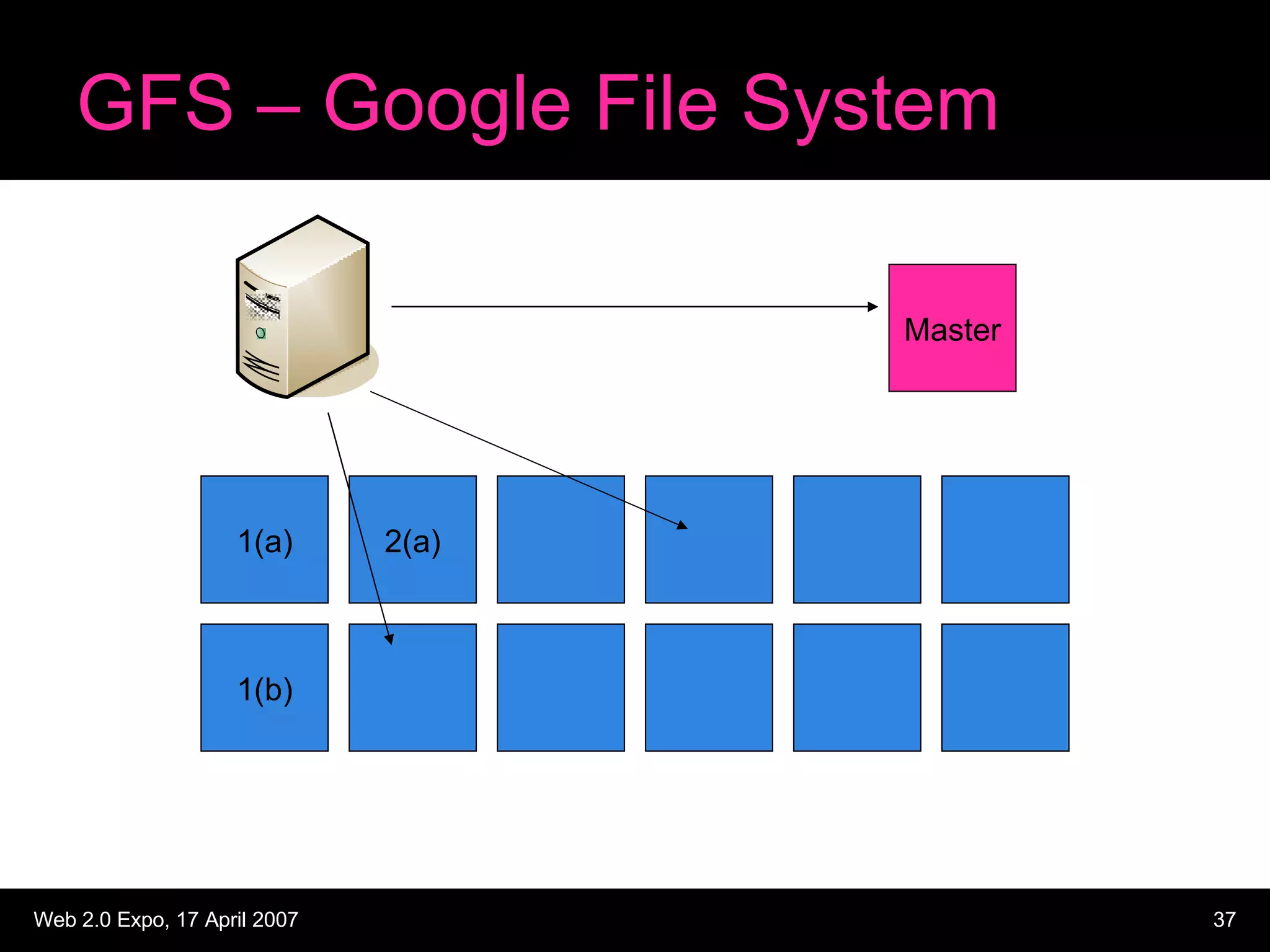
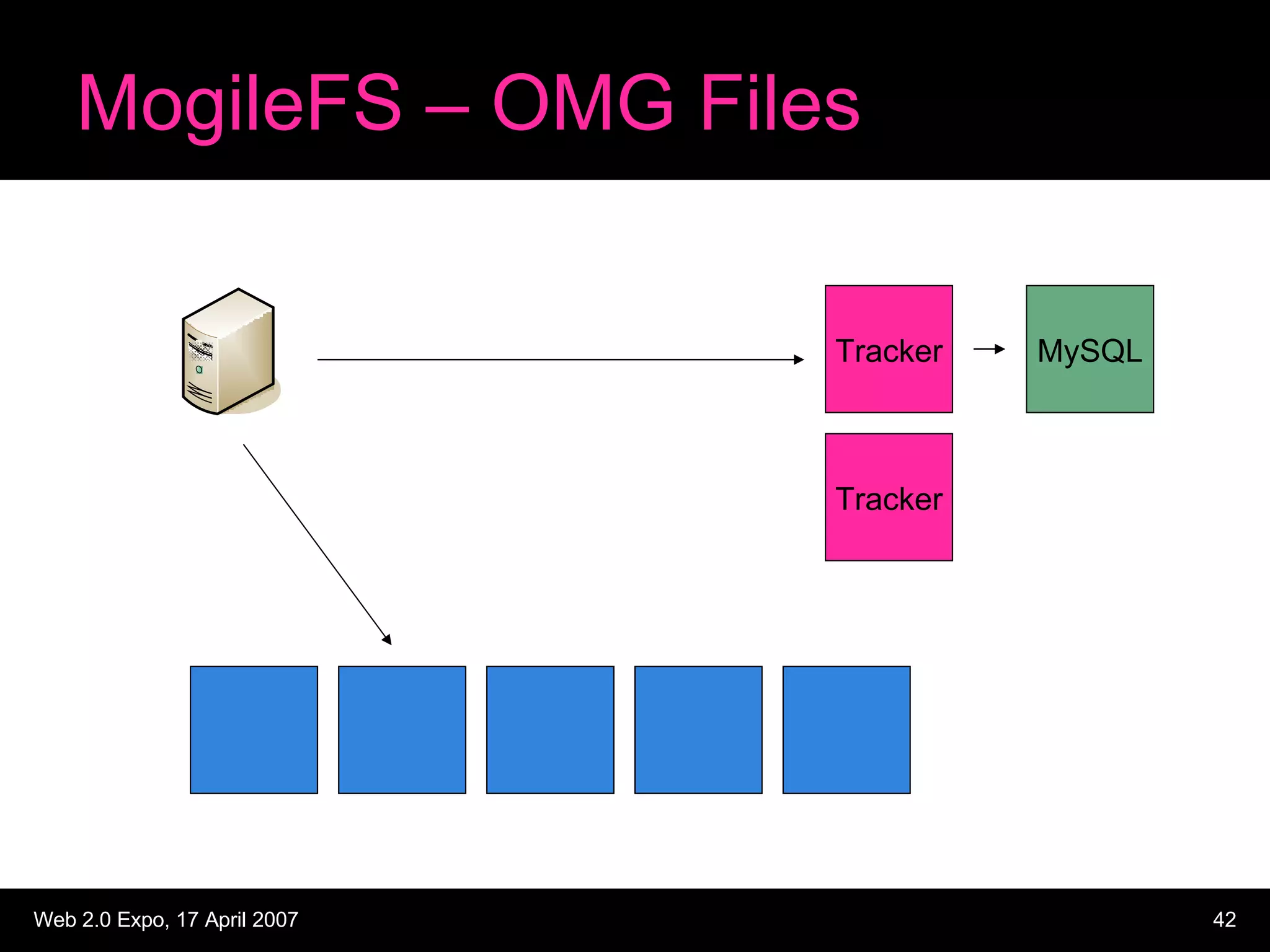
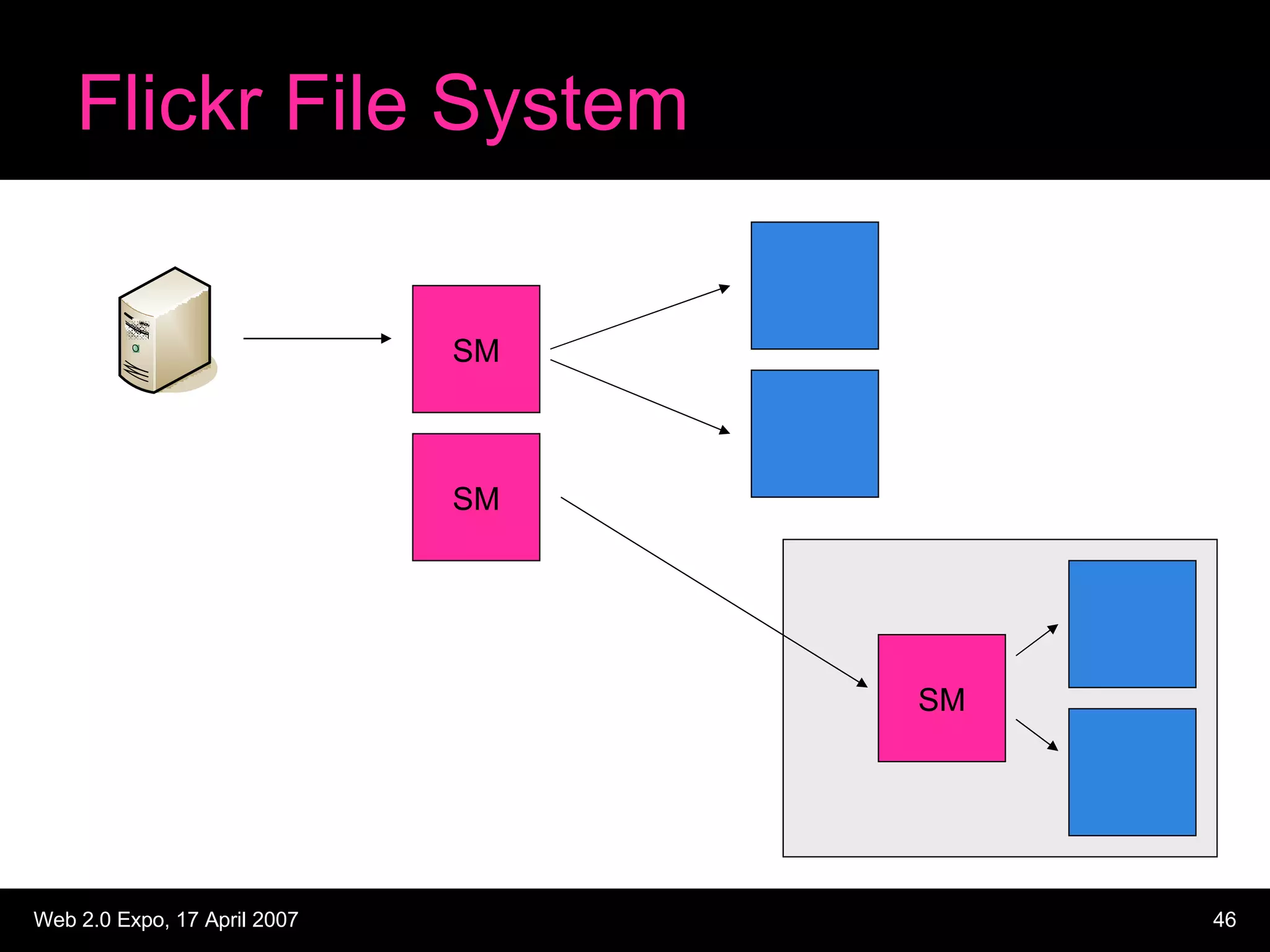
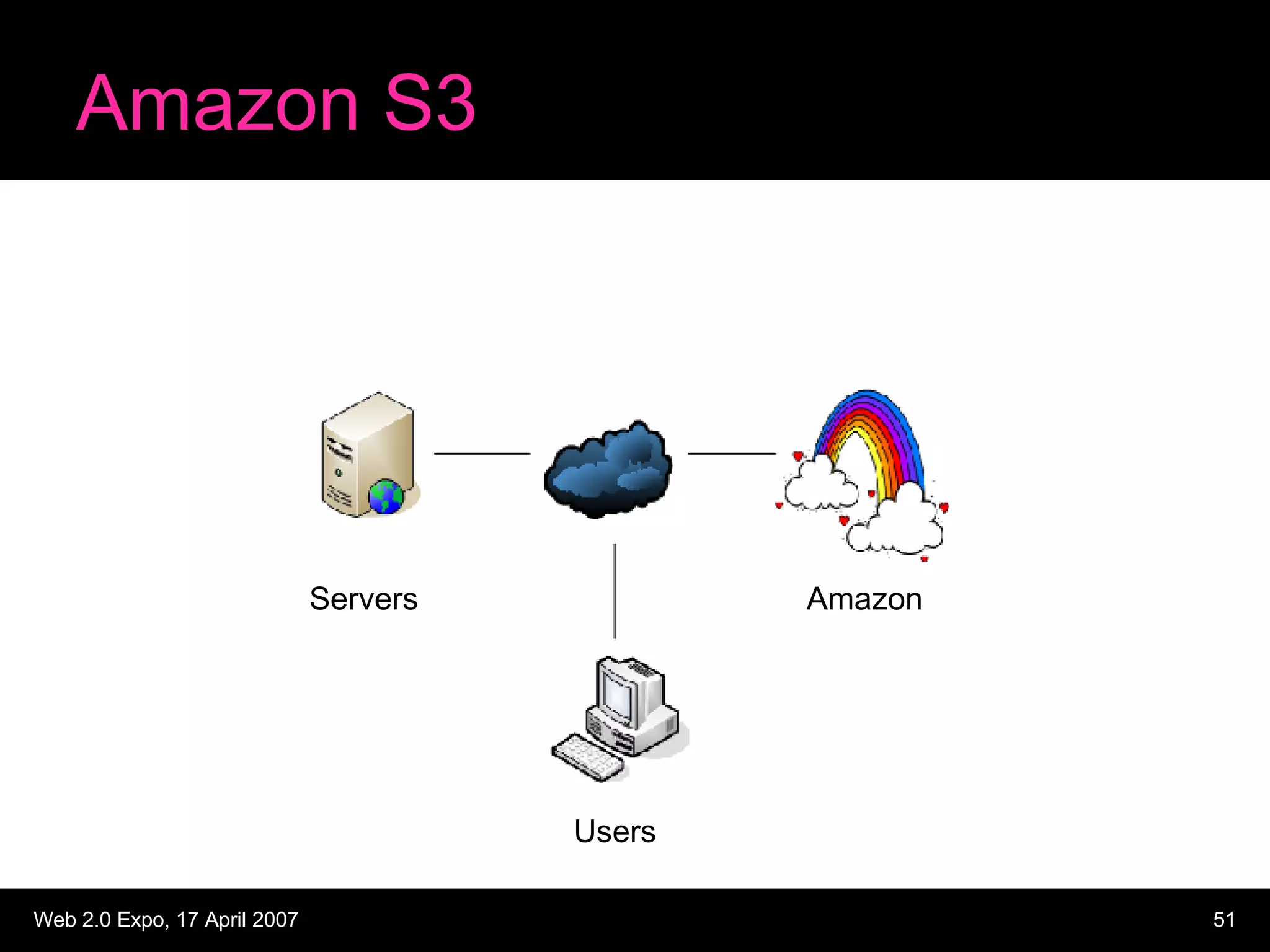
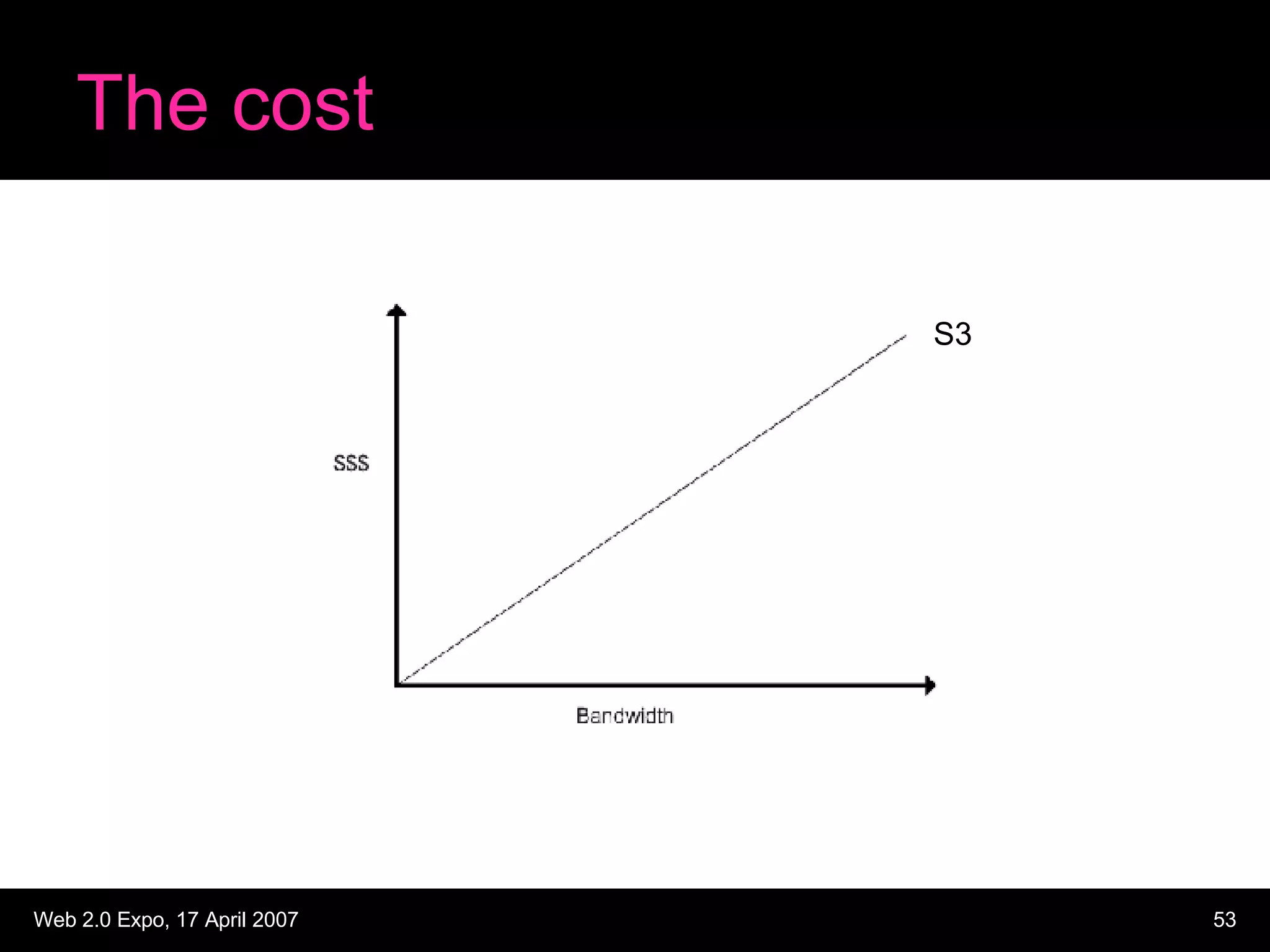
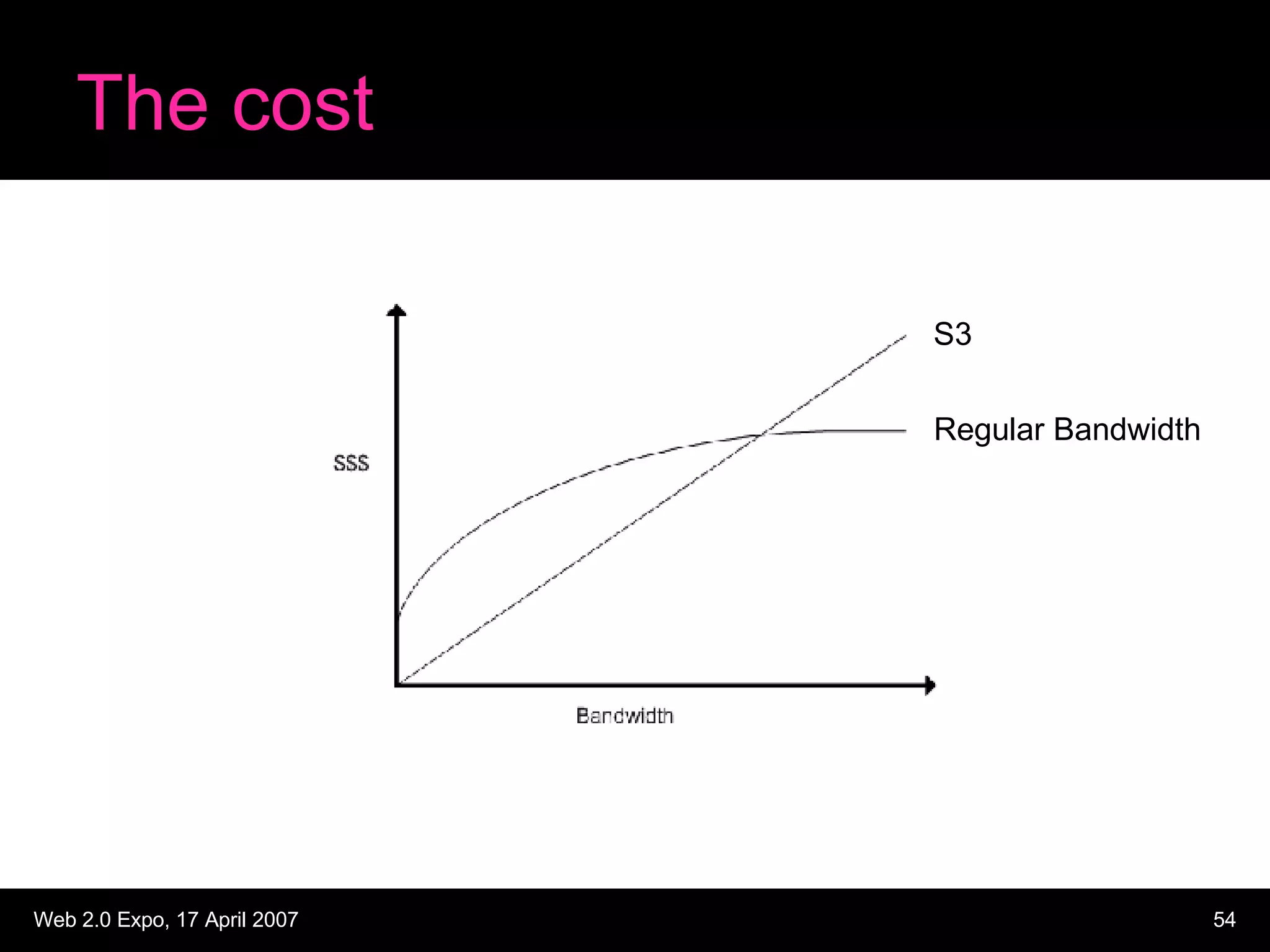
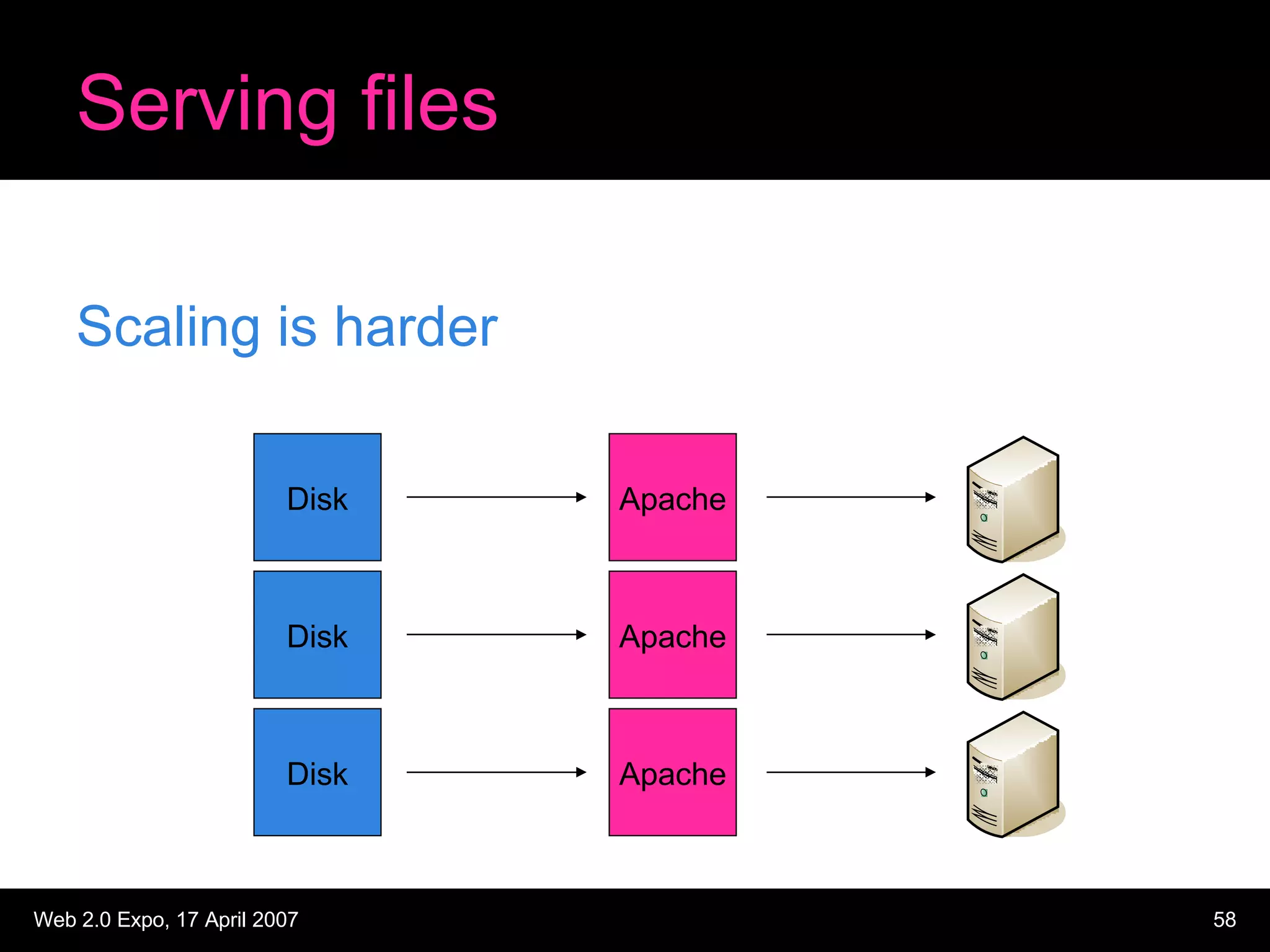
The document discusses designing large scale file storage and serving systems. It covers key requirements like scalability, reliability, and cost-effectiveness. It then describes various approaches to storage, such as network attached storage (NAS), storage area networks (SAN), and caching. Specific examples like Google File System, MogileFS, and Flickr's file system are examined. Business continuity planning (BCP) through redundancy and replication is also discussed.

















































































![Space costs Cost per U Usable GB [ ] U’s needed (inc network) x Recurring Cost](https://image.slidesharecdn.com/web20expo-filesystems156/75/Web20expo-Filesystems-94-2048.jpg)

![Misc costs Support contracts + spare disks Usable GB + bus adaptors + cables [ ] Single & Recurring Costs](https://image.slidesharecdn.com/web20expo-filesystems156/75/Web20expo-Filesystems-96-2048.jpg)
![Human costs Admin cost per node Node count x Recurring Cost Usable GB [ ]](https://image.slidesharecdn.com/web20expo-filesystems156/75/Web20expo-Filesystems-97-2048.jpg)

























![Post video to sla blog [tutorial]](https://cdn.slidesharecdn.com/ss_thumbnails/postvideotoslablogtutorial-141028095758-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)






































![[BDD 2025 - Artificial Intelligence] Building AI Systems That Users (and Comp...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-buildingaisystemsthatusersandcompanieslove-251124030845-038f7732-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DevFest Strasbourg 2025] - NodeJs Can do that !!](https://cdn.slidesharecdn.com/ss_thumbnails/devfeststrasbourg2025-nodejscandothat-251127142731-da65b6fd-thumbnail.jpg?width=640&height=640&fit=bounds)















