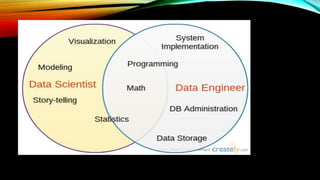
The document outlines the certification process and skill requirements for becoming a Cloudera Certified Data Engineer. It describes the responsibilities of data engineers and data scientists, the necessary technical competencies, preparation steps for the exam, and available resources. Additionally, it details the structure of the exam, including scheduling and permitted materials during the test.