Download as PDF, PPTX








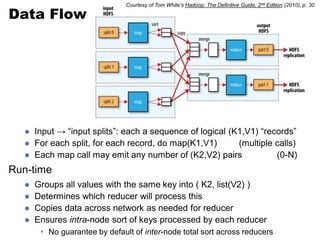

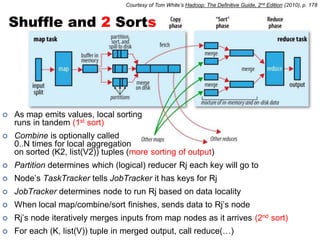
![Partition
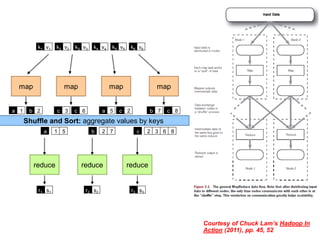
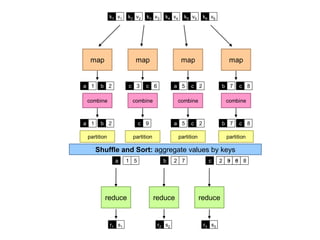
Given: map ( K1, V1 ) → list ( K2, V2 )
reduce ( K2, list(V2) ) → list ( K3, V3)
partition (K2, N) → Rj maps K2 to some reducer Rj in [1..N]
Each distinct key (with associated values) sent to a single reducer
• Same reduce node may process multiple keys in separate reduce() calls
Balances workload across reducers: equal number of keys to each
• Default: simple hash of the key, e.g., hash(k’) mod N (# reducers)
Customizable
• Some keys require more computation than others
• e.g. value skew, or key-specific computation performed
• For skew, sampling can dynamically estimate distribution & set partition
• Secondary/Tertiary sorting (e.g. bigrams or arbitrary n-grams)?](https://image.slidesharecdn.com/uta-dicta-lecture2-090111-110902081833-phpapp02/85/Lecture-2-Data-Intensive-Computing-for-Text-Analysis-Fall-2011-15-320.jpg)



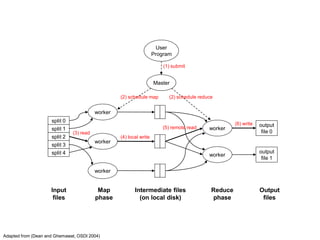




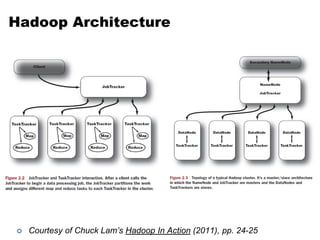

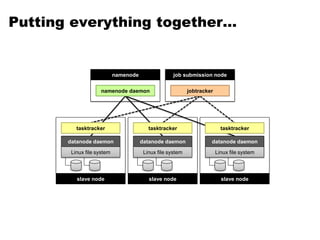





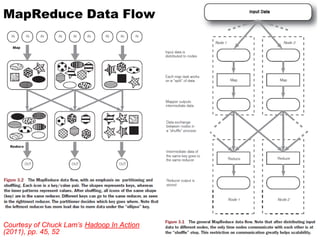
The document outlines the principles of data-intensive computing for text analysis, focusing on the MapReduce programming model used in Hadoop. It describes the data flow in MapReduce, including how input is split into records, processed by mappers, and reduced into outputs, along with the roles of the distributed file system. Furthermore, it explains key functional properties, cluster architecture, and the differences between the old and new API in Hadoop.























































































