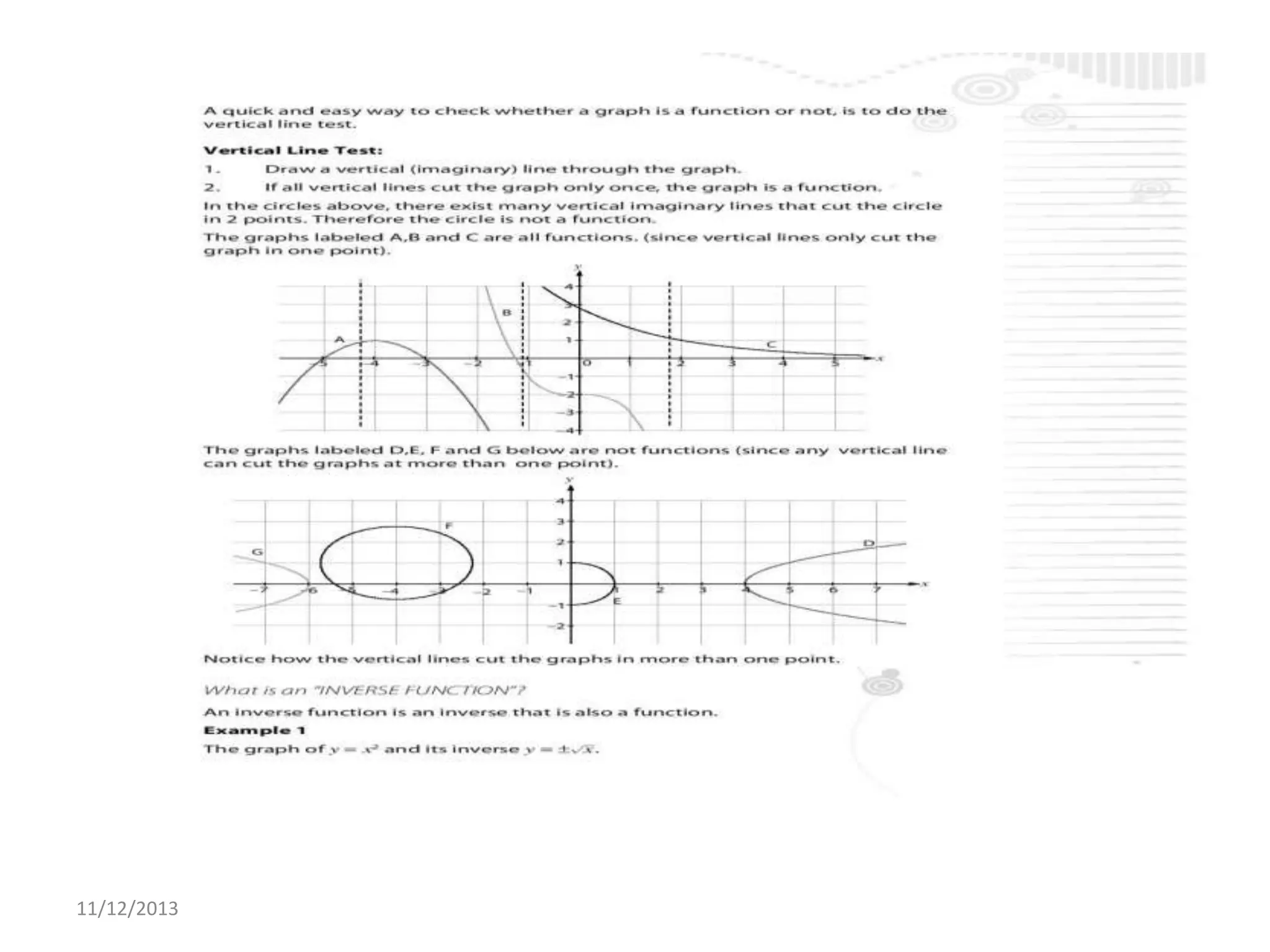
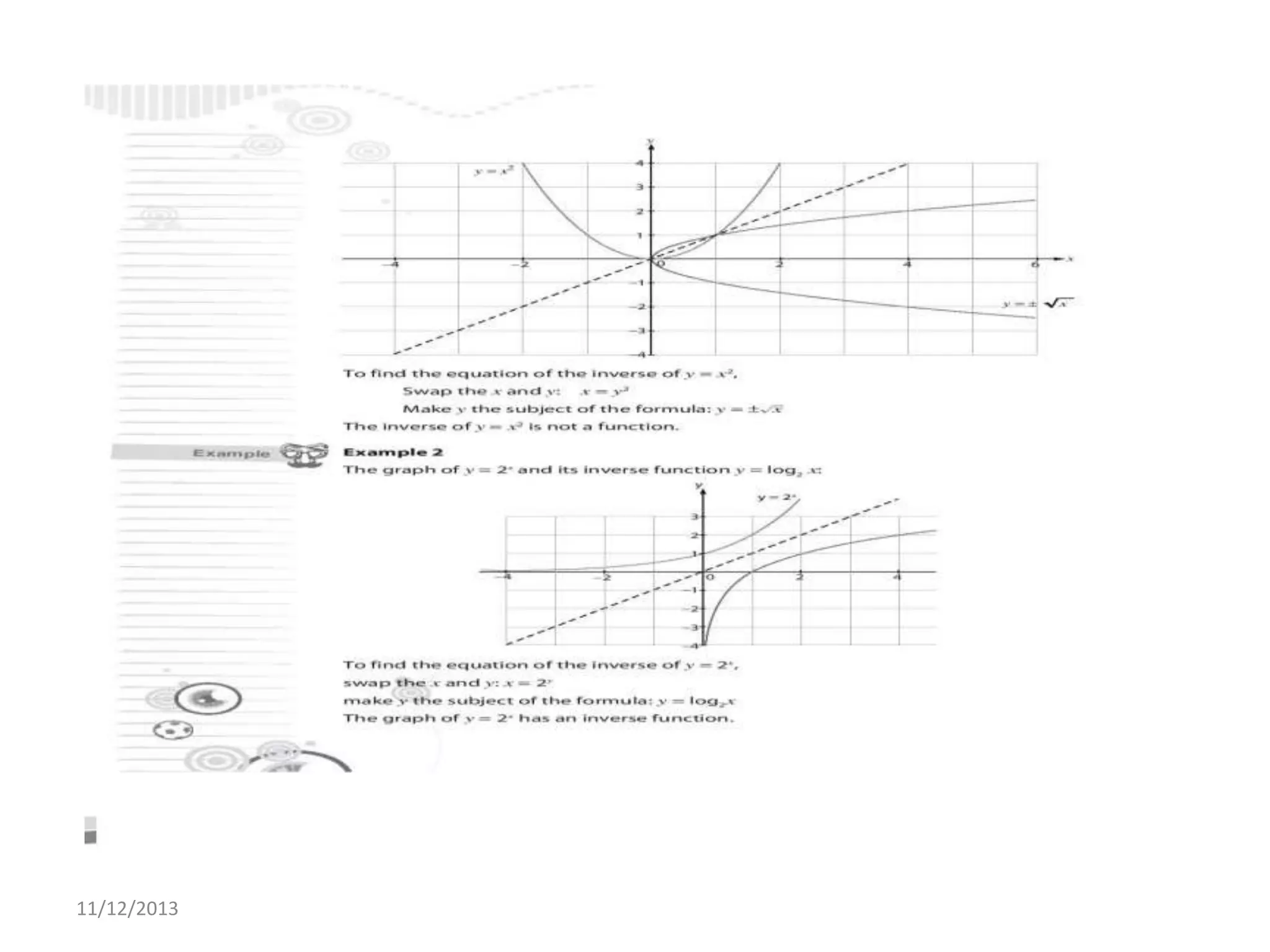
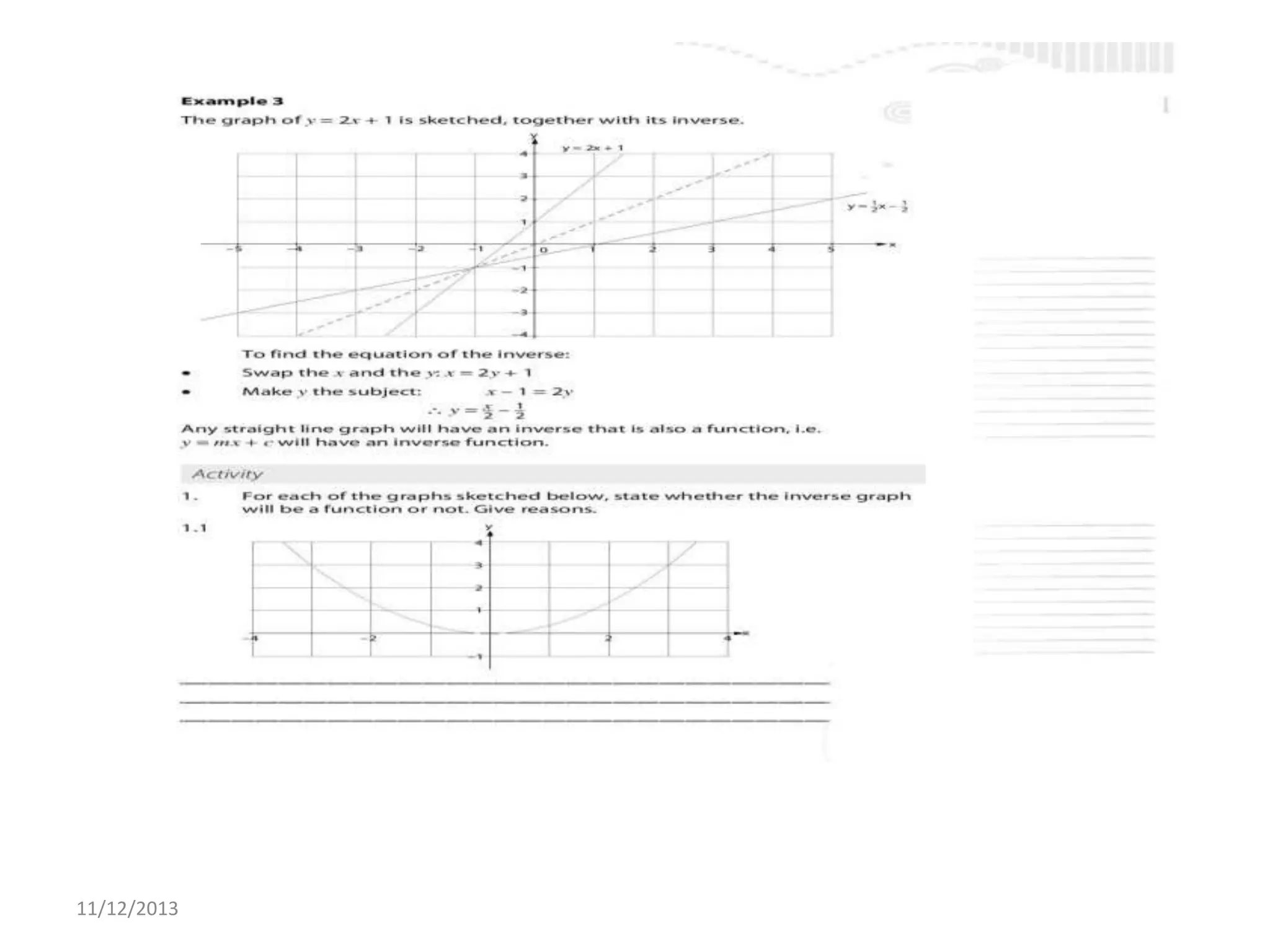
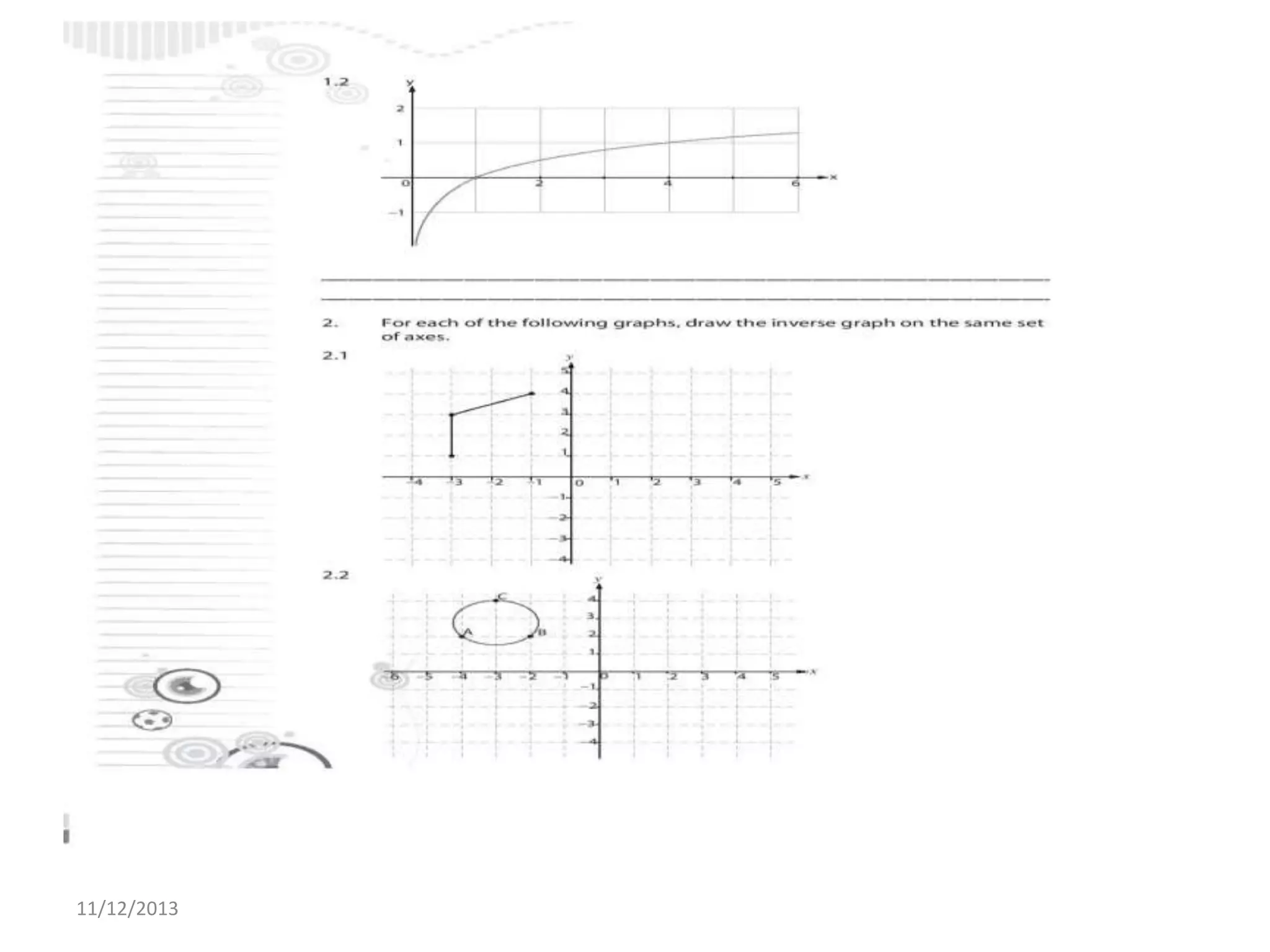
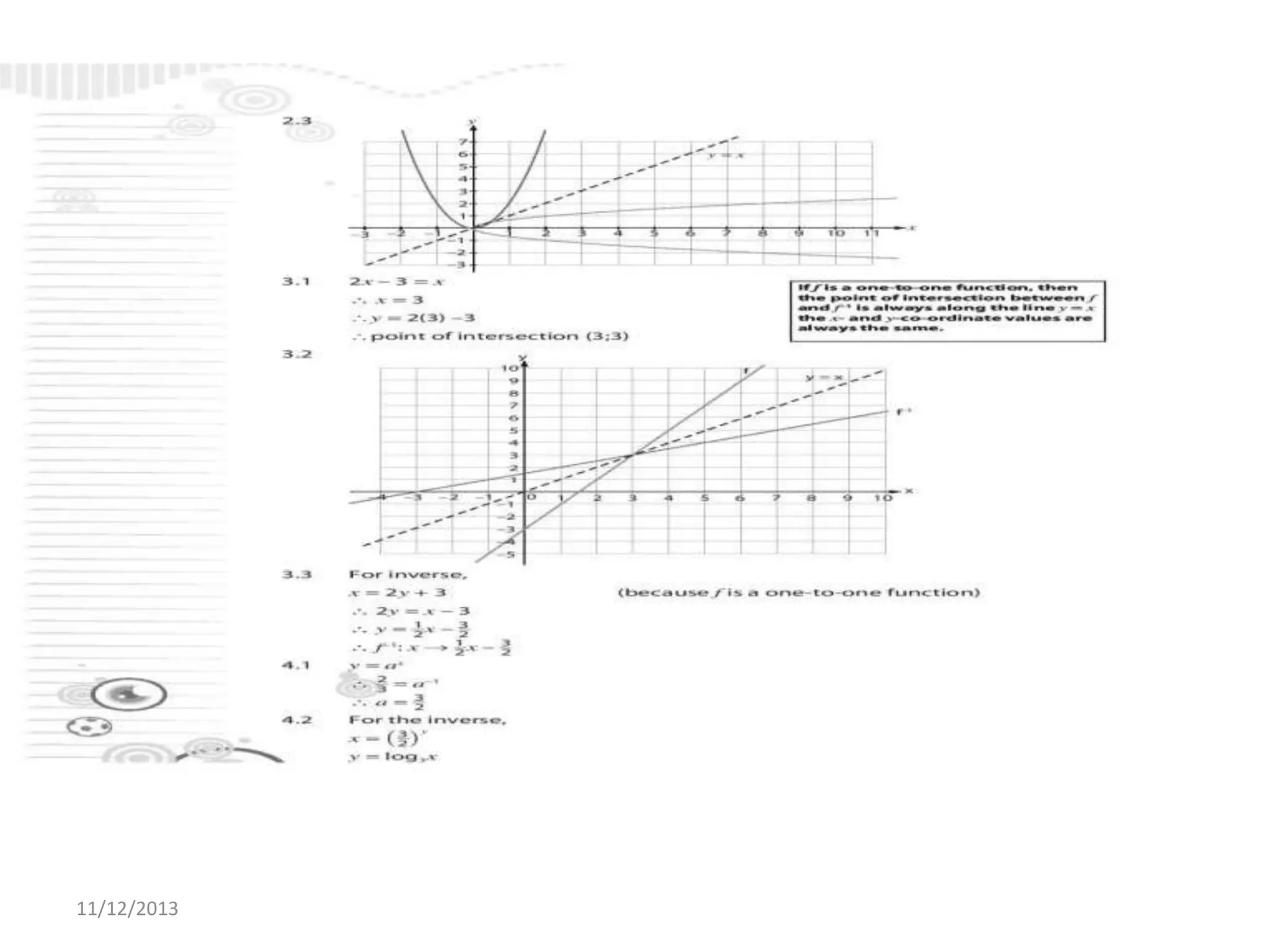
Il documento tratta la rappresentazione grafica delle funzioni inverse. Questi grafici sono essenziali per comprendere il comportamento delle funzioni e le loro inversi. La data di pubblicazione è l'11 dicembre 2013.