

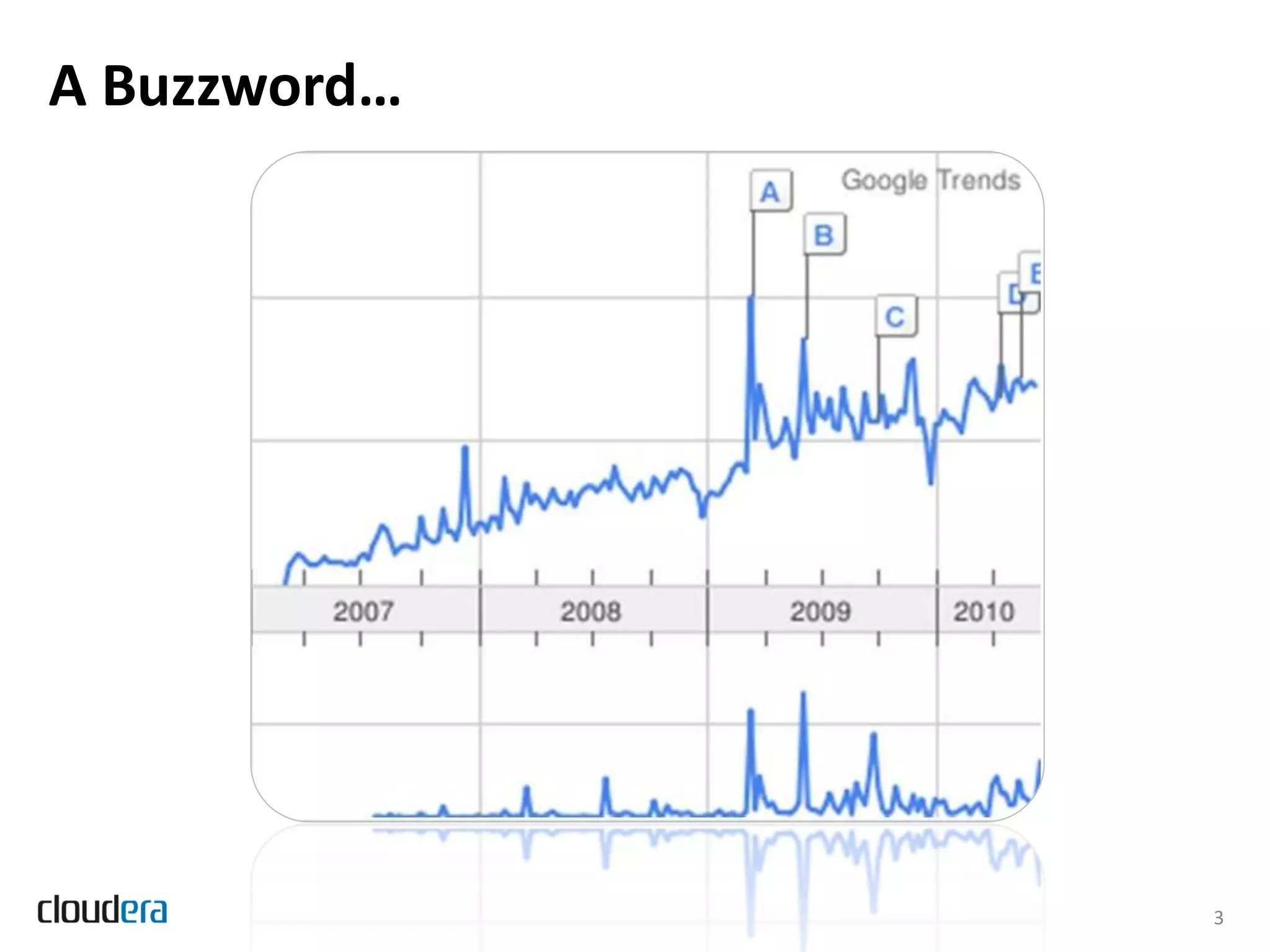
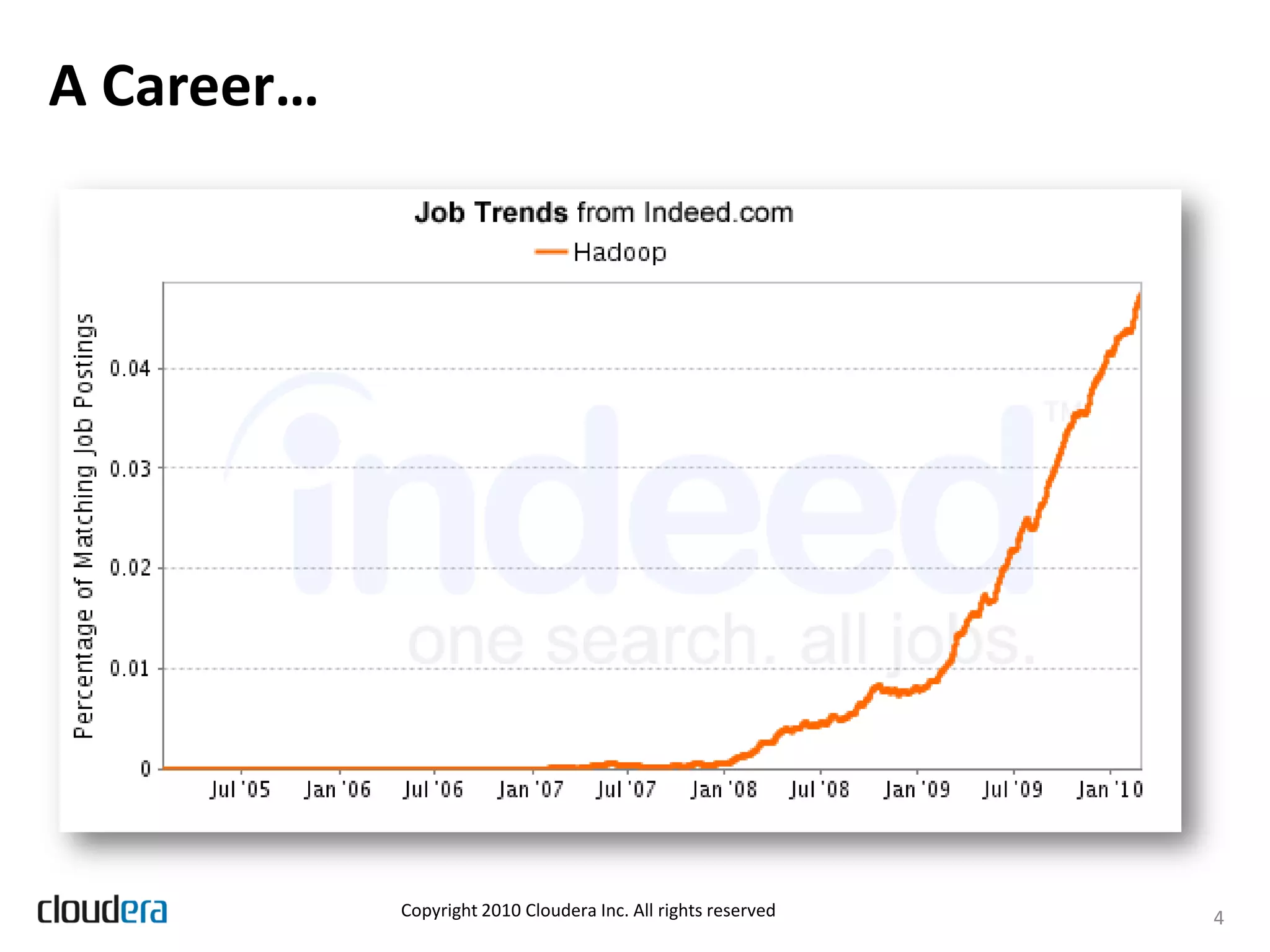



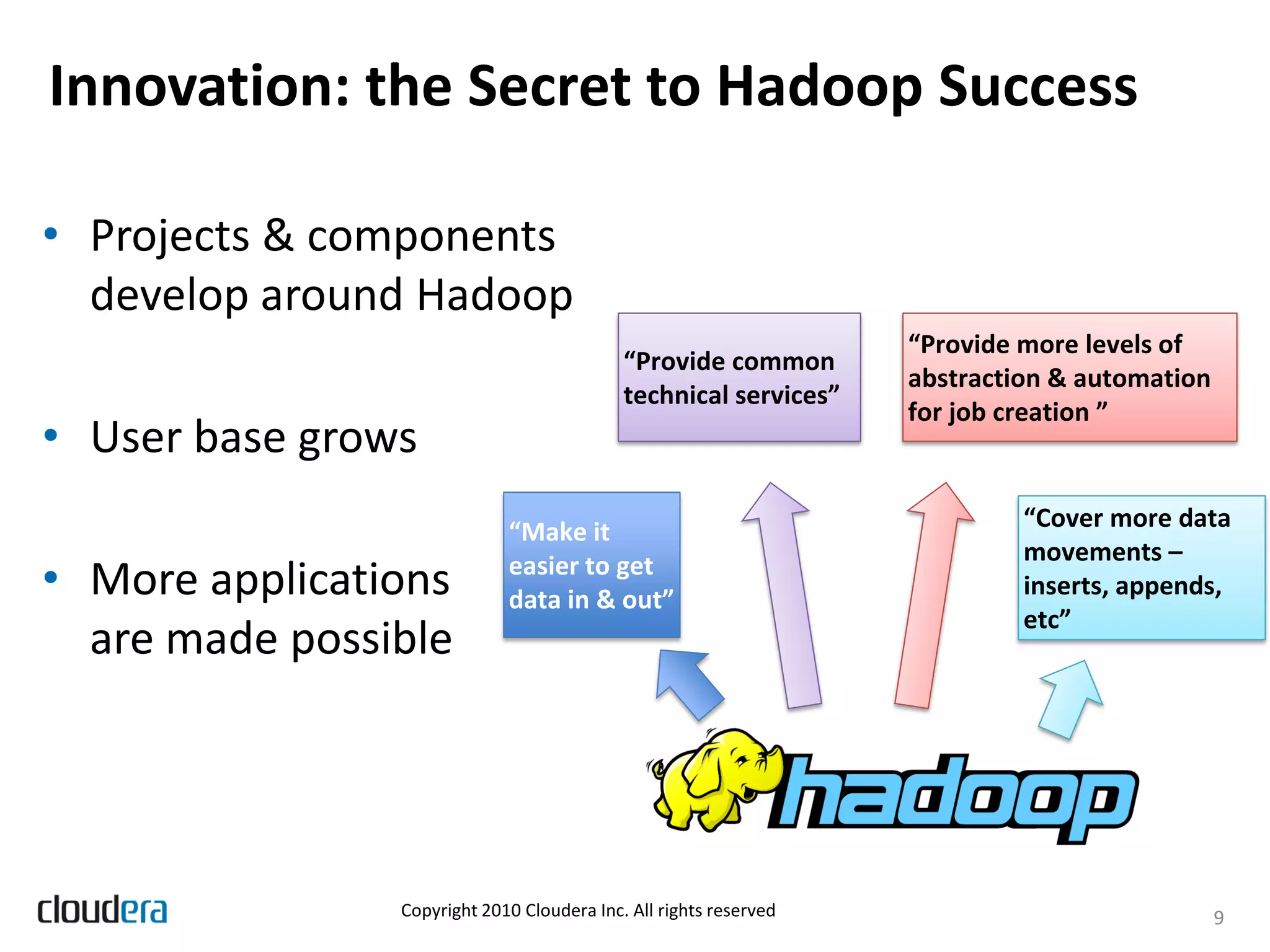





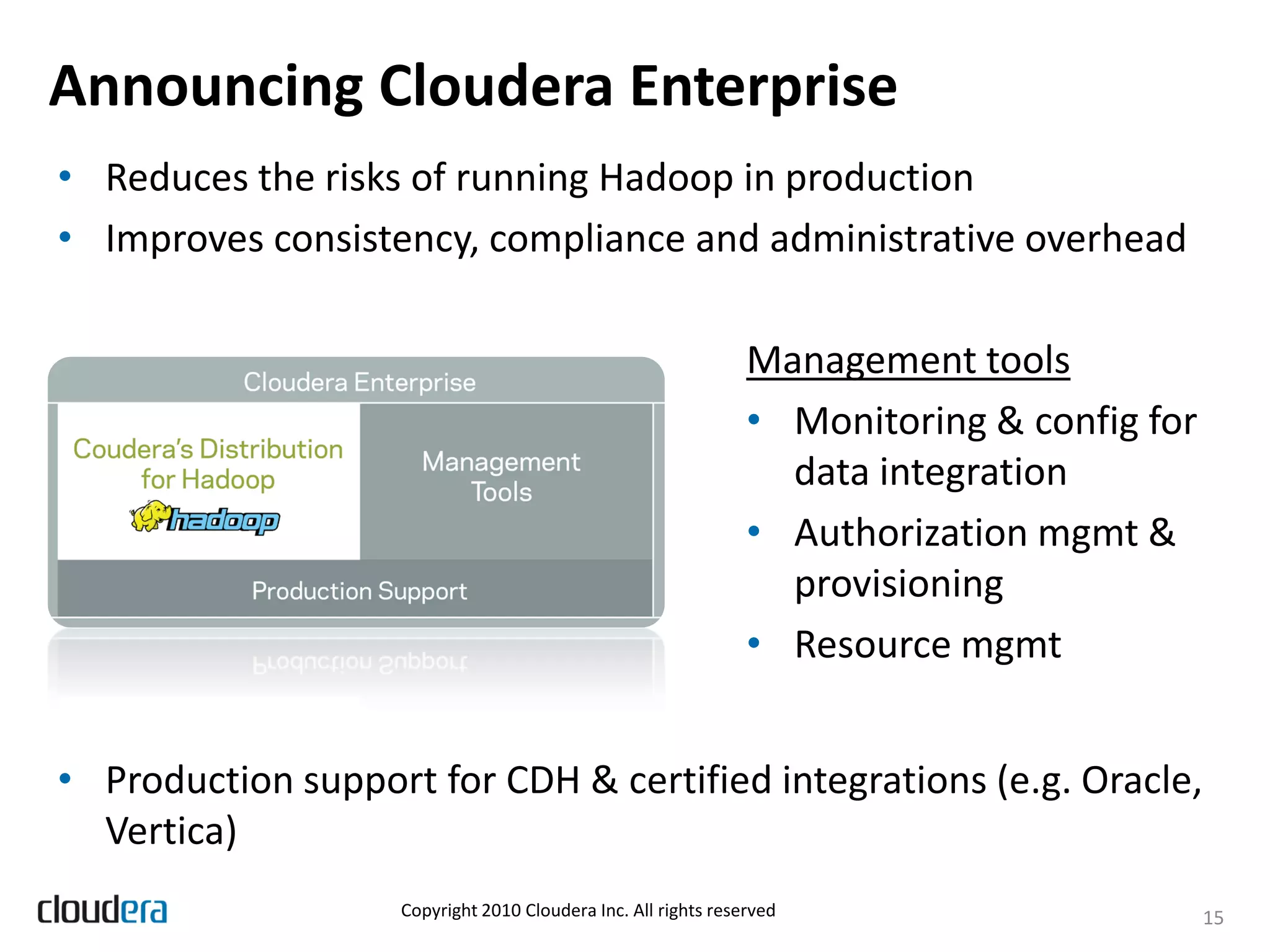




The document discusses the evolution and growth of Hadoop, highlighting its transition from a basic framework focused on MapReduce and HDFS to a comprehensive ecosystem with various components and applications. It announces Cloudera's Distribution for Hadoop (CDH) version 3, which integrates multiple components, simplifies dependency management, and introduces new features like Flume and Hue. Additionally, it addresses the challenges associated with using Hadoop in production environments, outlining Cloudera Enterprise's tools to improve manageability and compliance.

































































































![[BDD 2025 - Full-Stack Development] PHP in AI Age: The Laravel Way. (Rizqy Hi...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-phpinaiagethelaravelway-251125012602-ef9d330e-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Full-Stack Development] The Modern Stack: Building Web & AI Appli...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-themodernstackbuildingwebaiapplicationswithserverless-251124030844-388cf04f-thumbnail.jpg?width=640&height=640&fit=bounds)








