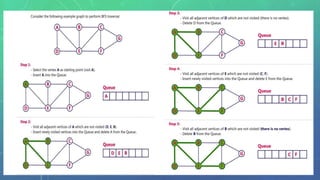
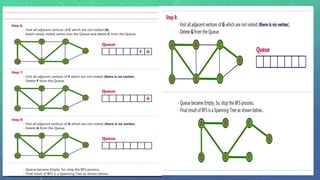
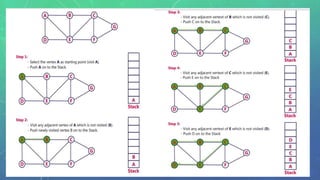
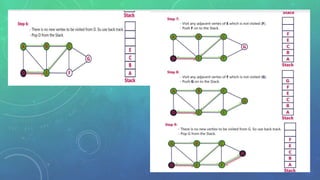
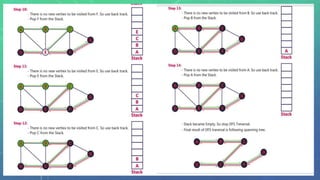
This document discusses graph traversal techniques for searching graphs. It describes two common techniques: breadth-first search (BFS) and depth-first search (DFS). BFS uses a queue data structure to visit all adjacent vertices of the starting vertex before moving to the next level, producing a spanning tree. DFS uses a stack, visiting all vertices reachable from the starting point before backtracking, also producing a spanning tree. The document outlines the step-by-step process for implementing BFS and DFS on a graph.