Download to read offline





![© Copyright 2020 Xilinx
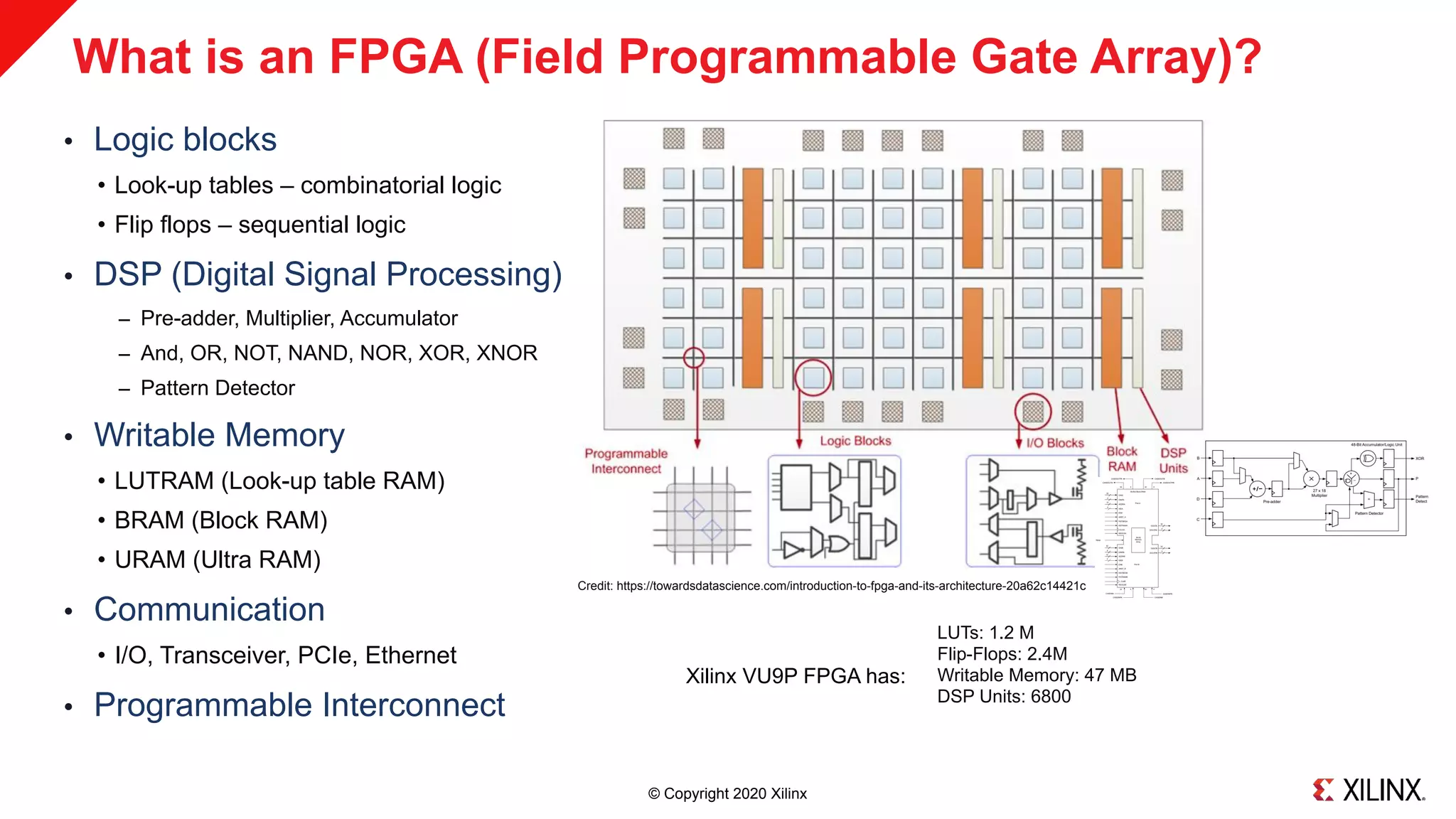
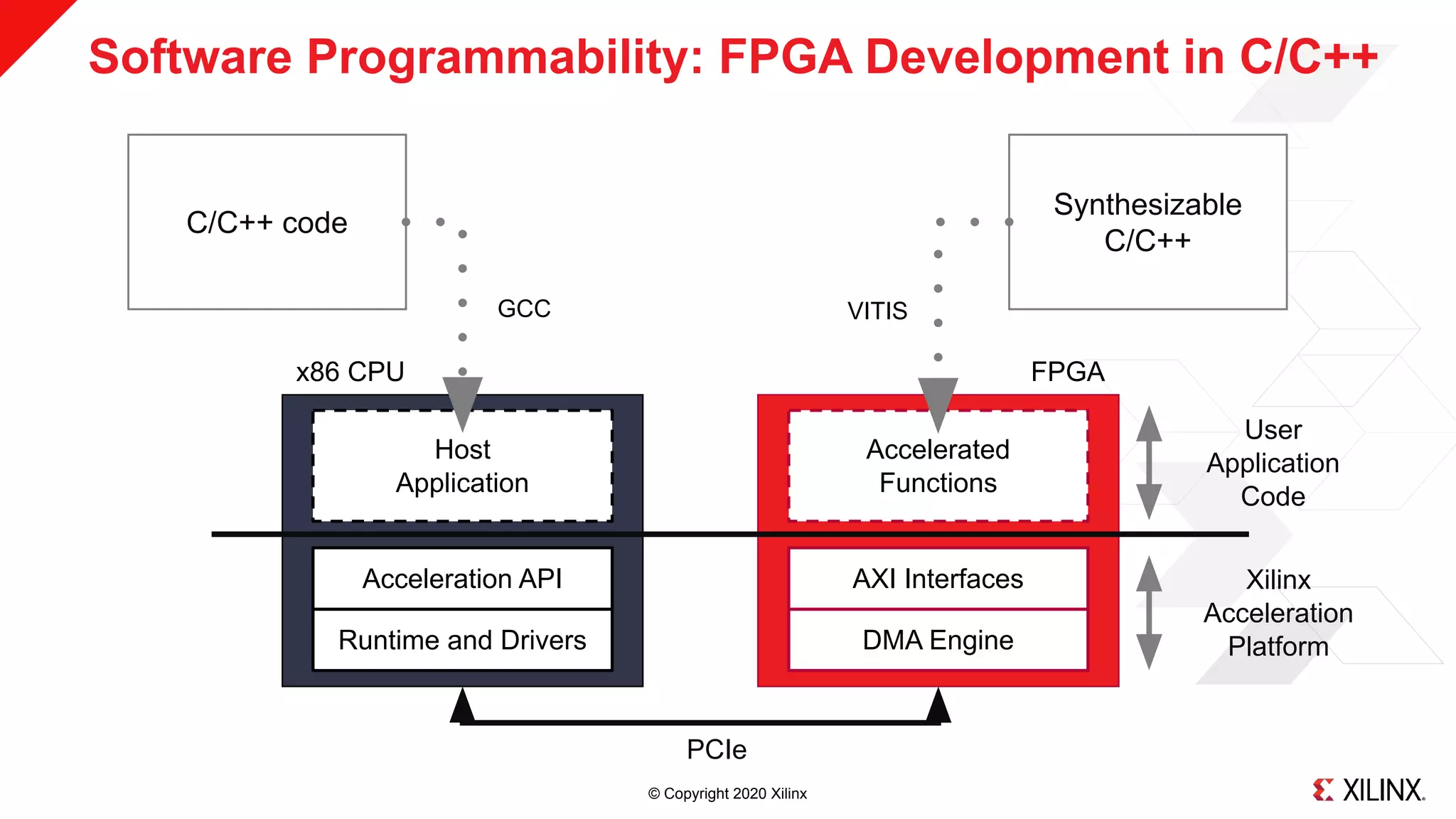
Using C, C++ or OpenCL to Program FPGAs
˃ Xilinx pioneered C to FPGA compilation technology (aka “HLS”) in 2011
˃ No need for low-level hardware description languages
˃ FPGAs are “Software Programmable”
loop_main:for(int j=0;j<NUM_SIMGROUPS;j+=2) {
loop_share:for(uint k=0;k<NUM_SIMS;k++) {
loop_parallel:for(int i=0;i<NUM_RNGS;i++) {
mt_rng[i].BOX_MULLER(&num1[i][k],&num2[i][k],ratio4,ratio3);
float payoff1 = expf(num1[i][k])-1.0f;
float payoff2 = expf(num2[i][k])-1.0f;
if(num1[i][k]>0.0f)
pCall1[i][k]+= payoff1;
else
pPut1[i][k]-=payoff1;
if(num2[i][k]>0.0f)
pCall2[i][k]+=payoff2;
else
pPut2[i][k]-=payoff2;
}
}
}
FPGAVitis Compiler (v++)](https://image.slidesharecdn.com/hardwareacceleratedmlsolutionatgraphaiworldfall20final-201210020226/75/Hardware-Accelerated-Machine-Learning-Solution-for-Detecting-Fraud-and-Money-Laundering-Rings-17-2048.jpg)
![© Copyright 2020 Xilinx
Coloring vertices
can relieve
dependencies
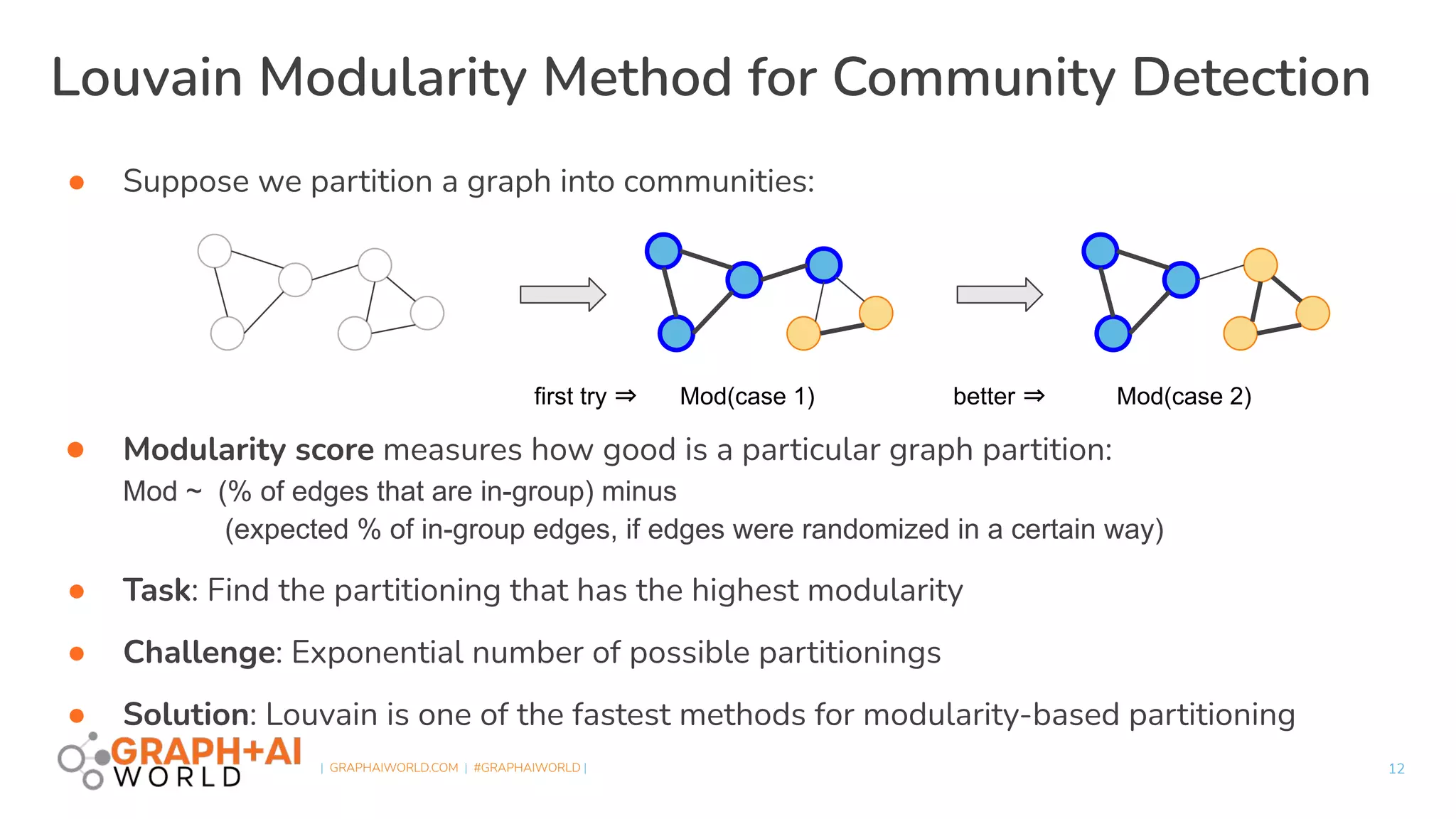
Louvain Modularity Algorithm
˃ Measurement of Modularity Q: judgement of stability of current
clustering
˃ Simple judgement for moving a node: ΔQ : judgement for job
hopping(move) for a vertice
˃ main challenge: Integrating large-size variables by scanning graph as
input
Fig. 2 Parallel Louvain Algorithm flow
The algorithm is like a group of people clustering and then
job hopping until stable
Cid,
TOT,
cSize
Get
Cid[v{e}]
Find Best
Target
Update
>> 20
Cid,
TOT,
cSiz
e
Get
Cid[v{e}]
Find Best
Target
Update
Cid,
TOT,
cSiz
e
Building
-Phases
• Merged to
smaller graph
Coloring Coloring
Clustering:
No more clustering
happen
Phase-1 Phase-2 Phase-n
Same-color
vertices’
distance >1
No need for
coloring small
graph
Clustering:
• Iterating until
ΔQ small
enough
• Q: modularity
• 1 iteration will
scan all
vertices
• 1st
Phase
always take
most of
time(>80%)
Clustering:
The smaller the
graph,
the fewer the
vertices,
the faster the
iteration
Building
-Phases
>90%
workload
can be
accelerated
Input
graph
(Done )
For
FPGA
(… )](https://image.slidesharecdn.com/hardwareacceleratedmlsolutionatgraphaiworldfall20final-201210020226/75/Hardware-Accelerated-Machine-Learning-Solution-for-Detecting-Fraud-and-Money-Laundering-Rings-20-2048.jpg)

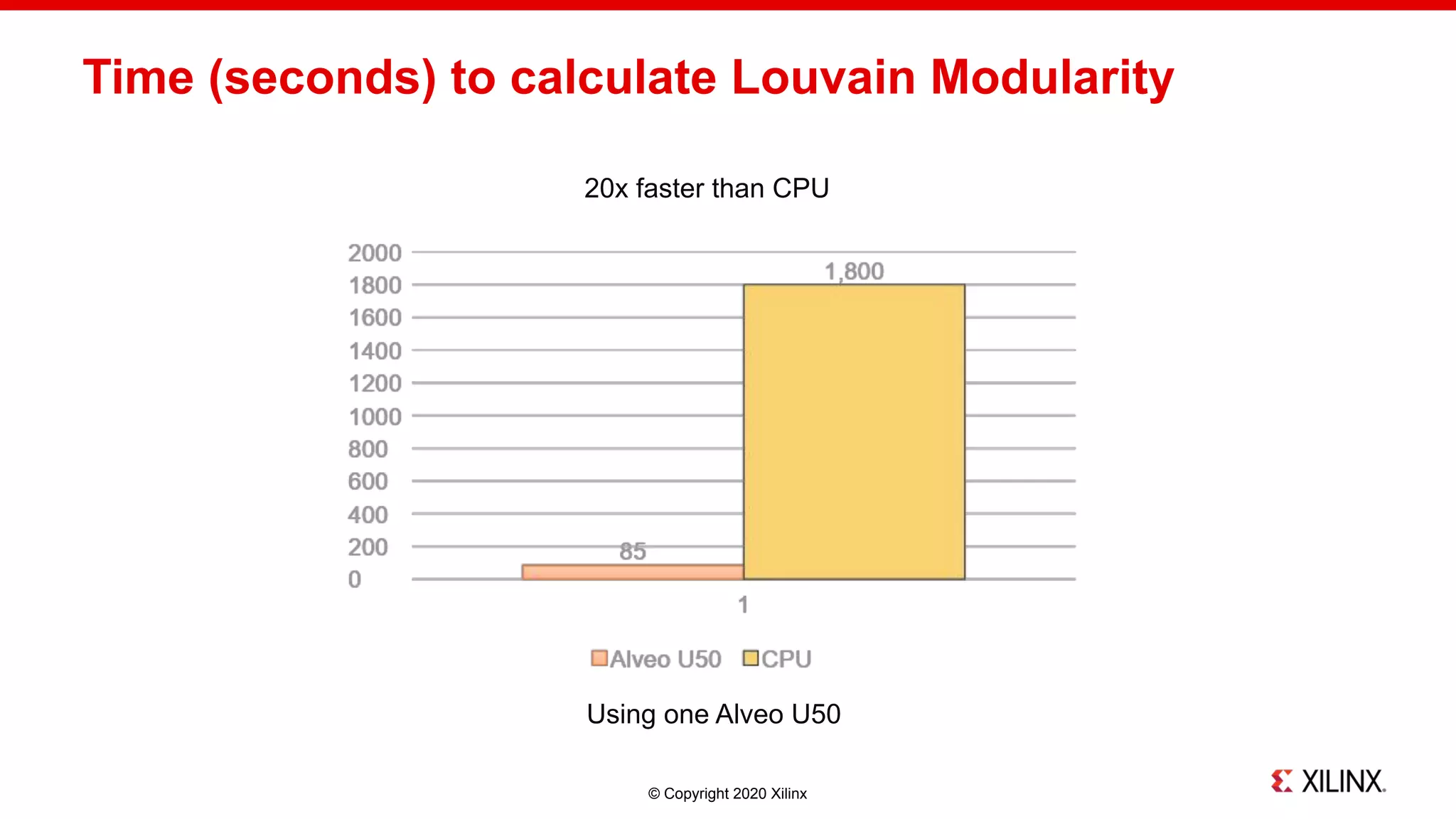


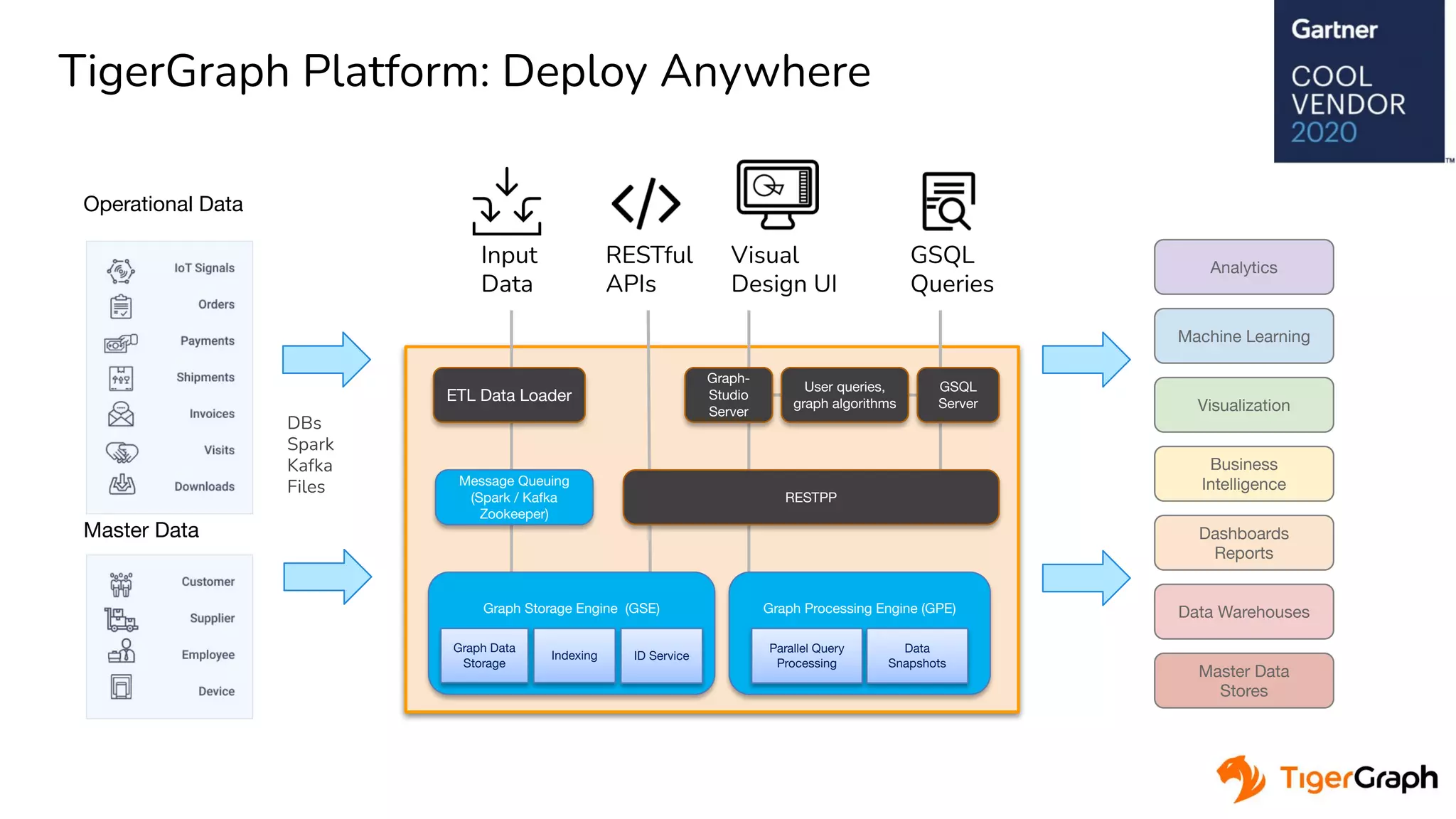
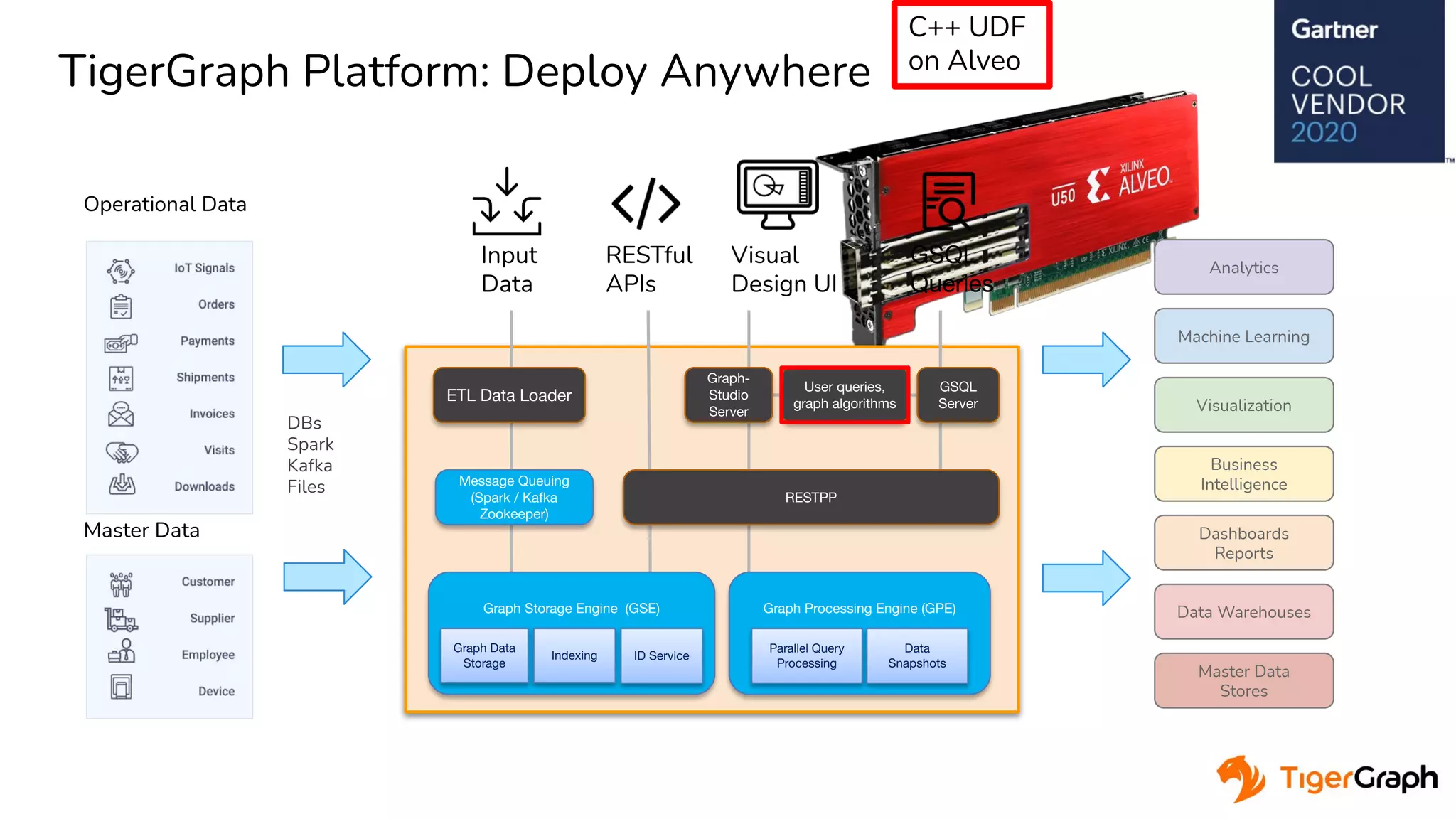
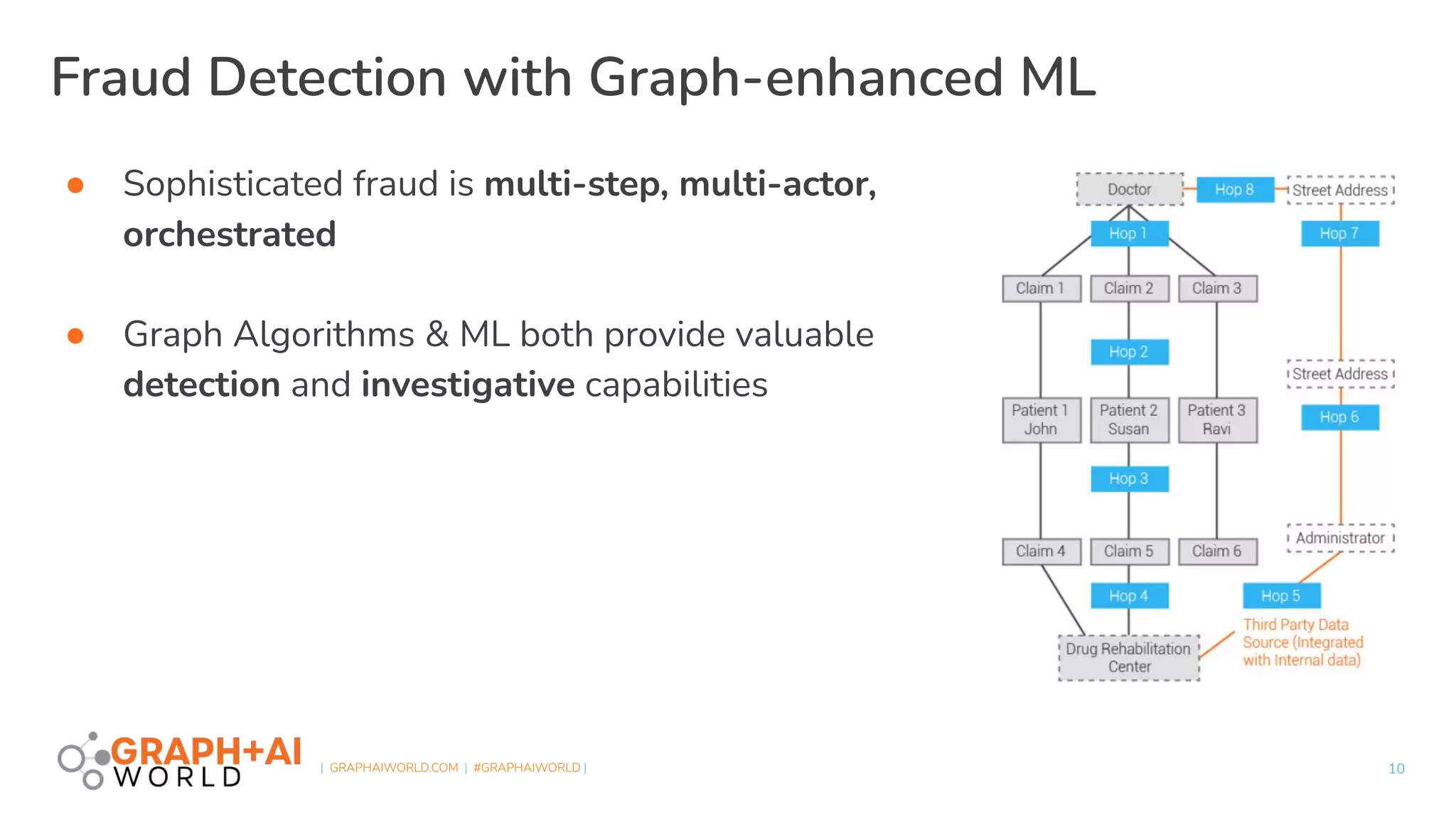
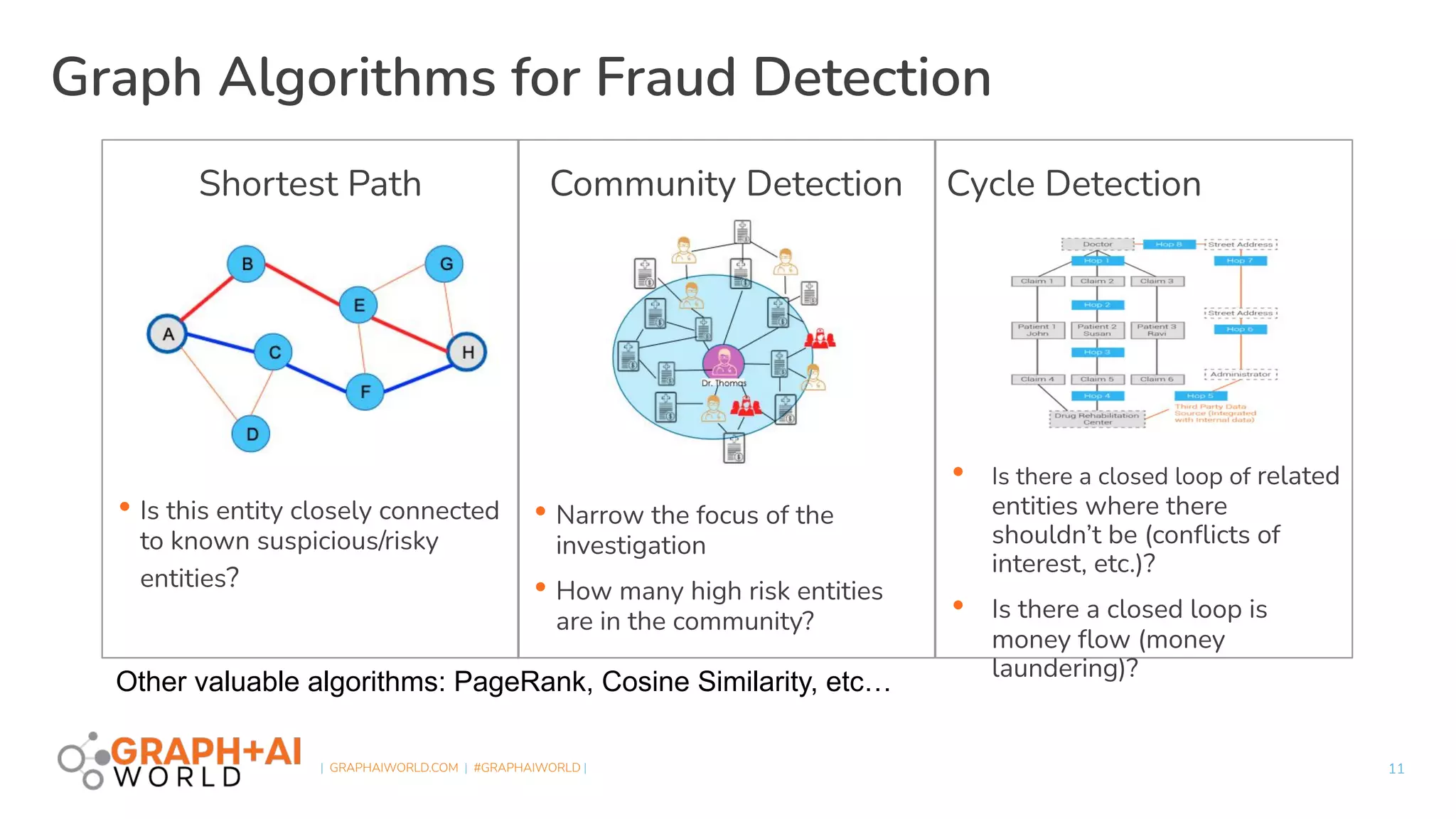
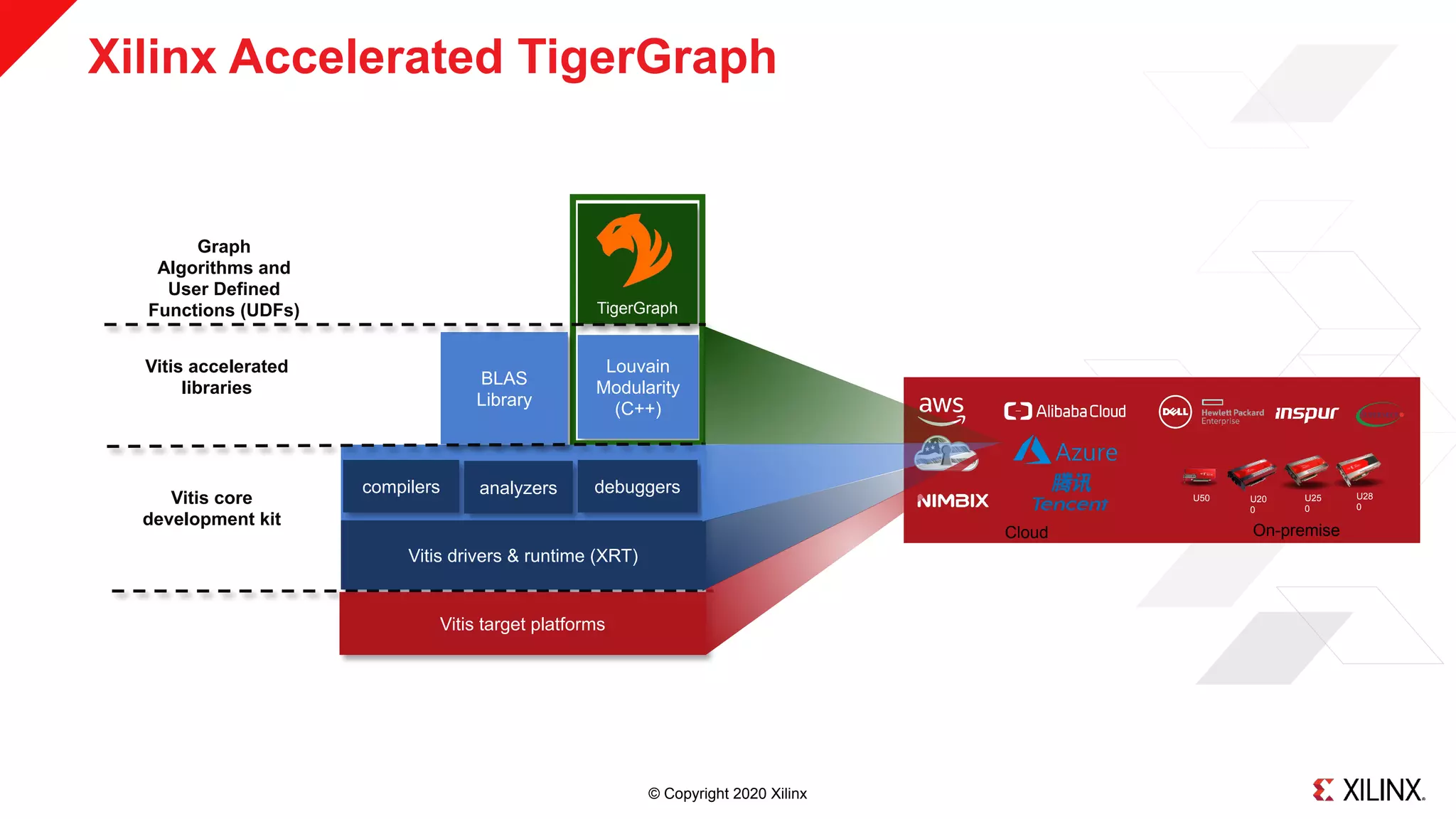
The document discusses a hardware-accelerated machine learning solution utilizing FPGA technology for detecting fraud and money laundering. It highlights the advantages of graph analytics and machine learning in uncovering complex patterns and relationships within data, specifically for fraud detection use cases. The presentation includes technical details about the TigerGraph platform and its integration with Xilinx FPGAs to enhance performance in real-time analytics.



































































![[DSC Europe 25] Boris Perkovic - Lost in performance.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/uq5hrp7vsuahqkxzifux-1-251204082258-fd2ee09d-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Goran Obradovic - The Rise of Sovereign AI: Building the Regi...](https://cdn.slidesharecdn.com/ss_thumbnails/7nw2xxixrxqdxvrb5wca-6-251205085714-ab09a2ac-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Dragana Ilic - AI for Big Data in Astronomy.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/8palya86qaatvjhva1ms-2-dragana-ilic-ai-ilic-251208151906-652b819c-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Petar Zivanov - AI meets documents From chatbots to AI-powere...](https://cdn.slidesharecdn.com/ss_thumbnails/xer2bb6nrdc8pdpev0pc-8-251204082258-7c2fa4a1-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Max Talanov - Non digital NNs.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/wif8tr3gtua74qvtopke-non-digital-nns-251205090438-26b0eea6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dragan Vucic - Building the Learning Organization - How AI Tr...](https://cdn.slidesharecdn.com/ss_thumbnails/8brigo2sbu6qur6gxrra-7-251205085715-6ae07d24-thumbnail.jpg?width=640&height=640&fit=bounds)




