







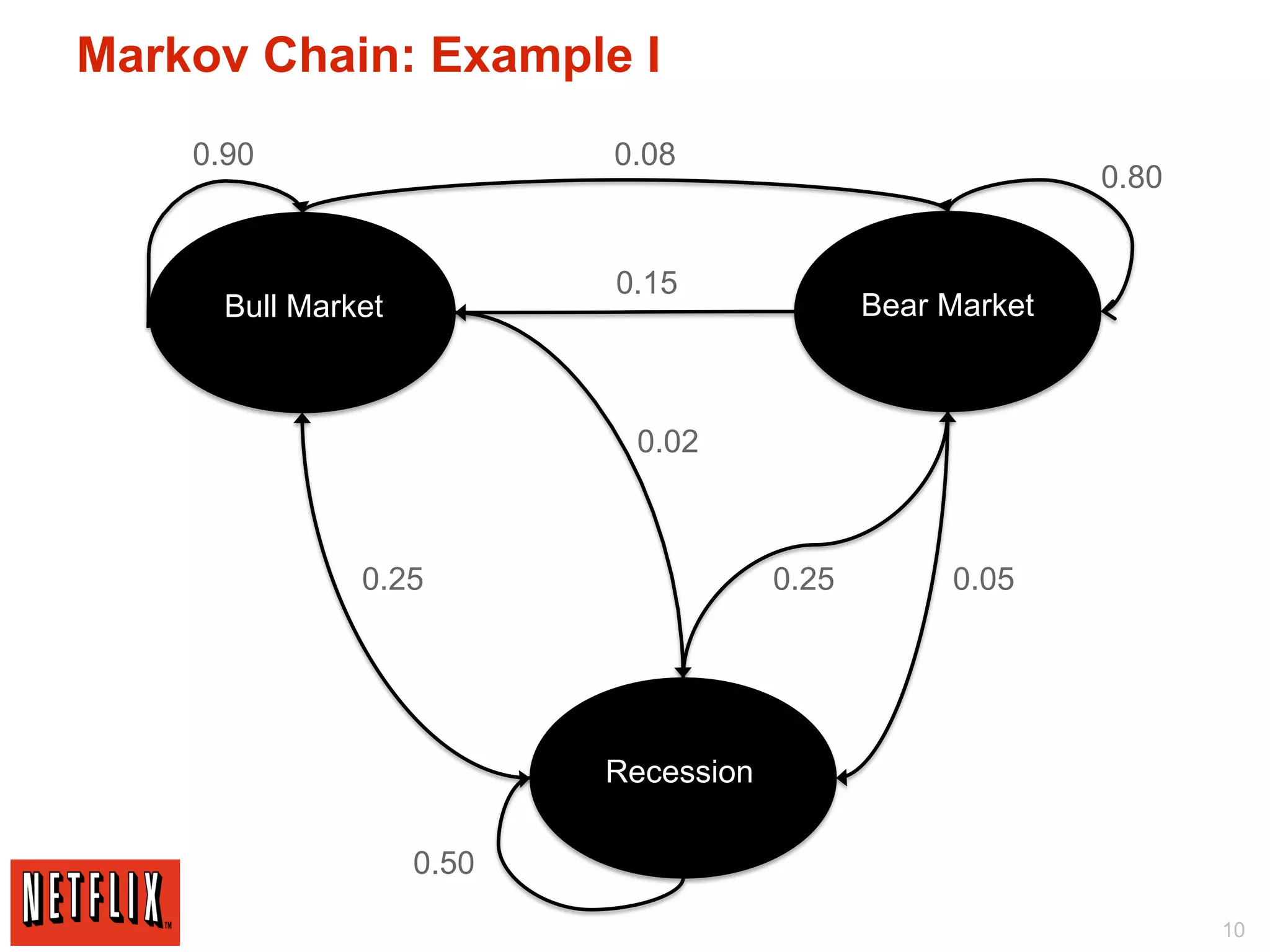
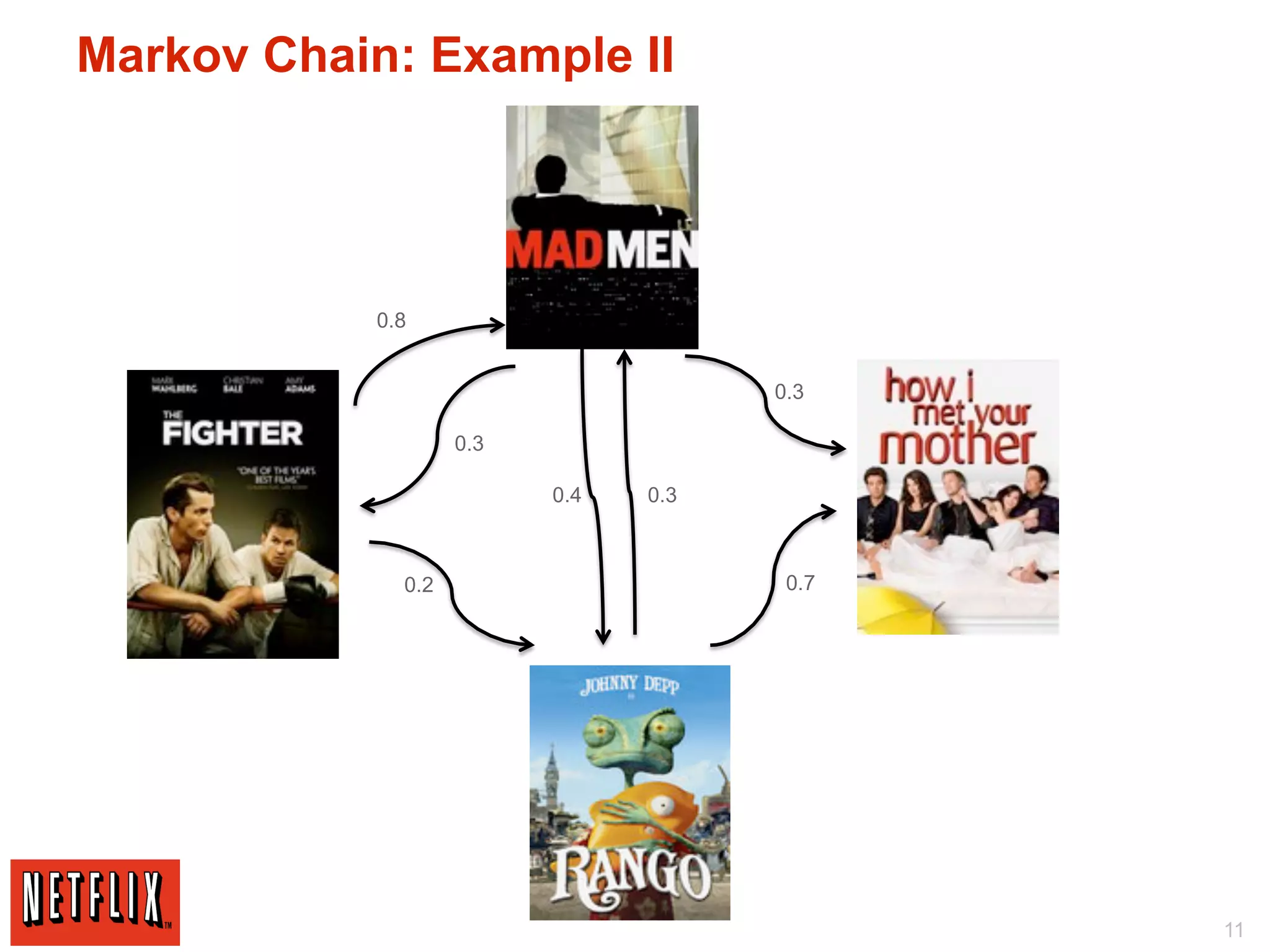


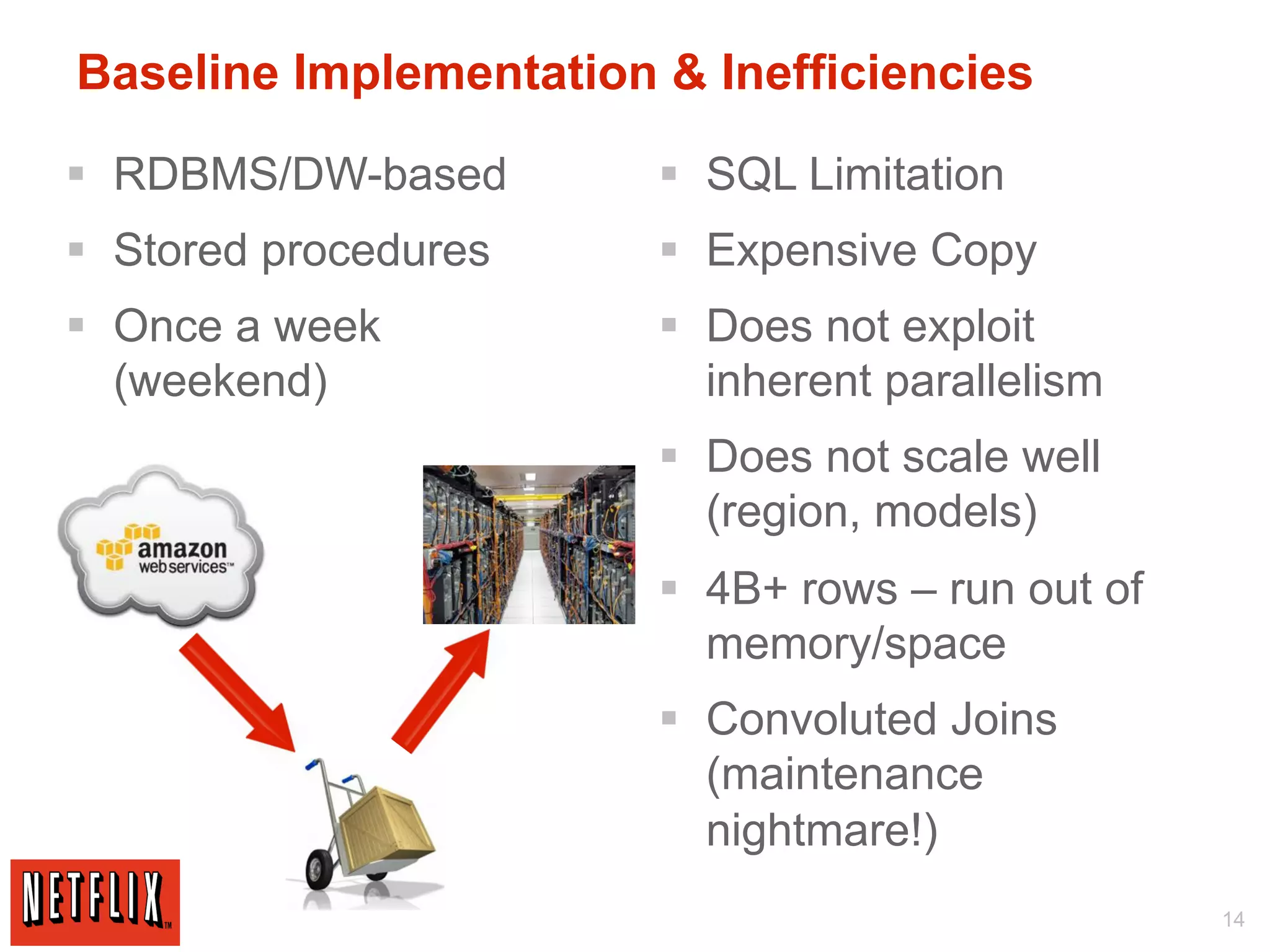
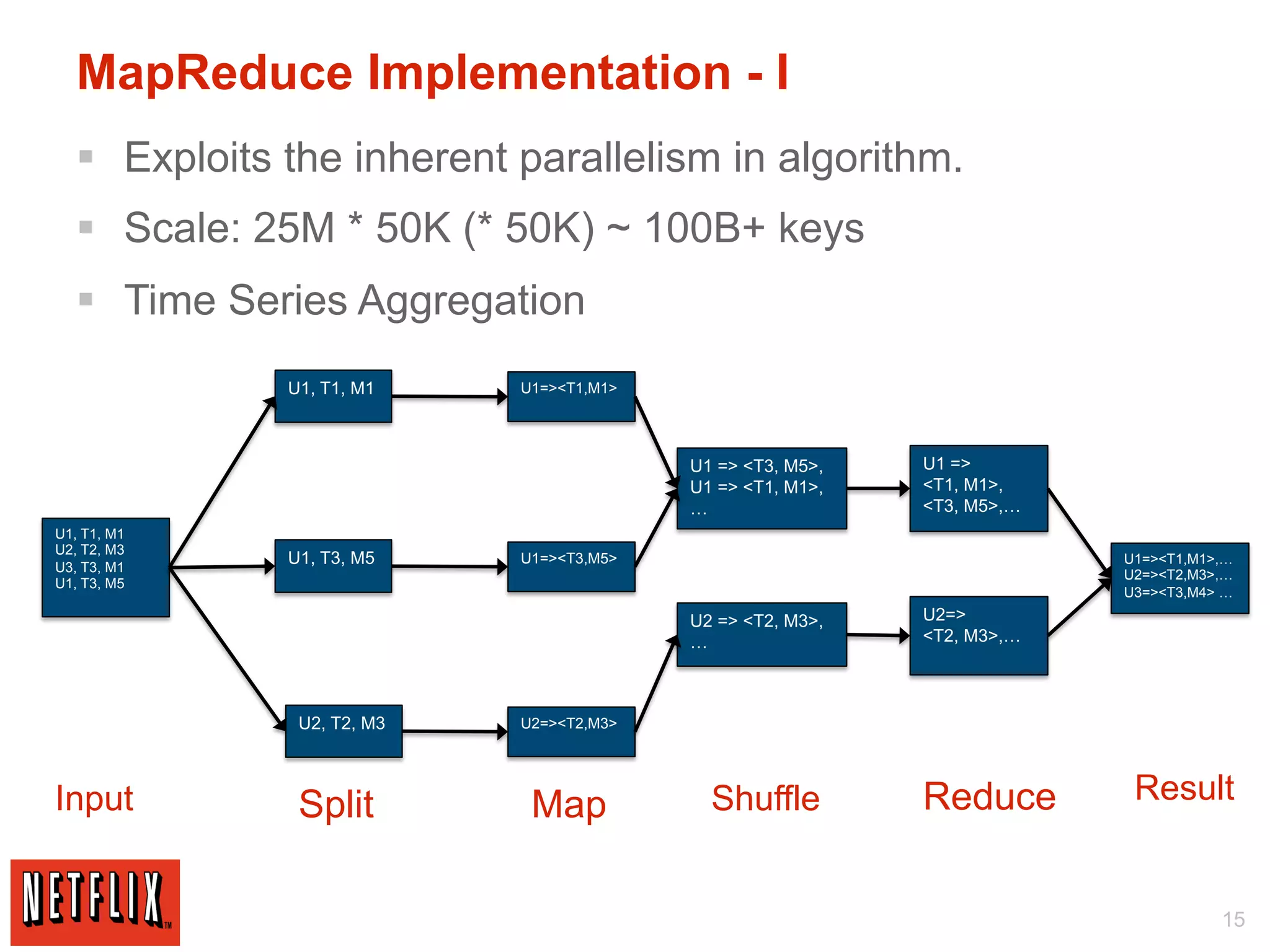
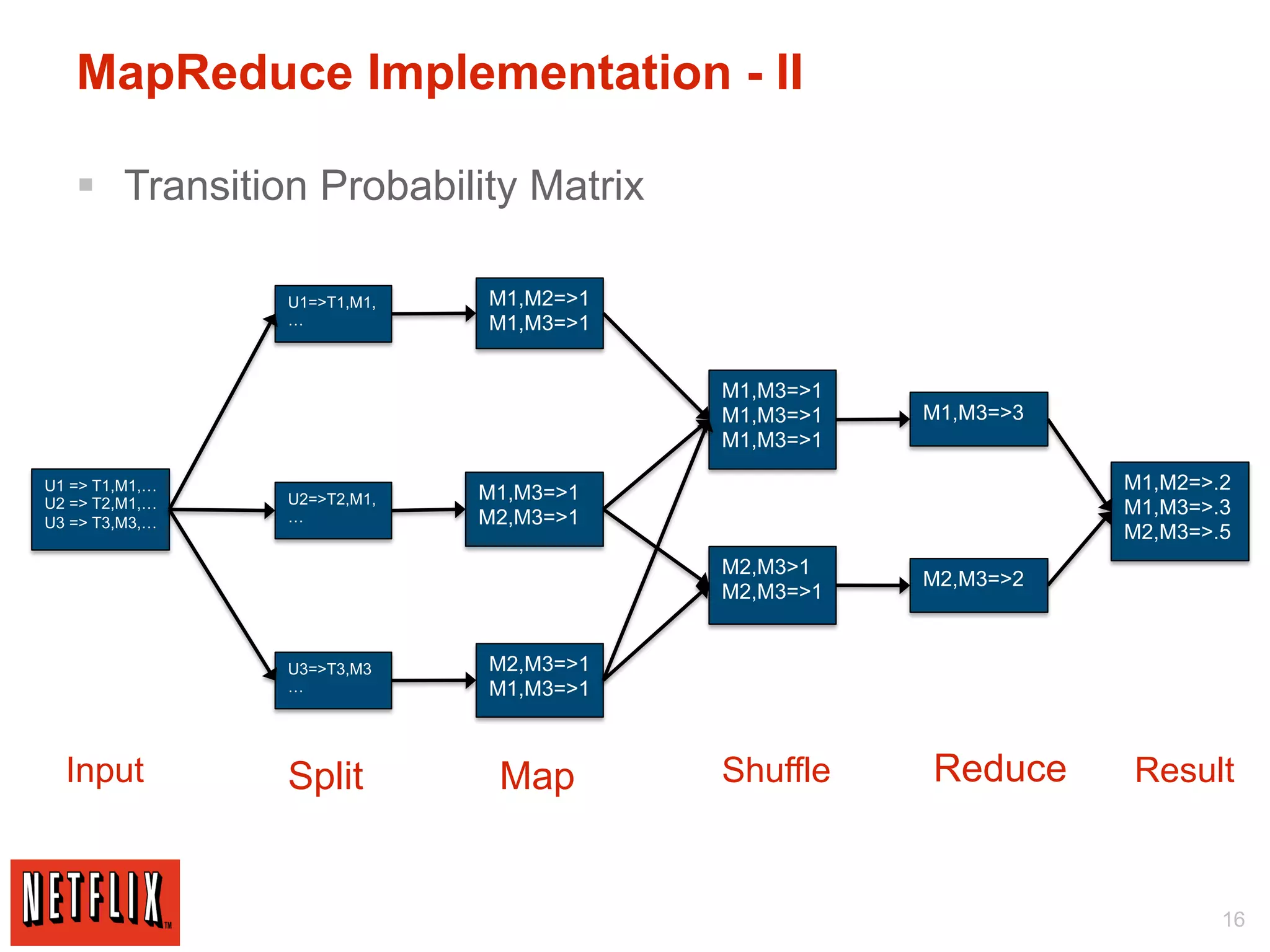




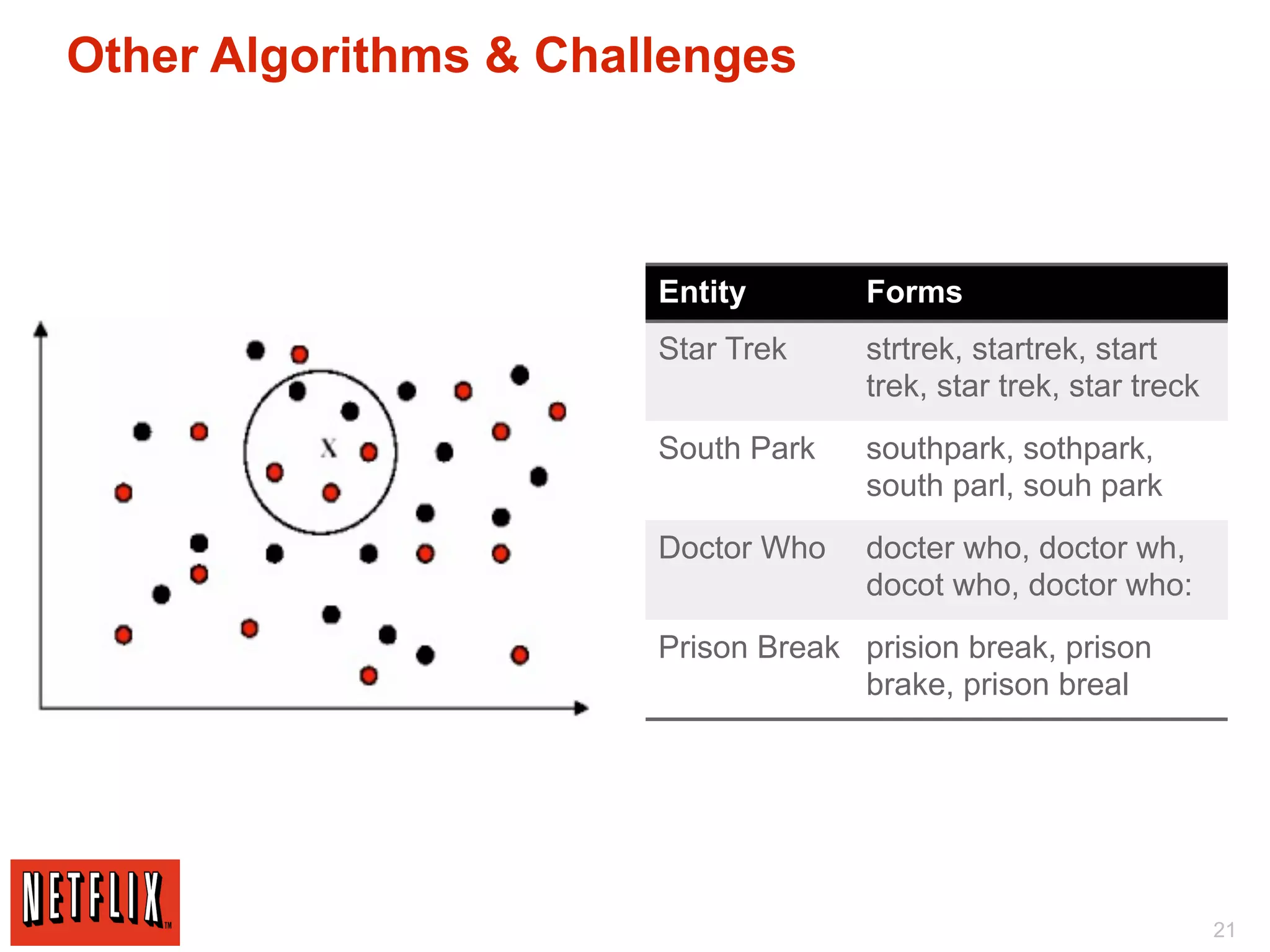





The document discusses Netflix's use of Hadoop and cloud computing to analyze large amounts of social data. It describes how Netflix receives data from 25 million subscribers including ratings, searches, plays, and other information. This amounts to over 4 million ratings and 3 million searches per day. Traditional databases struggled to handle this volume and scale effectively. Netflix migrated its algorithms to run on Hadoop, which allowed for arbitrarily complex modeling and easy scaling across new models and regions. This included using techniques like Markov chains, collaborative filtering, and machine learning on large datasets. The migration from traditional databases to Hadoop improved performance, scalability and maintainability.


















![[214] Ai Serving Platform: 하루 수 억 건의 인퍼런스를 처리하기 위한 고군분투기](https://cdn.slidesharecdn.com/ss_thumbnails/214aiservingplatforminference-181012022603-thumbnail.jpg?width=640&height=640&fit=bounds)












![[Harvard CS264] 09 - Machine Learning on Big Data: Lessons Learned from Googl...](https://cdn.slidesharecdn.com/ss_thumbnails/machinelearningbigdata-maxlin-cs264opt-110331195757-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)













































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)








