Downloaded 231 times


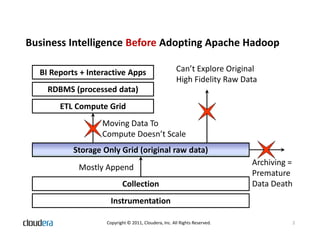
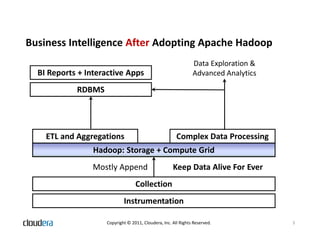

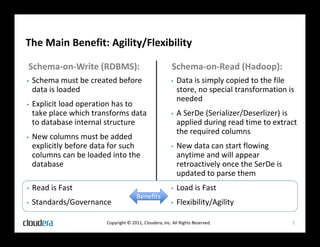






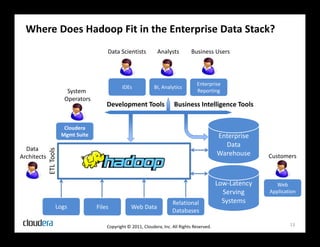




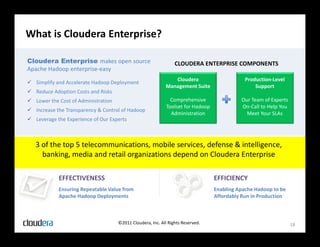





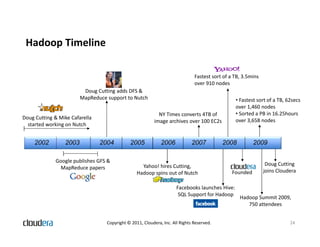


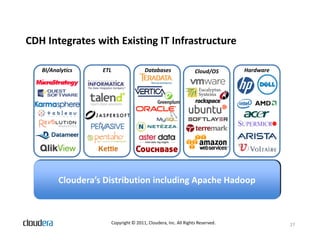


The document discusses how Apache Hadoop transforms business intelligence and data analytics by enabling scalable, flexible, and cost-effective data storage and processing. It highlights Hadoop's core components, benefits like agility and complex data processing capabilities, and its integration within the enterprise data stack. Additionally, it outlines Cloudera's role in simplifying Hadoop deployment and management, and provides insights into the Hadoop ecosystem's growth and community impact.























































































