Downloaded 25 times




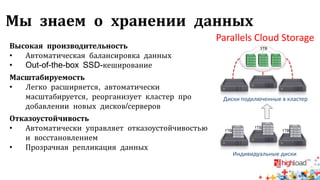
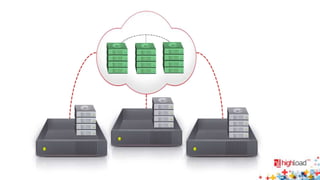
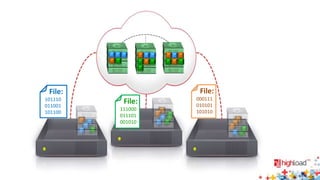
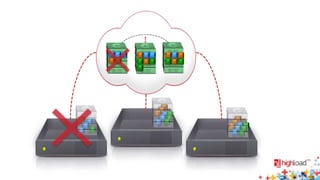


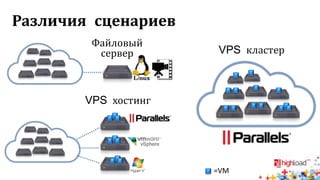


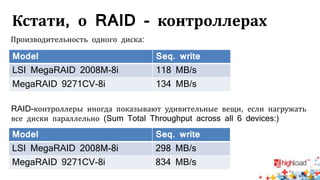


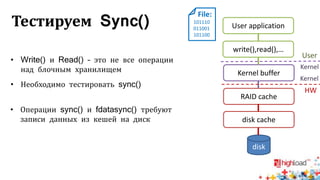
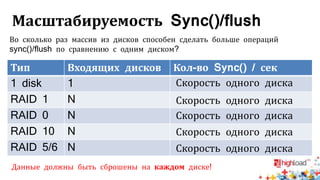
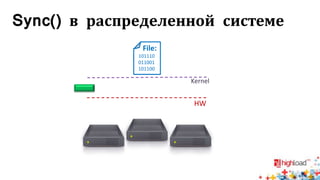
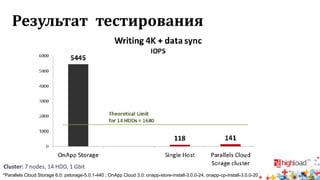


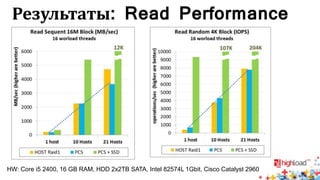
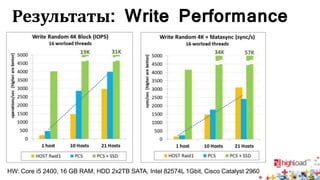




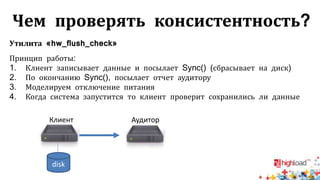







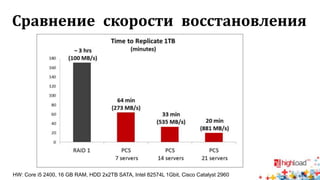





Документ посвящен тестированию производительности распределенных систем хранения данных и особенностям, связанным с этим процессом. Основное внимание уделяется методам проверки консистентности и производительности, а также выявлению ключевых факторов, влияющих на результаты тестирования. Рассматриваются практические рекомендации по проведению тестов и выбору оборудования для обеспечения высокой надежности систем.



































































