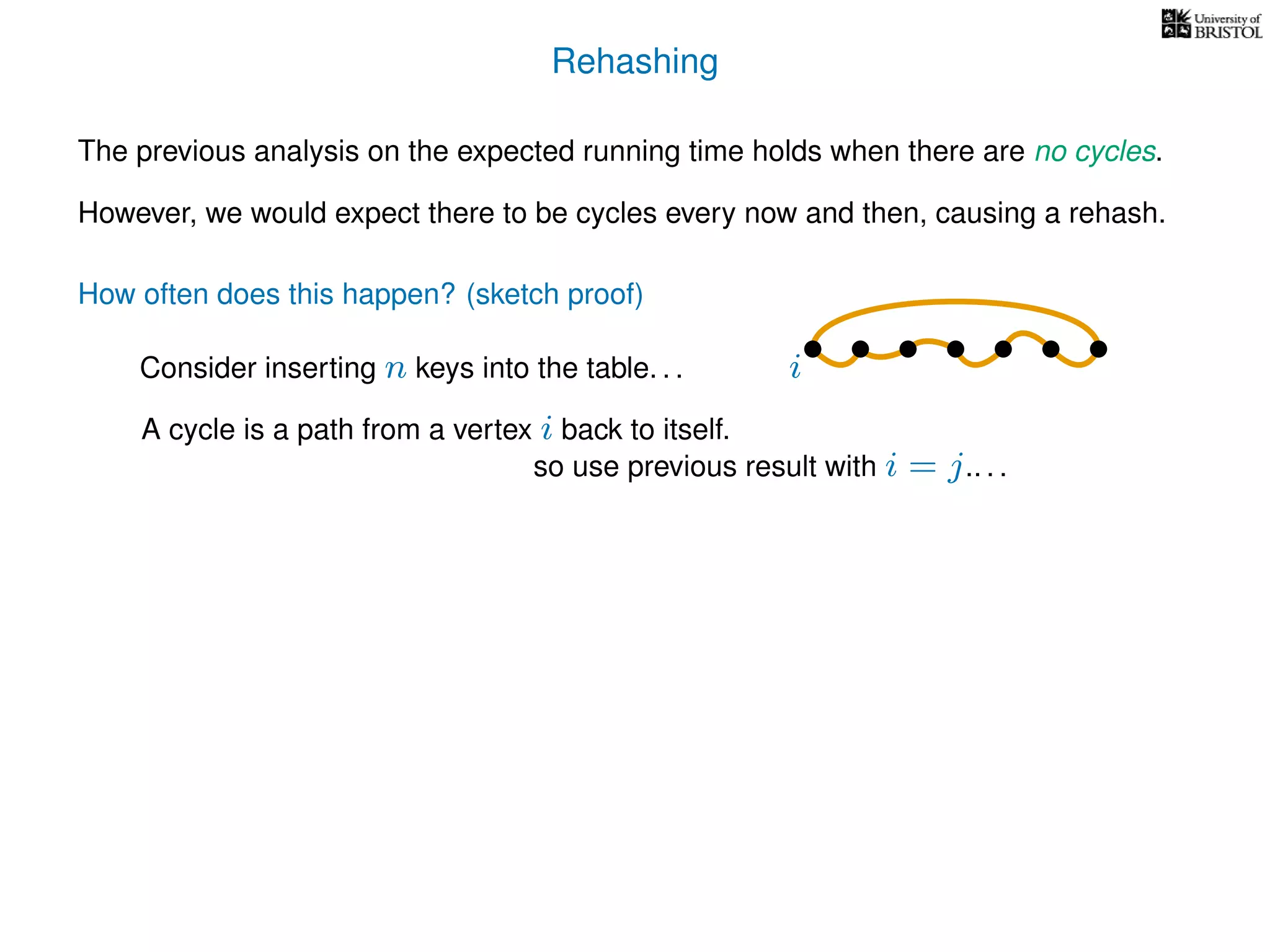
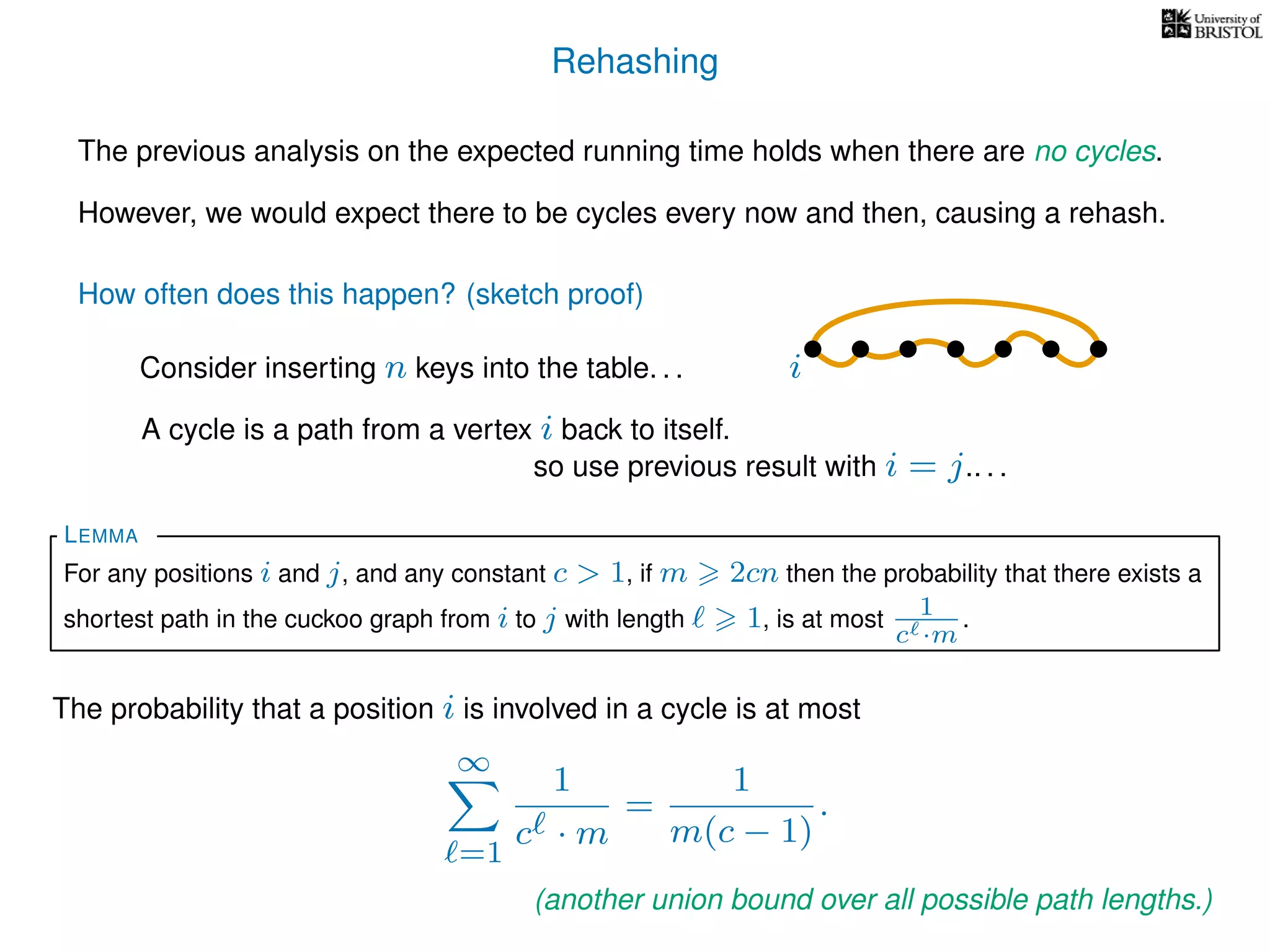
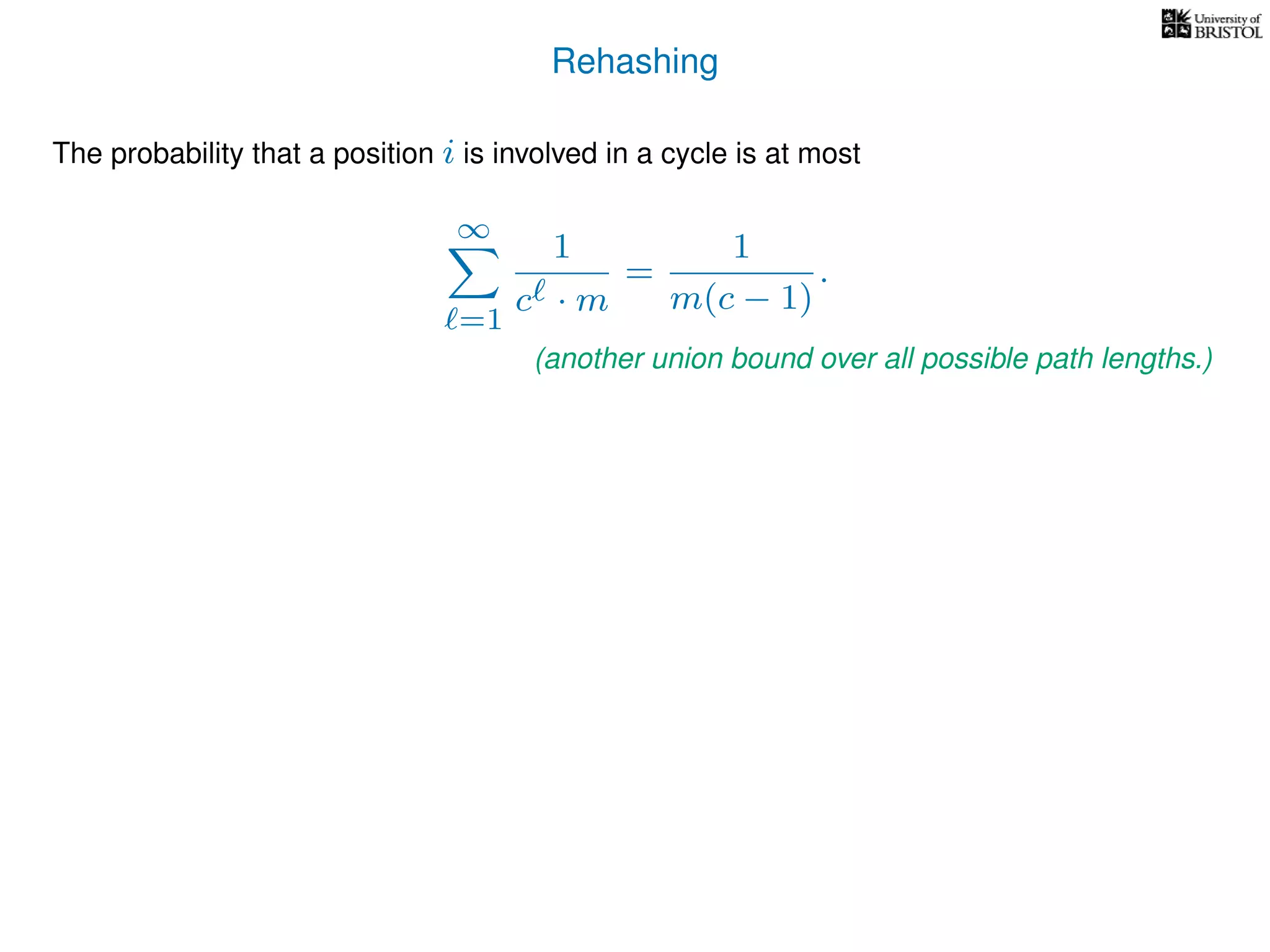
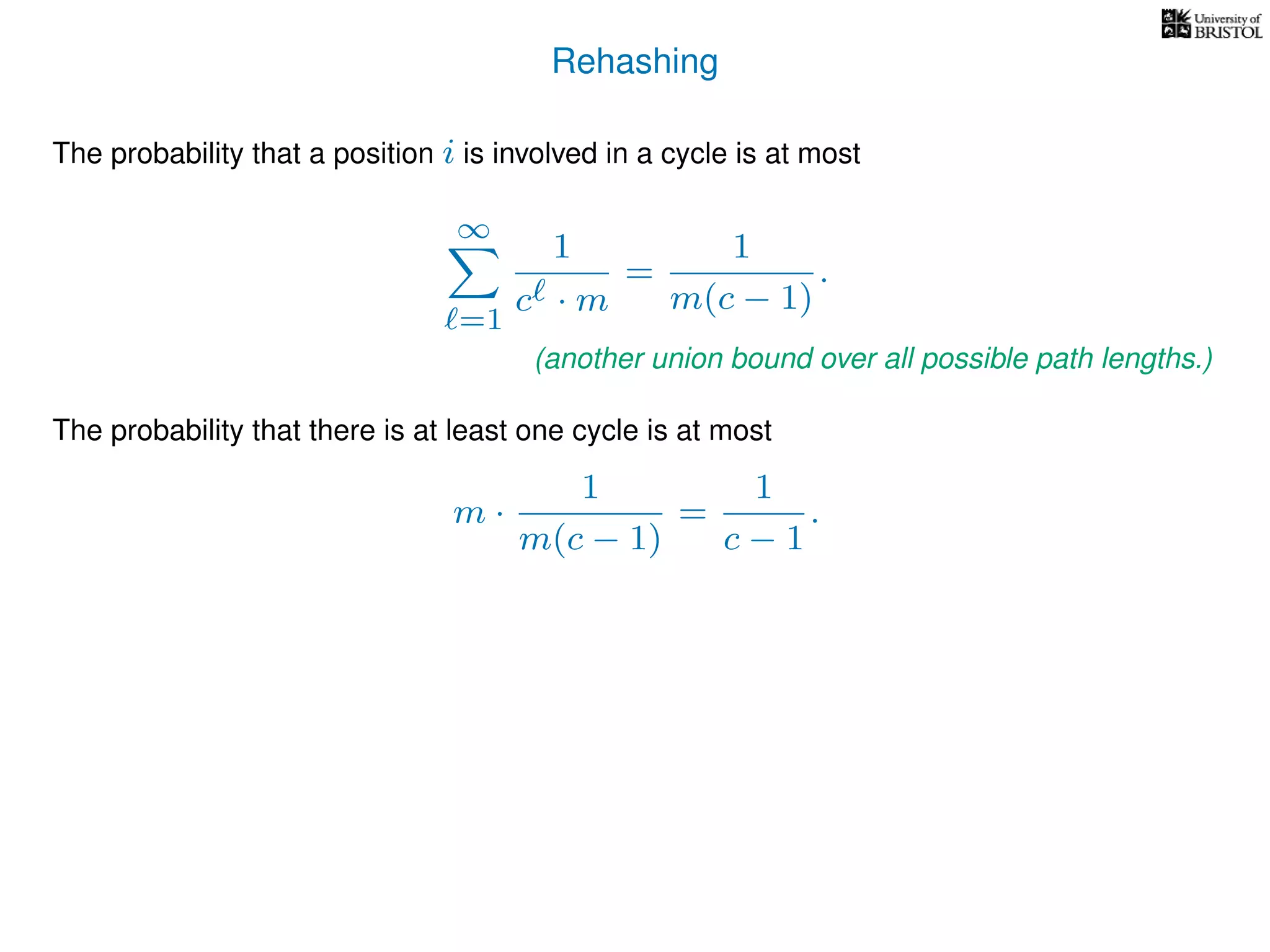
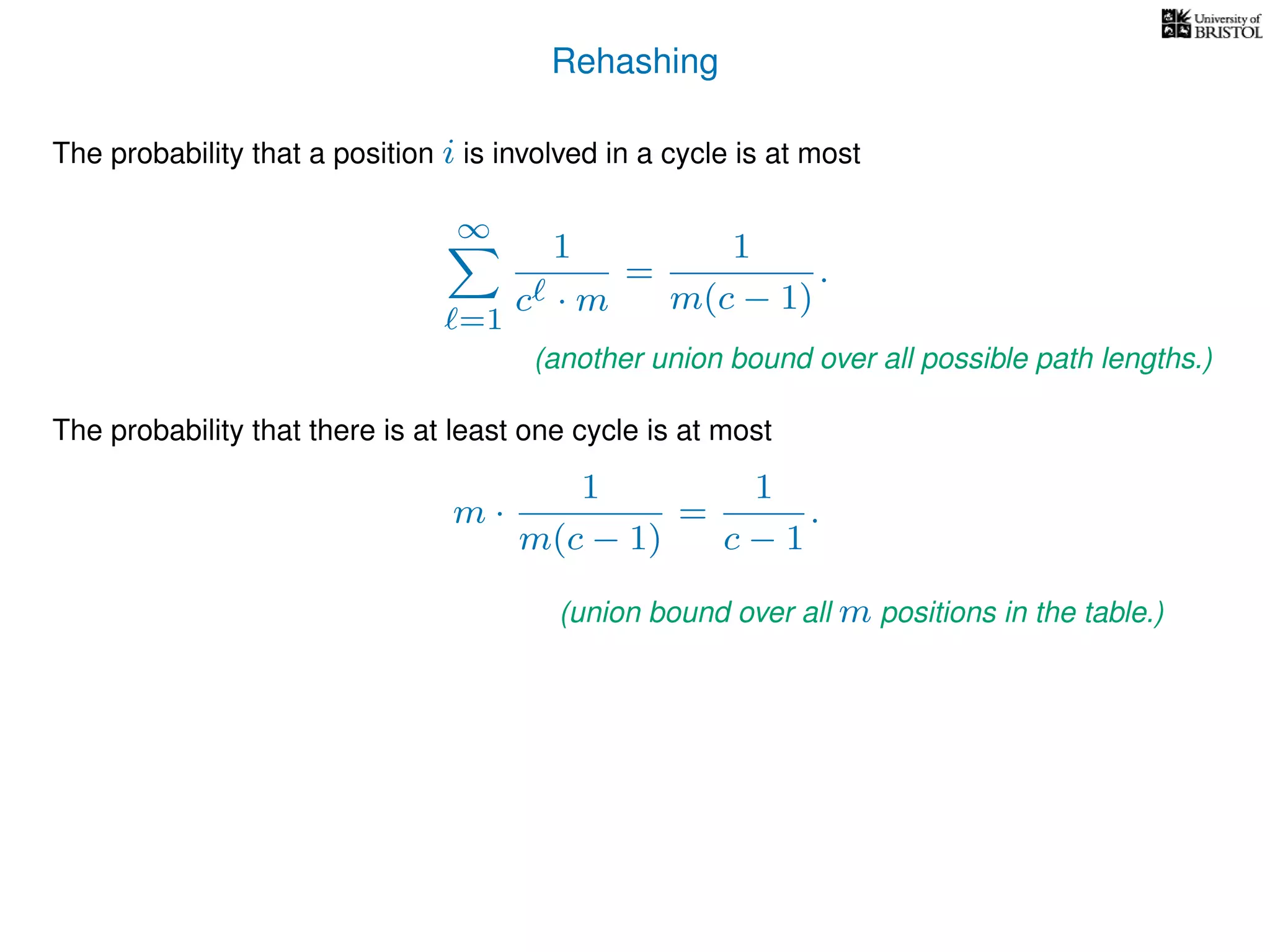
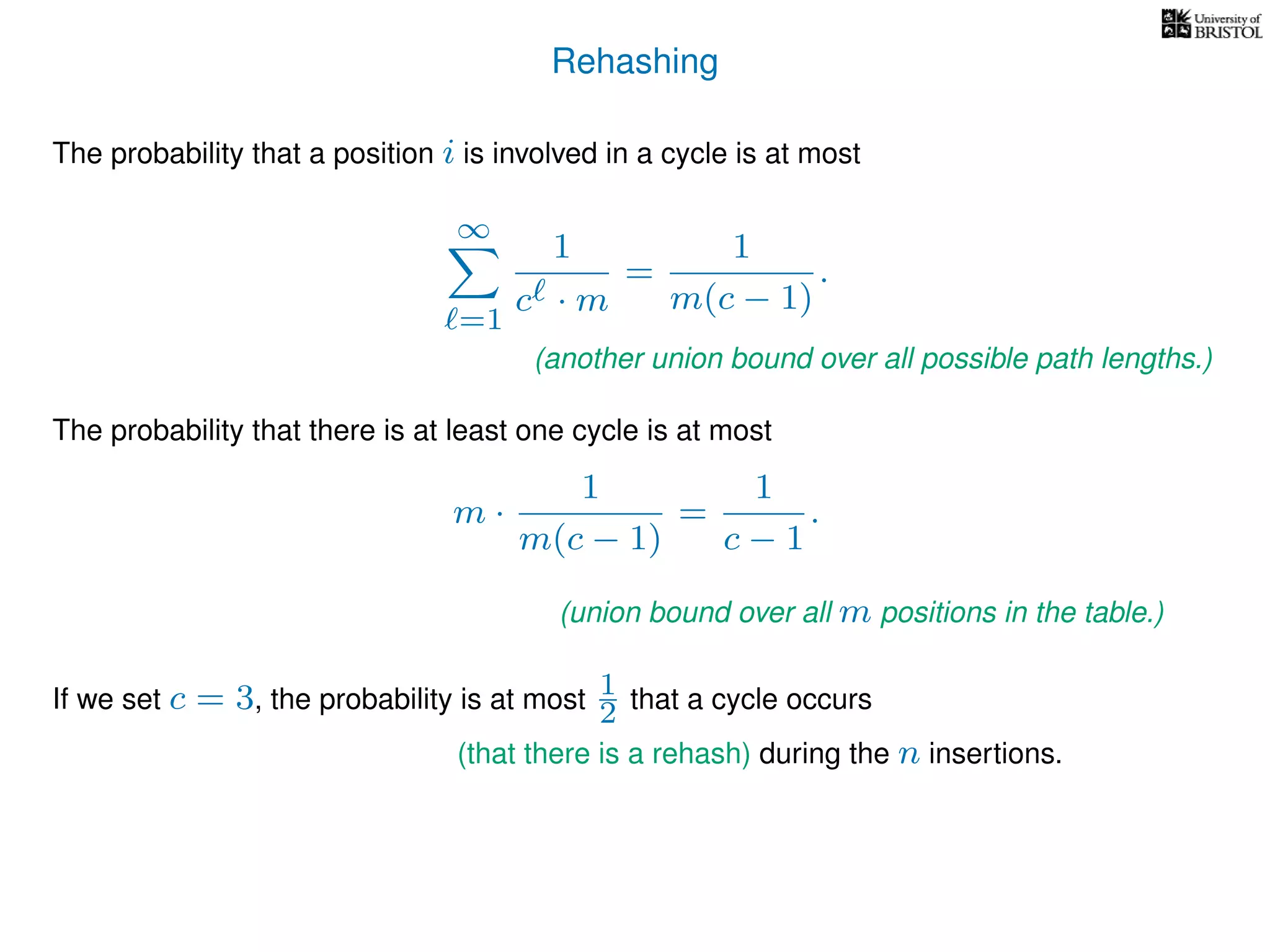
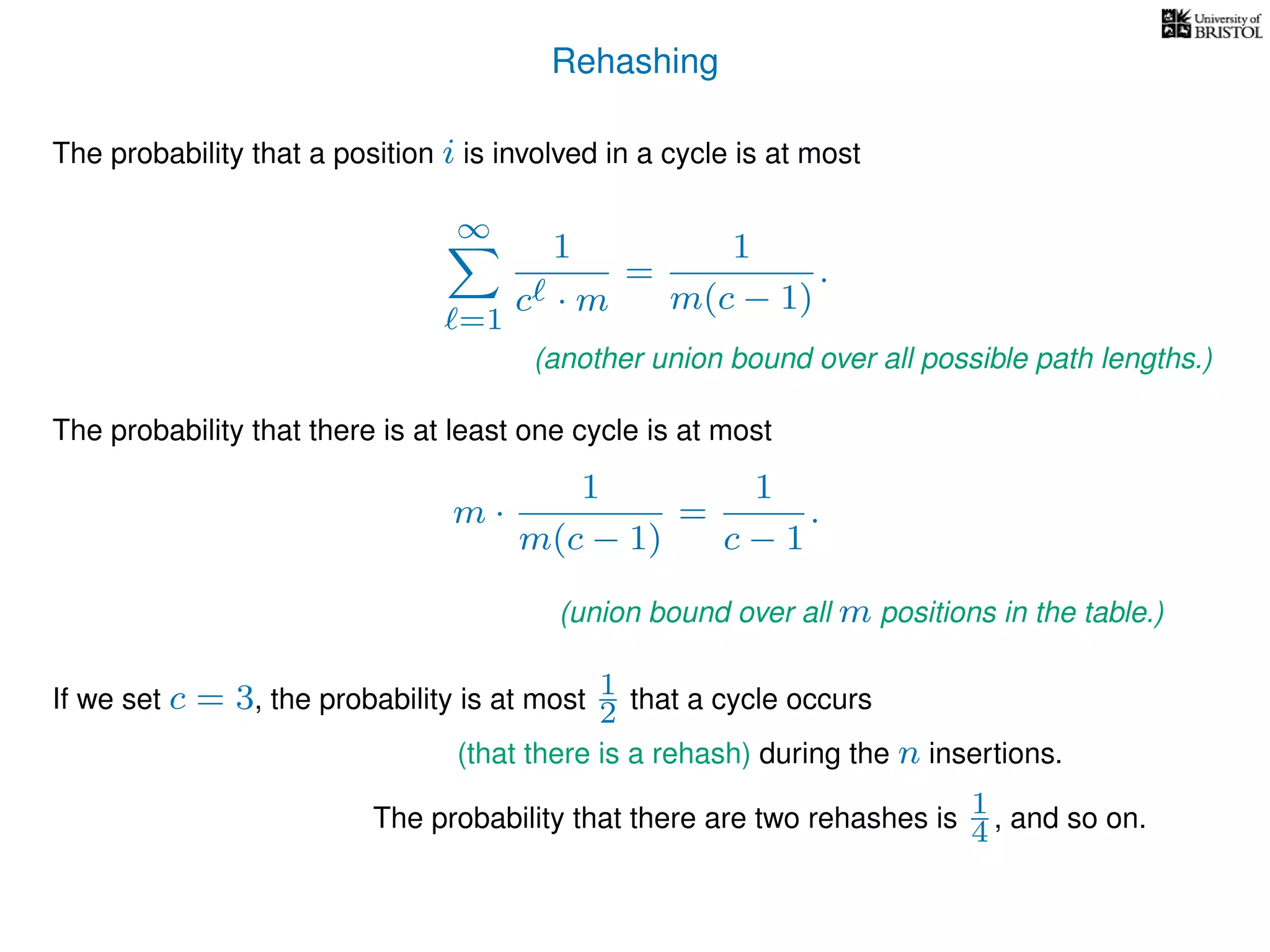
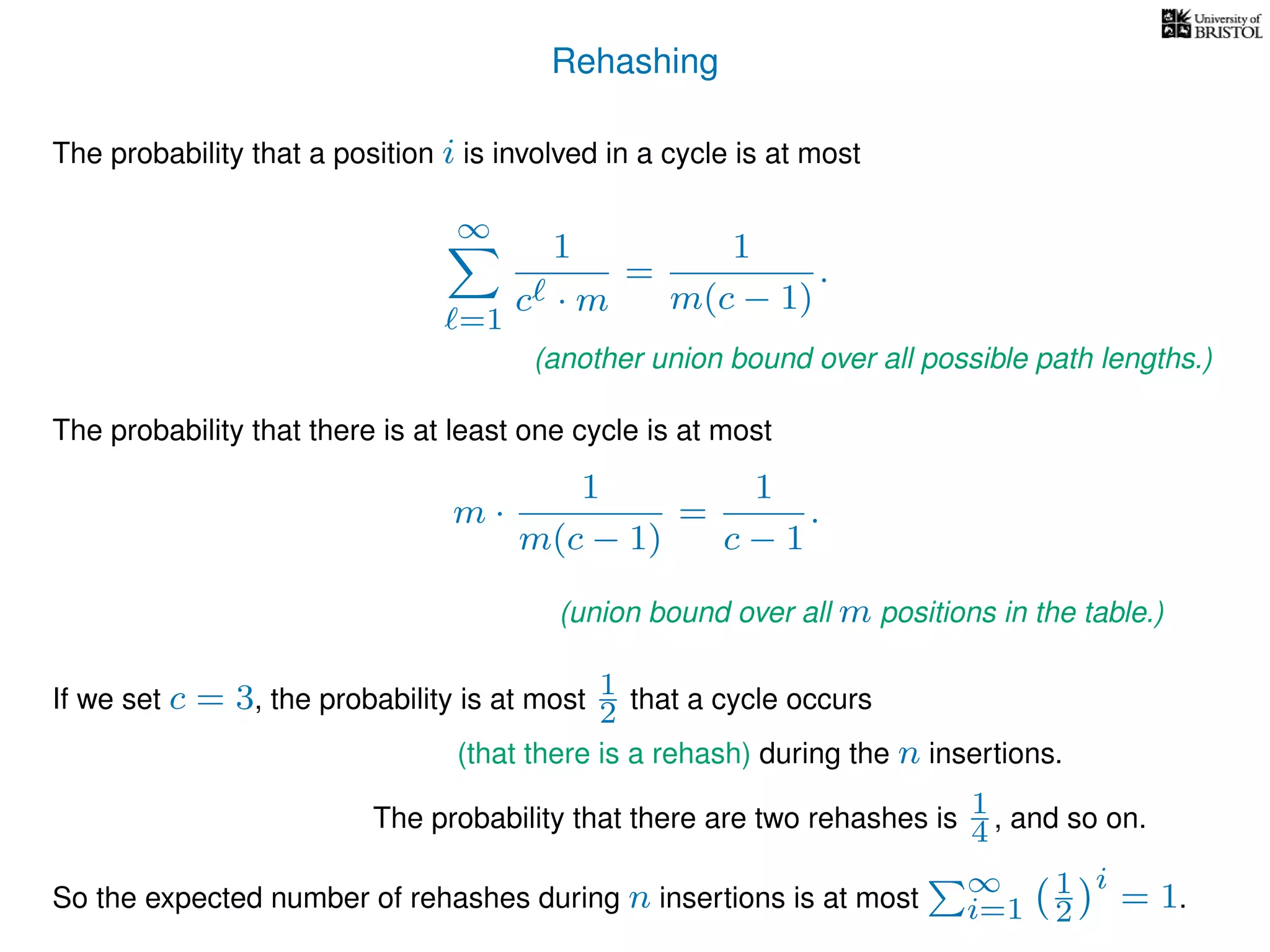
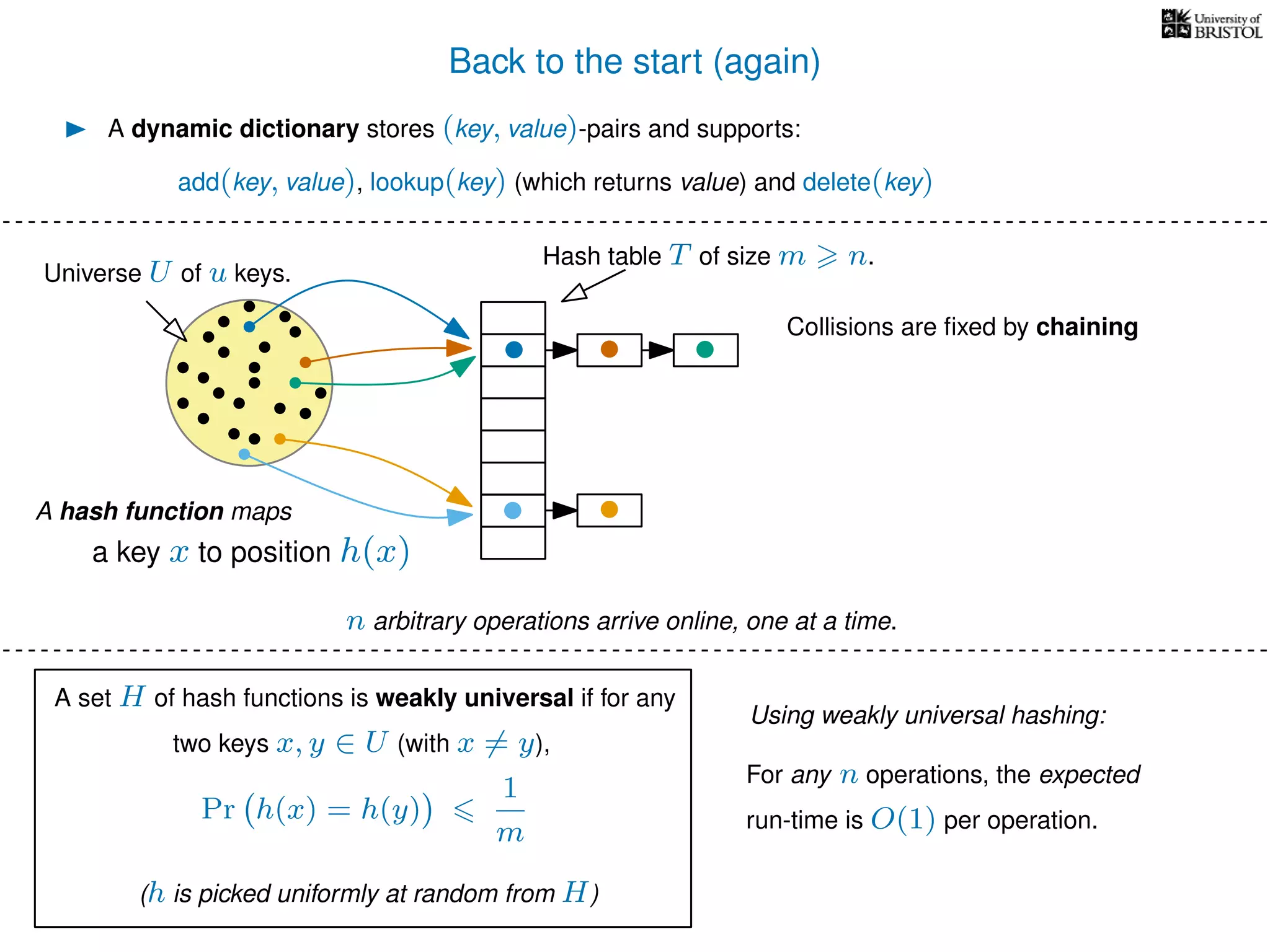
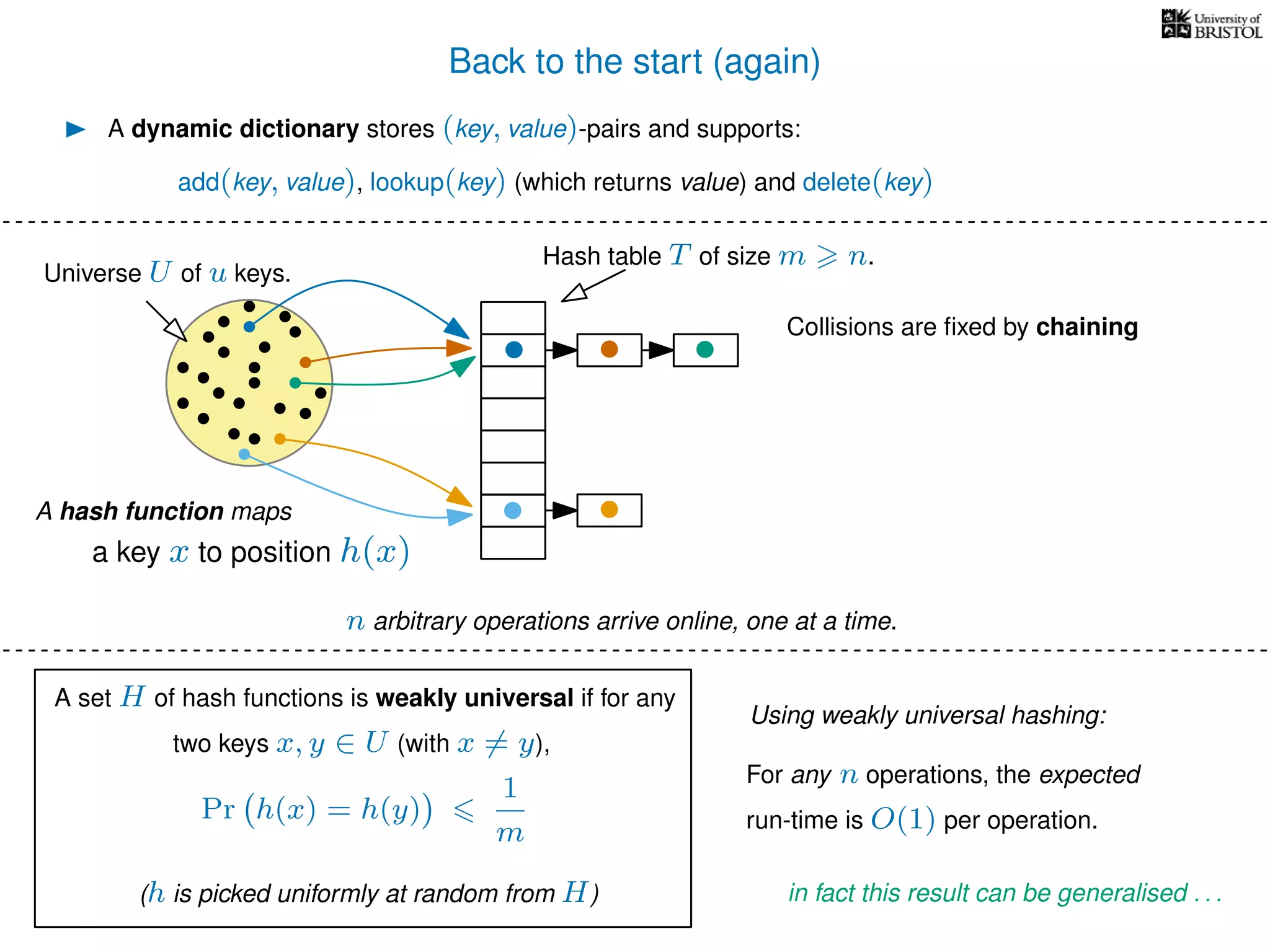
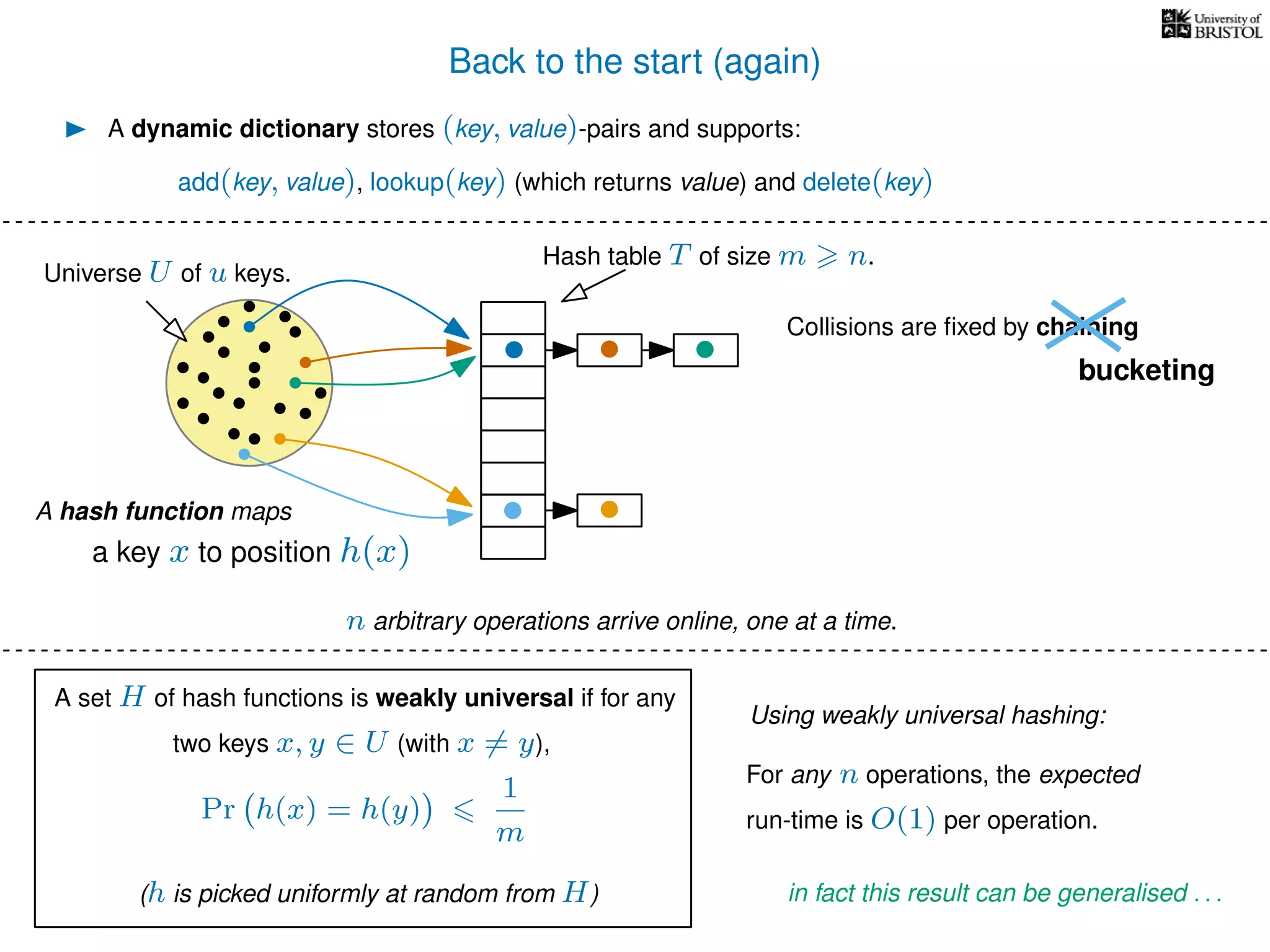
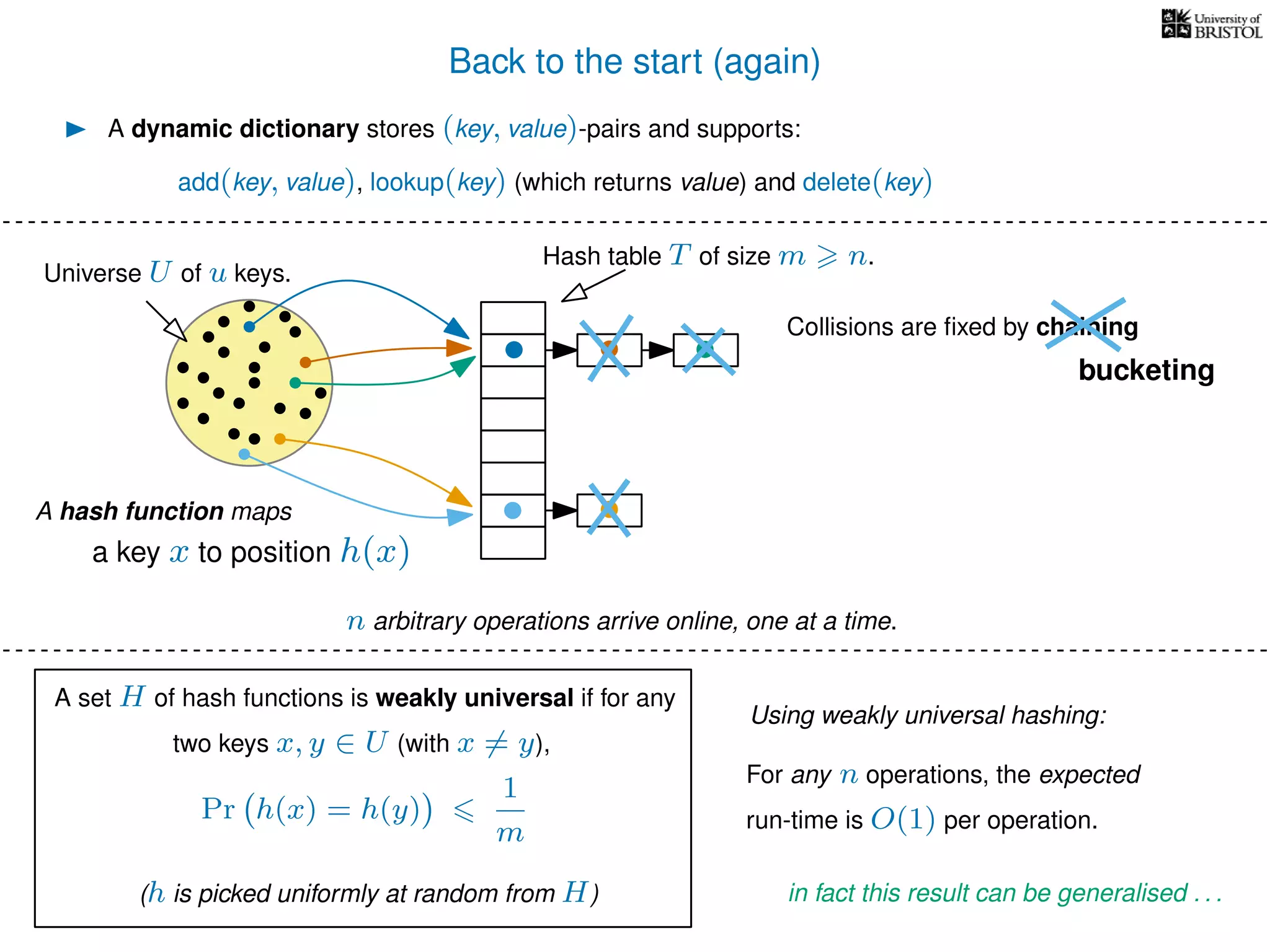
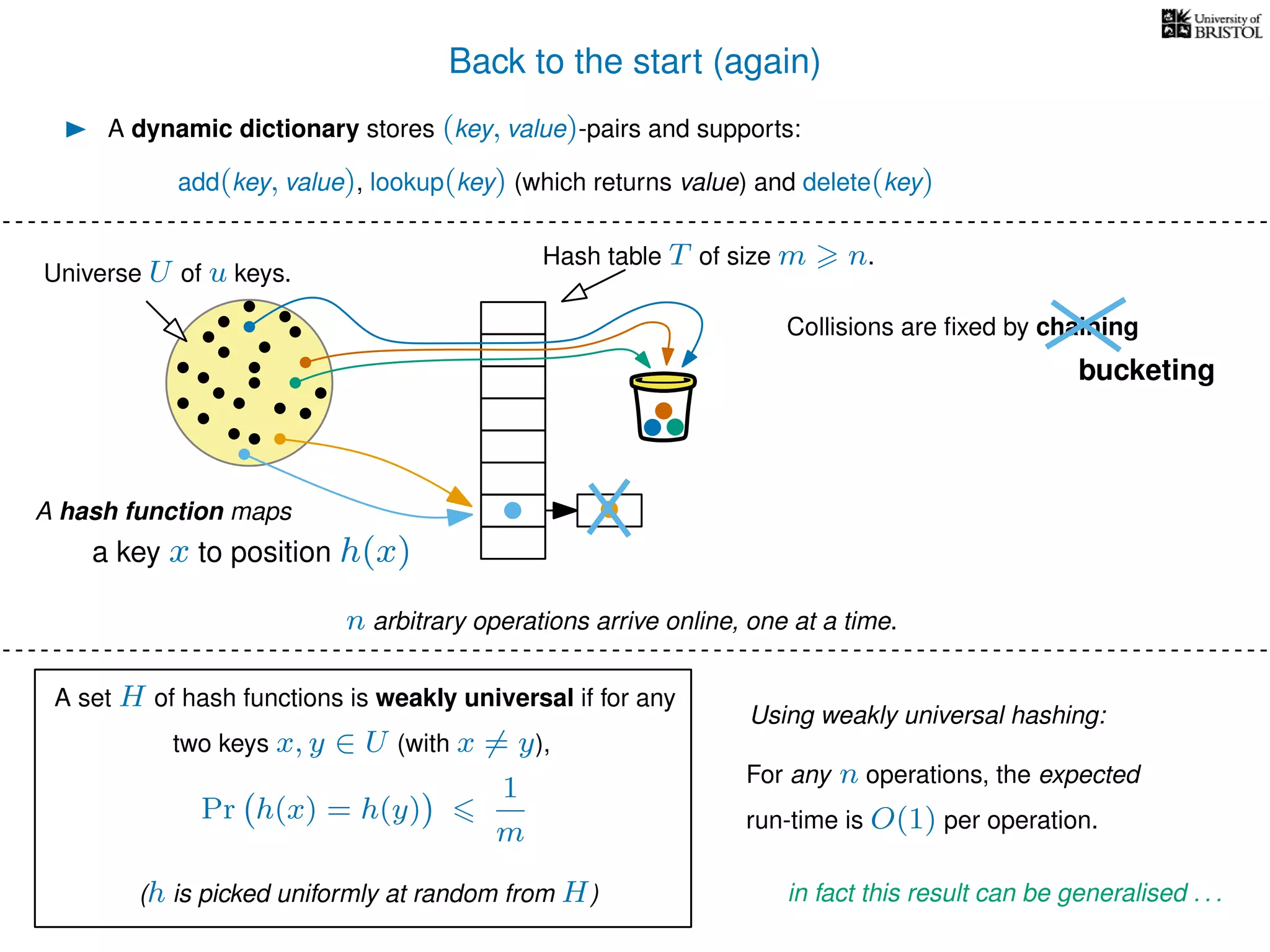
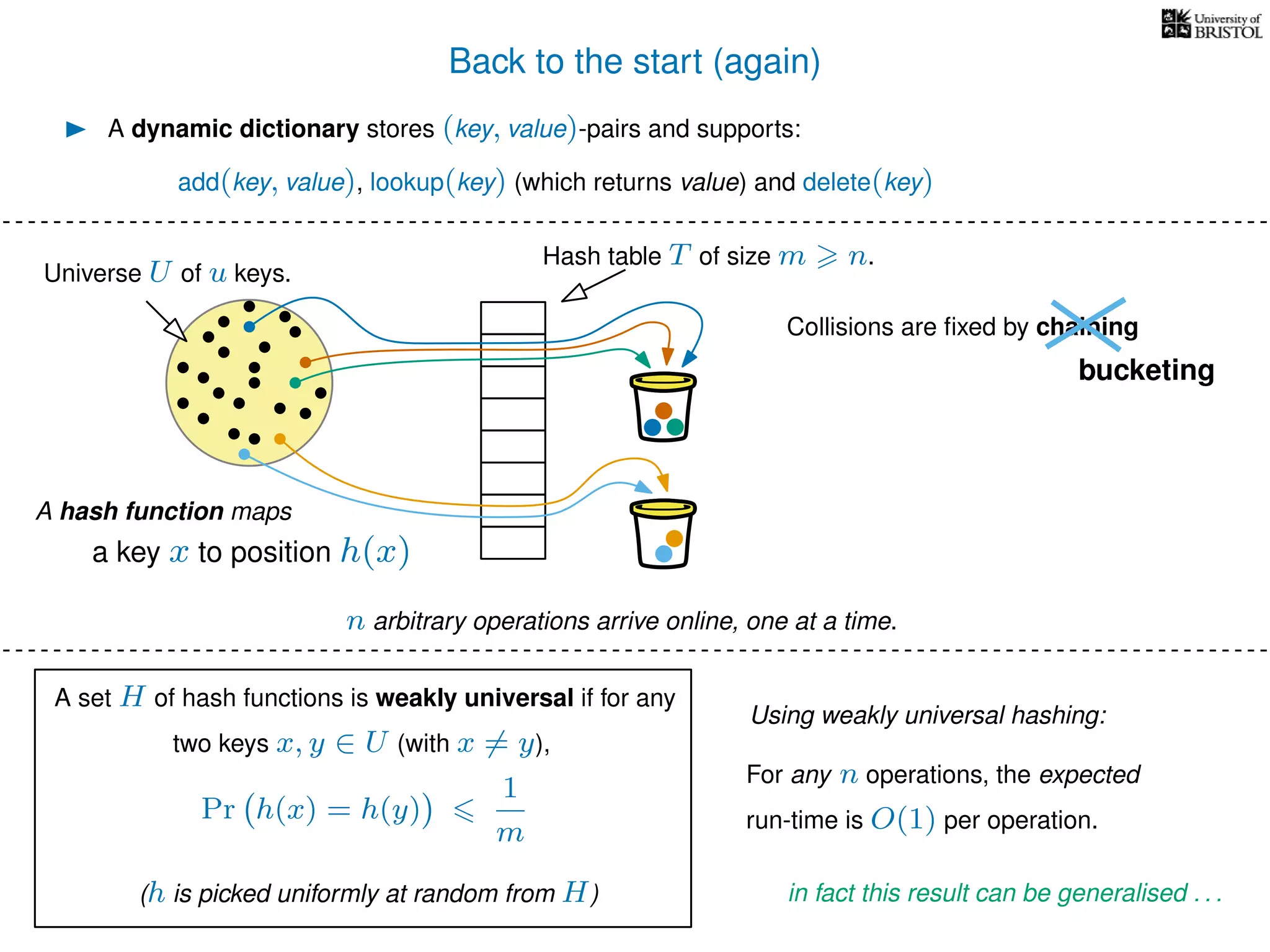
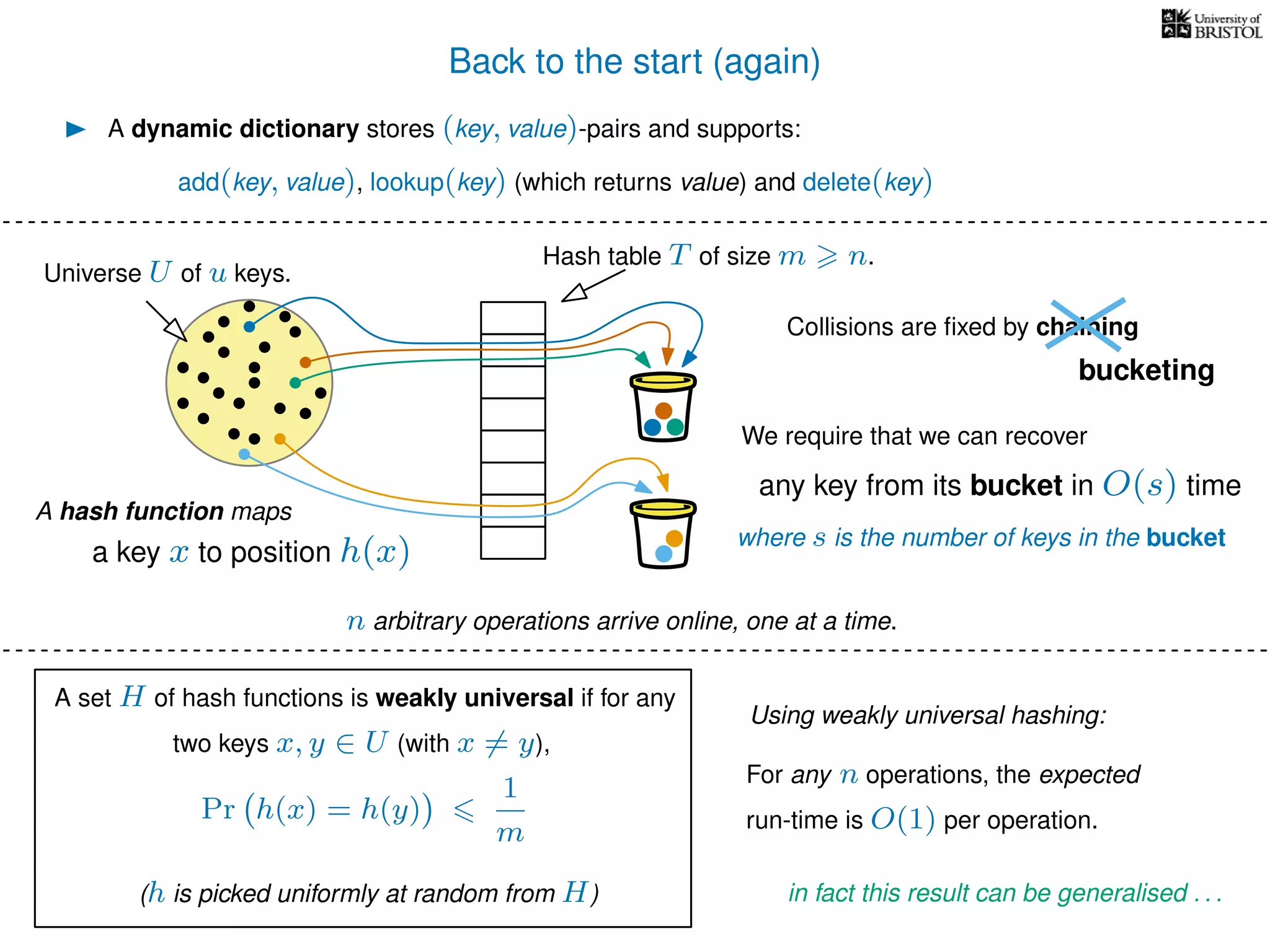
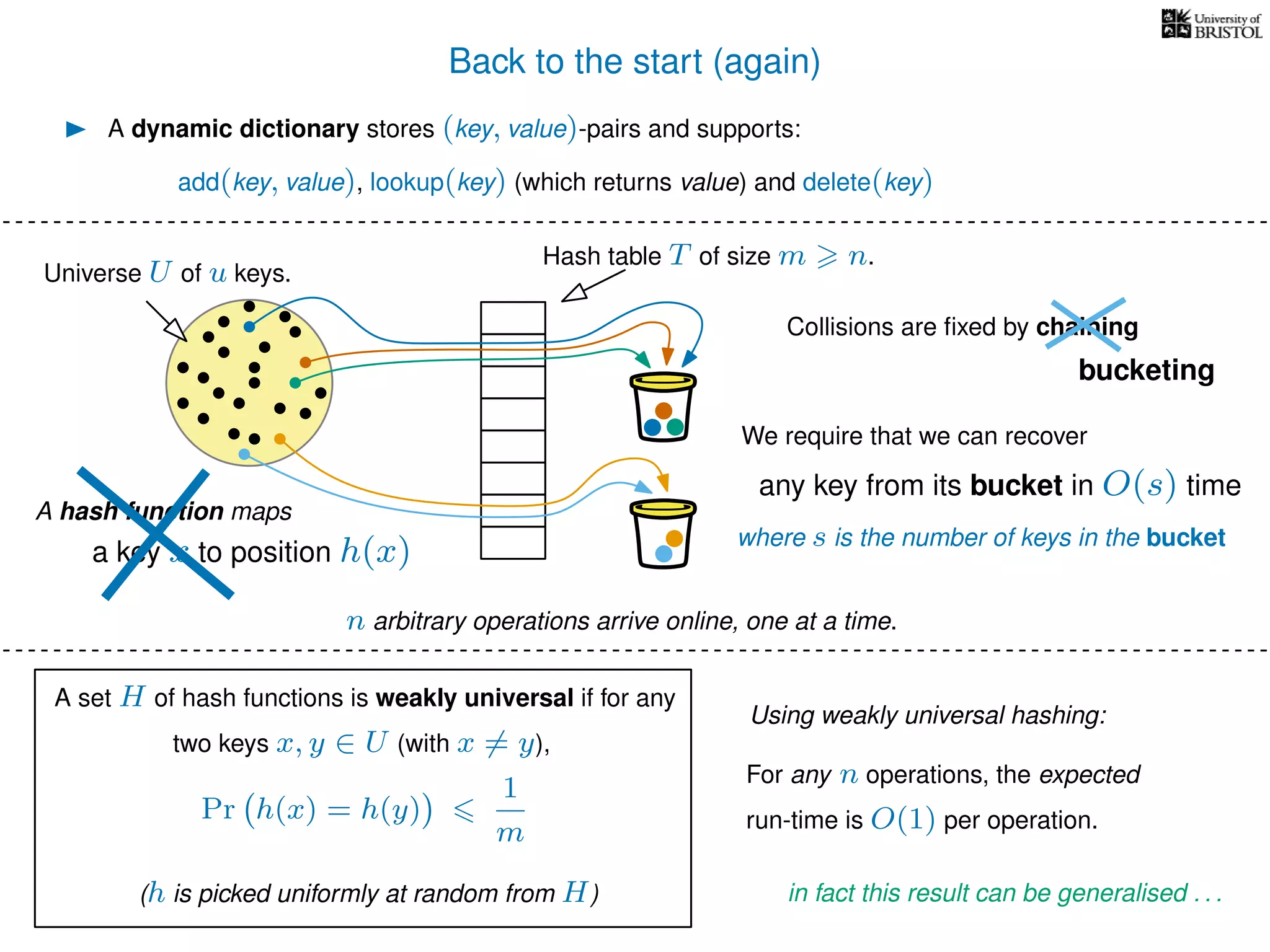
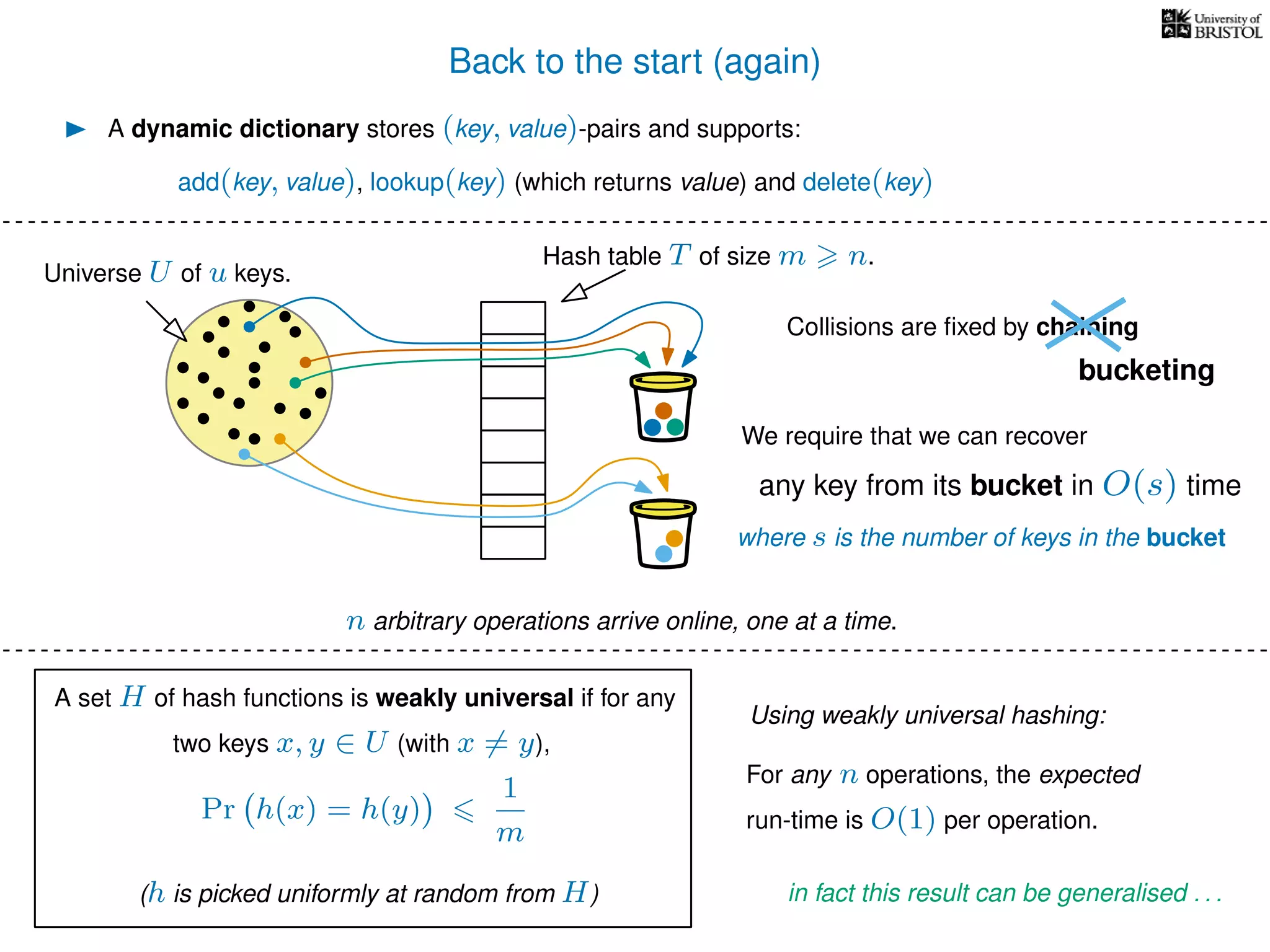
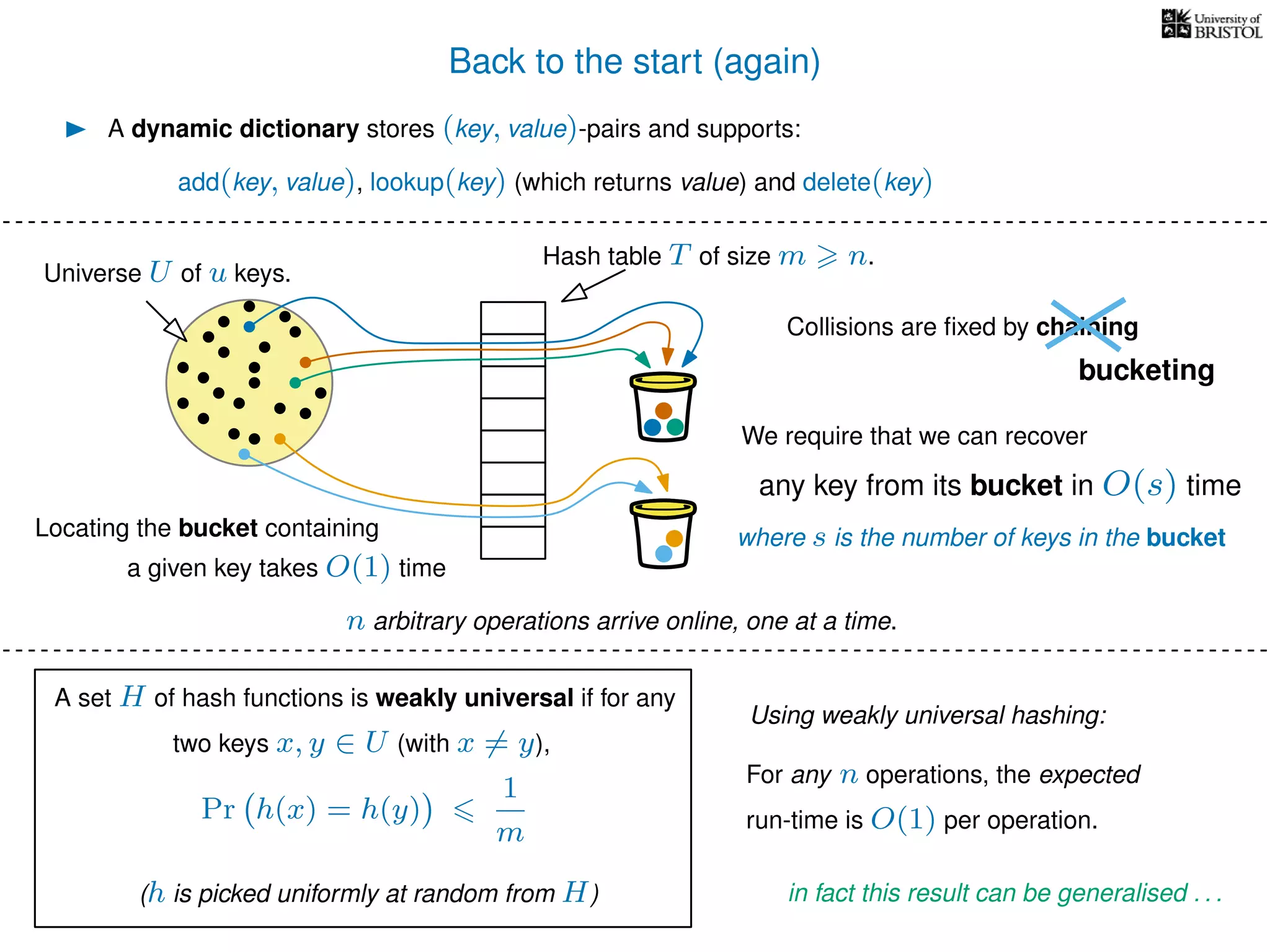
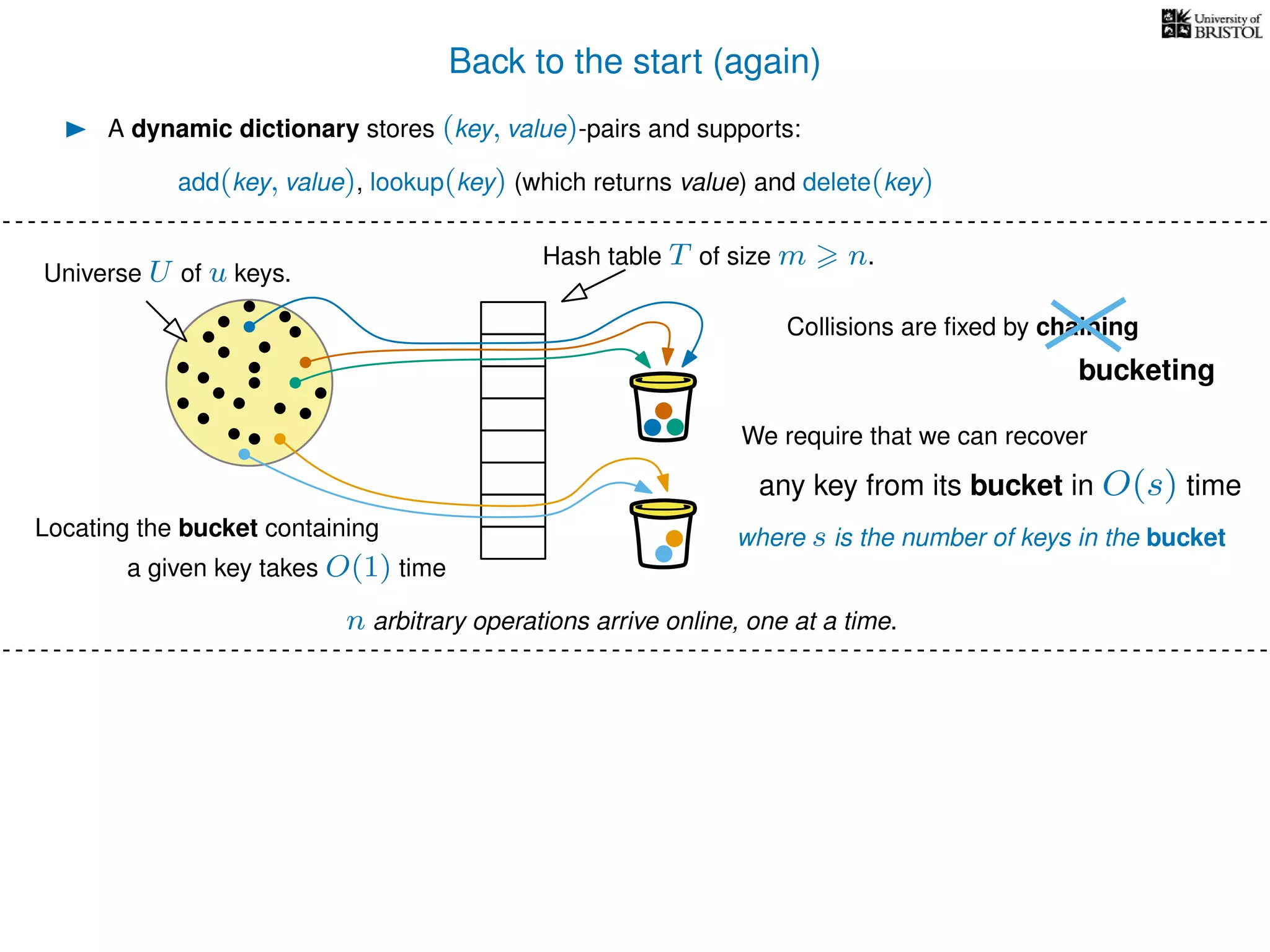
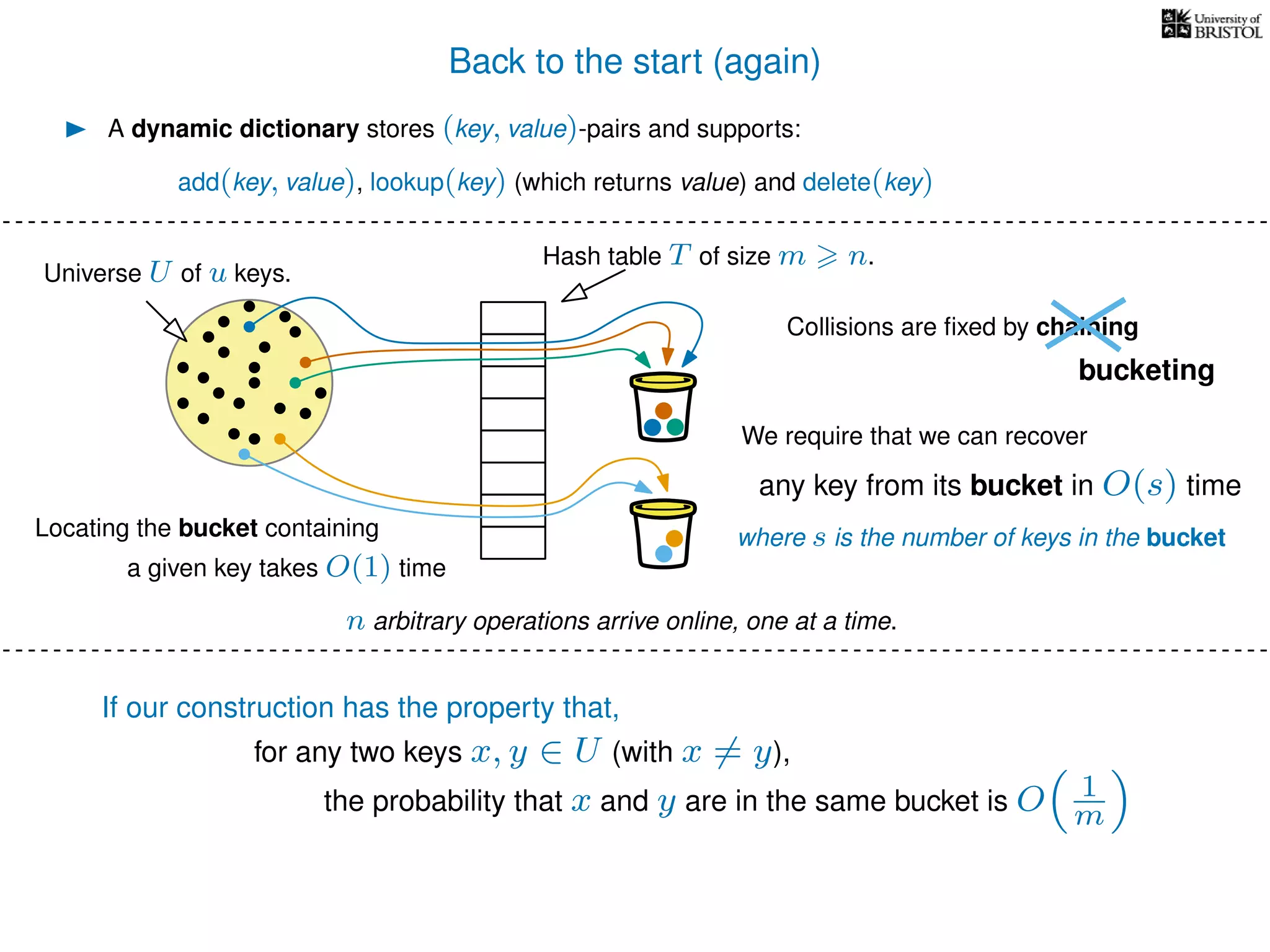
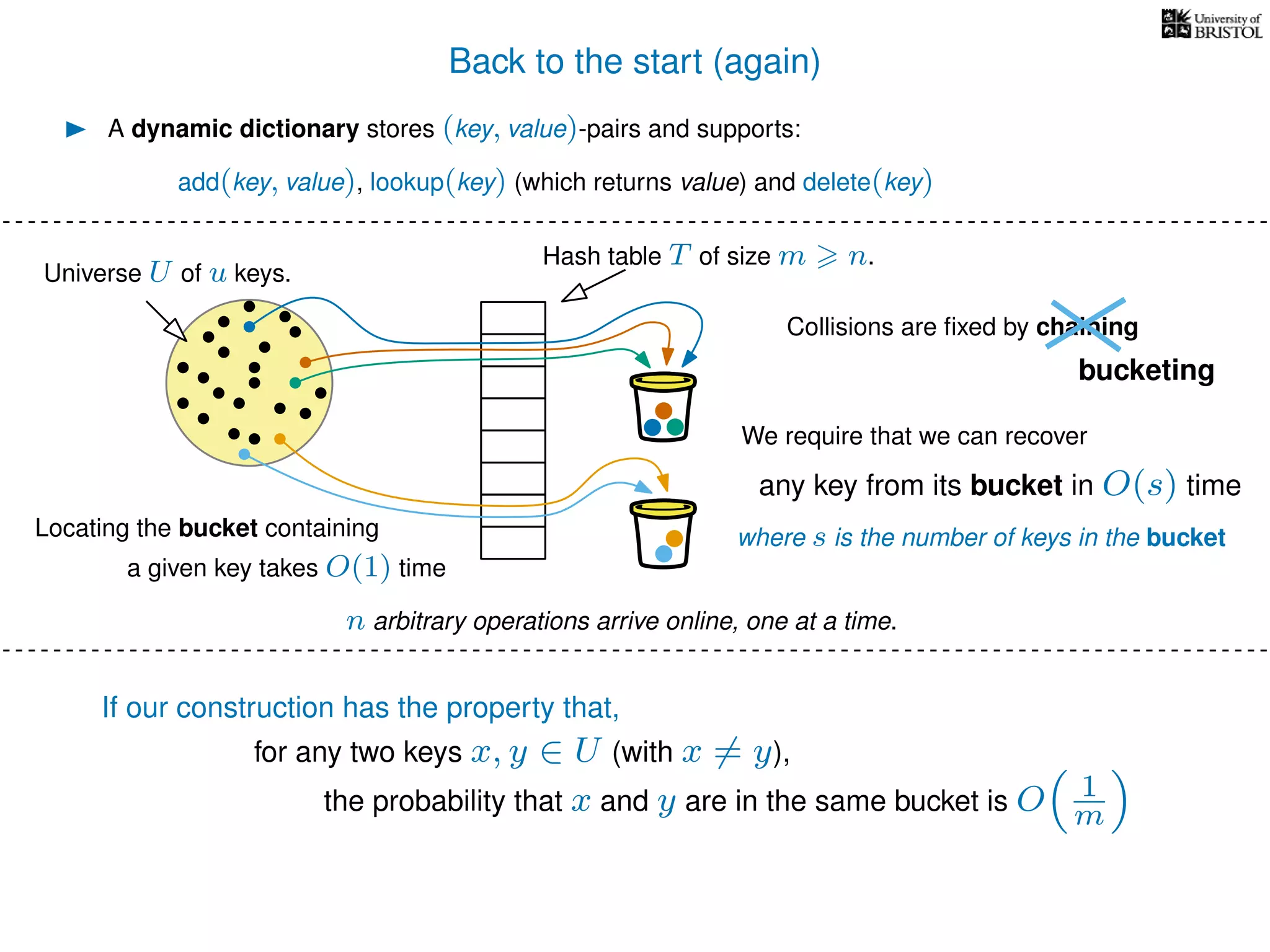
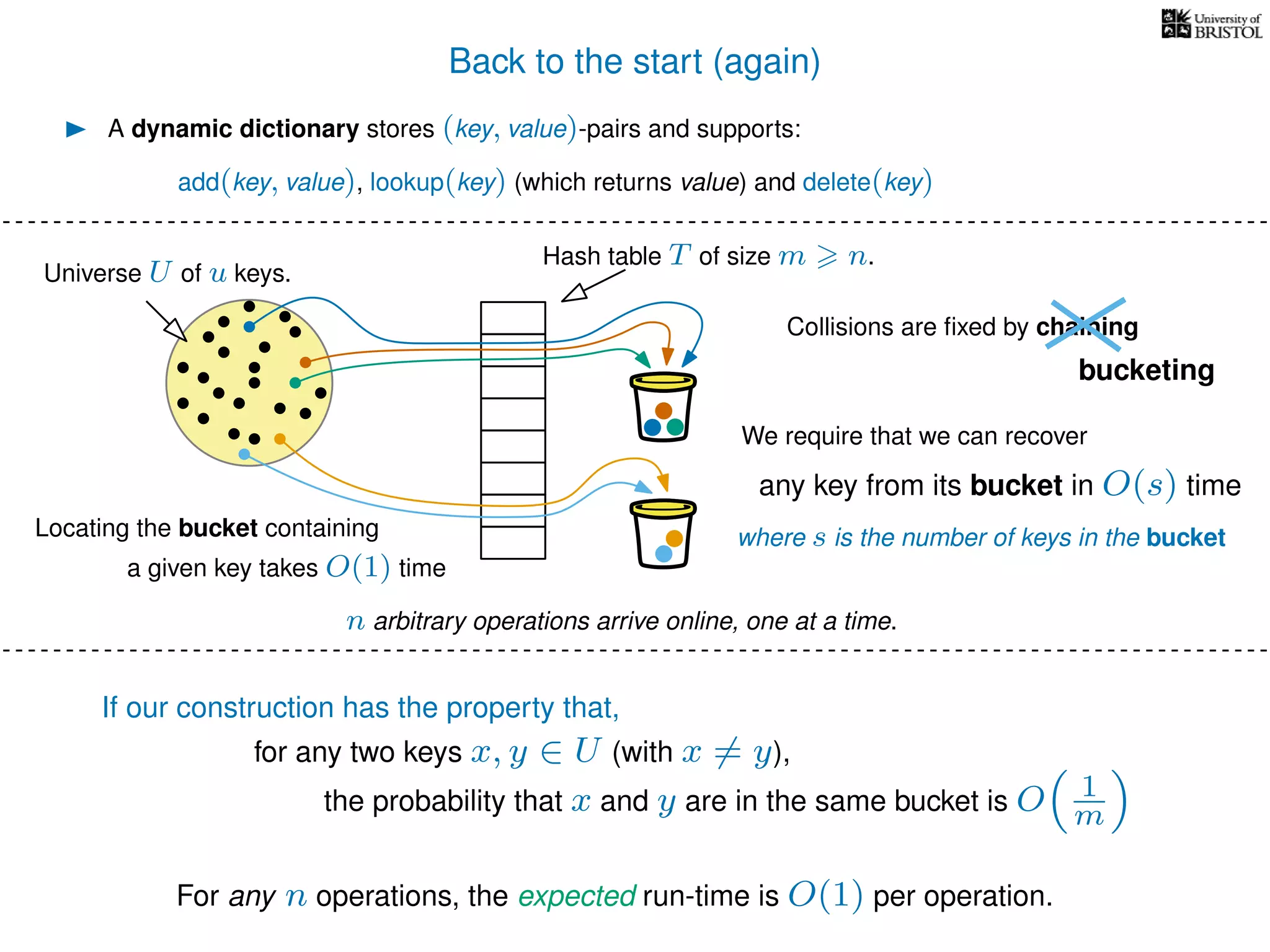
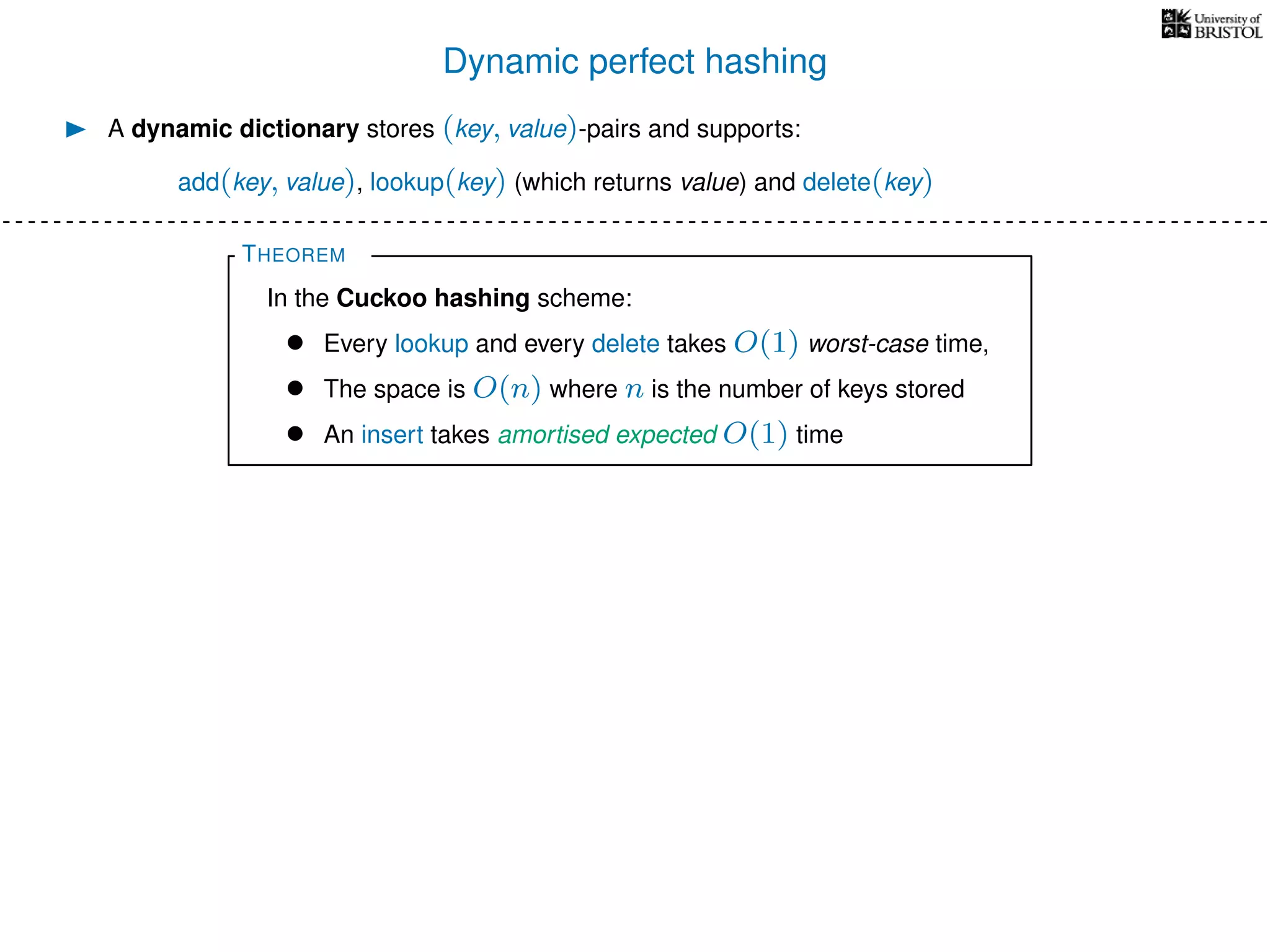
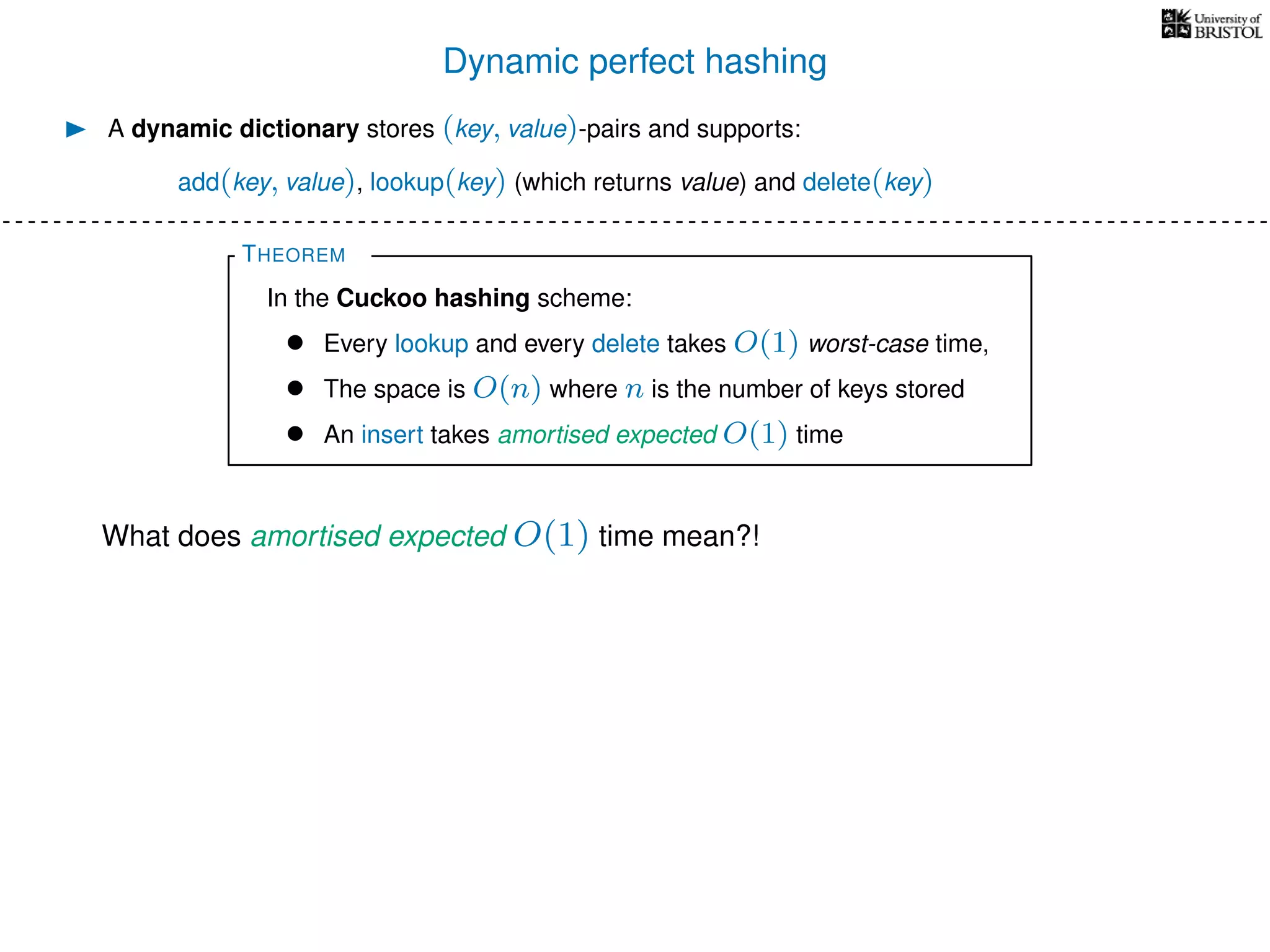
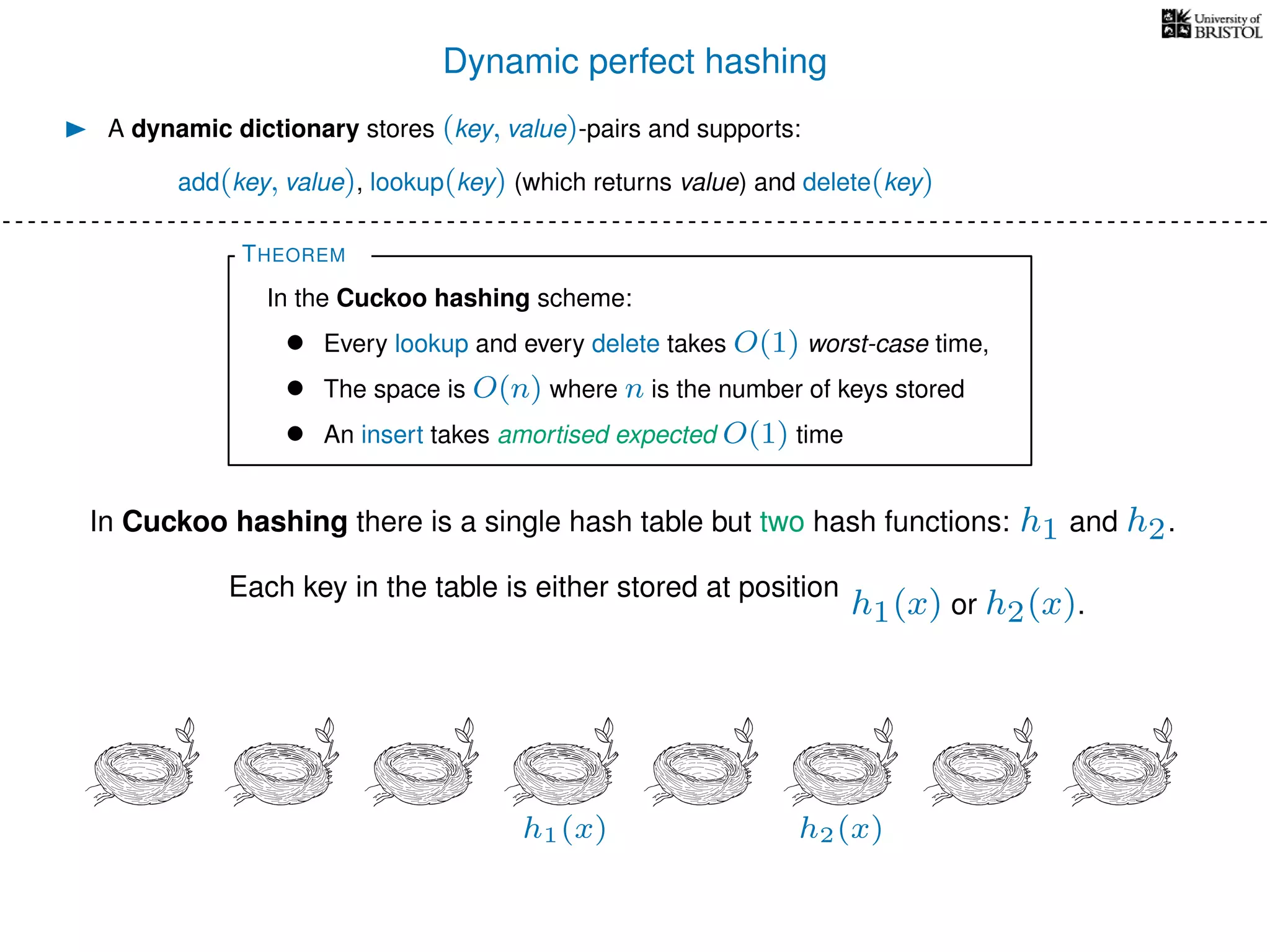
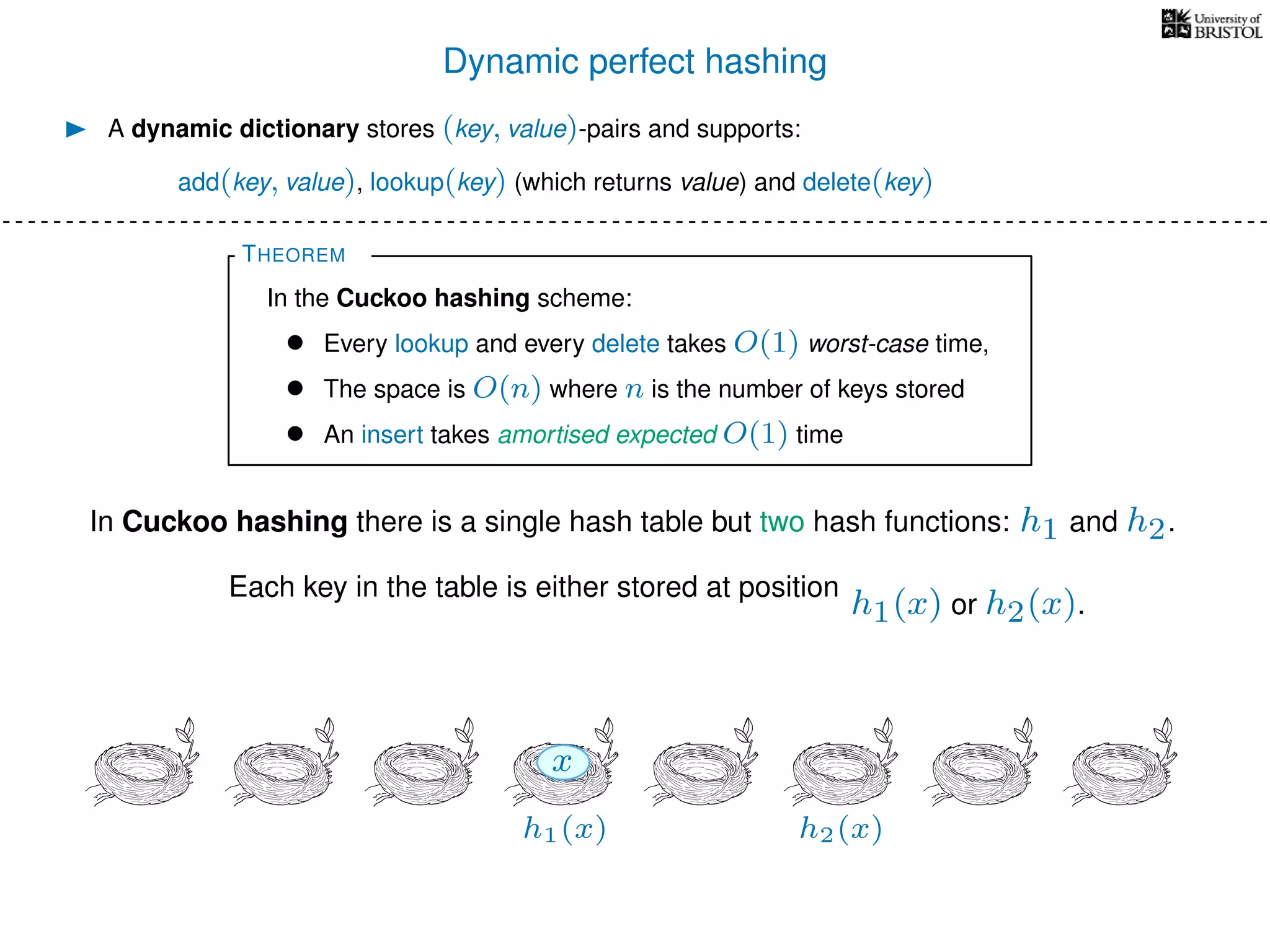
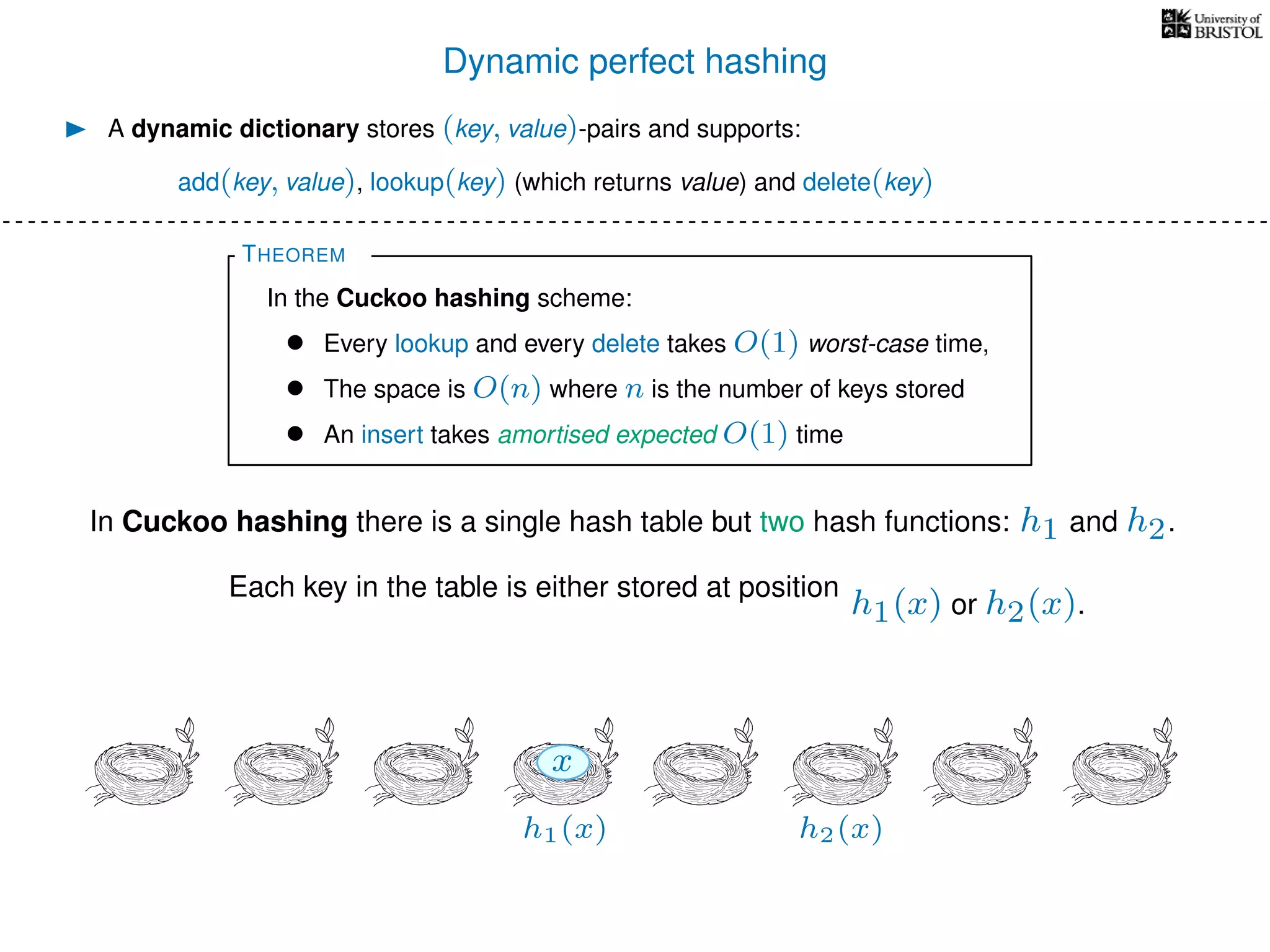
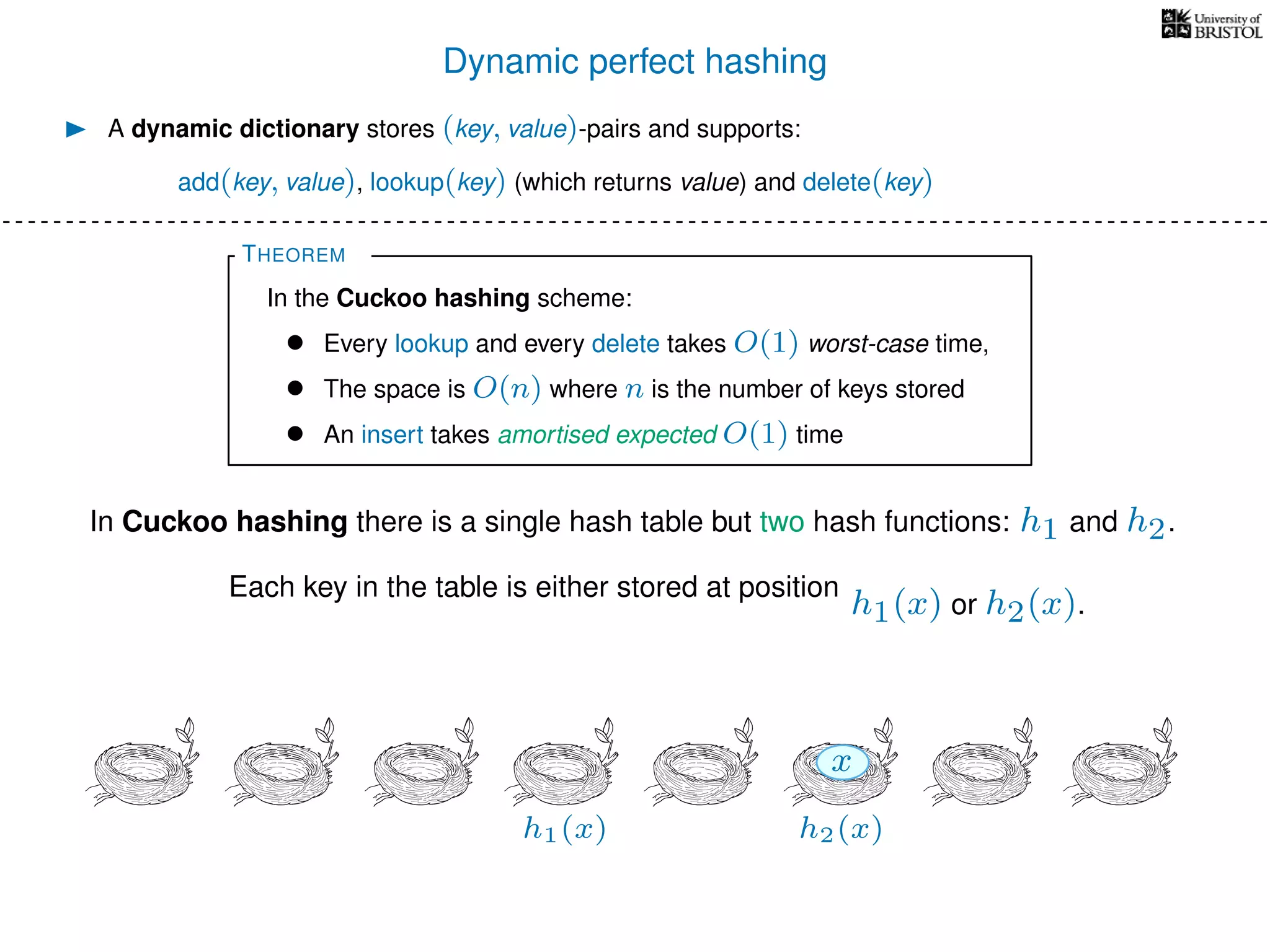
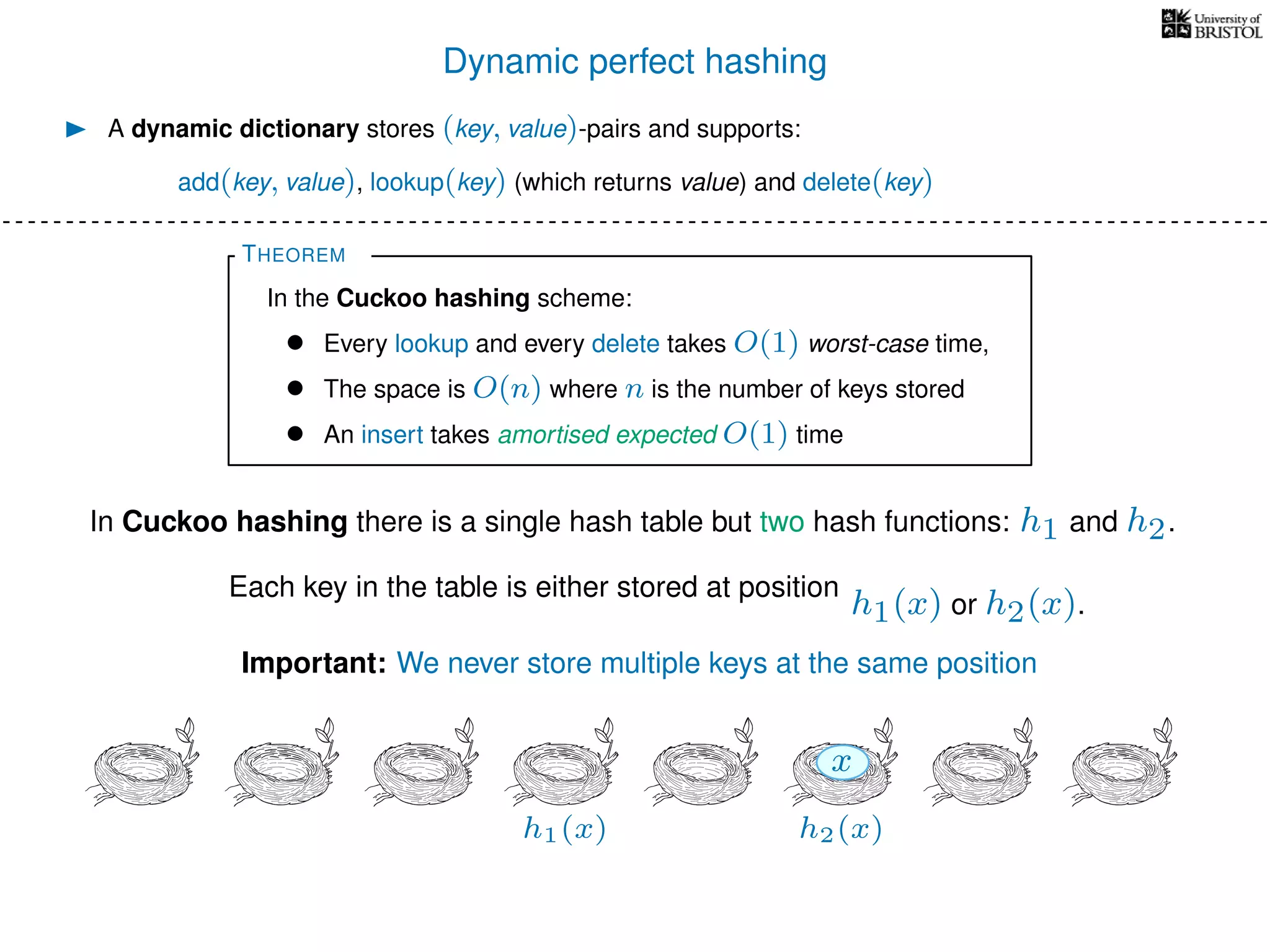
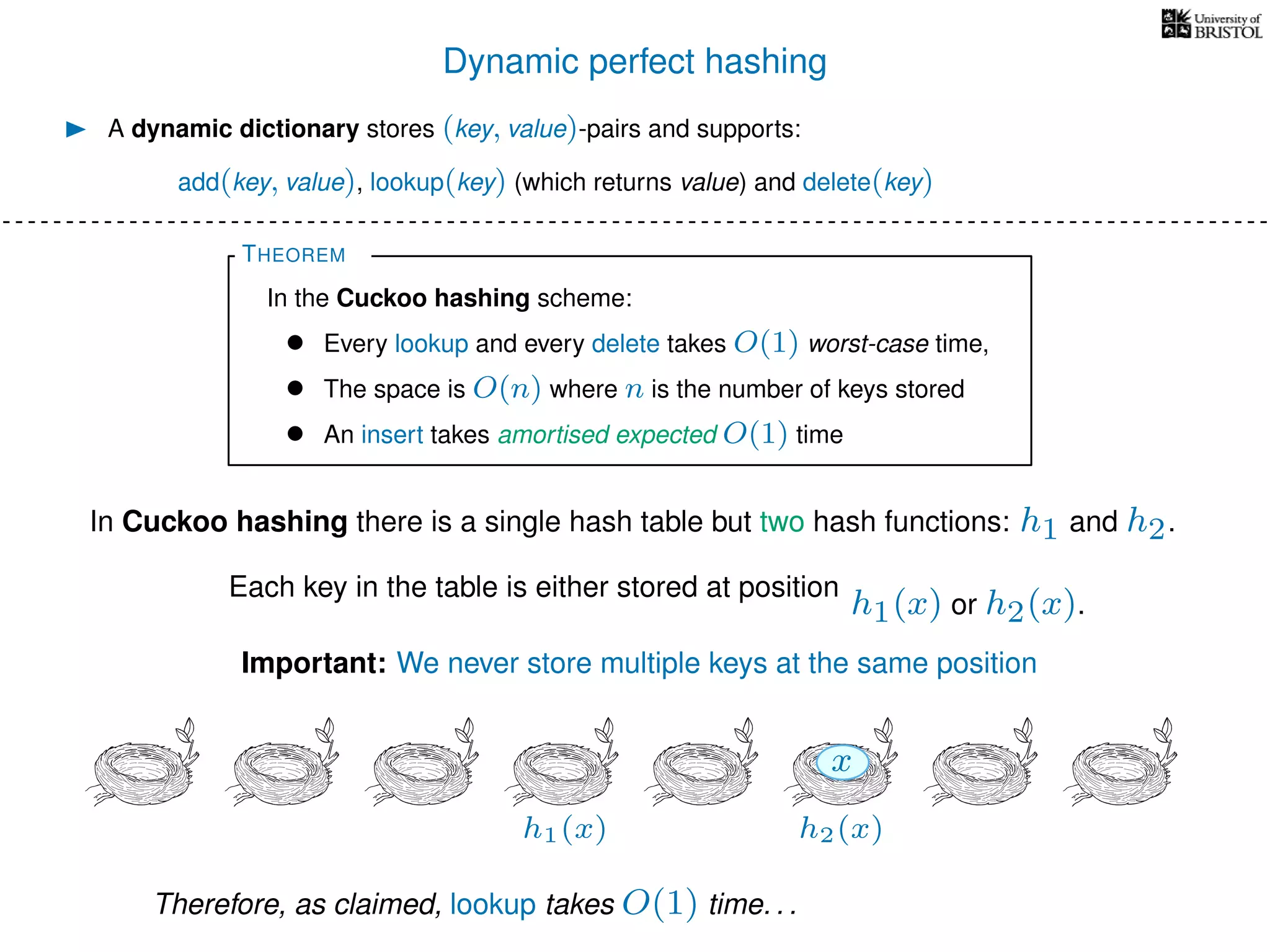
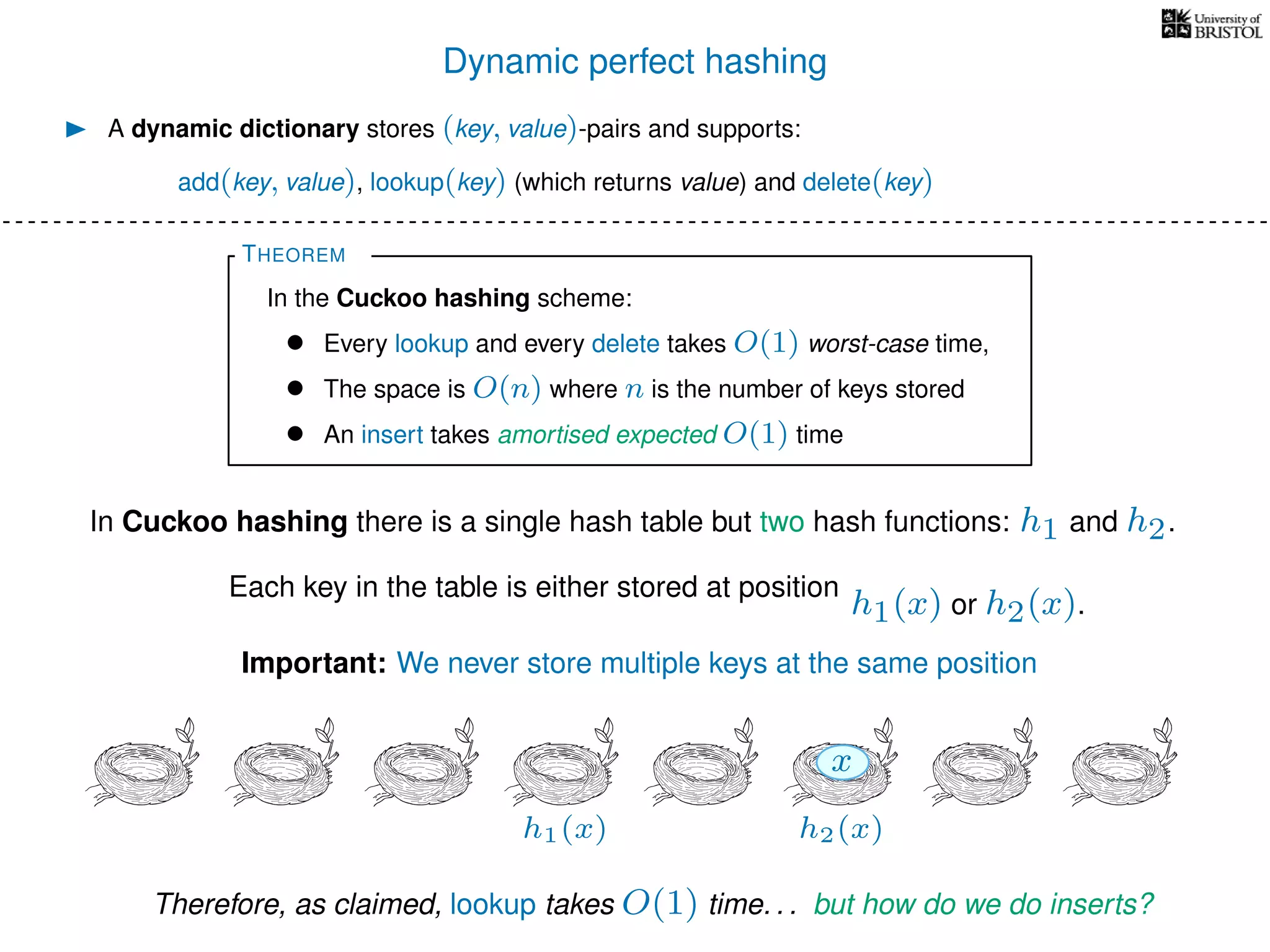
The document discusses cuckoo hashing as a method for dynamic dictionaries that store key-value pairs while supporting efficient operations like addition, lookup, and deletion. It details the expected runtime of these operations as O(1) using weakly universal hashing and highlights that in this scheme, every lookup and delete takes O(1) worst-case time with space complexity of O(n). Additionally, it explains the concept of amortized expected time for insertions and the role of multiple hash functions in cuckoo hashing.




![Pseudocode
h1(x) h2(x)
h1(y) h2(y)
yx
z
h1(z)h2(z)
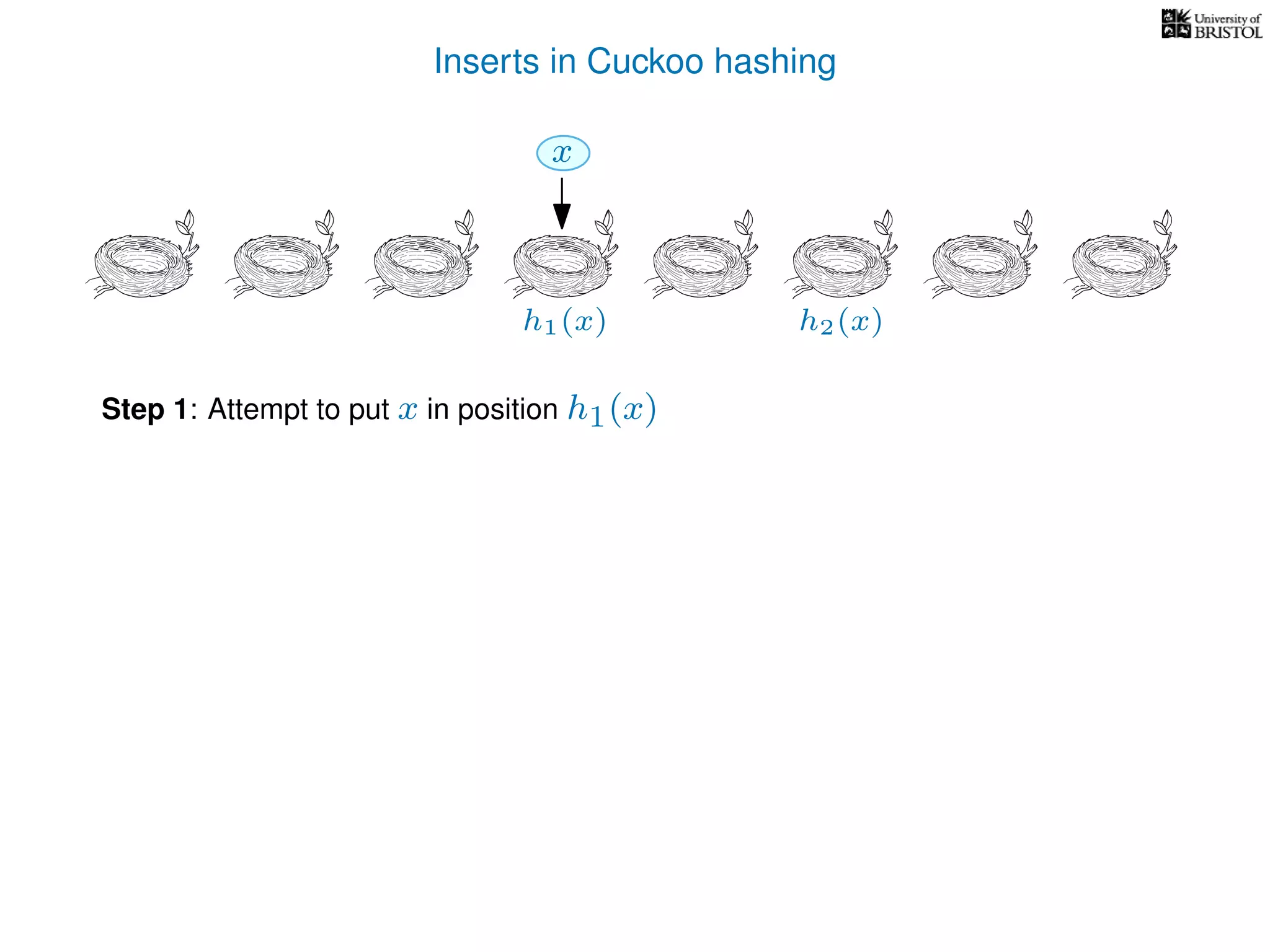
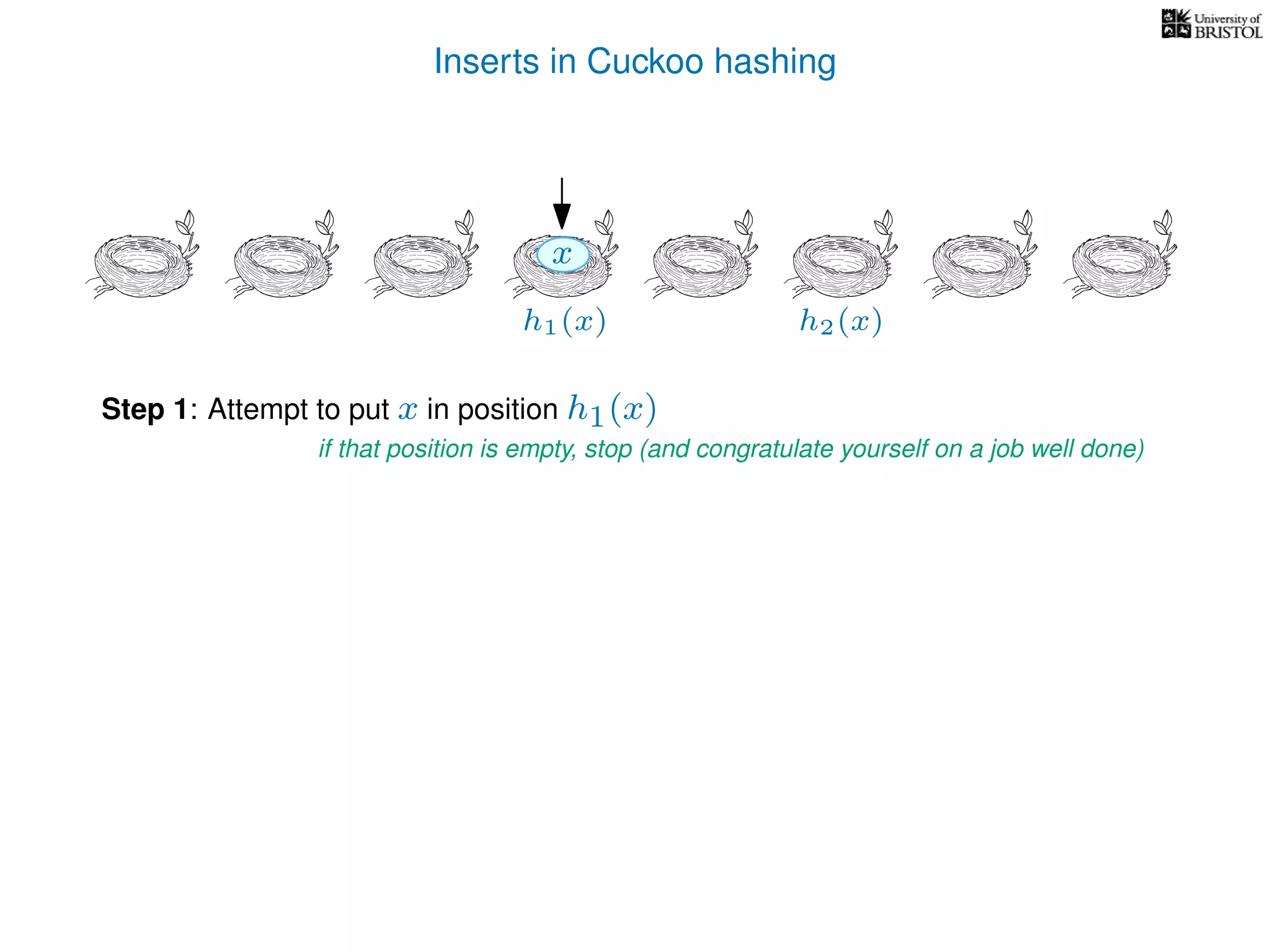
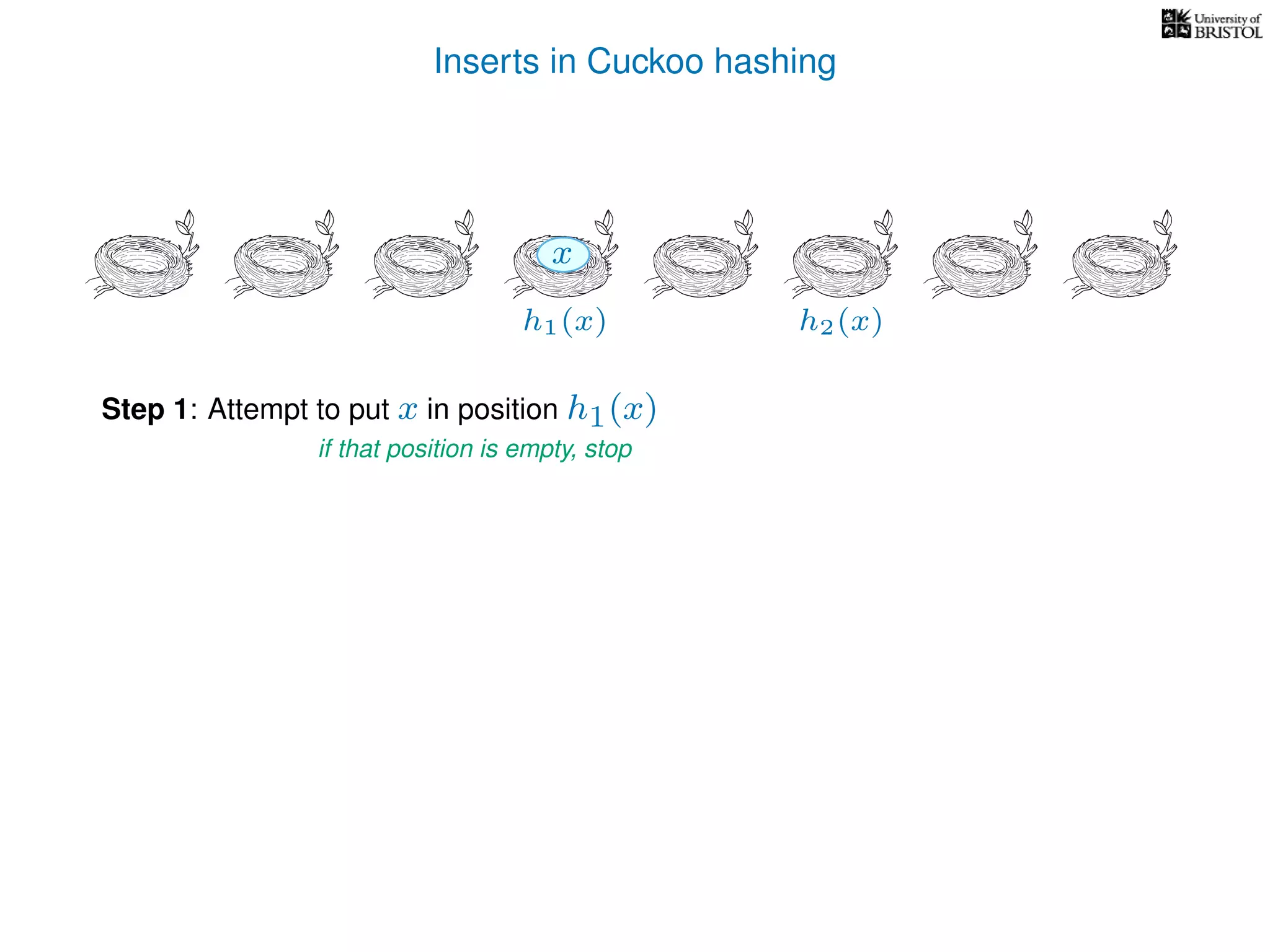
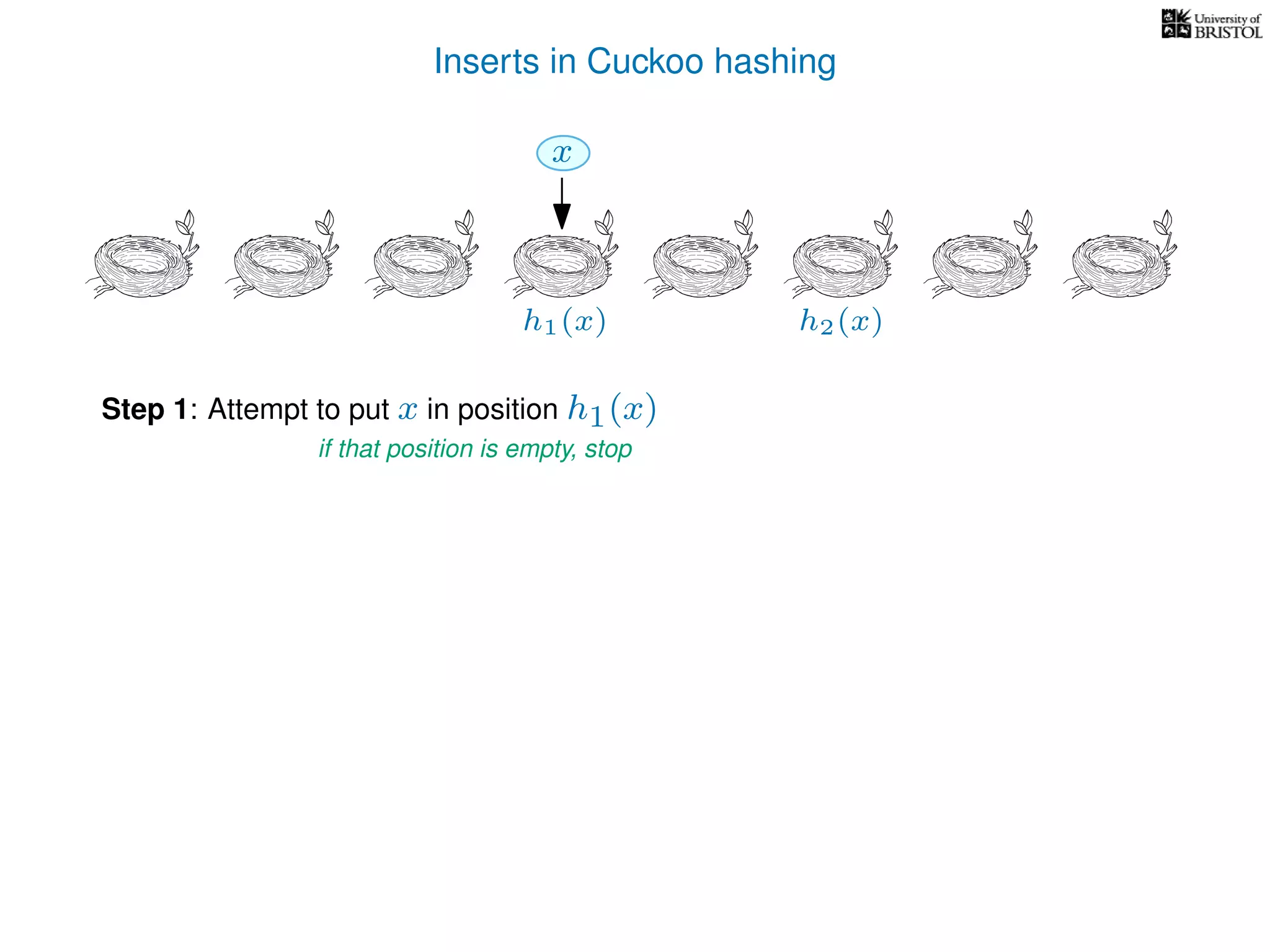
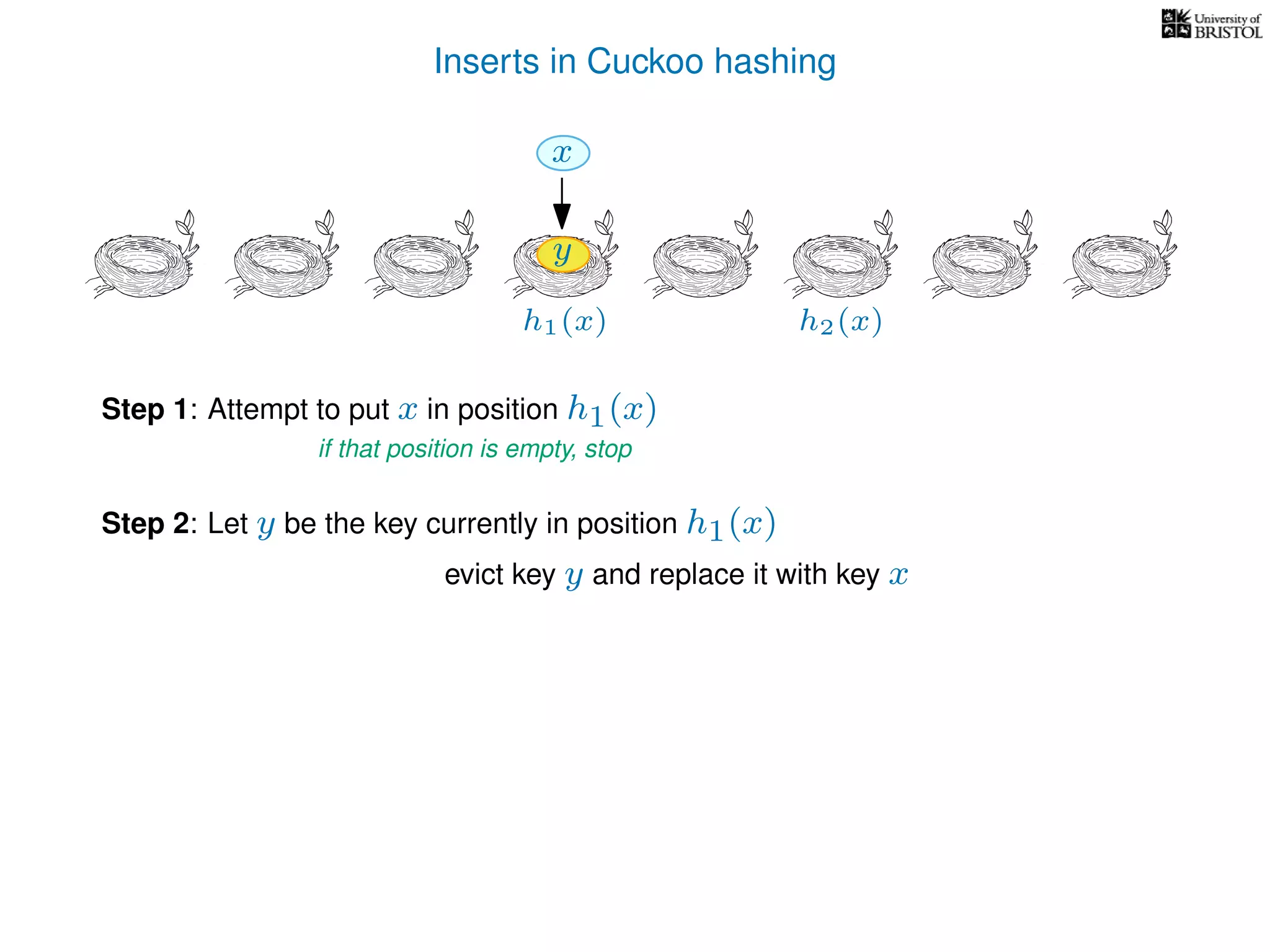
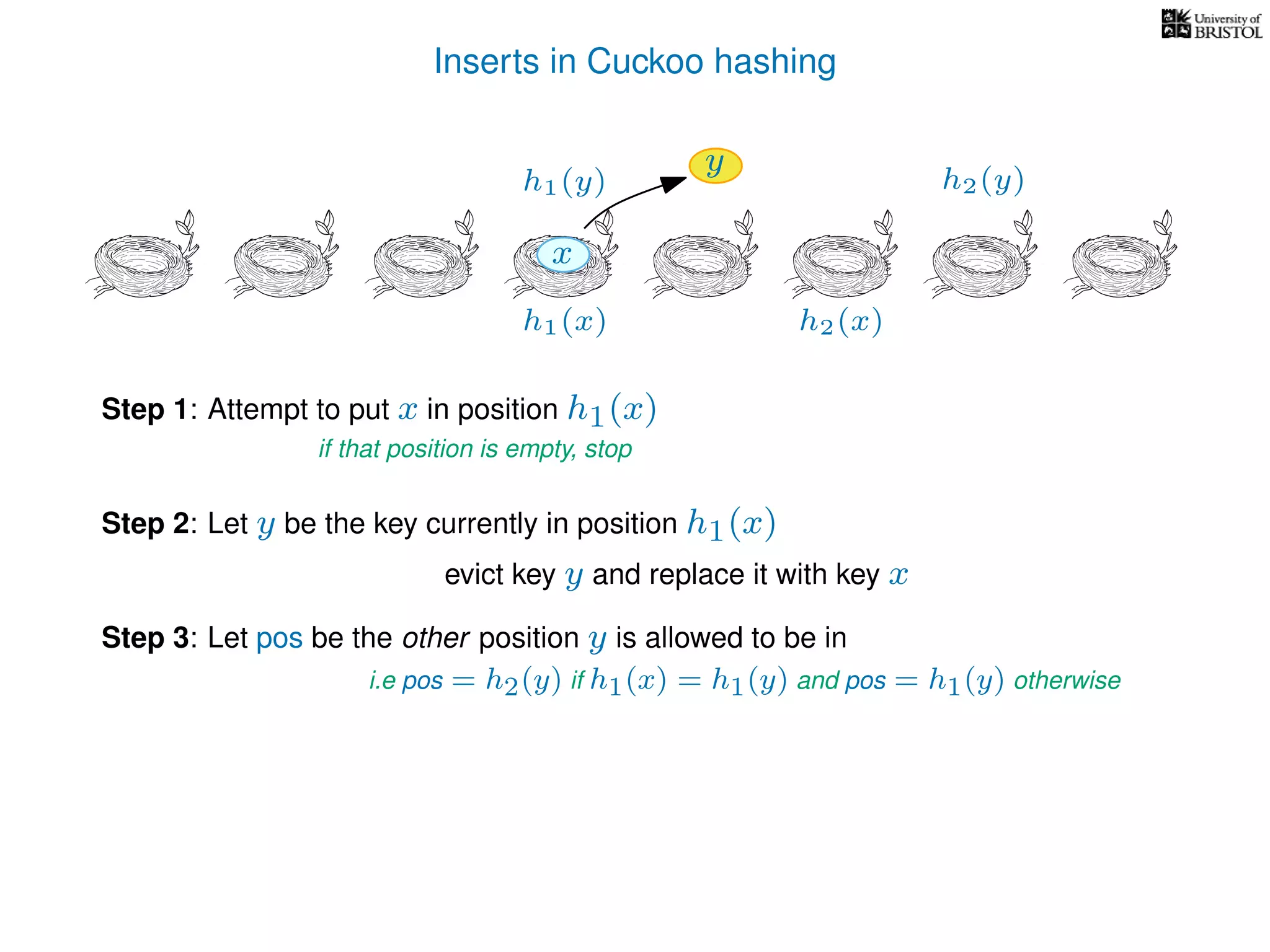
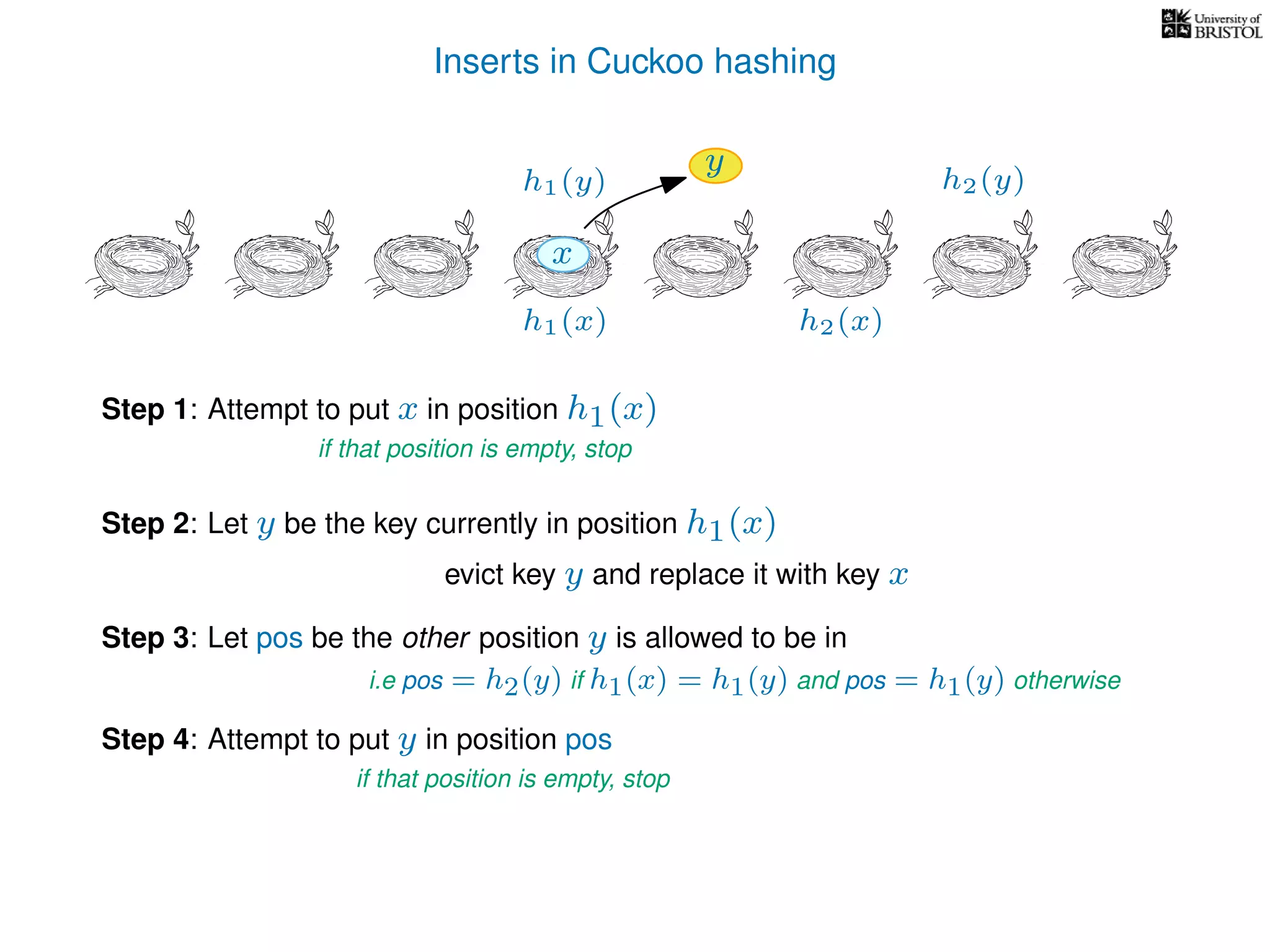
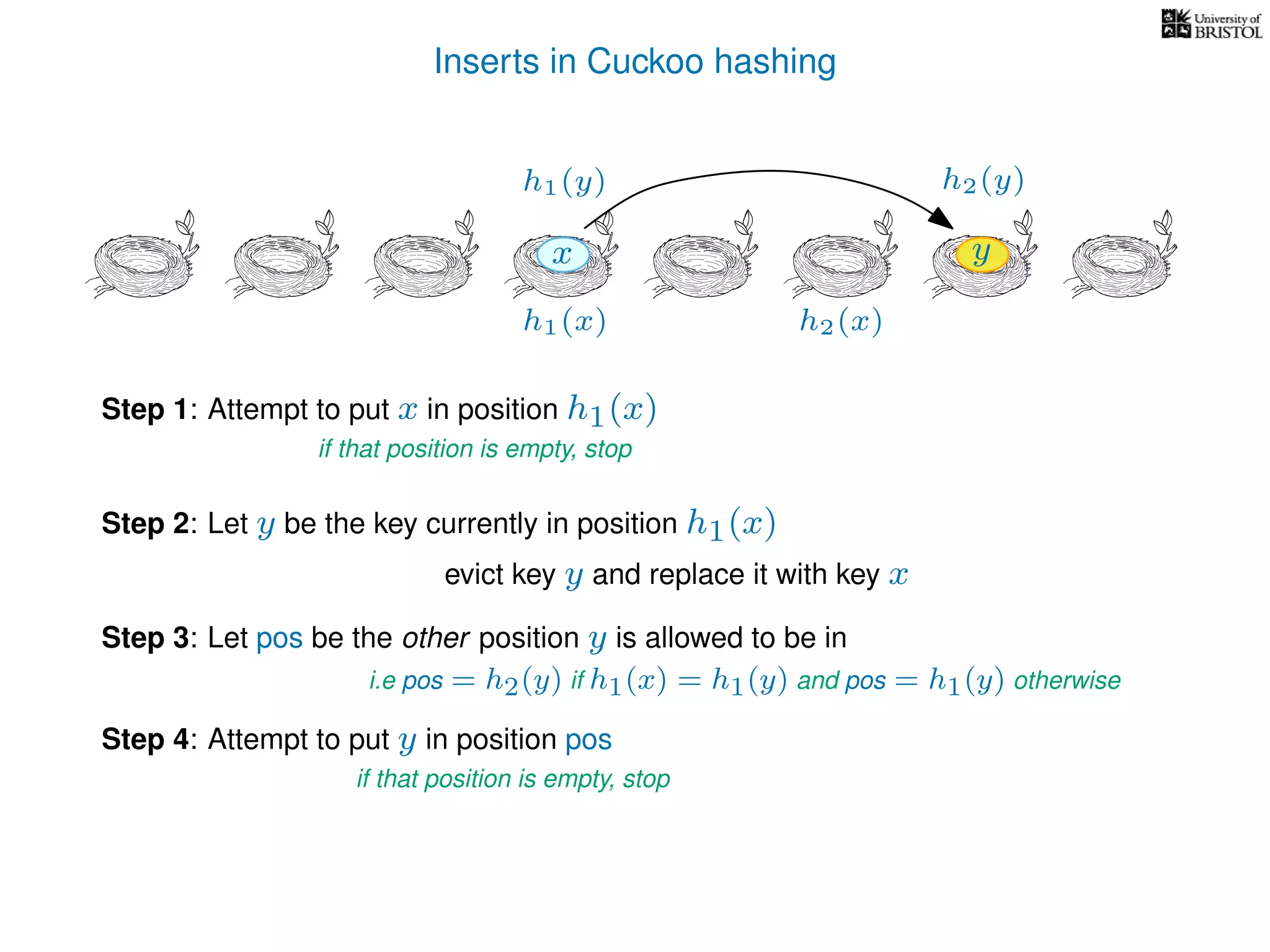
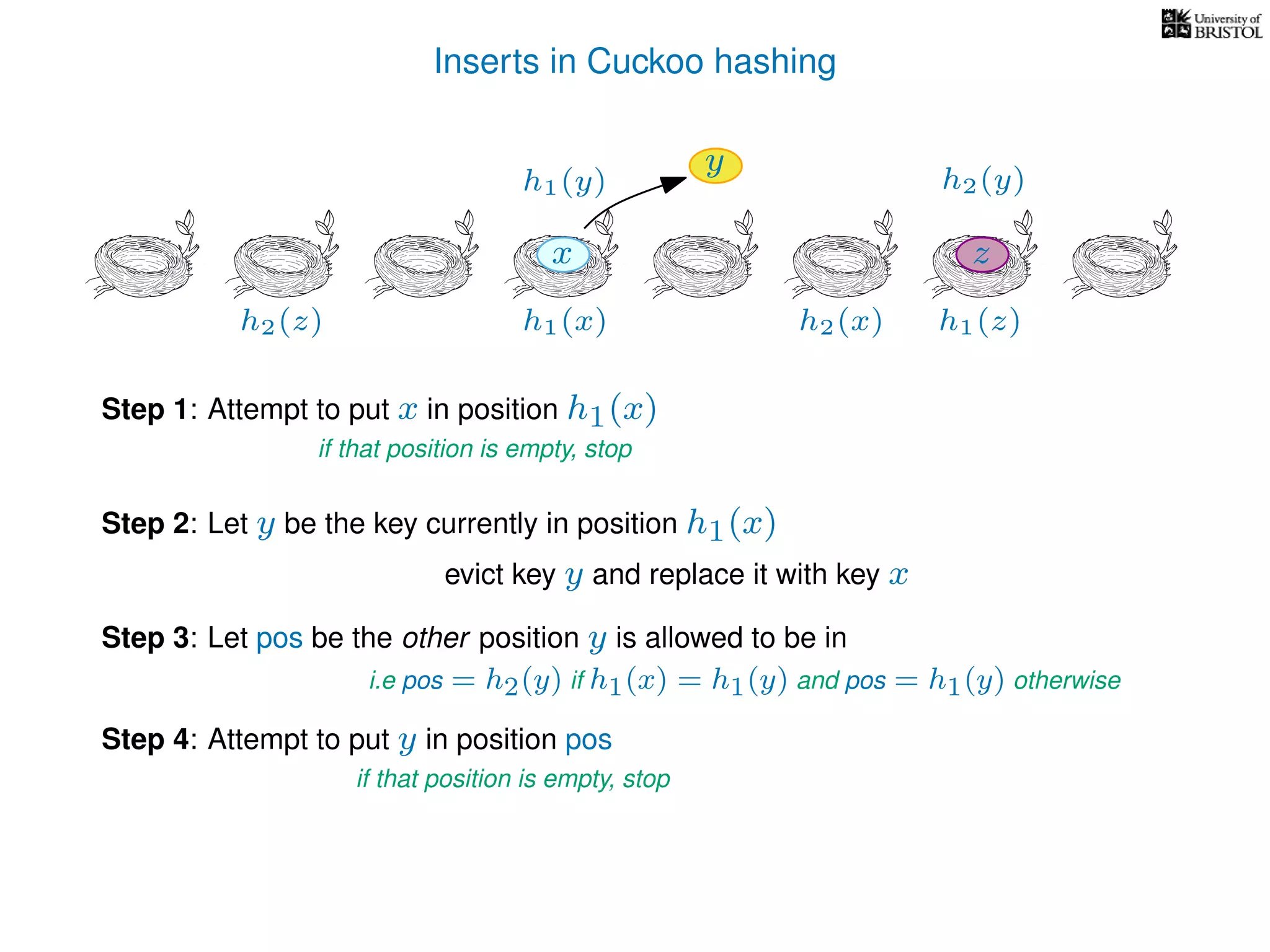
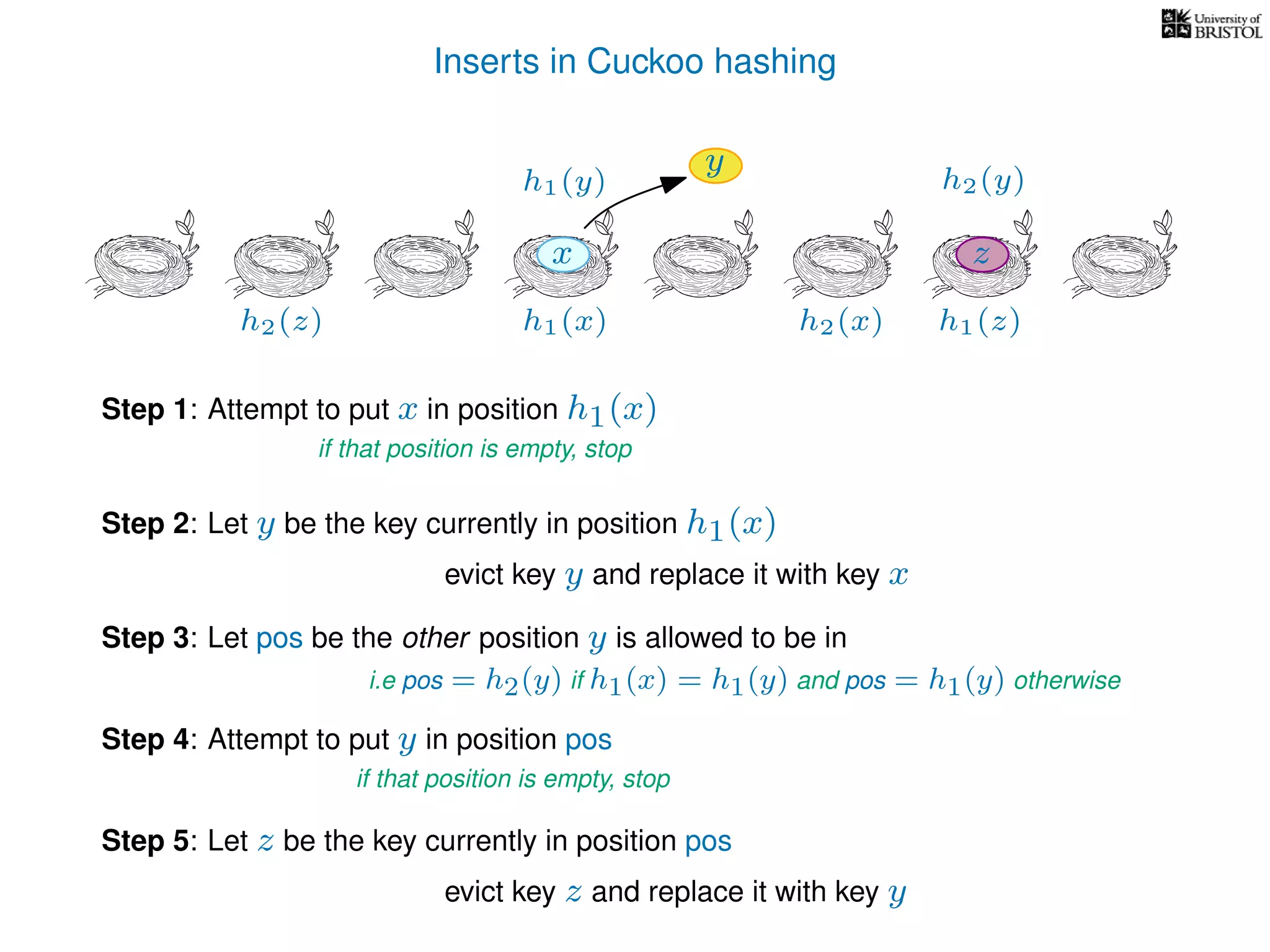
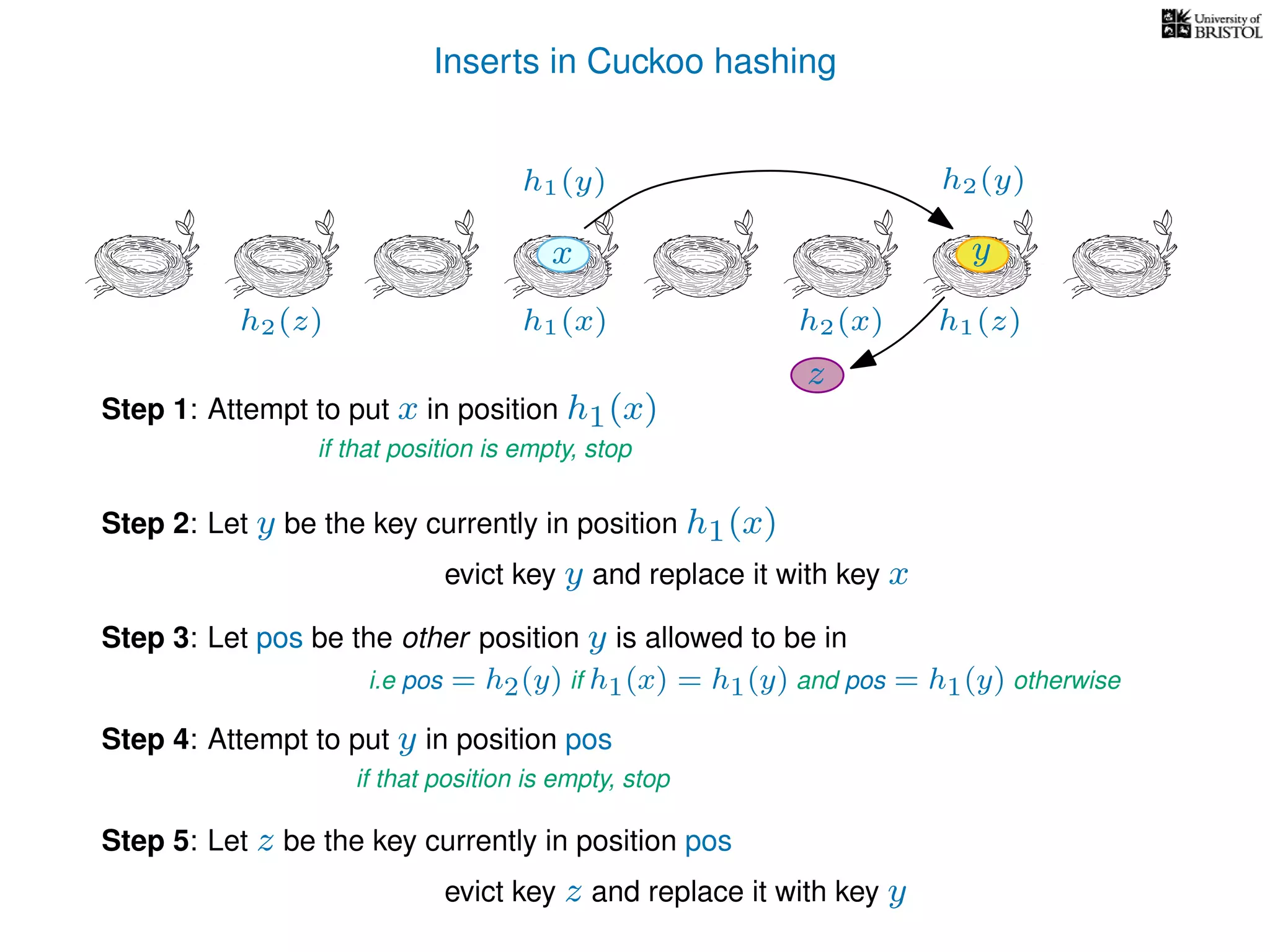
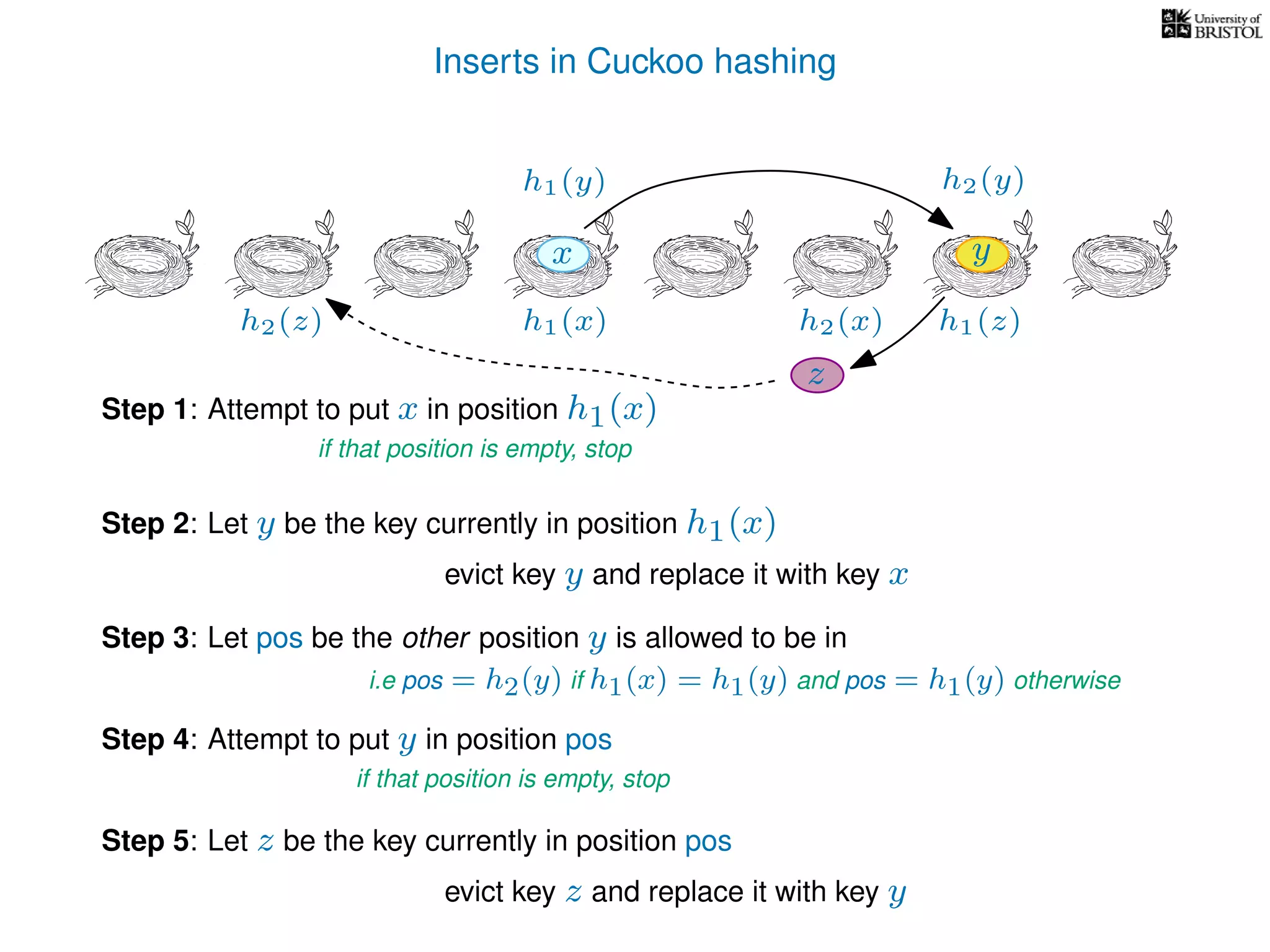
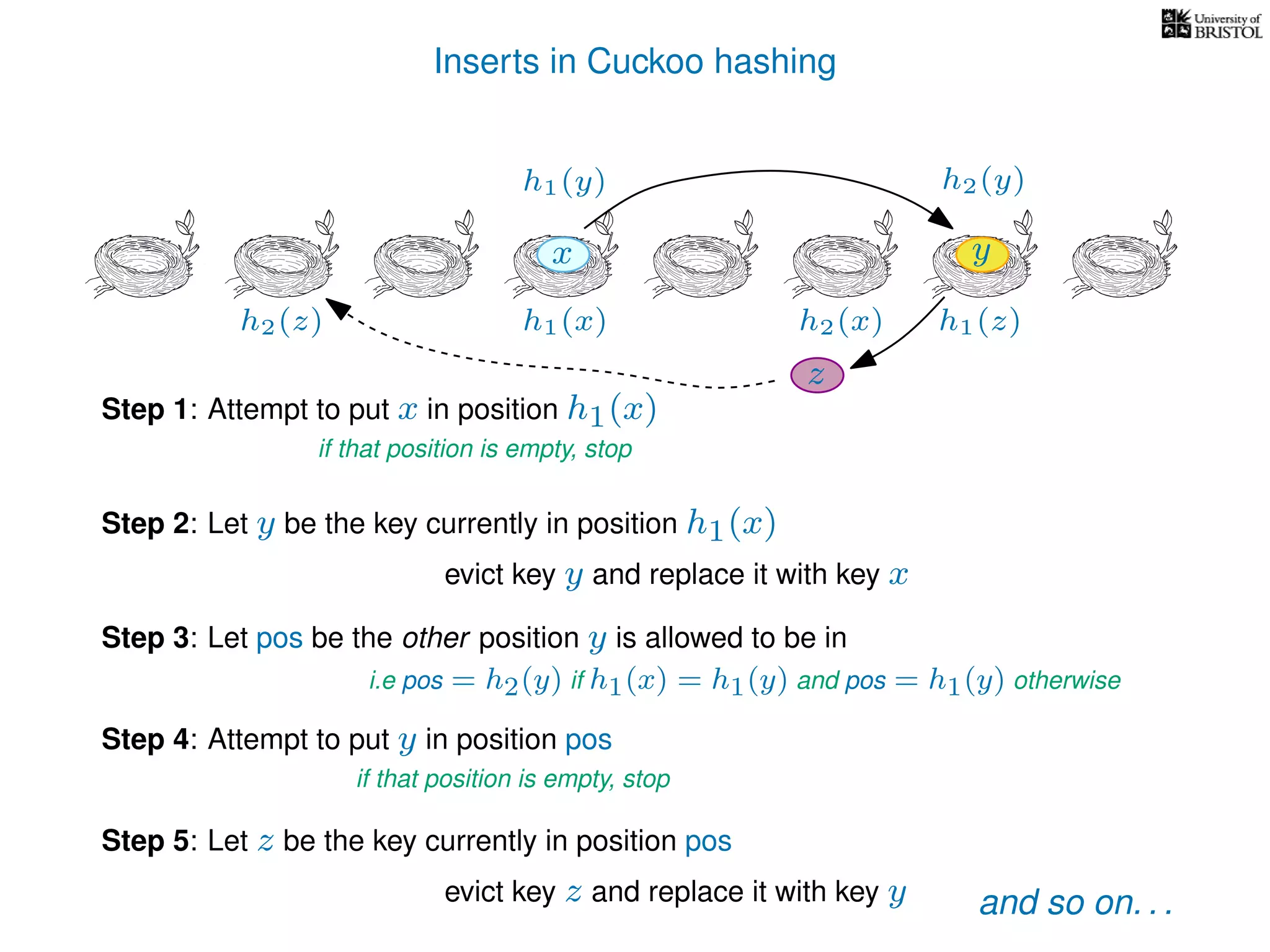
add(x):
pos ← h1(x)
Repeat at most n times:
If T[pos] is empty then T[pos] ← x.
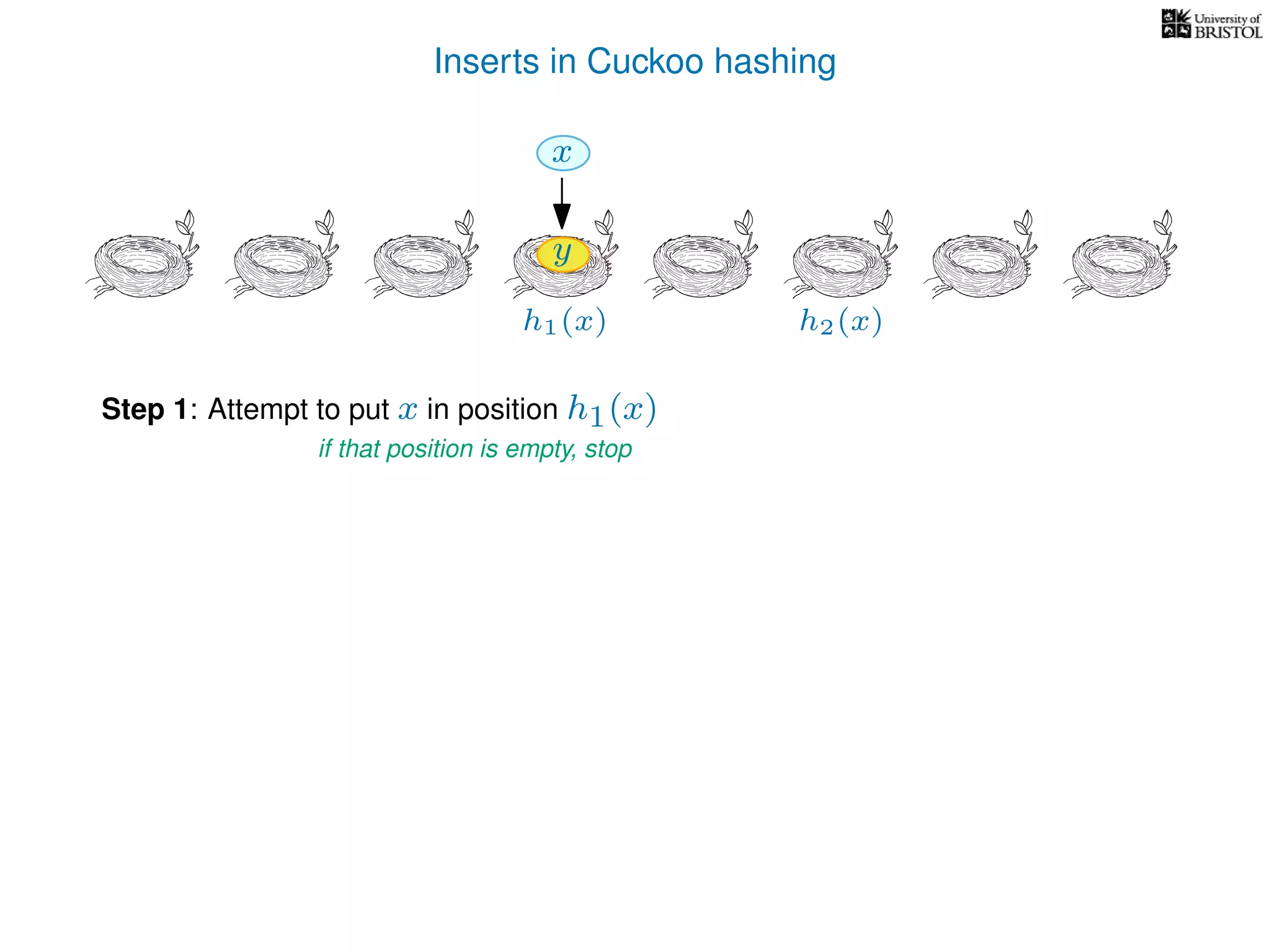
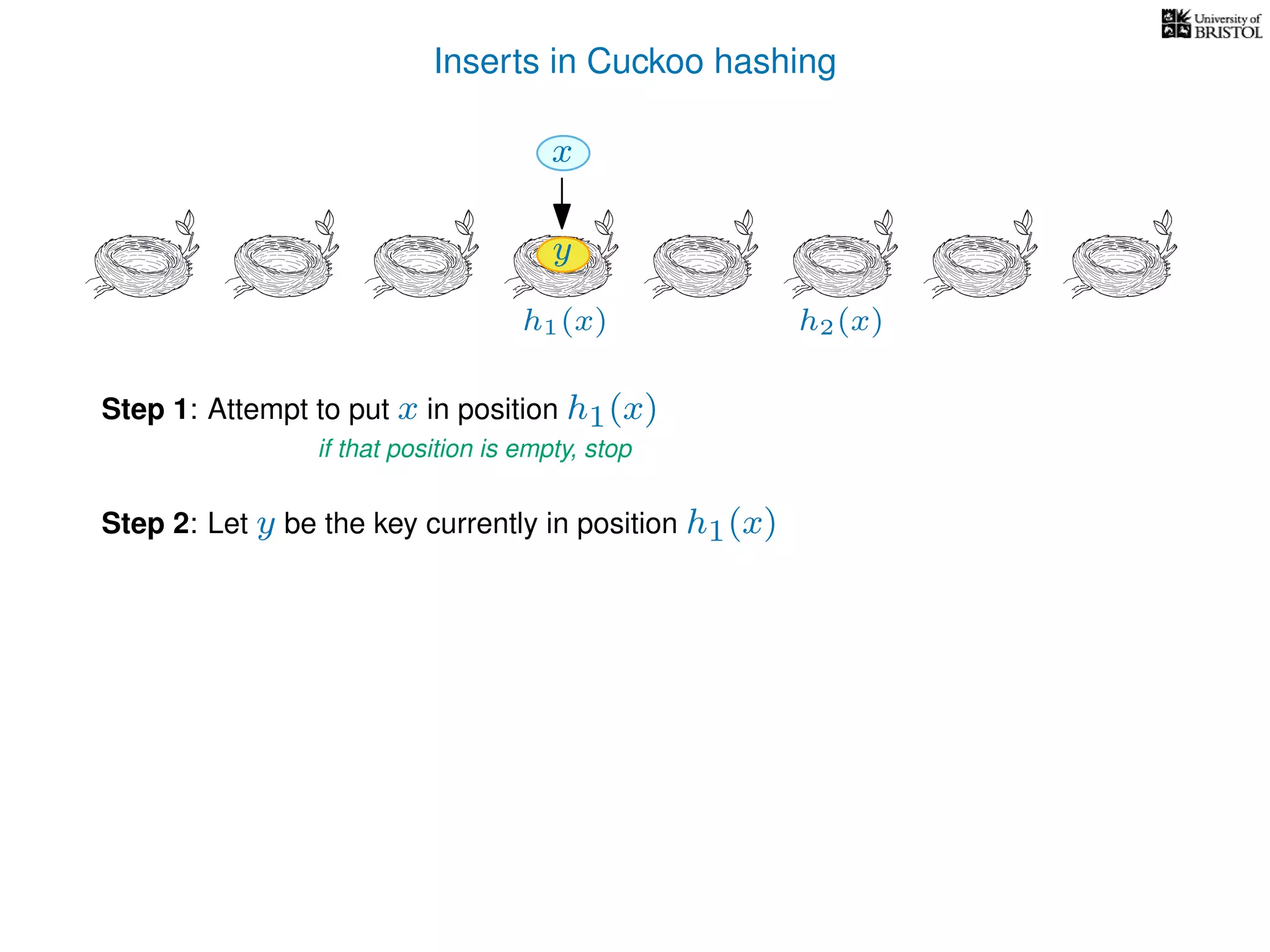
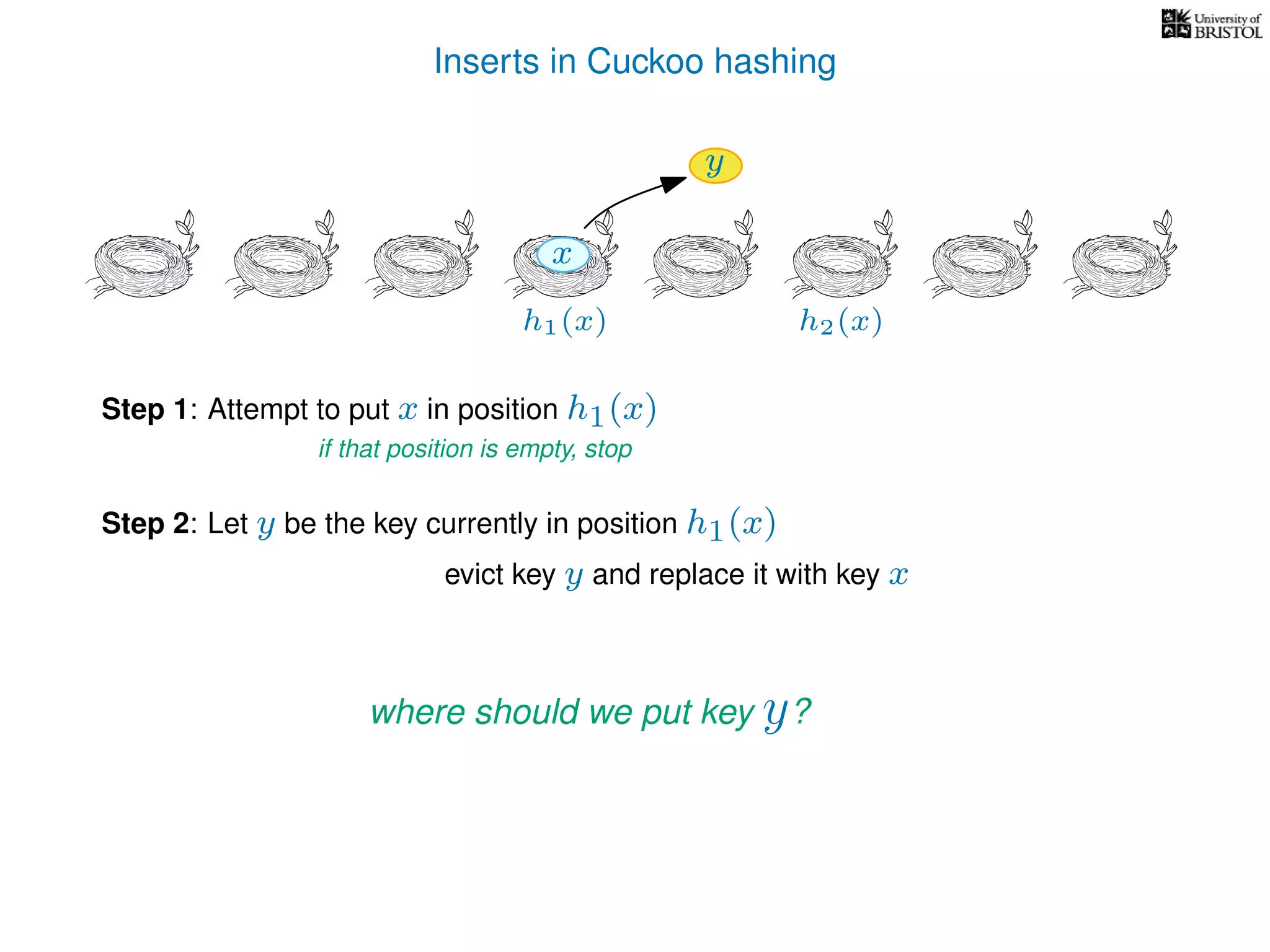
Otherwise,
y ← T[pos],
T[pos] ← x,
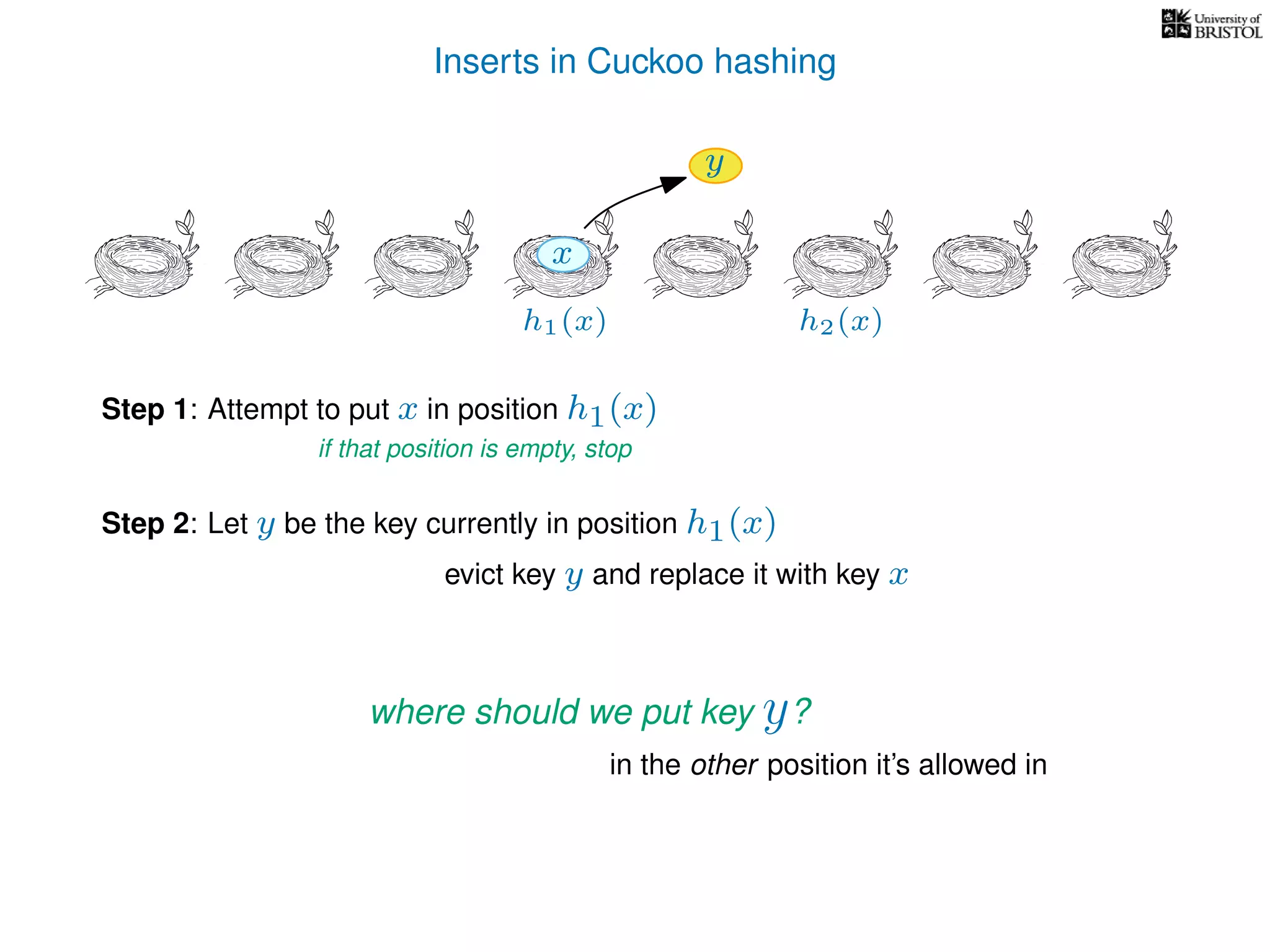
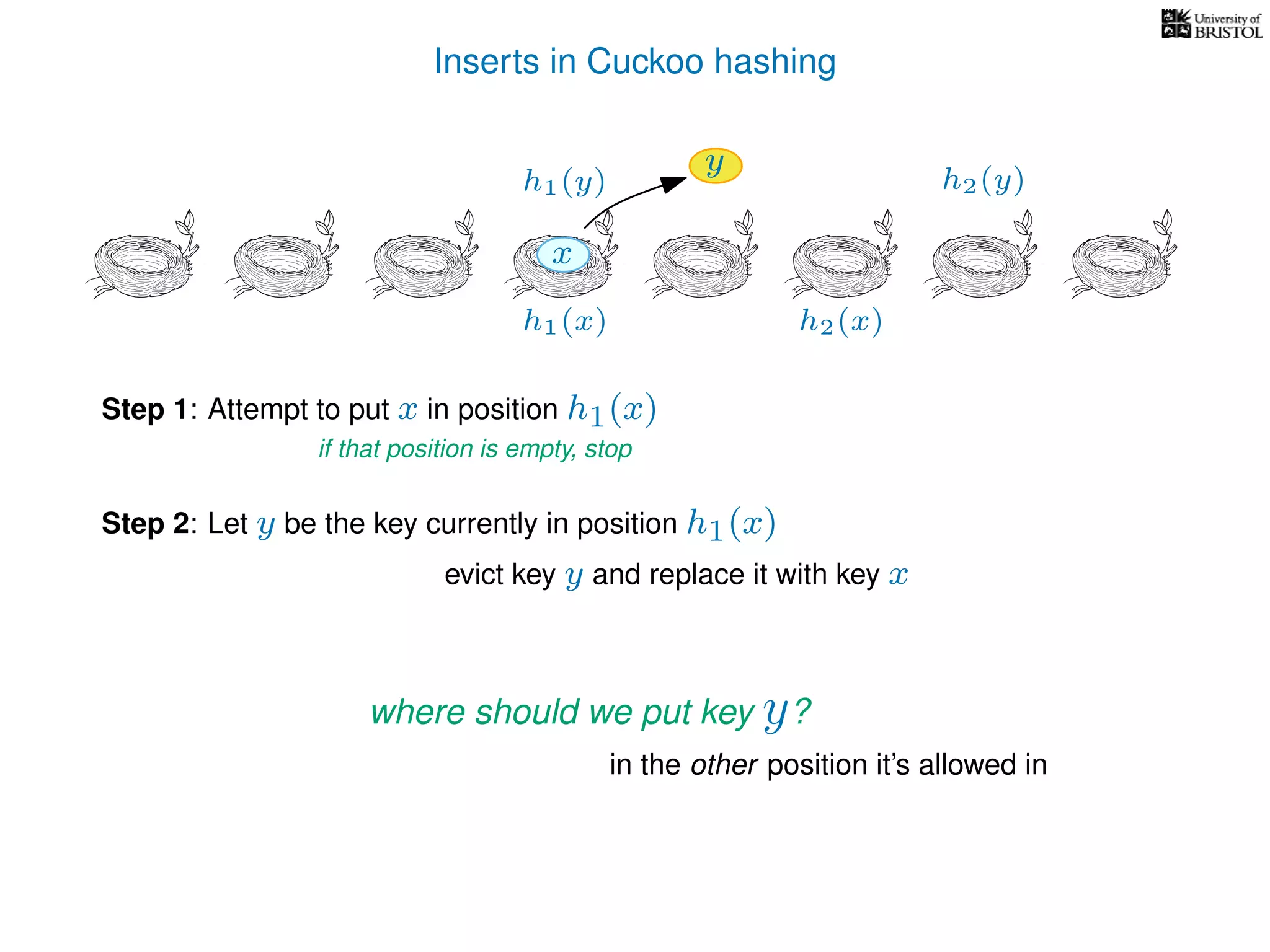
pos ← the other possible location for y.
(i.e. if y was evicted from h1(y) then pos ← h2(y), otherwise pos ← h1(y).)
x ← y.
Repeat
Give up and rehash the whole table.
i.e. empty the table, pick two new hash functions and reinsert every key](https://image.slidesharecdn.com/aa-04-160916143736/75/Hashing-Part-Two-Cuckoo-Hashing-53-2048.jpg)