Downloaded 57 times



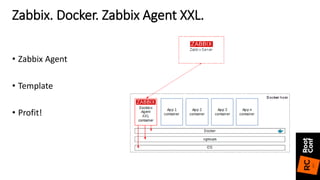
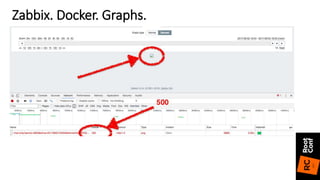
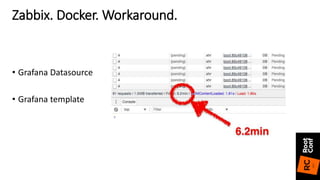

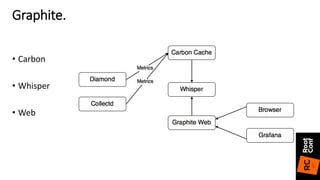


![• Clojure конфигурация
• OOM
• Кластерный InfluxDB
• InfluxDB 0.8/0.9
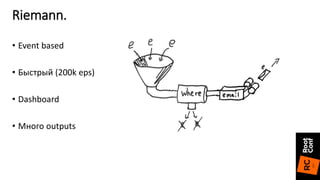
Riemann. InfluxDB. Проблемы.
[18228436.798056] Out of memory: Kill process 7657 (influxdb)
score 670 or sacrifice child
[18228436.838105] Killed process 7657 (influxdb)
total-vm:35068428kB, anon-rss:33083764kB, file-rss:880kB
(streams
(moving-time-window 600
(smap folds/mean
(where (> metric 1000)
(email "freezhan@mycompany.com")))))](https://image.slidesharecdn.com/2zabbixprometheusfevlake0-170630120932/85/Zabbix-Prometheus-fevlake-18-320.jpg)






![• Top5 docker containers by cpu
• topk(3, sum(rate(container_cpu_system_seconds_total[5m])) by (name))
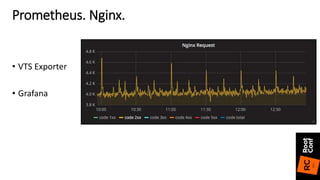
• RPS for site across all nginx nodes
• sum(irate(nginx_server_requests{host="*"}[5m]))
• Predict used space in some time
• predict_linear(node_filesystem_free{}[1h], 3600)
Prometheus. PromQL.](https://image.slidesharecdn.com/2zabbixprometheusfevlake0-170630120932/85/Zabbix-Prometheus-fevlake-29-320.jpg)




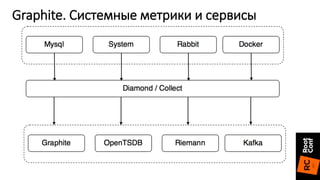
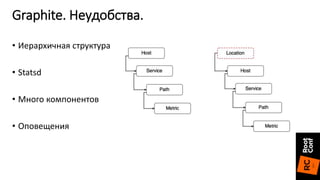
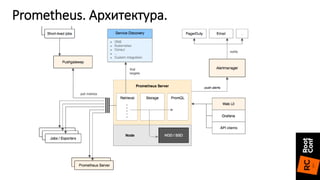
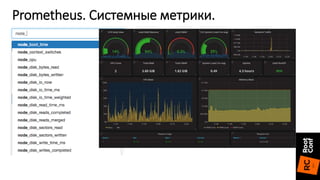
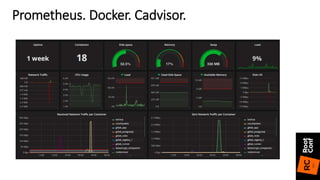
Документ описывает переход от Zabbix к Prometheus для мониторинга систем и приложений, включая детали настройки и конфигурации. Приведены преимущества Prometheus, такие как простота конфигурации, быстрая обработка данных и поддержка различных экспортеров. Также упоминаются проблемы, с которыми сталкиваются при использовании InfluxDB, и положительный опыт в использовании Prometheus с различными сервисами.
























































