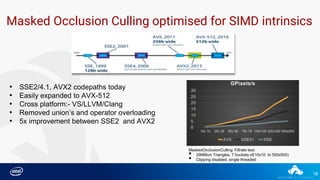
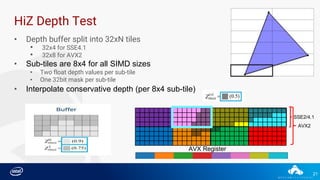
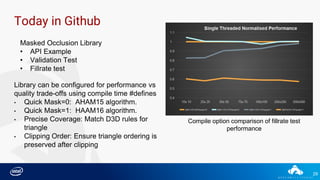
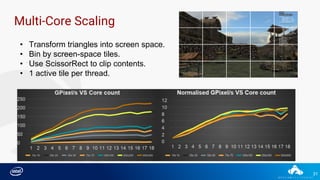
Downloaded 54 times





![5
Traditional software Occlusion Systems
Low Resolution depth buffer: [Col11]
• Requires manually inner
conservative for Occluders
Daniel Collin (DICE, GDC 2011)*
Hierarchical Z Buffer (HiZ) [Greene93]
• Rasterize to full resolution z buffer
• Create HiZ buffer
– Find maximum depth in each NxN tile
• Perform occlusion query with HiZ buffer
– Doesn’t fit with hierarchical scene traversal.
• Intel: Occlusion Culling Sample [CMK16]
*Other names and brands may be claimed as the property of others.](https://image.slidesharecdn.com/04mocgdcava-v1-180509191309/85/Masked-Occlusion-Culling-5-320.jpg)
![6
Masked Occlusion Culling
Based on Masked Occlusion Culling for Graphics Hardware [AHAM15]
• Created by Andersson M., Hasselgren J.,
Akenine-Möller T (AHAM)*
• Directly update HiZ buffer without
computing a full res z buffer during
rasterization
• Being conservative is the only requirement
-Depth must be >= to full resolution buffer for any pixel
Depth Buffer ( Near == dark, Far == white )
Approximate, conservative HiZ buffer
Conservative representation, picks furthest Z.
Queries will never cull a visible object](https://image.slidesharecdn.com/04mocgdcava-v1-180509191309/85/Masked-Occlusion-Culling-6-320.jpg)













![22
Building Hi-Z Buffer[AHAM15]
Simple example;
• Z0Max set to clear value or fully covered by
triangle](https://image.slidesharecdn.com/04mocgdcava-v1-180509191309/85/Masked-Occlusion-Culling-22-320.jpg)
![23
Building Hi-Z Buffer [AHAM15]
Simple example;
• Z0Max set to clear value or fully covered by
triangle
• Z1Max set to incoming triangle depth,
coverage mask is for 1 triangle.](https://image.slidesharecdn.com/04mocgdcava-v1-180509191309/85/Masked-Occlusion-Culling-23-320.jpg)
![24
Building Hi-Z Buffer [AHAM15]
Simple example;
• Z0Max set to clear value or fully covered by
triangle
• Z1Max set to incoming triangle depth
• 3 Options for the depth after next triangle;
• Discard Z1 if close to Z0Max
• Merge coverage with Z1Max
• Keep and discard Z1Max and coverage](https://image.slidesharecdn.com/04mocgdcava-v1-180509191309/85/Masked-Occlusion-Culling-24-320.jpg)
![25
Building Hi-Z Buffer [AHAM15]
Culled
Not Culled](https://image.slidesharecdn.com/04mocgdcava-v1-180509191309/85/Masked-Occlusion-Culling-25-320.jpg)


![28
Merging Buffers[HAAM16]
*Intel® Core™ i7-6950X
Terrain
Rasterization*
Foreground
Rasterization*
Total
Rasterization*
Merge
Time*
% spent
in merge
640x400 0.19 0.652 0.842 0.008 0.9%
1280x800 0.26 0.772 1.068 0.027 2.5%
1920x1080 0.31 0.834 1.144 0.051 4.4%
Working Layers
Reference Layers
Merge layers has more context to scene than
updating buffer on a per triangle basis.
Can “special case” hard to sort meshes.
• Triangle sort of individual mesh
• BSP tree](https://image.slidesharecdn.com/04mocgdcava-v1-180509191309/85/Masked-Occlusion-Culling-28-320.jpg)
![30
Update Tile, New Method [HAAM16]
Update [HAAM16] is quicker than original [AHAM15] , including Occlusion Queries
• z0max is the reference layer: Maximum value for the entire tile
z1max is the working layer: Maximum value for a subset of the tile
– Updated as
– New depth = max(z1max , ztrimax)
– New mask = TriangleMask OR LayerMask
• Whenever working layer mask is full, overwrite reference layer
[AHAM15] [HAAM16]](https://image.slidesharecdn.com/04mocgdcava-v1-180509191309/85/Masked-Occlusion-Culling-30-320.jpg)
![32
Masked Software Occlusion Culling
Benefits of Masked Occlusion Culling [AHAM15, HAAM16]
• Much less memory to read/write than full res z-buffer
• Updates use bitmasks – can process many pixels in parallel (i.e.
SSE/AVX)
• No need to compute per-pixel depths
• No need for conservative art assets
Cons:
• Doesn’t cull everything a full rez buffer would ( 98% accurate)*
• Conservative depth error is sensitive to render order
• Small amount of temporal instability in depth errors
*98% quoted in High Performance Graphics (2016) abstract
Addressed with HI-Z Buffer merging](https://image.slidesharecdn.com/04mocgdcava-v1-180509191309/85/Masked-Occlusion-Culling-32-320.jpg)




![37
● Halfres depth buffer
Occluder Rendering
● Using quick mask update method [HAAM16]
○ Depth discrepancies occur in mostly same places, size makes little difference
● Threaded rendering
○ Merging vs binned rendering
○ High overhead cost for binned rendering
○ Merging proved more suitable for us
○ Improved temporal stability is a nice bonus](https://image.slidesharecdn.com/04mocgdcava-v1-180509191309/85/Masked-Occlusion-Culling-37-320.jpg)



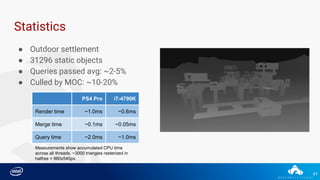




![46
References
• [AHAM15] ANDERSSON M., HASSELGREN J., AKENINE-MÖLLER T.: Masked Depth Culling for
Graphics Hardware. ACM Transactions on Graphics 34, 6 (2015), pp. 188:1–188:9
• [CMK16] CHANDRASEKARAN C., MCNABB D., KUAH K., FAUCONNEAU M., GIESEN F.: Software
Occlusion Culling. Published online at: https://software.intel.com/en-us/articles/
software-occlusion-culling, (2013–2016).
http://www.gdcvault.com/play/1017837/Why-Render-Hidden-Objects-Cull
• [Col11] COLLIN D.: Culling the Battlefield. Game Developer’s Conference (presentation), (2011).
http://www.gdcvault.com/play/1014491/Culling-the-Battlefield-Data-Oriented
• [Greene93] GREENE N., KASS M., MILLER G.: Hierarchical Z-Buffer Visibility. In Proceedings of
SIGGRAPH, (1993), pp. 231–238
• [HAAM16] HASSELGREN J., ANDERSSON M., AKENINE-MÖLLER T.: Masked Software Occlusion
Culling. High Performance Graphics, (2016)
https://www.slideshare.net/IntelSoftware/masked-software-occlusion-culling](https://image.slidesharecdn.com/04mocgdcava-v1-180509191309/85/Masked-Occlusion-Culling-46-320.jpg)

This document provides an overview of Masked Occlusion Culling (MOC), a technique for efficient CPU occlusion culling. It discusses traditional software occlusion culling methods and their limitations. MOC works by directly updating a hierarchical Z-buffer without computing the full resolution depth buffer. This allows culling many pixels in parallel using SIMD instructions. The document also describes how Avalanche Studios integrated MOC into their Apex engine. They use artist-placed boxes and quad occluders as well as low-poly terrain meshes. MOC provided a smoother, more modular workflow and was more efficient than their previous box culling approach.






















































































