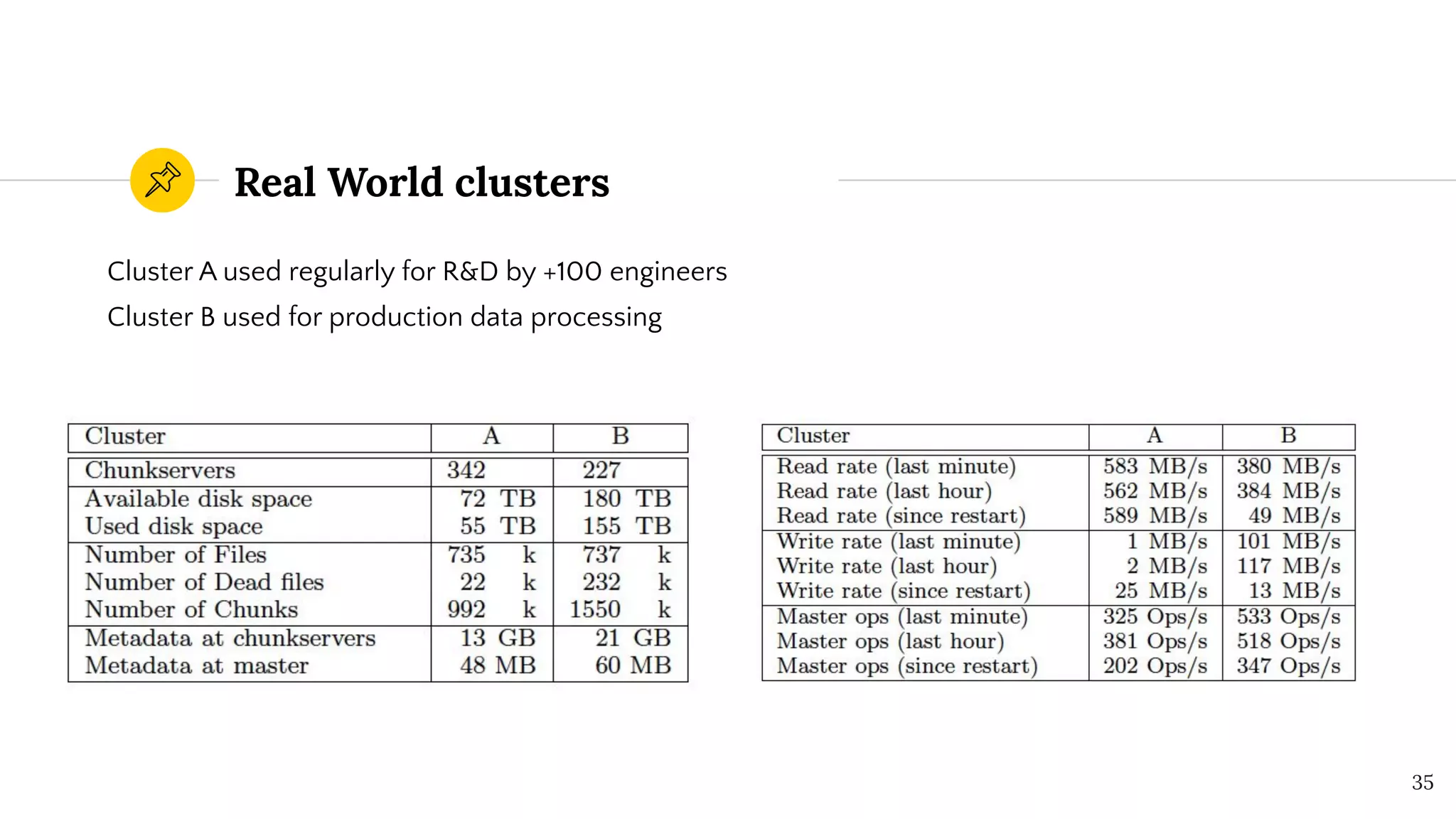
The Google File System was designed by Google to store and manage large files across thousands of commodity servers. It uses a single master to manage metadata and track file locations across chunkservers. Chunks are replicated for reliability and placed across racks to improve bandwidth utilization. The system provides high throughput for concurrent reads and writes through leases to maintain consistency and pipelining of data flows. Logs and replication are used to provide fault tolerance against server failures.