Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
なおき きしだ
PDF, PPTX
9,433 views
GPUをJavaで使う話(Java Casual Talks #1)
GPUとは何か、GPUをJavaで使うにはどうするか
Software
◦
Read more
5
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 29
2
/ 29
3
/ 29
4
/ 29
Most read
5
/ 29
6
/ 29
7
/ 29
8
/ 29
9
/ 29
Most read
10
/ 29
11
/ 29
12
/ 29
13
/ 29
14
/ 29
15
/ 29
16
/ 29
17
/ 29
18
/ 29
19
/ 29
20
/ 29
21
/ 29
22
/ 29
23
/ 29
24
/ 29
25
/ 29
26
/ 29
27
/ 29
28
/ 29
29
/ 29
More Related Content
PDF
constexpr関数はコンパイル時処理。これはいい。実行時が霞んで見える。cpuの嬌声が聞こえてきそうだ
by
Genya Murakami
PPTX
async/await のしくみ
by
信之 岩永
PDF
マルチコアを用いた画像処理
by
Norishige Fukushima
PPTX
C# 8.0 null許容参照型
by
信之 岩永
PDF
C/C++プログラマのための開発ツール
by
MITSUNARI Shigeo
PDF
プログラムを高速化する話
by
京大 マイコンクラブ
PDF
勉強か?趣味か?人生か?―プログラミングコンテストとは
by
Takuya Akiba
PDF
Cognitive Complexity でコードの複雑さを定量的に計測しよう
by
Shuto Suzuki
constexpr関数はコンパイル時処理。これはいい。実行時が霞んで見える。cpuの嬌声が聞こえてきそうだ
by
Genya Murakami
async/await のしくみ
by
信之 岩永
マルチコアを用いた画像処理
by
Norishige Fukushima
C# 8.0 null許容参照型
by
信之 岩永
C/C++プログラマのための開発ツール
by
MITSUNARI Shigeo
プログラムを高速化する話
by
京大 マイコンクラブ
勉強か?趣味か?人生か?―プログラミングコンテストとは
by
Takuya Akiba
Cognitive Complexity でコードの複雑さを定量的に計測しよう
by
Shuto Suzuki
What's hot
PDF
PlaySQLAlchemy: SQLAlchemy入門
by
泰 増田
PDF
Pythonによる黒魔術入門
by
大樹 小倉
PDF
モジュールの凝集度・結合度・インタフェース
by
Hajime Yanagawa
PPTX
C#で速度を極めるいろは
by
Core Concept Technologies
PDF
関数型プログラミングのデザインパターンひとめぐり
by
Kazuyuki TAKASE
PDF
分散システムの限界について知ろう
by
Shingo Omura
PDF
SQLアンチパターン - 開発者を待ち受ける25の落とし穴 (拡大版)
by
Takuto Wada
PDF
ゲーム開発者のための C++11/C++14
by
Ryo Suzuki
PDF
誰もAddressableについて語らないなら、自分が語るしかない…ッッッッ
by
Tatsuhiko Yamamura
PDF
CEDEC 2018 最速のC#の書き方 - C#大統一理論へ向けて性能的課題を払拭する
by
Yoshifumi Kawai
PPTX
世界一わかりやすいClean Architecture
by
Atsushi Nakamura
PDF
プログラムを高速化する話Ⅱ 〜GPGPU編〜
by
京大 マイコンクラブ
PDF
KubeCon + CloudNativeCon Europe 2022 Recap / Kubernetes Meetup Tokyo #51 / #k...
by
Preferred Networks
PDF
できる!並列・並行プログラミング
by
Preferred Networks
PDF
Djangoのエントリポイントとアプリケーションの仕組み
by
Shinya Okano
PDF
ウェーブレット木の世界
by
Preferred Networks
PDF
新しい並列for構文のご提案
by
yohhoy
PPTX
Androidで画像処理リベンジ
by
Daisuke Takai
PDF
SQLアンチパターン 幻の第26章「とりあえず削除フラグ」
by
Takuto Wada
PDF
中3女子でもわかる constexpr
by
Genya Murakami
PlaySQLAlchemy: SQLAlchemy入門
by
泰 増田
Pythonによる黒魔術入門
by
大樹 小倉
モジュールの凝集度・結合度・インタフェース
by
Hajime Yanagawa
C#で速度を極めるいろは
by
Core Concept Technologies
関数型プログラミングのデザインパターンひとめぐり
by
Kazuyuki TAKASE
分散システムの限界について知ろう
by
Shingo Omura
SQLアンチパターン - 開発者を待ち受ける25の落とし穴 (拡大版)
by
Takuto Wada
ゲーム開発者のための C++11/C++14
by
Ryo Suzuki
誰もAddressableについて語らないなら、自分が語るしかない…ッッッッ
by
Tatsuhiko Yamamura
CEDEC 2018 最速のC#の書き方 - C#大統一理論へ向けて性能的課題を払拭する
by
Yoshifumi Kawai
世界一わかりやすいClean Architecture
by
Atsushi Nakamura
プログラムを高速化する話Ⅱ 〜GPGPU編〜
by
京大 マイコンクラブ
KubeCon + CloudNativeCon Europe 2022 Recap / Kubernetes Meetup Tokyo #51 / #k...
by
Preferred Networks
できる!並列・並行プログラミング
by
Preferred Networks
Djangoのエントリポイントとアプリケーションの仕組み
by
Shinya Okano
ウェーブレット木の世界
by
Preferred Networks
新しい並列for構文のご提案
by
yohhoy
Androidで画像処理リベンジ
by
Daisuke Takai
SQLアンチパターン 幻の第26章「とりあえず削除フラグ」
by
Takuto Wada
中3女子でもわかる constexpr
by
Genya Murakami
Similar to GPUをJavaで使う話(Java Casual Talks #1)
PDF
コンピューティングとJava~なにわTECH道
by
なおき きしだ
PPTX
Javaで簡単にgpgpu aparapi
by
Ken'ichi Sakiyama
PDF
Maxwell と Java CUDAプログラミング
by
NVIDIA Japan
PPTX
もしも… Javaでヘテロジニアスコアが使えたら…
by
Yasumasa Suenaga
KEY
NVIDIA Japan Seminar 2012
by
Takuro Iizuka
PDF
Introduction to OpenCL (Japanese, OpenCLの基礎)
by
Takahiro Harada
KEY
PyOpenCLによるGPGPU入門
by
Yosuke Onoue
PDF
これからのコンピューティングの変化とJava-JJUG CCC 2015 Fall
by
なおき きしだ
KEY
CUDAを利用したPIV解析の高速化
by
翔新 史
PDF
1072: アプリケーション開発を加速するCUDAライブラリ
by
NVIDIA Japan
PDF
2015年度GPGPU実践基礎工学 第15回 GPGPU開発環境 (OpenCL)
by
智啓 出川
PDF
OpenCLに触れてみよう
by
You&I
PDF
Altera SDK for OpenCL解体新書 : ホストとデバイスの関係
by
Mr. Vengineer
PDF
2015年度GPGPU実践プログラミング 第3回 GPGPUプログラミング環境
by
智啓 出川
PDF
Cuda
by
Shumpei Hozumi
PDF
これからのコンピューティングとJava(Hacker Tackle)
by
なおき きしだ
PDF
Hello, DirectCompute
by
dasyprocta
PDF
PEZY-SC programming overview
by
Ryo Sakamoto
DOC
GPGPUによるパーソナルスーパーコンピュータの可能性
by
Yusaku Watanabe
KEY
GTC2011 Japan
by
Takuro Iizuka
コンピューティングとJava~なにわTECH道
by
なおき きしだ
Javaで簡単にgpgpu aparapi
by
Ken'ichi Sakiyama
Maxwell と Java CUDAプログラミング
by
NVIDIA Japan
もしも… Javaでヘテロジニアスコアが使えたら…
by
Yasumasa Suenaga
NVIDIA Japan Seminar 2012
by
Takuro Iizuka
Introduction to OpenCL (Japanese, OpenCLの基礎)
by
Takahiro Harada
PyOpenCLによるGPGPU入門
by
Yosuke Onoue
これからのコンピューティングの変化とJava-JJUG CCC 2015 Fall
by
なおき きしだ
CUDAを利用したPIV解析の高速化
by
翔新 史
1072: アプリケーション開発を加速するCUDAライブラリ
by
NVIDIA Japan
2015年度GPGPU実践基礎工学 第15回 GPGPU開発環境 (OpenCL)
by
智啓 出川
OpenCLに触れてみよう
by
You&I
Altera SDK for OpenCL解体新書 : ホストとデバイスの関係
by
Mr. Vengineer
2015年度GPGPU実践プログラミング 第3回 GPGPUプログラミング環境
by
智啓 出川
Cuda
by
Shumpei Hozumi
これからのコンピューティングとJava(Hacker Tackle)
by
なおき きしだ
Hello, DirectCompute
by
dasyprocta
PEZY-SC programming overview
by
Ryo Sakamoto
GPGPUによるパーソナルスーパーコンピュータの可能性
by
Yusaku Watanabe
GTC2011 Japan
by
Takuro Iizuka
More from なおき きしだ
PDF
GraalVMの紹介とTruffleでPHPぽい言語を実装したら爆速だった話
by
なおき きしだ
PDF
GraalVM at Fukuoka LT
by
なおき きしだ
PDF
これからのコンピューティングの変化とこれからのプログラミング in 福岡 2018/12/8
by
なおき きしだ
PDF
GraalVMについて
by
なおき きしだ
PDF
VRカメラが楽しいのでブラウザで見たくなった話
by
なおき きしだ
PDF
最近のJava事情
by
なおき きしだ
PDF
怖いコードの話 2018/7/18
by
なおき きしだ
PDF
Java新機能観察日記 - JJUGナイトセミナー
by
なおき きしだ
PDF
プログラマになるためになにを勉強するか at 九州学生エンジニアLT大会
by
なおき きしだ
PDF
これからのコンピューティングの変化とこれからのプログラミング at 広島
by
なおき きしだ
PDF
Summary of JDK10 and What will come into JDK11
by
なおき きしだ
PDF
Summary of JDK10 and What will come into JDK11
by
なおき きしだ
PDF
Java10 and Java11 at JJUG CCC 2018 Spr
by
なおき きしだ
PPTX
New thing in JDK10 even that scala-er should know
by
なおき きしだ
PPTX
Java Release Model (on Scala Matsuri)
by
なおき きしだ
PDF
これからのJava言語と実行環境
by
なおき きしだ
PDF
JavaOne報告2017
by
なおき きしだ
PDF
JavaOne2017で感じた、Javaのいまと未来 in 大阪
by
なおき きしだ
PDF
Java8 コーディングベストプラクティス and NetBeansのメモリログから...
by
なおき きしだ
PDF
NetBeansのメモリ使用ログから機械学習できしだが働いてるかどうか判定する
by
なおき きしだ
GraalVMの紹介とTruffleでPHPぽい言語を実装したら爆速だった話
by
なおき きしだ
GraalVM at Fukuoka LT
by
なおき きしだ
これからのコンピューティングの変化とこれからのプログラミング in 福岡 2018/12/8
by
なおき きしだ
GraalVMについて
by
なおき きしだ
VRカメラが楽しいのでブラウザで見たくなった話
by
なおき きしだ
最近のJava事情
by
なおき きしだ
怖いコードの話 2018/7/18
by
なおき きしだ
Java新機能観察日記 - JJUGナイトセミナー
by
なおき きしだ
プログラマになるためになにを勉強するか at 九州学生エンジニアLT大会
by
なおき きしだ
これからのコンピューティングの変化とこれからのプログラミング at 広島
by
なおき きしだ
Summary of JDK10 and What will come into JDK11
by
なおき きしだ
Summary of JDK10 and What will come into JDK11
by
なおき きしだ
Java10 and Java11 at JJUG CCC 2018 Spr
by
なおき きしだ
New thing in JDK10 even that scala-er should know
by
なおき きしだ
Java Release Model (on Scala Matsuri)
by
なおき きしだ
これからのJava言語と実行環境
by
なおき きしだ
JavaOne報告2017
by
なおき きしだ
JavaOne2017で感じた、Javaのいまと未来 in 大阪
by
なおき きしだ
Java8 コーディングベストプラクティス and NetBeansのメモリログから...
by
なおき きしだ
NetBeansのメモリ使用ログから機械学習できしだが働いてるかどうか判定する
by
なおき きしだ
GPUをJavaで使う話(Java Casual Talks #1)
1.
GPUをJavaで使う話 (来れたので) 2015/10/16 きしだ なおき
2.
自己紹介 ● 最近、化物語を見ました。
3.
今日の話 ● GPU速そう ● Cめんどい ● Javaでやりたい ● ディープラーニング書いてみた ● 高速化してみた
4.
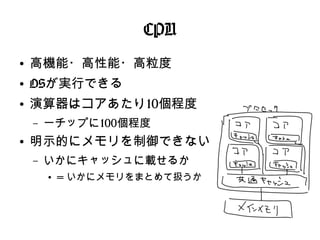
CPU ● 高機能・高性能・高粒度 ● OSが実行できる ● 演算器はコアあたり10個程度 – 一チップに100個程度 ● 明示的にメモリを制御できない – いかにキャッシュに載せるか ● =
いかにメモリをまとめて扱うか
5.
GPU ● GPU – ちょうたくさんコアがある – 同じ処理を行う –
行列計算に向いてる ● GTX 970 – 1664コア! – 衝動買い!
6.
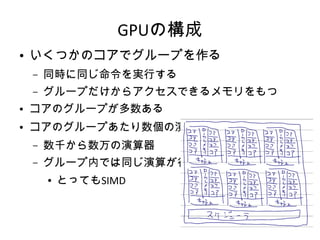
GPUの構成 ● いくつかのコアでグループを作る – 同時に同じ命令を実行する – グループだけからアクセスできるメモリをもつ ● コアのグループが多数ある ● コアのグループあたり数個の演算器 –
数千から数万の演算器 – グループ内では同じ演算が行われる ● とってもSIMD
7.
GPUの製品 ● NVIDIA – GeForce –
Tesla ● GPGPU専用 ● AMD – Radeon ● Intel – Intel HD Graphics ● CPUチップに内蔵されたGPU
8.
GPGPU ● General Purpose
computing on GPU ● GPUで汎用計算 ● シミュレーションとか速い ● 最近のスーパーコンピュータはGPUがたくさん載って る
9.
GPGPU環境 ● CUDA – NVIDIA製品用 ●
DirectX – Windows専用 ● OpenCL – OpenGLとか作った団体(Khronos Group)が策定 – さまざまなデバイスで使える – FPGAでも使えたりする
10.
JavaでGPU ● Aparapi – JavaコードをOpenCLに変換 ● OpenCLを呼び出す – OpenCL:並列計算フレームワーク ● AMD始め、IntelやNVIDIAなどが参加 –
JOCL(jogamp.org) – JOCL(jocl.org) – JavaCL ● Project Sumatra – Stream処理を自動的にGPUで行う – Java VMに組み込む
11.
Aparapi ● A PARalell API ● 実行時にJavaコードをOpenCLに変換 ● https://code.google.com/p/aparapi/
12.
Aparapiコード public class AparapiKernel
extends Kernel{ float[] inputA; float[] inputB; float[] output; @Override public void run() { int gid = getGlobalId(); output[gid] = inputA[gid] * inputB[gid]; } public static void main(String[] args) { AparapiKernel kernel = new AparapiKernel(); int elementCount = 1_444_477; kernel.inputA = new float[elementCount]; kernel.inputB = new float[elementCount]; kernel.output = new float[elementCount]; fillBuffer(kernel.inputA); fillBuffer(kernel.inputB); kernel.execute(elementCount); } }
13.
バグがある・・・ • 三項演算子のカッコが反映されない – (修正してプルリクなげてとりこまれてます) •
CPUとの結果と比較するテストを用意したほうがいい – けど、丸めの違いを考慮するの面倒 void proc(int fxy) { float d = (result[fxy] >= 0 ? 1 : 0) * delta[fxy]; tempBiasDelta[fxy] = learningRate * d; } void kishida_cnn_kernels_ConvolutionBackwordBiasKernel__proc(This *this, int fxy){ float d = (float)(this->result[fxy]>=0.0f)?1:0 * this->delta[fxy]; this->tempBiasDelta[fxy] = this->learningRate * d; return; } ↓
14.
JOCL(jogamp.org) ● OpenCLを薄くラップ ● https://jogamp.org/jocl/www/
15.
JOCLのコード String KERNEL_CODE = "kernel
void add(global const float* inputA," + " global const float* inputB," + " global float* output," + " uint numElements){" + " size_t gid = get_global_id(0);" + " if(gid >= numElements){" + " return;" + " }" + " output[gid] = inputA[gid] + inputB[gid];" + "}"; CLContext ctx = CLContext.create(); CLDevice device = ctx.getMaxFlopsDevice(); CLCommandQueue queue = device.createCommandQueue(); CLProgram program = ctx.createProgram(KERNEL_CODE).build(); int elementCount = 1_444_477; int localWorkSize = Math.min(device.getMaxWorkGroupSize(), 256); int globalWorkSize = ((elementCount + localWorkSize - 1) / localWorkSize) * localWorkSize; CLBuffer<FloatBuffer> clBufferA = ctx.createFloatBuffer( elementCount, CLMemory.Mem.READ_ONLY); CLBuffer<FloatBuffer> clBufferB = ctx.createFloatBuffer( elementCount, CLMemory.Mem.READ_ONLY); CLBuffer<FloatBuffer> clBufferC = ctx.createFloatBuffer( elementCount, CLMemory.Mem.READ_WRITE); fillBuffer(clBufferA.getBuffer()); fillBuffer(clBufferB.getBuffer()); CLKernel kernel = program.createCLKernel("add"); kernel .putArgs(clBufferA, clBufferB, clBufferC) .putArg(elementCount); queue.putWriteBuffer(clBufferA, false) .putWriteBuffer(clBufferB, false) .put1DRangeKernel(kernel, 0, globalWorkSize, localWorkSize) .putReadBuffer(clBufferC, true);
16.
比較 ● Aparapi – めちゃ楽 – GPUの性能出しにくい ● JOCL –
ちょっと面倒 – GPUの性能出しやすい
17.
Sumatra ● Java VMに組み込むことを目標 ● 実装難しそう ● コード書くのもわかりにくそう ● 性能出しにくそう ● Java VMに組み込むほどメリットなさそう –
性能欲しい人はOpenCL使うよね
18.
と思ったら ● 「Sumatra is not
in active development for now.(2015/5/1) 」 http://mail.openjdk.java.net/pipermail/sumatra-dev/2015- May/000310.html
19.
ところでディープラーニング 実装してみました
20.
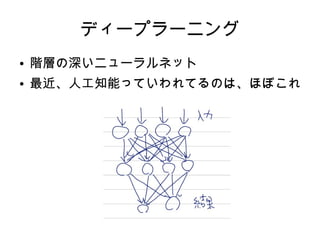
ディープラーニング ● 階層の深いニューラルネット ● 最近、人工知能っていわれてるのは、ほぼこれ
21.
Aparapiを使う ● 15枚/分→75枚/分 ● 1400万枚の画像処理が650日→130日!
22.
DoubleではなくFloatを使う ● ディープラーニングに精度は不要 ● 精度が半分になれば並列度があげれる ● データの転送量が減る ● 75枚/分→95枚/分 ● 1400万枚の画像処理が130日→102日!
23.
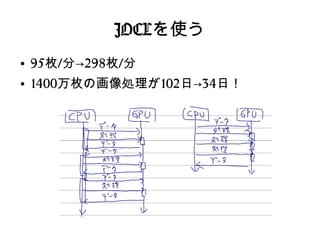
JOCLを使う ● 95枚/分→298枚/分 ● 1400万枚の画像処理が102日→34日!
24.
GPUローカルメモリを使う ● 298枚/分→300枚/分 ● 1400万枚の画像処理が34日→33日
25.
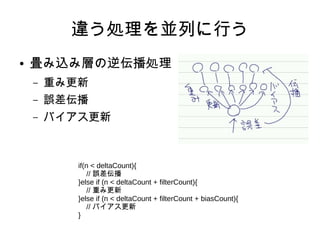
違う処理を並列に行う ● 畳み込み層の逆伝播処理 – 重み更新 – 誤差伝播 –
バイアス更新 if(n < deltaCount){ // 誤差伝播 }else if (n < deltaCount + filterCount){ // 重み更新 }else if (n < deltaCount + filterCount + biasCount){ // バイアス更新 }
26.
条件分岐の注意 ● ひとつのグループにif/else両方走ると if→elseの順に両方の処理が走る ● ひとつのグループではどちらかになるように調 整が必要 ● 32個単位くらい
27.
画面表示をはぶく ● 画面表示のためにGPU→CPU間転送が行われて いた ● 300枚/分→320枚/分 ● 1400万枚の画像処理が34日→30日
28.
結果 ● 機械学習 – まだ学習できてません・・・ ● オレ学習 – GPUのプログラミングが学習できました。
29.
まとめ ● GPUで高速化たのしい ● 世の中ね、顔かお金かなのよ
Download











![Aparapiコード
public class AparapiKernel extends Kernel{
float[] inputA;
float[] inputB;
float[] output;
@Override
public void run() {
int gid = getGlobalId();
output[gid] = inputA[gid] * inputB[gid];
}
public static void main(String[] args) {
AparapiKernel kernel = new AparapiKernel();
int elementCount = 1_444_477;
kernel.inputA = new float[elementCount];
kernel.inputB = new float[elementCount];
kernel.output = new float[elementCount];
fillBuffer(kernel.inputA);
fillBuffer(kernel.inputB);
kernel.execute(elementCount);
}
}](https://image.slidesharecdn.com/gpuonjava20151016-151019120506-lva1-app6892/85/GPU-Java-Java-Casual-Talks-1-12-320.jpg)
![バグがある・・・
• 三項演算子のカッコが反映されない
– (修正してプルリクなげてとりこまれてます)
• CPUとの結果と比較するテストを用意したほうがいい
– けど、丸めの違いを考慮するの面倒
void proc(int fxy) {
float d = (result[fxy] >= 0 ? 1 : 0) * delta[fxy];
tempBiasDelta[fxy] = learningRate * d;
}
void kishida_cnn_kernels_ConvolutionBackwordBiasKernel__proc(This
*this, int fxy){
float d = (float)(this->result[fxy]>=0.0f)?1:0 * this->delta[fxy];
this->tempBiasDelta[fxy] = this->learningRate * d;
return;
}
↓](https://image.slidesharecdn.com/gpuonjava20151016-151019120506-lva1-app6892/85/GPU-Java-Java-Casual-Talks-1-13-320.jpg)

![JOCLのコード
String KERNEL_CODE =
"kernel void add(global const float* inputA,"
+ " global const float* inputB,"
+ " global float* output,"
+ " uint numElements){"
+ " size_t gid = get_global_id(0);"
+ " if(gid >= numElements){"
+ " return;"
+ " }"
+ " output[gid] = inputA[gid] + inputB[gid];"
+ "}";
CLContext ctx = CLContext.create();
CLDevice device = ctx.getMaxFlopsDevice();
CLCommandQueue queue = device.createCommandQueue();
CLProgram program = ctx.createProgram(KERNEL_CODE).build();
int elementCount = 1_444_477;
int localWorkSize = Math.min(device.getMaxWorkGroupSize(), 256);
int globalWorkSize = ((elementCount + localWorkSize - 1) /
localWorkSize) * localWorkSize;
CLBuffer<FloatBuffer> clBufferA = ctx.createFloatBuffer(
elementCount, CLMemory.Mem.READ_ONLY);
CLBuffer<FloatBuffer> clBufferB = ctx.createFloatBuffer(
elementCount, CLMemory.Mem.READ_ONLY);
CLBuffer<FloatBuffer> clBufferC = ctx.createFloatBuffer(
elementCount, CLMemory.Mem.READ_WRITE);
fillBuffer(clBufferA.getBuffer());
fillBuffer(clBufferB.getBuffer());
CLKernel kernel = program.createCLKernel("add");
kernel
.putArgs(clBufferA, clBufferB, clBufferC)
.putArg(elementCount);
queue.putWriteBuffer(clBufferA, false)
.putWriteBuffer(clBufferB, false)
.put1DRangeKernel(kernel, 0, globalWorkSize, localWorkSize)
.putReadBuffer(clBufferC, true);](https://image.slidesharecdn.com/gpuonjava20151016-151019120506-lva1-app6892/85/GPU-Java-Java-Casual-Talks-1-15-320.jpg)