Download to read offline
























![Fogg, B.J., Soohoo, C., Danielson, D.R., Marable, L., Stanford, J. and Tauber, E.R. (2003), “How do
users evaluate the credibility of web sites? A study with over 2,500 participants”,
Proceedings of the 2003 Conference on Designing for User Experiences, San Francisco,
CA, USA, pp. 1-15.
Fogg, B.J., Marshall, J., Laraki, O., Osipovich, A., Varma, C., Fang, N., Paul, J., Rangnekar, A.,
Shon, J., Swani, P. and Treinen, M. (2001), “What makes web sites credible? A report on a
large quantitative study”, Proceedings of the SIGCHI Conference on Human Factors in
Computing Systems, Seattle, Washington, USA, March 31-April 4, pp. 61-8.
Fogg, B.J., Marshal, J., Osipovich, A., Varma, C., Laraki, O., Fang, N., Paul, J., Rangnekar, A.,
Shon, J., Swani, P. and Treinen, M. (2000), “Elements that affect web credibility: early
results from a self-report study”, Proceedings of ACM CHI ’00 Extended Abstracts on
Human Factors in Computing Systems, The Hague, The Netherlands, pp. 287-8.
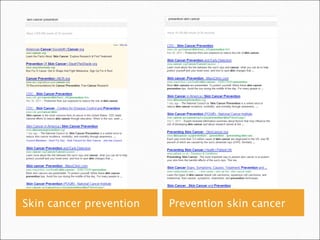
Deep Web vs. surface Web scores were obtained by using the BrightPlanet technology's selection by source option and then counting total
documents and documents above the quality scoring threshold.
Results and Discussion
This study is the first known quantification and characterization of the deep Web. Very little has been written or known of the deep Web.
Estimates of size and importance have been anecdotal at best and certainly underestimate scale. For example, Intelliseek's "invisible Web"
says that, "In our best estimates today, the valuable content housed within these databases and searchable sources is far bigger than the
800 million plus pages of the 'Visible Web.'" They also estimate total deep Web sources at about 50,000 or so. [35]
Ken Wiseman, who has written one of the most accessible discussions about the deep Web, intimates that it might be about equal in size to
the known Web. He also goes on to say, "I can safely predict that the invisible portion of the Web will continue to grow exponentially
before the tools to uncover the hidden Web are ready for general use." [36] A mid-1999 survey by About.com's Web search guide
concluded the size of the deep Web was "big and getting bigger." [37] A paper at a recent library science meeting suggested that only "a
relatively small fraction of the Web is accessible through search engines."[38]
The deep Web is about 500 times larger than the surface Web, with, on average, about three times higher quality based on our document
scoring methods on a per-document basis. On an absolute basis, total deep Web quality exceeds that of the surface Web by thousands of
times.](https://image.slidesharecdn.com/googlegarbagelsta2012-120326151610-phpapp02/85/Google-garbage-lsta-2012-35-320.jpg)

This document discusses the size and quality of information available on the "deep web" or non-searchable parts of the internet, as compared to the "surface web" or searchable parts. It finds that the deep web is about 500 times larger than the surface web, with documents in the deep web having an average quality score about 3 times higher per document. The total quality of information in the deep web vastly exceeds that of the surface web by thousands of times. The deep web has long been underestimated in size and importance, with some estimates placing it as large as the surface web or larger and growing exponentially.























































































