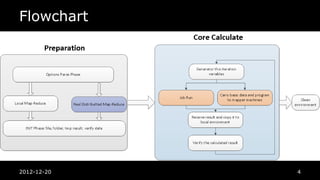
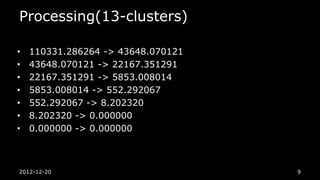
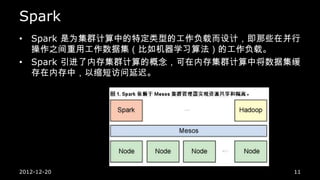
K-means in Hadoop
•Programs:
• Kmeans.py: k-means core algorithm
• Wrapper.py: local control iterations of k-means
• Generator.py: generate data in random of
range
• Graph.py: draw data
2012-12-20 3
Kmeans.py
• use “in-mappercombining” technology, for
implementing combiner functionality within every
map task. Notice, not combiner phase.
• It makes a discrete Combine step between Map and Reduce
unnecessary. Typically, it is not guaranteed that a combiner
function will be called on every mapper or that ,if called , it
will only be called once.
• In-mapper combiner design patten, we will guarantee that
combiner-like key aggregation occurs in every mapper,
instead of optionally in some mappers.
2012-12-20 5
6.
Kmeans.py
• The aggregationis done entirely in the memory, without
touching disk and it happens before any emission code has
been called
• But it can not assure “Memory Leak” issue. We
should use python to control this condition.
• Results (3.6G Test Dataset)
• Old: 30+ min
• Current: 9+ min, in reduce phase we only use
1~2 second. Saving significant time.
2012-12-20 6
Plan
• 27 PCsrun properly in Hadoop
• Remote management : write some shell scripts,
power saving, task submit from everyone etc.
• Build Mesos, spark, ZooKeeper, Hbase in our
platform.
2012-12-20 13