Download to read offline















The document outlines the operations and achievements of Oak Ridge National Laboratory (ORNL) in the field of high-performance computing (HPC), primarily focusing on the leadership-class systems managed by the Oak Ridge Leadership Computing Facility. It details the evolution of ORNL's computing infrastructure, including notable supercomputers such as Summit and Frontier, alongside the challenges and advancements in data management and operational processes. Additionally, there are insights into the collaborative partnerships and the strategic vision for sustaining scientific impact and advancing computational sciences.
Introduction to ORNL's mission in supercomputing, its vision, and the facility's commitment to top-tier research.
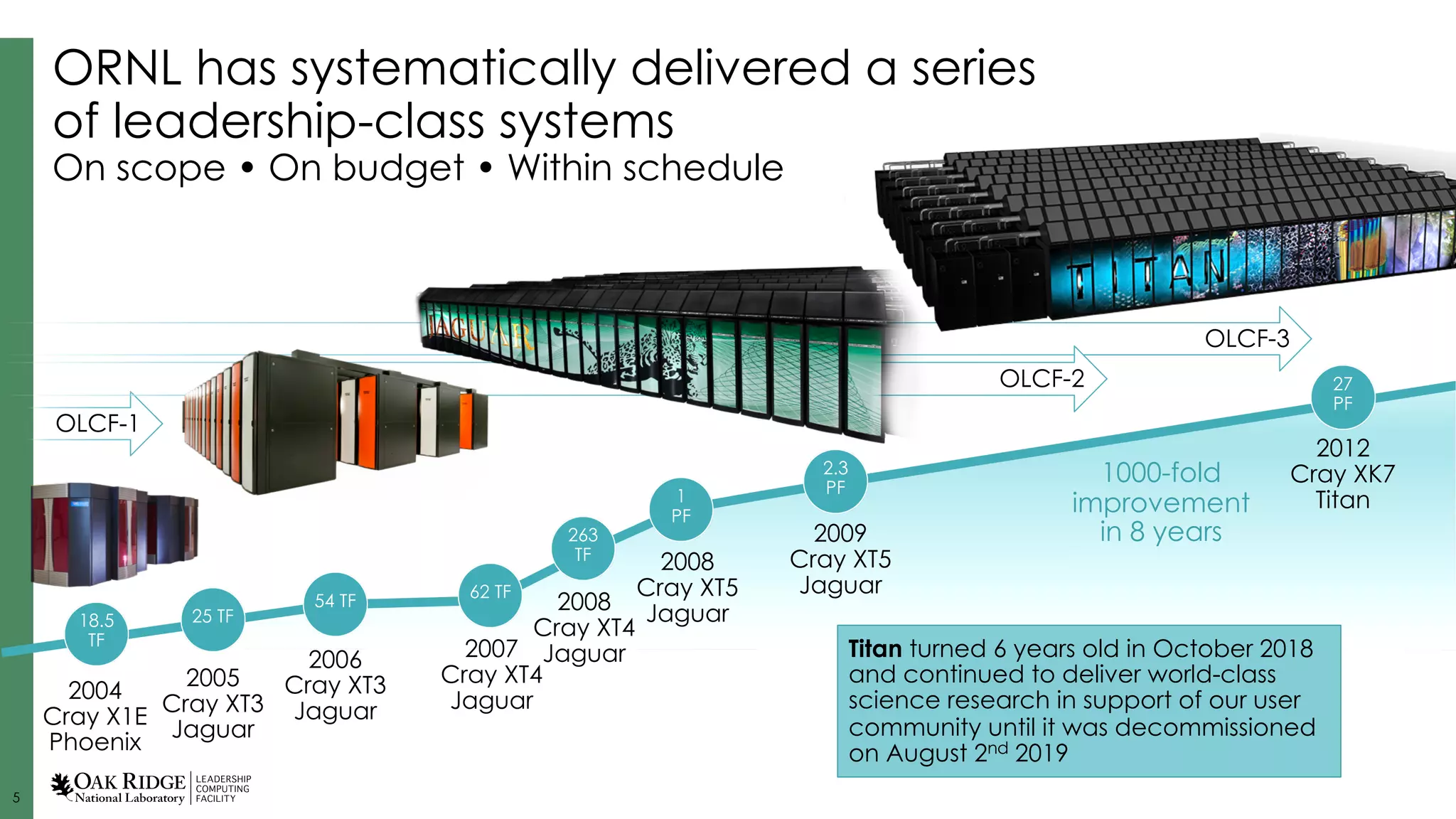
Details on the infrastructure and capabilities of the OLCF, including building specifications and growth in computing power.
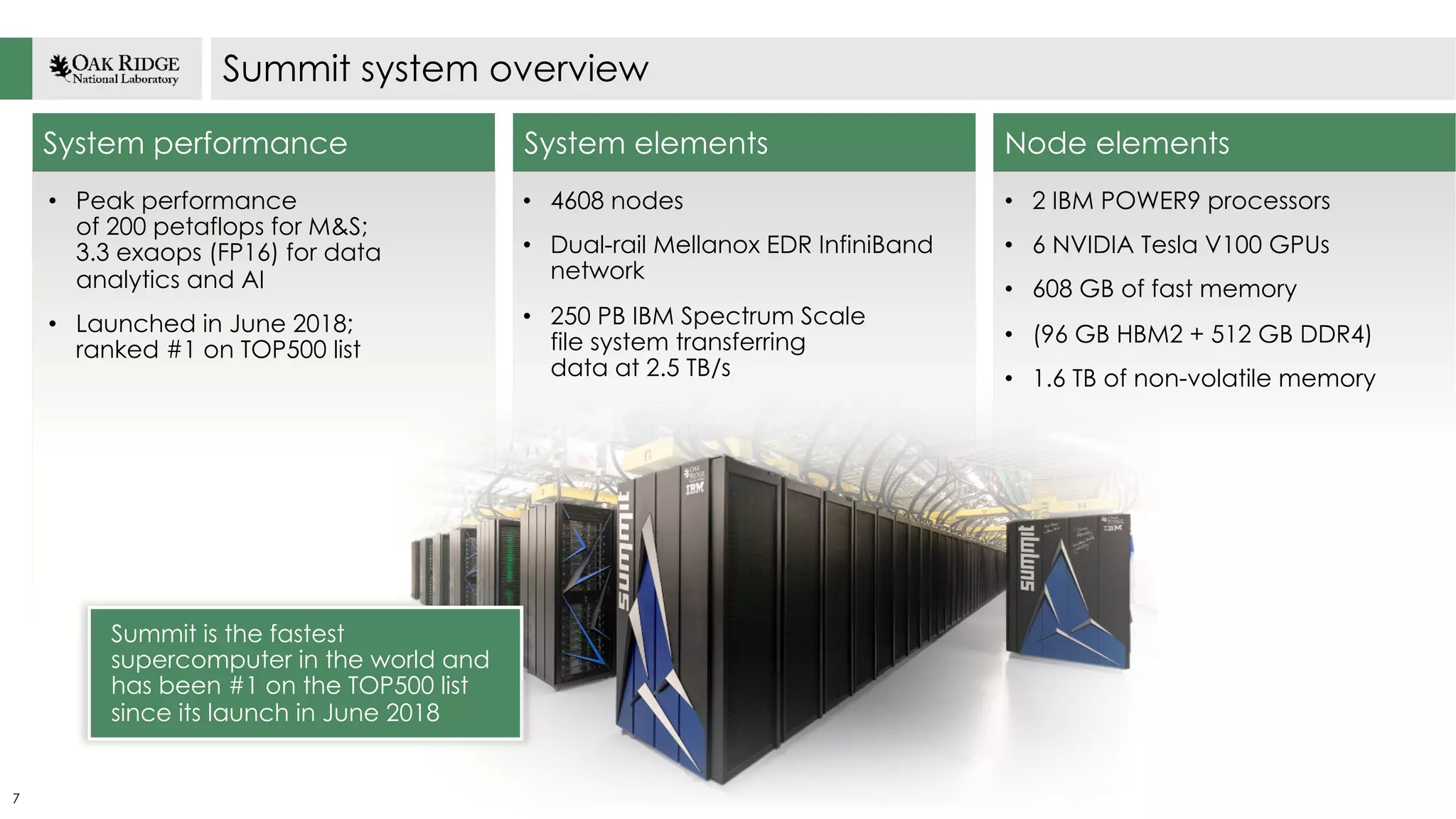
Overview of exascale systems like Frontier and Summit, highlighting their performance metrics and contributions to scientific advancements.
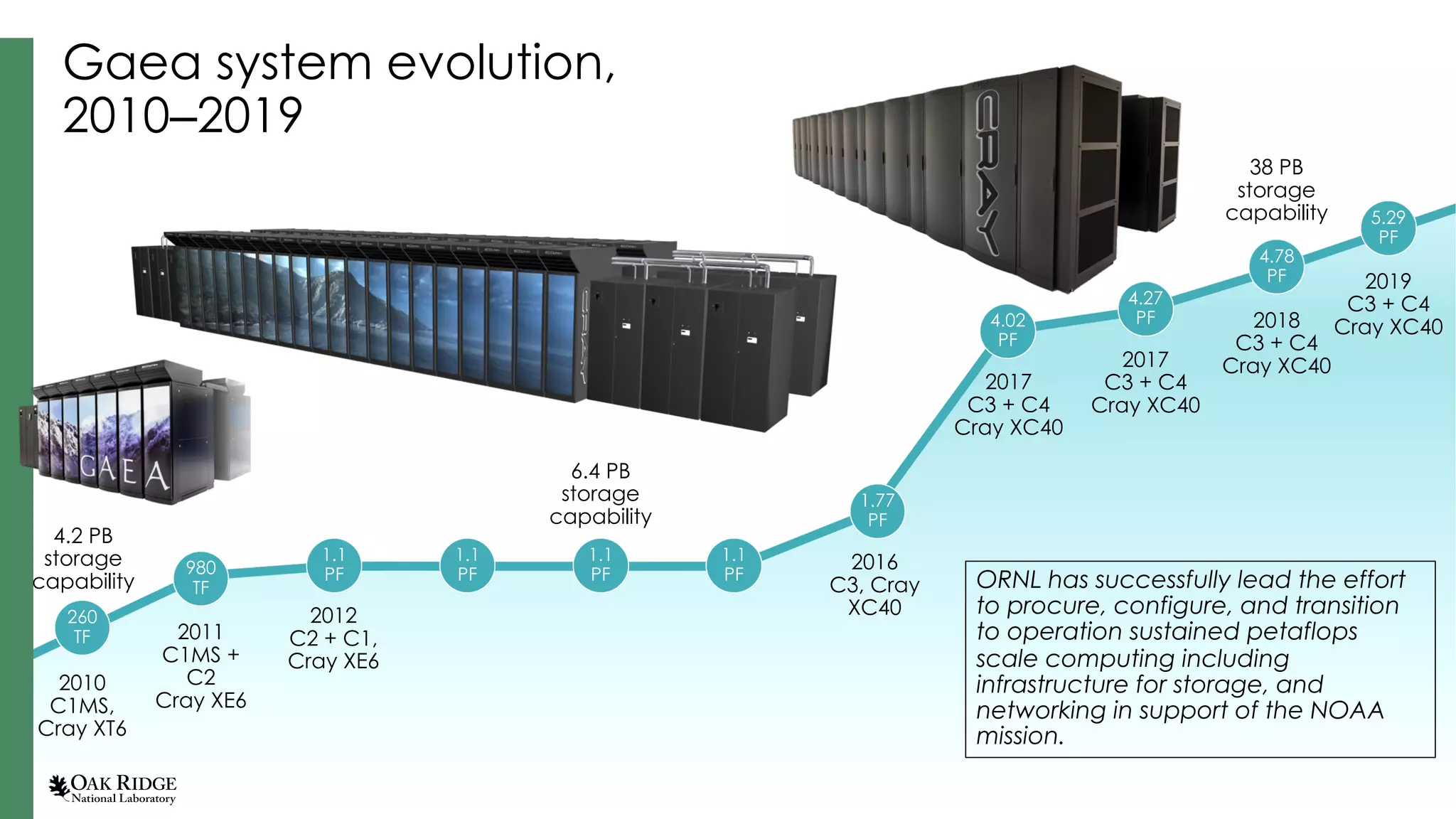
Partnerships for climate computing services, showcasing data evolution and alignment with NOAA’s data needs.
ORNL’s HPC services providing reliable computing for Air Force weather operations and their global missions.
Discussion on scientific and operational data, challenges in management, and the need for improved monitoring.
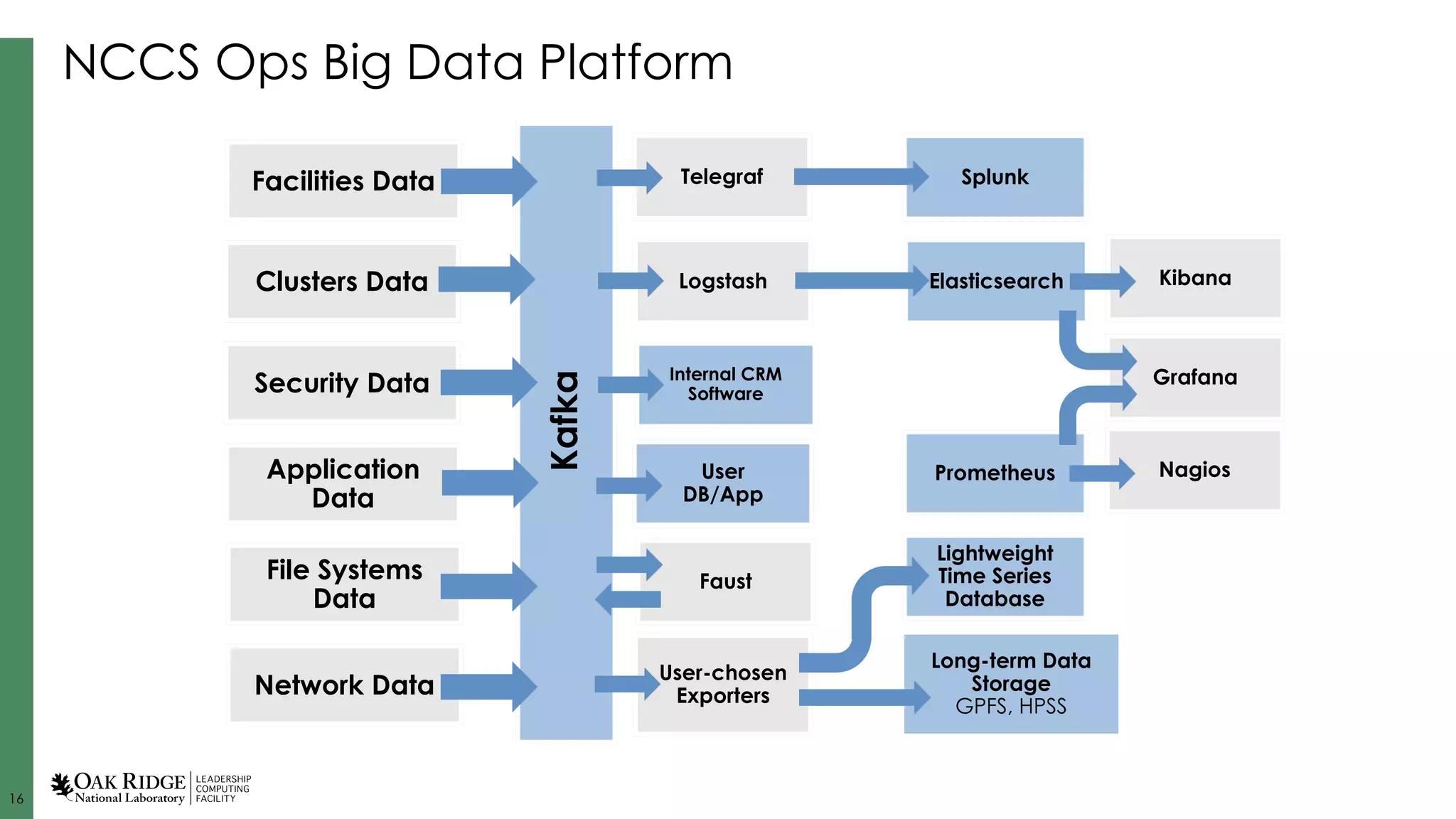
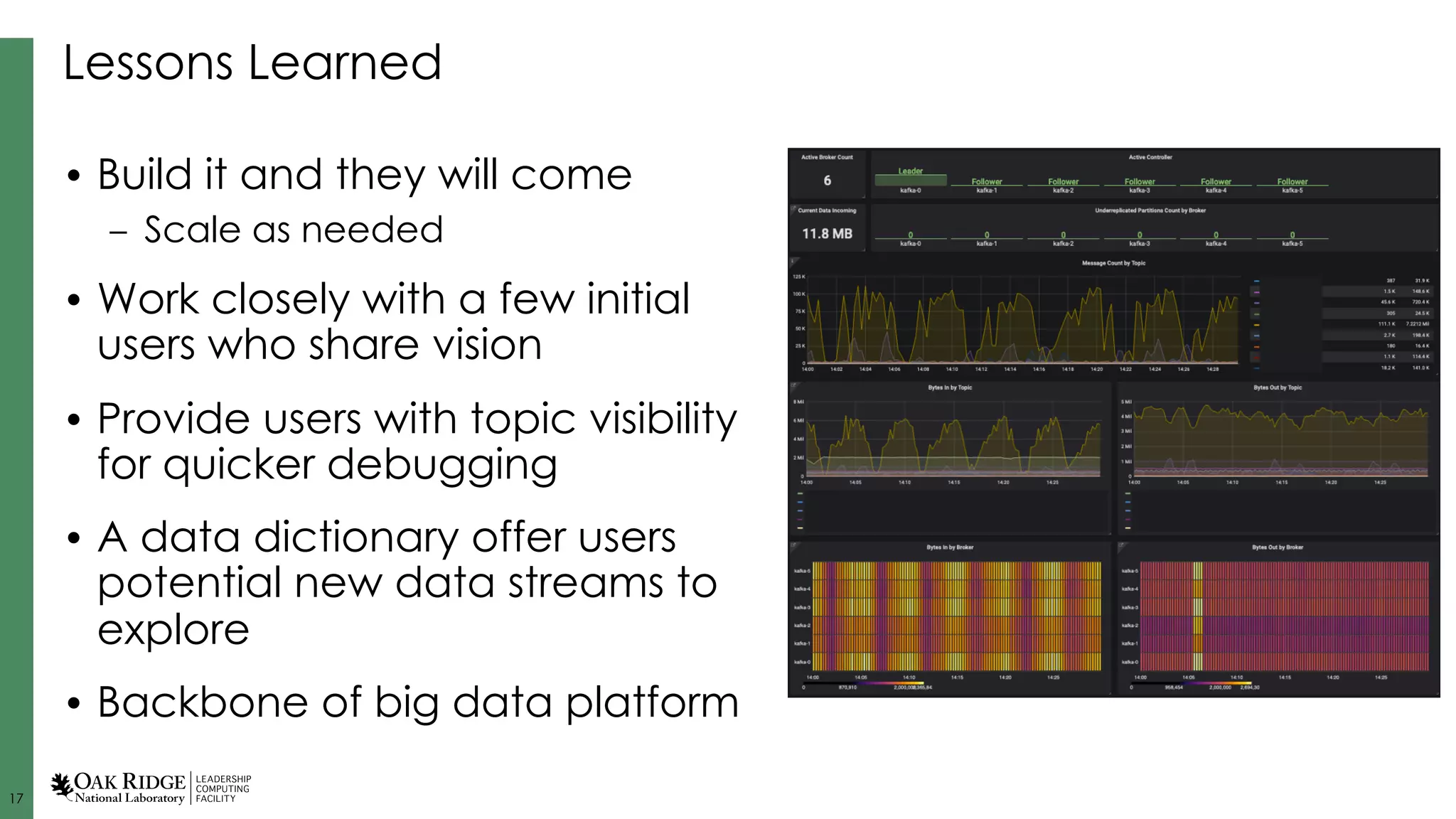
Formation of new teams and development of an integrated data platform for better management and analytics.
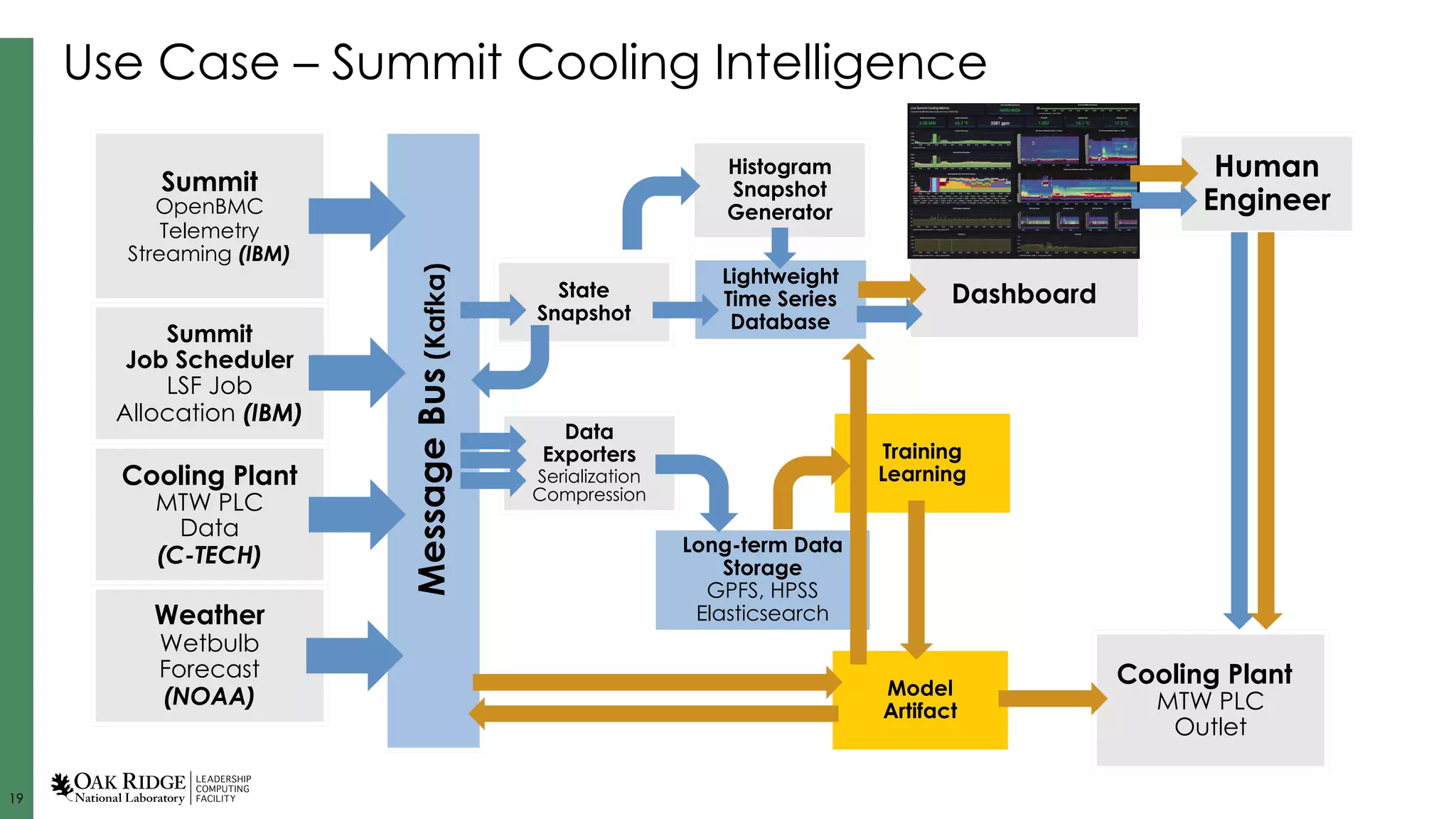
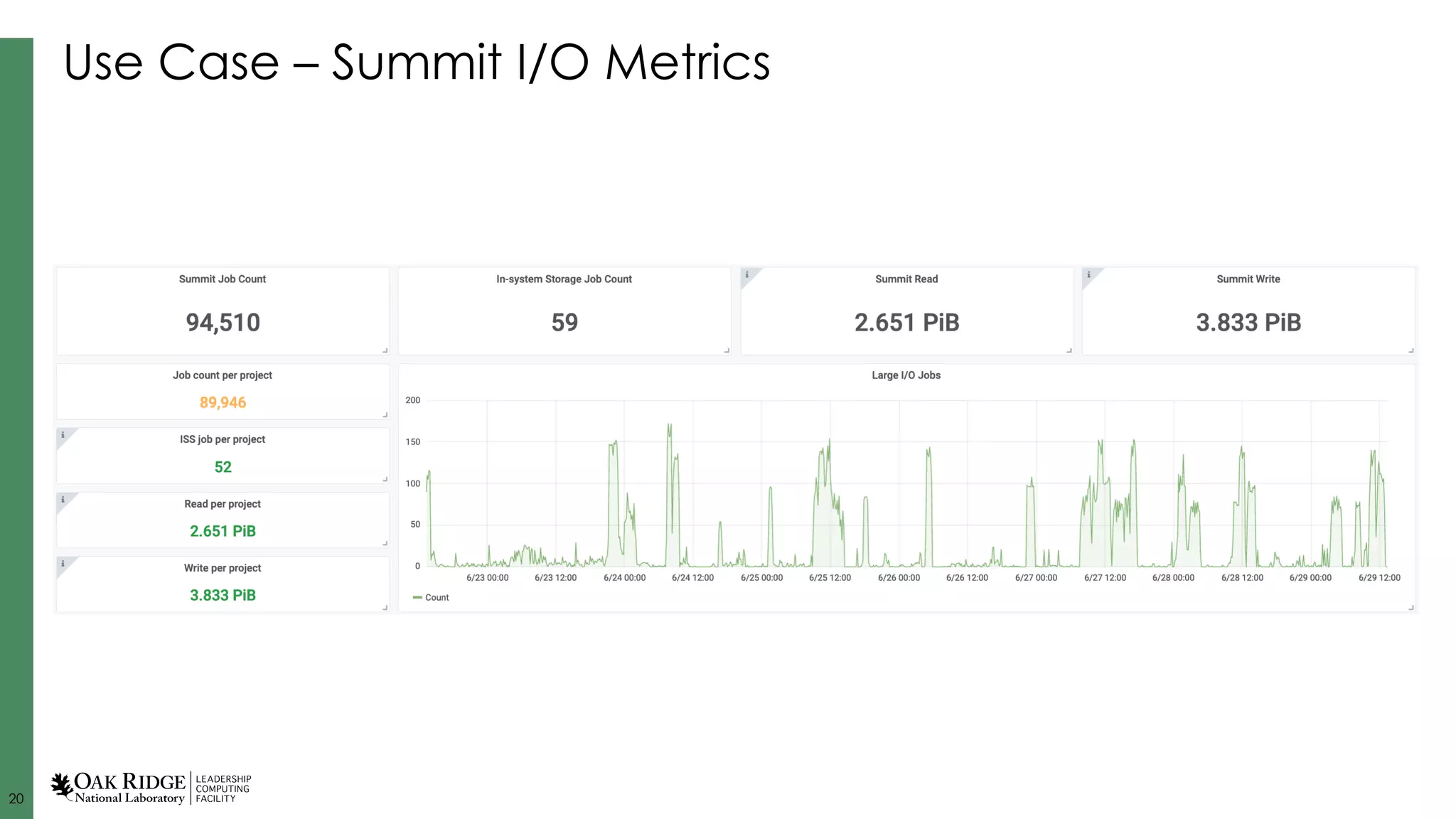
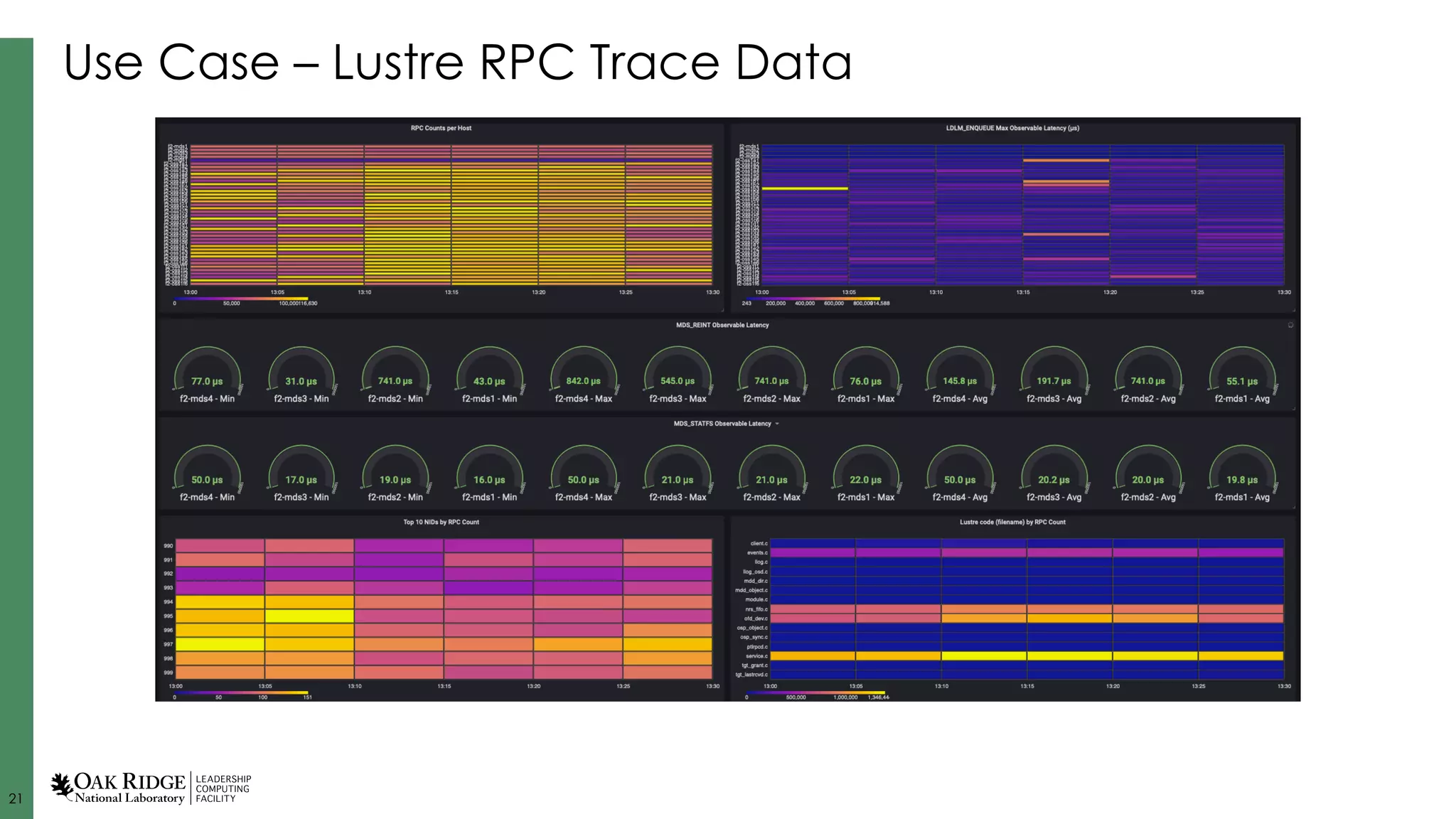
Specific use cases like cooling intelligence and metrics analysis, demonstrating real-time data management and resource optimization.



































































