






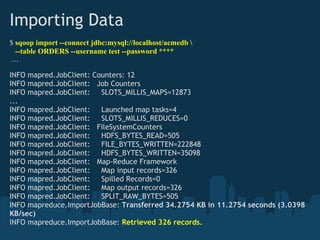






![Importing Data into HBase
hbase(main):001:0> list
TABLE
ORDERS
1 row(s) in 0.3650 seconds
hbase(main):002:0> describe 'ORDERS'
DESCRIPTION ENABLED
{NAME => 'ORDERS', FAMILIES => [ true
{NAME => 'mysql', BLOOMFILTER => 'NONE',
REPLICATION_SCOPE => '0', COMPRESSION => 'NONE',
VERSIONS => '3', TTL => '2147483647',
BLOCKSIZE => '65536', IN_MEMORY => 'false',
BLOCKCACHE => 'true'}]}
1 row(s) in 0.0310 seconds
hbase(main):003:0>](https://image.slidesharecdn.com/apachesqoop-110919160731-phpapp02/85/Apache-Sqoop-A-Data-Transfer-Tool-for-Hadoop-14-320.jpg)









Apache Sqoop is a tool designed for the efficient transfer of data between structured data stores and Hadoop, supporting both import and export functions. It allows for seamless integration with Hadoop ecosystem components like Hive and HBase, while utilizing a metadata-driven approach for data structure inference. Sqoop aims to simplify data access from relational databases and enterprise data warehouses, ensuring data preparation is streamlined for analysis within Hadoop environments.
































































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)



