Download as PDF, PPTX



![© Cloudera, Inc. All rights reserved. 9© Cloudera, Inc. All rights reserved.
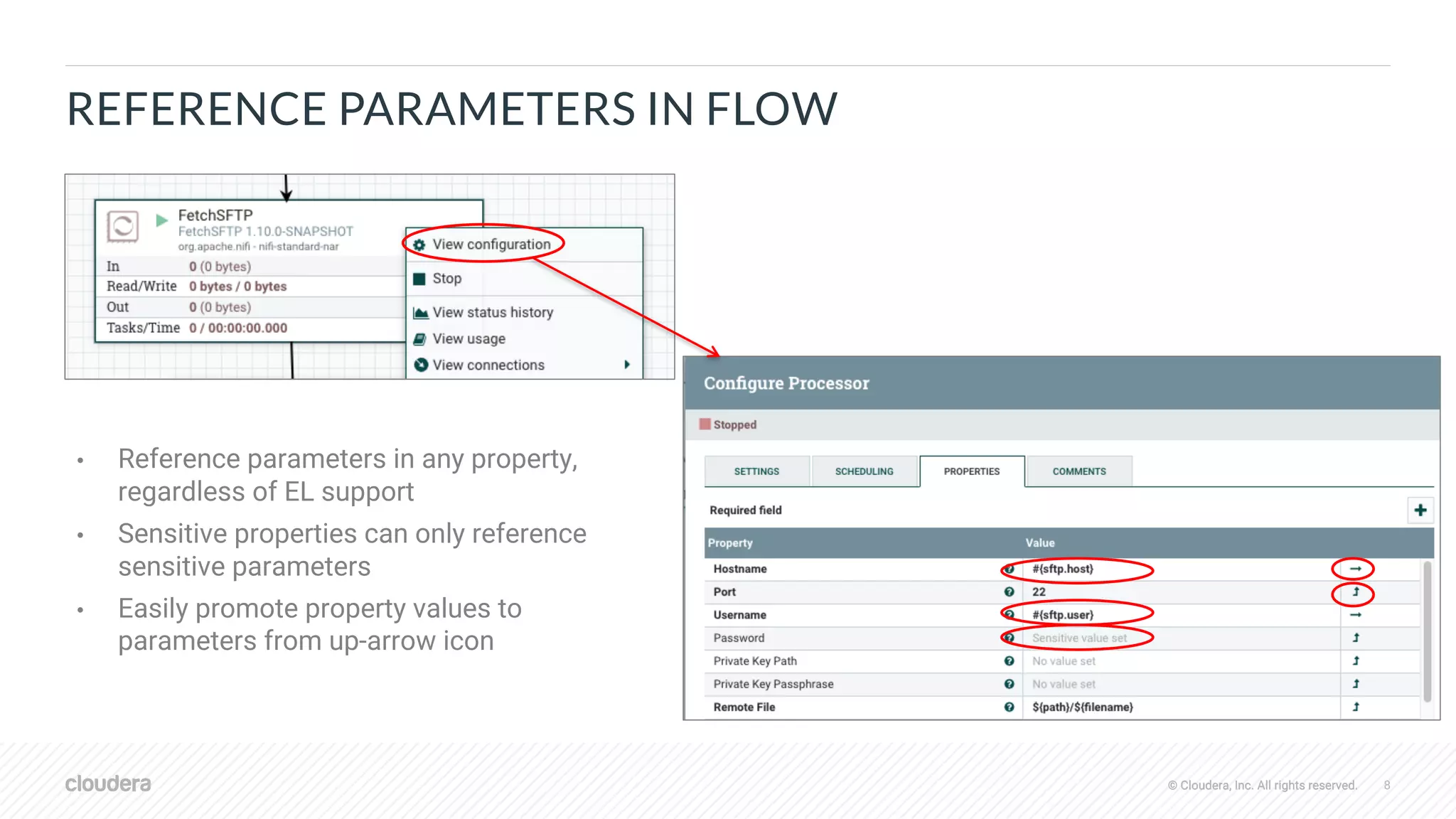
VERSION CONTROL FLOW WITH PARAMETERS
"parameterContexts" : {
"SFTP Params" : {
"name" : "SFTP Params",
"parameters" : [
{
"name" : "sftp.password",
"sensitive" : true
}, {
"name" : "sftp.host",
"sensitive" : false,
"value" : "localhost"
}, {
"name" : "sftp.user",
"sensitive" : false,
"value" : "myuser"
}
]
}
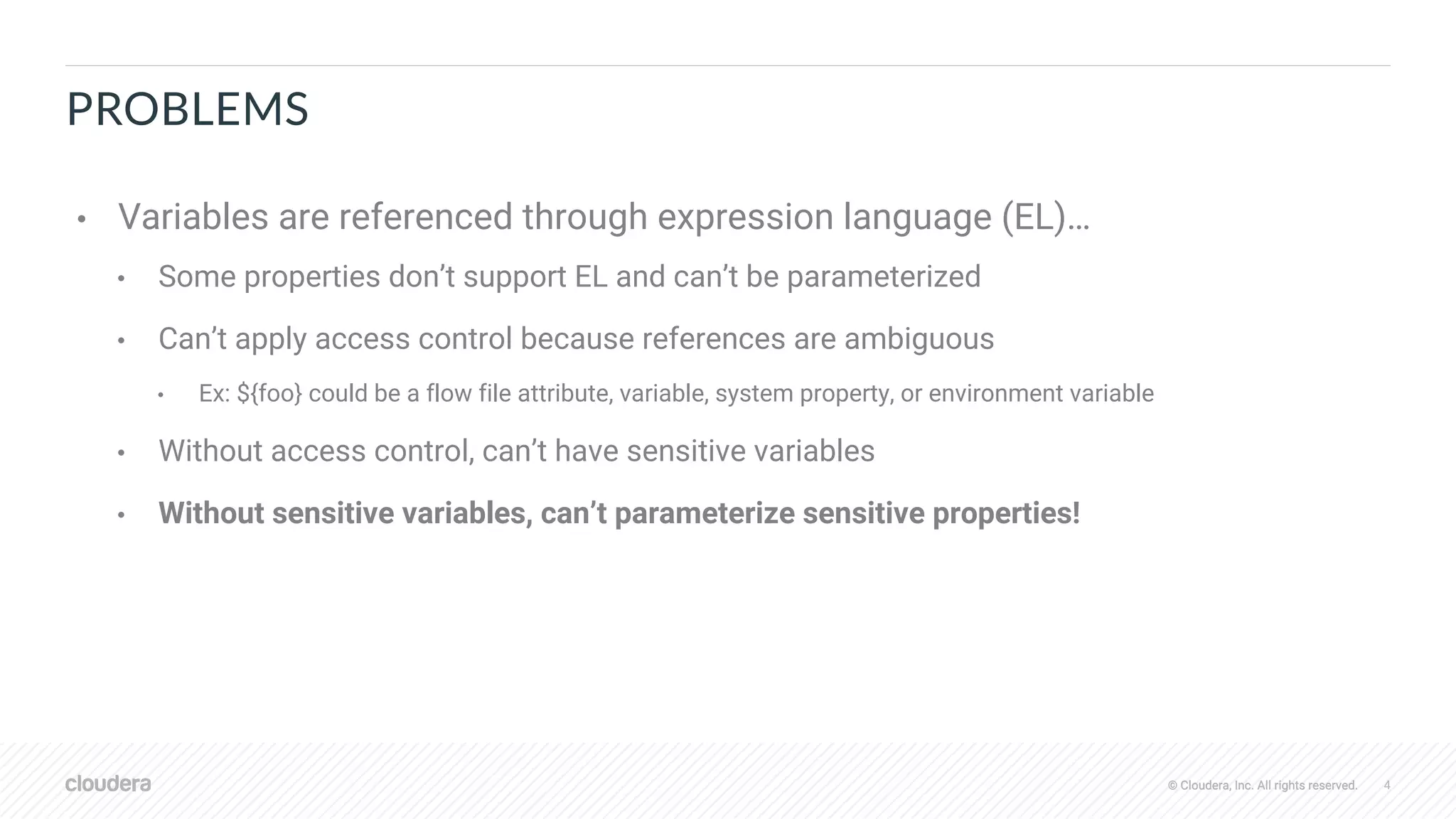
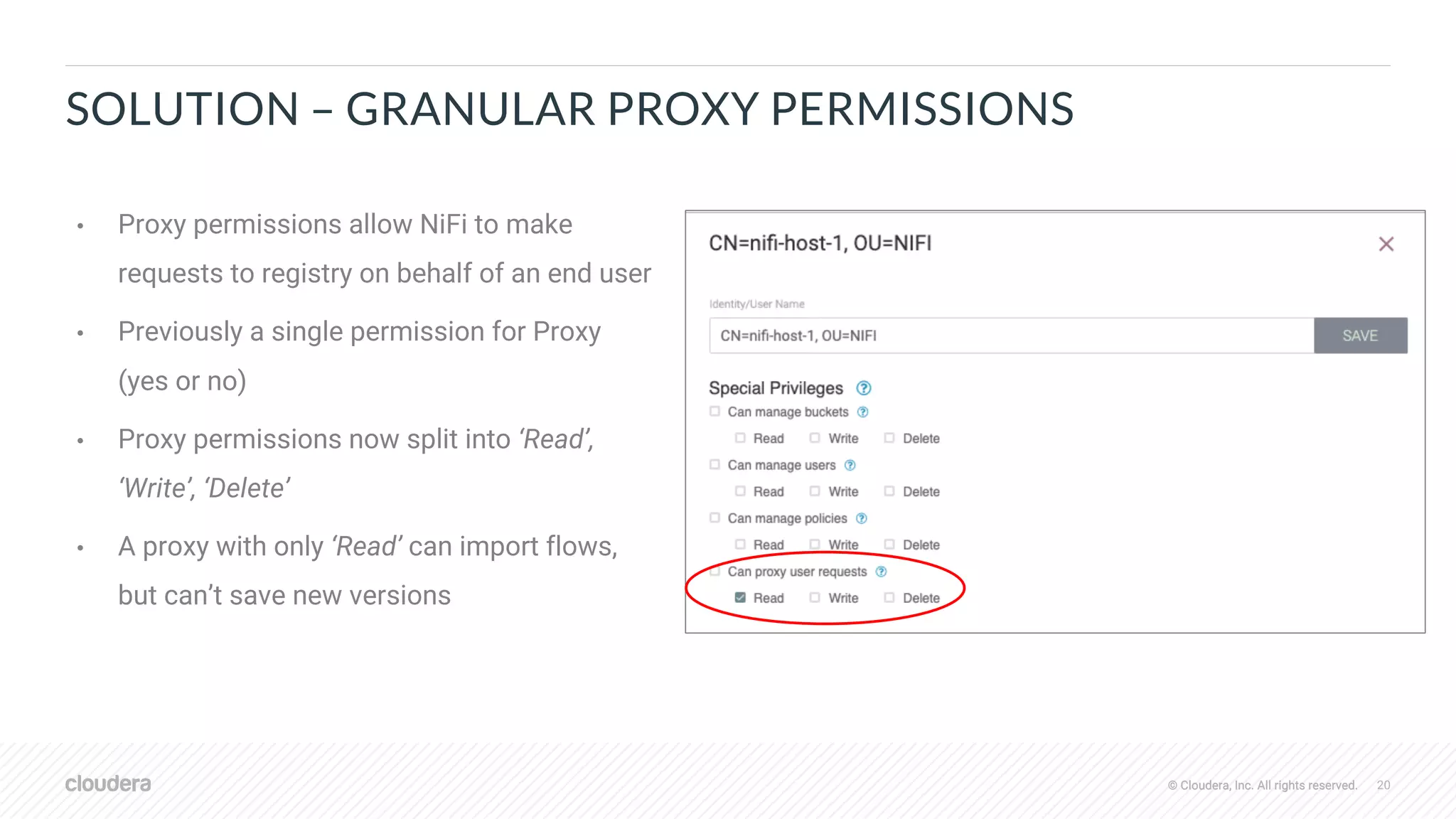
• Saved to registry with snapshots of referenced
parameter contexts
• Values of sensitive parameters scrubbed, set
once after importing to target environment
• Sensitive properties in versioned flow retain
parameter references like #{password}](https://image.slidesharecdn.com/2019-08-07-apache-nifi-sdlc-improvements-191104151405/75/Apache-NiFi-SDLC-Improvements-9-2048.jpg)








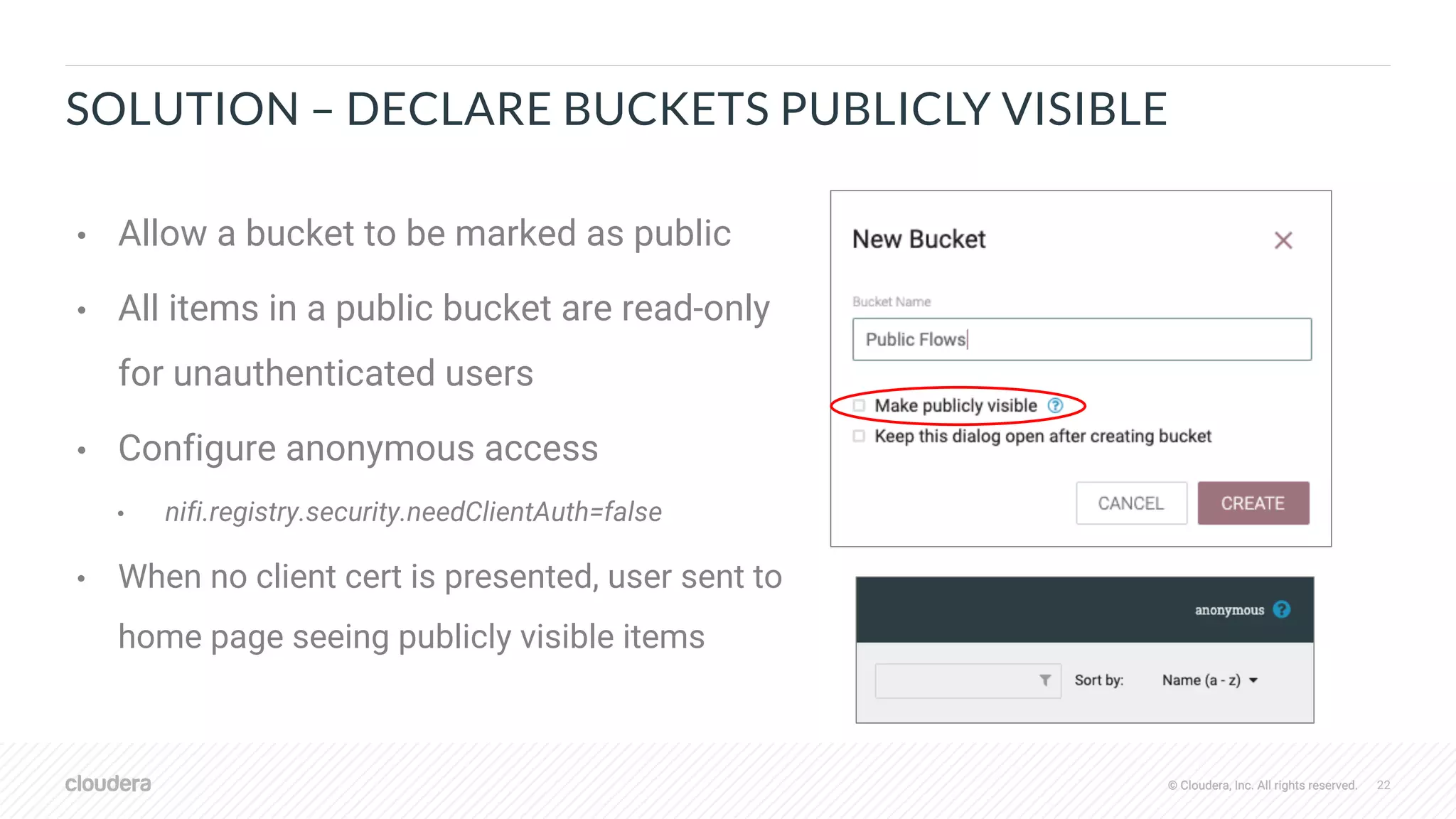





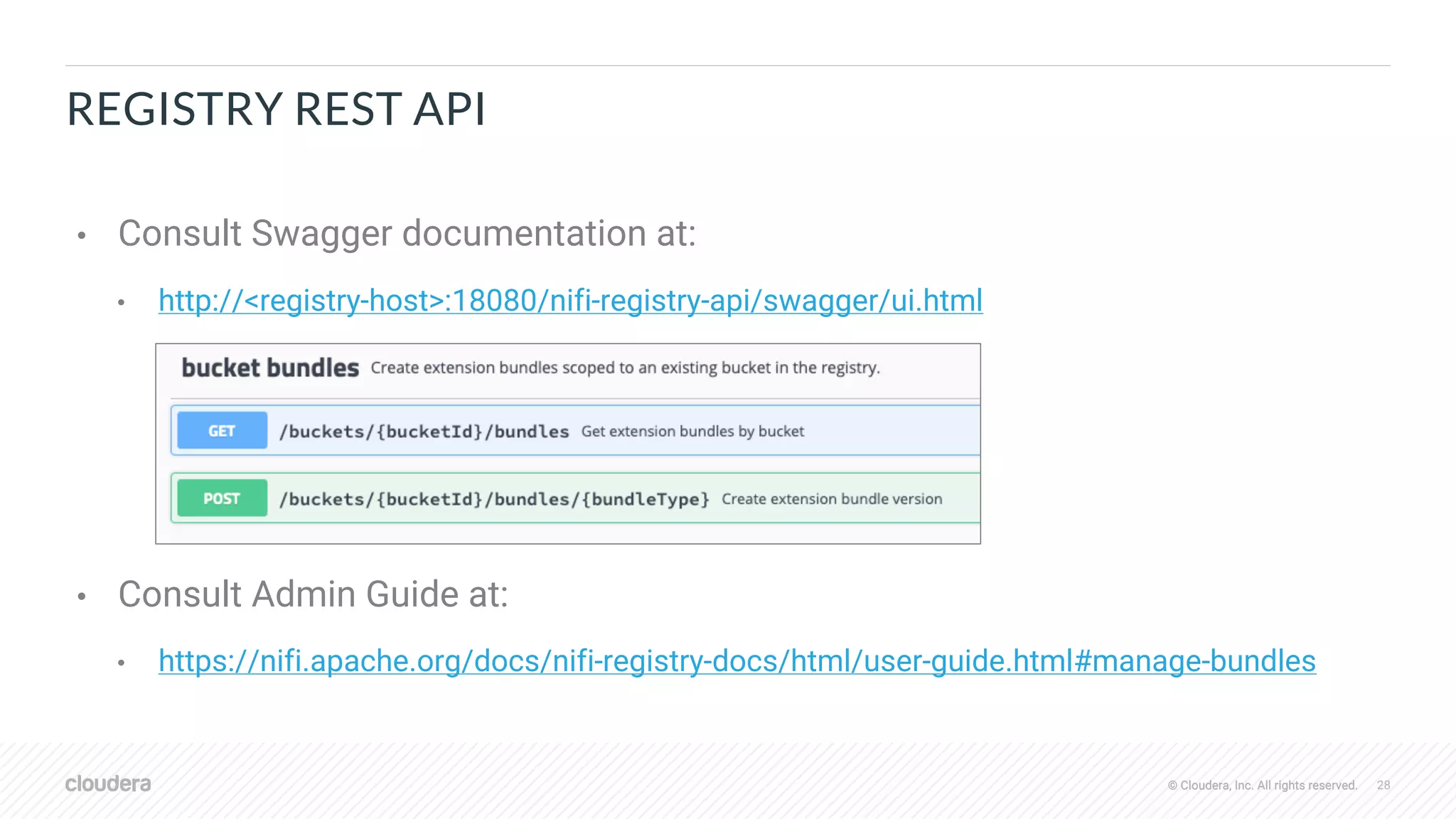
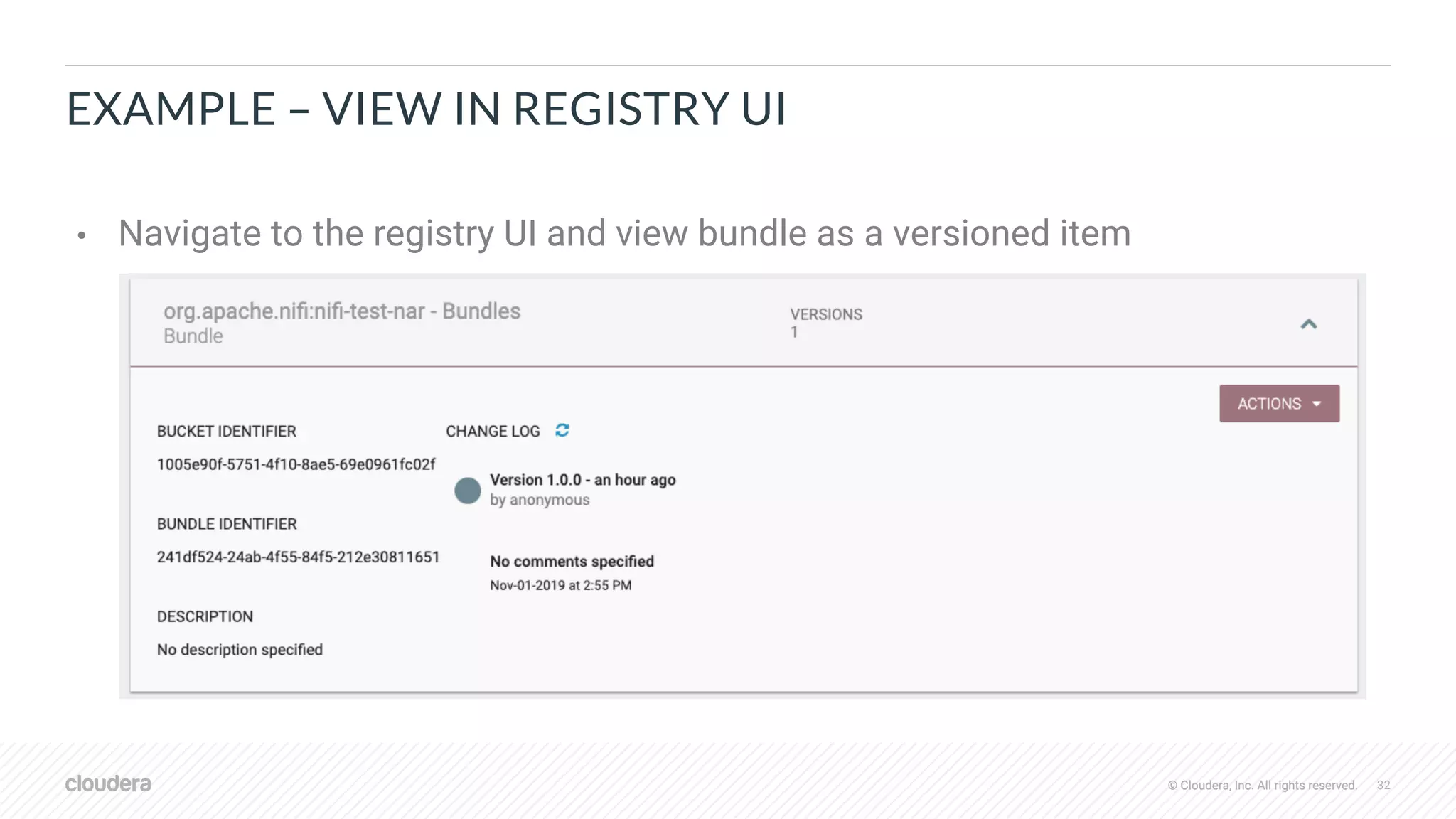
![© Cloudera, Inc. All rights reserved. 30© Cloudera, Inc. All rights reserved.
EXAMPLE – GENERATE AND BUILD NAR
mvn archetype:generate
-DarchetypeGroupId=org.apache.nifi
-DarchetypeArtifactId=nifi-processor-bundle-archetype
-DarchetypeVersion=1.10.0
-DnifiVersion=1.10.0
Define value for property 'groupId': org.apache.nifi
Define value for property 'artifactId': nifi-test-bundle
Define value for property 'version' 1.0-SNAPSHOT: : 1.0.0
Define value for property 'artifactBaseName': test
Define value for property 'package' org.apache.nifi.processors.test: :
cd nifi-test-bundle
mvn clean package
[1] https://cwiki.apache.org/confluence/display/NIFI/Maven+Projects+for+Extensions](https://image.slidesharecdn.com/2019-08-07-apache-nifi-sdlc-improvements-191104151405/75/Apache-NiFi-SDLC-Improvements-30-2048.jpg)





The document discusses improvements to Apache NiFi and NiFi Registry for software development lifecycles. Key improvements include: 1) Parameterized flows in NiFi that allow sensitive values to be parameterized and referenced securely. 2) Version control improvements like forcing commits and tracking component enable/disable state. 3) Granular proxy permissions and public buckets in NiFi Registry for access control. 4) Versioning of extension bundles alongside flows in NiFi Registry.














































































