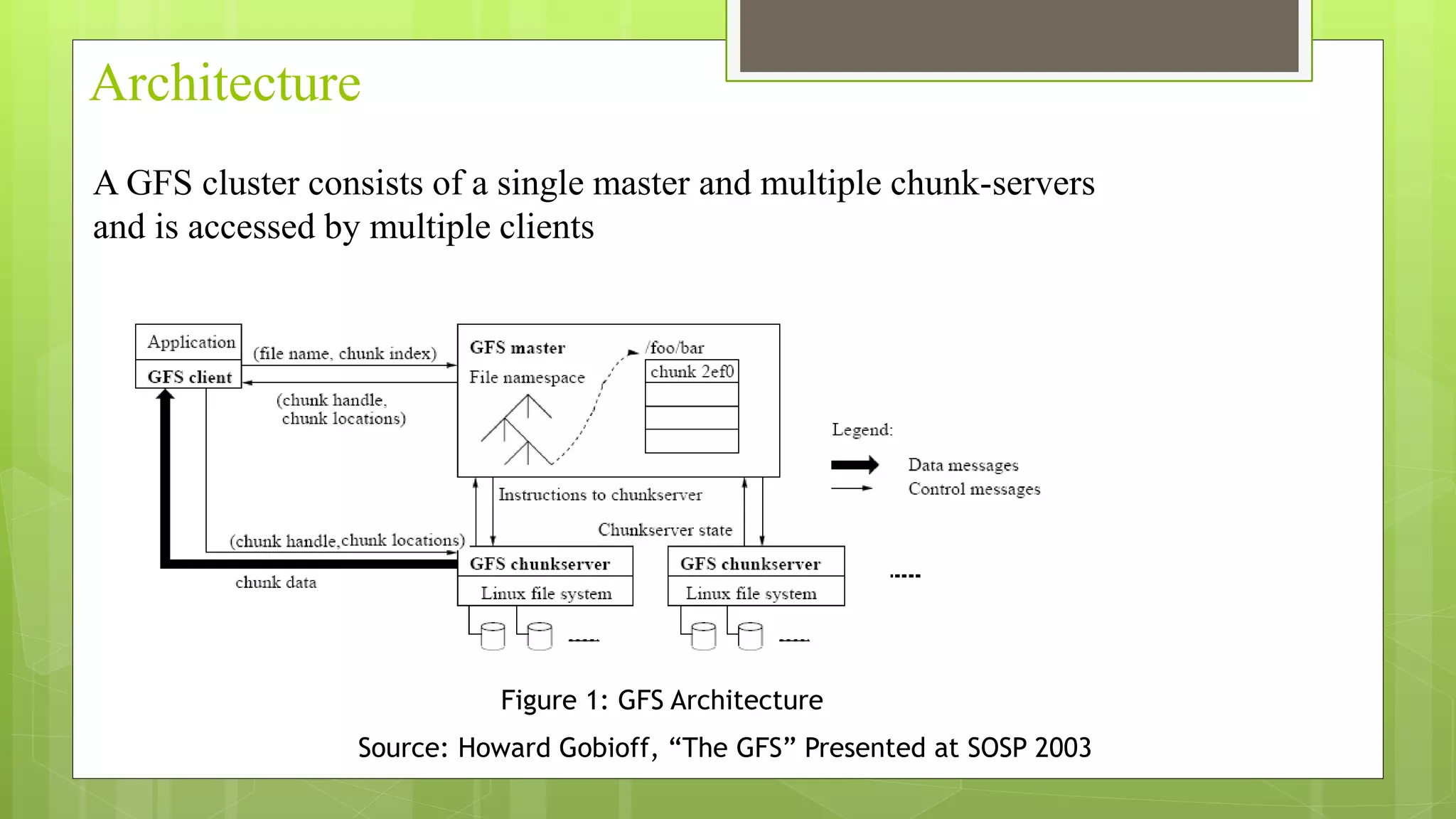
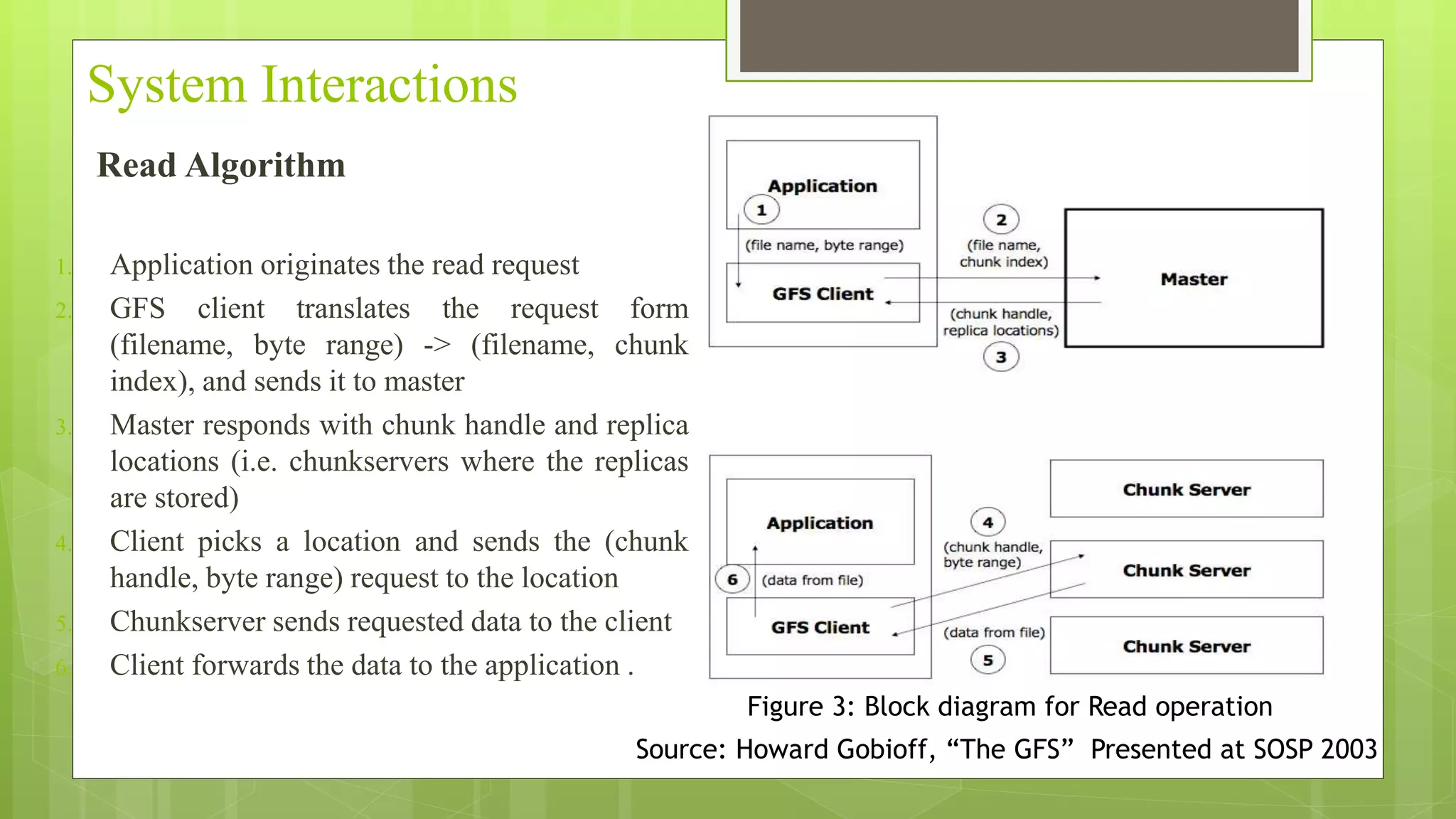
The Google File System (GFS) is a distributed file system designed to provide efficient, reliable access to data stored on commodity hardware. It consists of a single master node that manages metadata and chunk replication, and multiple chunkserver nodes that store file data in chunks. The master maintains metadata mapping files to variable-sized chunks, which are replicated across servers for fault tolerance. It performs tasks like chunk creation, rebalancing, and garbage collection to optimize storage usage and availability. Data flows linearly through servers to minimize latency. The system provides high throughput, incremental growth, and fault tolerance for Google's large-scale computing needs.

















![References
[1] Sanjay Ghemawat, Howard Gobioff and Shun-Tak Leung, The Google
File System, ACM SIGOPS Operating Systems Review, Volume 37, Issue 5,
2003.
[2] Sean Quinlan, Kirk McKusick “GFS-Evolution and Fast-Forward”
Communications of the ACM, Vol 53, 2013.
[3] Thomas Anderson, Michael Dahlin, JeannaNeefe, David Patterson, Drew
Roselli, and Randolph Wang. Serverlessnetworkfil e systems. In Proceedings of
the 15th ACM Symposium on Operating System Principles, pages 109–126,
Copper Mountain Resort, Colorado, December 1995.
[4] Luis-Felipe Cabrera and Darrell D. E. Long. Swift: Using distributed disks
triping to provide high I/O data rates. Computer Systems, 4(4):405–436, 1991.
[5] InterMezzo. http://www.inter-mezzo.org, 2003.](https://image.slidesharecdn.com/final-151227061939/75/advanced-Google-file-System-20-2048.jpg)




































































