Download to read offline











![MONGODB
• Document - Oriented > db.users.findOne( {
"phones.mob" : "+792194234"
})
• Вторичные индексы {
"_id" : ObjectId
("4d94d822596f0e3f4d4a51bc"),
"name" : "Vasya",
• Язык запросов
"age" : 22,
"phones" : {
"mob" : "+792194234",
"home" : "+812342341"
• Атомарные апдейты },
"roles" : [
"admin",
"staff"
• Скорость ]
}
• Автошардинг и репликация](https://image.slidesharecdn.com/goozzycodecamp-110520070211-phpapp01/85/Goozy-21-320.jpg)
![ТЕСТЫ И CI
println("Trying to create group with slug $slug")
reqBody = [name: “Test Group”, slug: “test”, ... ]
builder.request(POST, JSON) {
requestContentType = URLENC
uri.path = "internal/groups/create.json"
body = reqBody
response.success = { resp, json ->
println(json.toString())
assertEquals(201, resp.status)
assert json.name == reqBody.name
assert json.description == reqBody.description
assert json.slug == reqBody.slug.toLowerCase()
assert json.creatorId == reqBody.creatorId
assert json.counters.members == 1
assert json.counters.notes == 0
}
response.failure = { resp, json ->
println(resp.statusLine)
println(json.toString())
fail("Request for creating group $slug failed.")
}
}](https://image.slidesharecdn.com/goozzycodecamp-110520070211-phpapp01/85/Goozy-23-320.jpg)




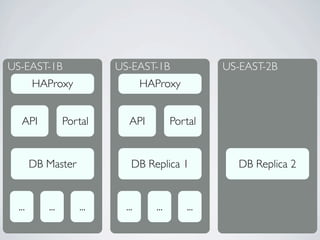





Документ описывает развитие архитектуры проекта Goozy, начиная с первой версии и её проблем и заканчивая требованиями к новой версии, способной обрабатывать до 1 миллиона пользователей. Рассматриваются технические аспекты, такие как использование Django, Scala и MongoDB, а также особенности хостинга и тестирования. В заключение упоминаются планы по автоматизации нагрузочного тестирования и внедрению новых технологий, включая Comet и WebSockets.



































































