Download to read offline




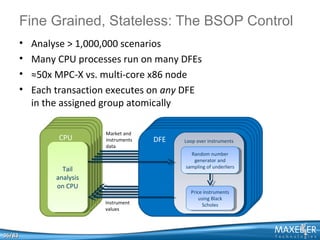
![1. Over 95% of run time in loops
2.
3.
4.
5.
6.
[loops to almost zero]
Reusability of data (e.g., x+x2+x3+x4+…)
[how close to zero?]
BigData
[prog: for data streaming, not for data
control]
Latency
A new programming model
WORM [prog.effort+comp.tim]
Use a tractor, not a Ferrari, to drive over a plowed field
5/83](https://image.slidesharecdn.com/1anegdoticmaxelerromania-131227034536-phpapp02/85/Anegdotic-Maxeler-Romania-5-320.jpg)



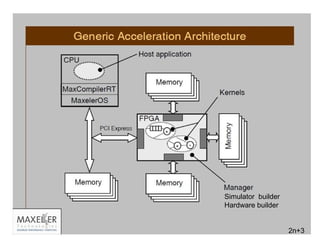
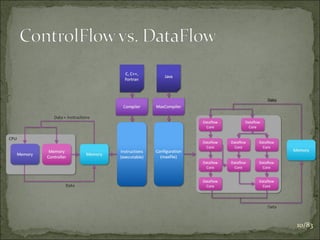
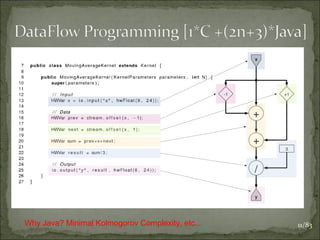
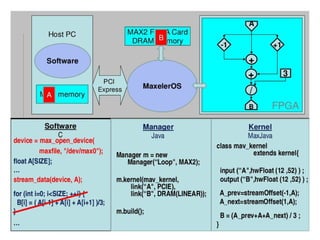
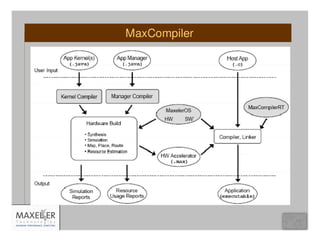




















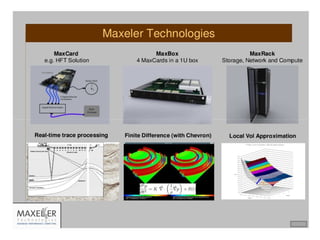






![Algorithmic Changes: Data Dependencies
PSI[0]
…
PSI[1]
OP
cbeta[0]
OP
cbeta[1]
PSI[N-3]
OP
…
…
0
OP’
OP’
…
PSI[0]
PSI[1]
PSI[2]
…
PSI[N-2]
PSI[N-1]
OP
cbeta[N-3]
OP’
PSI[N-3]
Example generated by Sasa Stojanovic (Gross-Pitaevskii)
cbeta[N-2]
OP’
0
PSI[N-2]
PSI[N-1]
53/83](https://image.slidesharecdn.com/1anegdoticmaxelerromania-131227034536-phpapp02/85/Anegdotic-Maxeler-Romania-53-320.jpg)
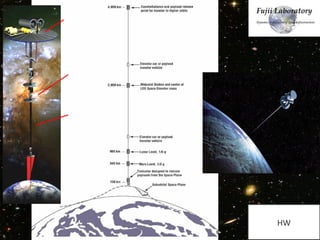
![Pipeline Changes: Higher Efficiency
0
X[0,0]
X[0,1]
[0,0]
0
[0,1]
[7,0]
[7,0]
[6,0]
[6,0]
[5,0]
[5,0]
[4,0]
[4,0]
[3,0]
[3,0]
[2,0]
[2,0]
[1,0]
[1,0]
[0,0]
R[0,0]
R[0,0]
Example generated by Sasa Stojanovic (Gross-Pitaevskii)
54/83](https://image.slidesharecdn.com/1anegdoticmaxelerromania-131227034536-phpapp02/85/Anegdotic-Maxeler-Romania-54-320.jpg)











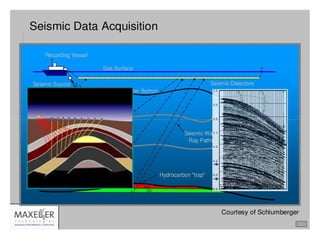
![Maxeler: Research (Google: good
method)
Structure of a Typical Research Paper: Scenario #1
[Comparison of Platforms for One Algorithm]
Curve A: MultiCore of approximately the same PurchasePrice
Curve B: ManyCore of approximately the same PurchasePrice
Curve C: Maxeler after a direct algorithm migration
Curve D: Maxeler after algorithmic improvements
Curve E: Maxeler after data choreography
Curve F: Maxeler after precision modifications
Structure of a Typical Research Paper: Scenario #2
[Ranking of Algorithms for One Application]
CurveSet A: Comparison of Algorithms on a MultiCore
CurveSet B: Comparison of Algorithms on a ManyCore
CurveSet C: Comparison on Maxeler, after a direct algorithm migration
CurveSet D: Comparison on Maxeler, after algorithmic improvements
CurveSet E: Comparison on Maxeler, after data choreography
CurveSet F: Comparison on Maxeler, after precision modifications
67/83
67/83](https://image.slidesharecdn.com/1anegdoticmaxelerromania-131227034536-phpapp02/85/Anegdotic-Maxeler-Romania-67-320.jpg)


















This document discusses how moving computationally intensive algorithms to Maxeler dataflow hardware can provide significant speedups, reductions in power consumption and space, while freeing up funds. Specifically, it notes that if a computer center spends €50M annually on electricity but reduces power usage 20x by using Maxeler, €47.5M could be saved. This money could pay the salaries of over 1000 PhD students per year.





























































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)





