Download as PDF, PPTX








![Yet…..Data Preservation in High
Energy Physics?
Data from high–energy physics (HEP)
experiments are collected with significant
financial and human effort and are in many
cases unique. At the same time, HEP has no
coherent strategy for data preservation and re–
use, and many important and complex data sets
are simply lost.
David M. South, on behalf of the ICFA DPHEP Study Group
arXiv:1101.3186v1 [hep-ex]](https://image.slidesharecdn.com/grahampryor-120515090005-phpapp02/75/Graham-Pryor-9-2048.jpg)
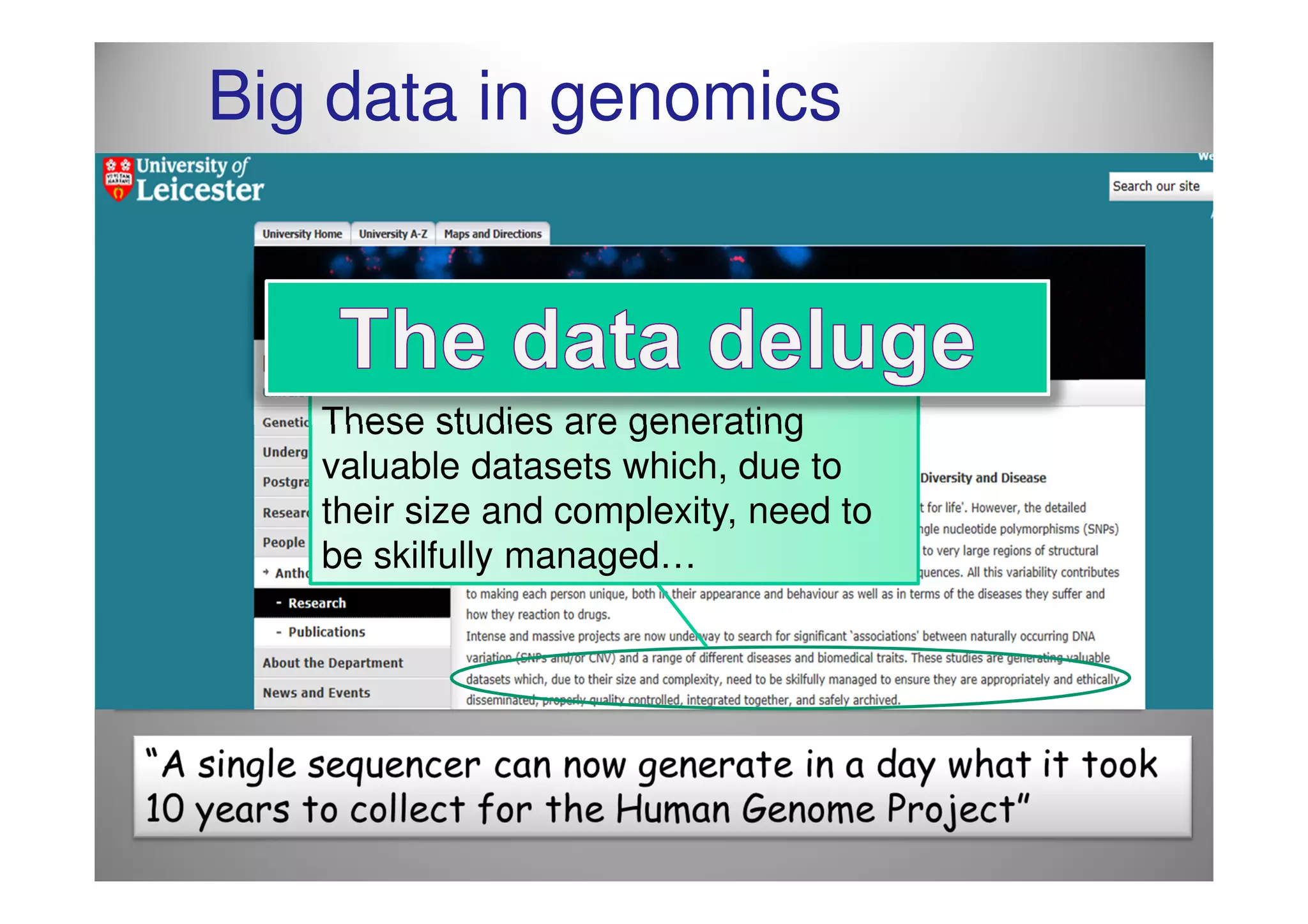














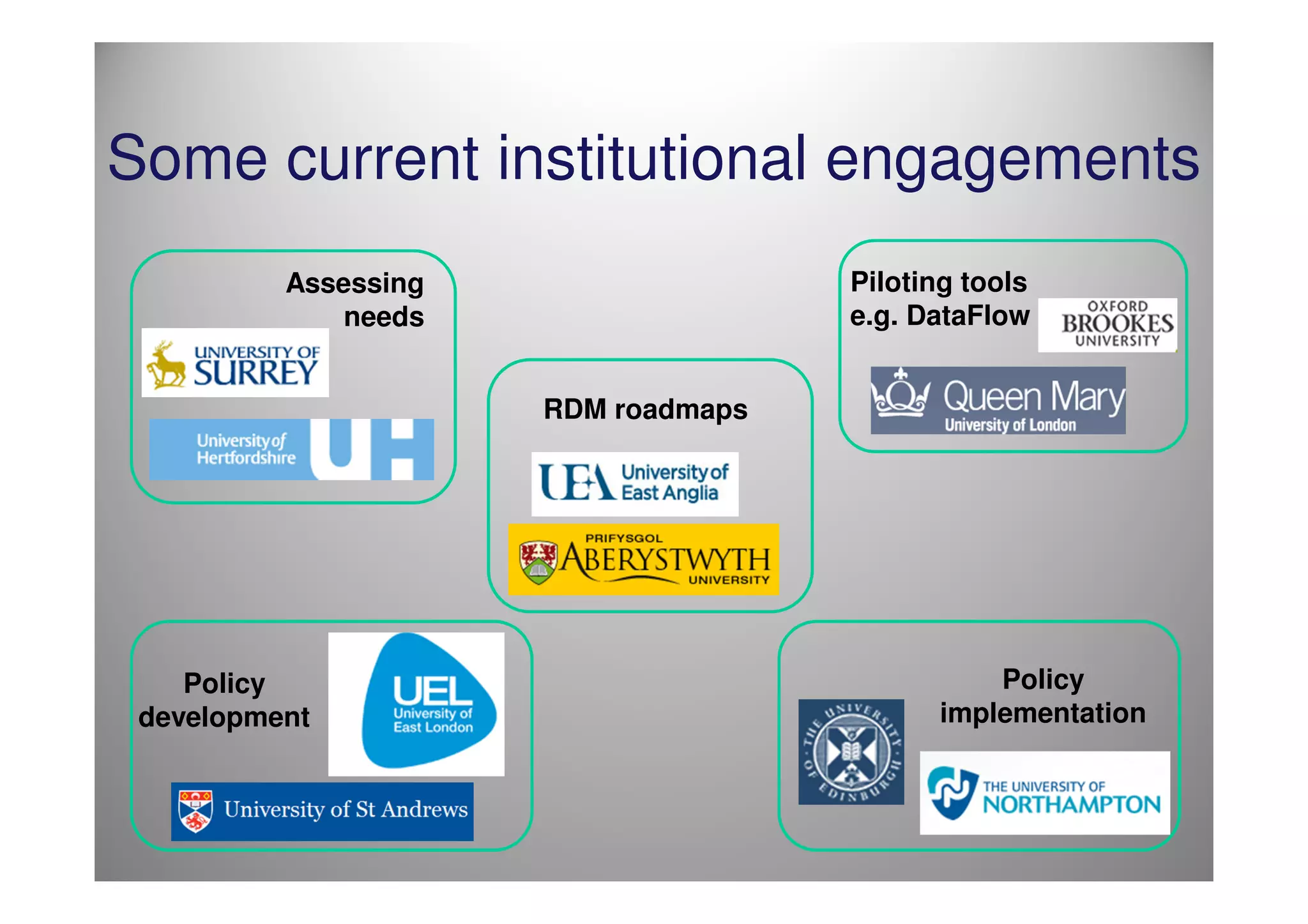










The document discusses the challenges and complexities of managing big data, particularly in research contexts like high-energy physics and genomics. It highlights the Digital Curation Centre's efforts to enhance data management capabilities in the UK, emphasizing the need for compliance with funding requirements and the importance of effective data preservation strategies. The document also critiques current practices and suggests the necessity for improved infrastructure and training in research data management.





































































































